


注意
点击 这里 下载完整示例代码
入门 || 张量 || Autograd || 构建模型 || TensorBoard 支持 || 训练模型 || 理解模型
PyTorch 入门¶
创建日期:2021 年 11 月 30 日 | 最后更新日期:2024 年 1 月 19 日 | 最后验证日期:2024 年 11 月 5 日
观看下面的视频或在 youtube 上观看。
PyTorch 张量¶
观看从 03:50 开始的视频。
首先,我们将导入 pytorch。
import torch
让我们来看一些基本的张量操作。首先,是一些创建张量的方法
z = torch.zeros(5, 3)
print(z)
print(z.dtype)
tensor([[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]])
torch.float32
上面,我们创建了一个填充零的 5x3 矩阵,并查询其数据类型,发现这些零是 32 位浮点数,这是 PyTorch 的默认类型。
如果您想要整数而不是浮点数怎么办?您总是可以覆盖默认设置
i = torch.ones((5, 3), dtype=torch.int16)
print(i)
tensor([[1, 1, 1],
[1, 1, 1],
[1, 1, 1],
[1, 1, 1],
[1, 1, 1]], dtype=torch.int16)
您可以看到,当我们确实改变默认设置时,张量在打印时会友好地报告这一点。
通常会随机初始化学习权重,为了结果的可复现性,通常会为 PRNG 设置特定的种子
torch.manual_seed(1729)
r1 = torch.rand(2, 2)
print('A random tensor:')
print(r1)
r2 = torch.rand(2, 2)
print('\nA different random tensor:')
print(r2) # new values
torch.manual_seed(1729)
r3 = torch.rand(2, 2)
print('\nShould match r1:')
print(r3) # repeats values of r1 because of re-seed
A random tensor:
tensor([[0.3126, 0.3791],
[0.3087, 0.0736]])
A different random tensor:
tensor([[0.4216, 0.0691],
[0.2332, 0.4047]])
Should match r1:
tensor([[0.3126, 0.3791],
[0.3087, 0.0736]])
PyTorch 张量直观地执行算术运算。形状相似的张量可以相加、相乘等。与标量的操作会分布到整个张量上
ones = torch.ones(2, 3)
print(ones)
twos = torch.ones(2, 3) * 2 # every element is multiplied by 2
print(twos)
threes = ones + twos # addition allowed because shapes are similar
print(threes) # tensors are added element-wise
print(threes.shape) # this has the same dimensions as input tensors
r1 = torch.rand(2, 3)
r2 = torch.rand(3, 2)
# uncomment this line to get a runtime error
# r3 = r1 + r2
tensor([[1., 1., 1.],
[1., 1., 1.]])
tensor([[2., 2., 2.],
[2., 2., 2.]])
tensor([[3., 3., 3.],
[3., 3., 3.]])
torch.Size([2, 3])
这里列出了一小部分可用的数学运算
r = (torch.rand(2, 2) - 0.5) * 2 # values between -1 and 1
print('A random matrix, r:')
print(r)
# Common mathematical operations are supported:
print('\nAbsolute value of r:')
print(torch.abs(r))
# ...as are trigonometric functions:
print('\nInverse sine of r:')
print(torch.asin(r))
# ...and linear algebra operations like determinant and singular value decomposition
print('\nDeterminant of r:')
print(torch.det(r))
print('\nSingular value decomposition of r:')
print(torch.svd(r))
# ...and statistical and aggregate operations:
print('\nAverage and standard deviation of r:')
print(torch.std_mean(r))
print('\nMaximum value of r:')
print(torch.max(r))
A random matrix, r:
tensor([[ 0.9956, -0.2232],
[ 0.3858, -0.6593]])
Absolute value of r:
tensor([[0.9956, 0.2232],
[0.3858, 0.6593]])
Inverse sine of r:
tensor([[ 1.4775, -0.2251],
[ 0.3961, -0.7199]])
Determinant of r:
tensor(-0.5703)
Singular value decomposition of r:
torch.return_types.svd(
U=tensor([[-0.8353, -0.5497],
[-0.5497, 0.8353]]),
S=tensor([1.1793, 0.4836]),
V=tensor([[-0.8851, -0.4654],
[ 0.4654, -0.8851]]))
Average and standard deviation of r:
(tensor(0.7217), tensor(0.1247))
Maximum value of r:
tensor(0.9956)
关于 PyTorch 张量的强大功能,还有很多需要了解的,包括如何为 GPU 上的并行计算进行设置——我们将在另一个视频中深入探讨。
PyTorch 模型¶
观看从 10:00 开始的视频。
让我们来谈谈如何在 PyTorch 中表达模型
import torch # for all things PyTorch
import torch.nn as nn # for torch.nn.Module, the parent object for PyTorch models
import torch.nn.functional as F # for the activation function
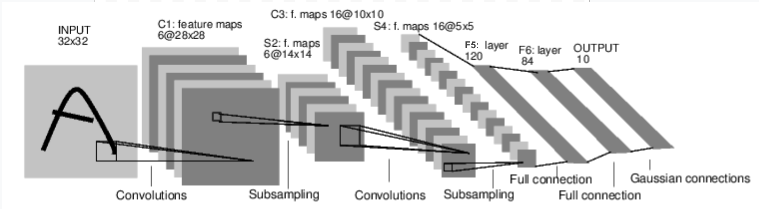
图:LeNet-5
上图是 LeNet-5 的示意图,它是最早的卷积神经网络之一,也是深度学习爆炸式增长的驱动力之一。它被构建用于读取手写数字的小图像(MNIST 数据集),并正确分类图像中表示的数字。
下面是其工作原理的简化版本
C1 层是卷积层,这意味着它扫描输入图像以查找在训练期间学习到的特征。它输出一个地图,显示其在图像中看到每个学习到的特征的位置。这个“激活图”在 S2 层进行下采样。
C3 层是另一个卷积层,这次扫描 C1 的激活图以查找特征的组合。它也输出一个激活图,描述这些特征组合的空间位置,这个激活图在 S4 层进行下采样。
最后,末端的全连接层 F5、F6 和 OUTPUT 是一个分类器,它接收最终的激活图,并将其分类到代表 10 个数字的十个类别之一。
我们如何在代码中表达这个简单的神经网络?
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
# 1 input image channel (black & white), 6 output channels, 5x5 square convolution
# kernel
self.conv1 = nn.Conv2d(1, 6, 5)
self.conv2 = nn.Conv2d(6, 16, 5)
# an affine operation: y = Wx + b
self.fc1 = nn.Linear(16 * 5 * 5, 120) # 5*5 from image dimension
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
# Max pooling over a (2, 2) window
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
# If the size is a square you can only specify a single number
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
x = x.view(-1, self.num_flat_features(x))
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
def num_flat_features(self, x):
size = x.size()[1:] # all dimensions except the batch dimension
num_features = 1
for s in size:
num_features *= s
return num_features
查看这段代码,您应该能够发现与上图的一些结构相似之处。
这展示了典型 PyTorch 模型的结构
它继承自
torch.nn.Module- 模块可以嵌套 - 事实上,甚至Conv2d和Linear层类也继承自torch.nn.Module。模型会有一个
__init__()函数,在此函数中实例化其层,并加载可能需要的任何数据工件(例如,一个 NLP 模型可能加载词汇表)。模型会有一个
forward()函数。这是实际计算发生的地方:输入通过网络层和各种函数来生成输出。除此之外,您可以像构建其他 Python 类一样构建您的模型类,添加您需要支持模型计算的任何属性和方法。
让我们实例化这个对象并运行一个示例输入通过它。
net = LeNet()
print(net) # what does the object tell us about itself?
input = torch.rand(1, 1, 32, 32) # stand-in for a 32x32 black & white image
print('\nImage batch shape:')
print(input.shape)
output = net(input) # we don't call forward() directly
print('\nRaw output:')
print(output)
print(output.shape)
LeNet(
(conv1): Conv2d(1, 6, kernel_size=(5, 5), stride=(1, 1))
(conv2): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1))
(fc1): Linear(in_features=400, out_features=120, bias=True)
(fc2): Linear(in_features=120, out_features=84, bias=True)
(fc3): Linear(in_features=84, out_features=10, bias=True)
)
Image batch shape:
torch.Size([1, 1, 32, 32])
Raw output:
tensor([[ 0.0898, 0.0318, 0.1485, 0.0301, -0.0085, -0.1135, -0.0296, 0.0164,
0.0039, 0.0616]], grad_fn=<AddmmBackward0>)
torch.Size([1, 10])
上面发生了几件重要的事情
首先,我们实例化 LeNet 类,并打印 net 对象。一个 torch.nn.Module 的子类将报告其创建的层及其形状和参数。如果您想快速了解模型的处理过程,这可以提供一个方便的概述。
在其下方,我们创建一个虚拟输入,代表一个具有 1 个颜色通道的 32x32 图像。通常,您会加载一个图像块并将其转换为这种形状的张量。
您可能已经注意到我们的张量有一个额外的维度 - 批次维度。PyTorch 模型假定它们正在处理数据的批次 - 例如,16 个图像块的批次将具有形状 (16, 1, 32, 32)。由于我们只使用一张图像,我们创建一个形状为 (1, 1, 32, 32) 的大小为 1 的批次。
我们通过像函数一样调用模型来请求推理:net(input)。此调用的输出代表模型对输入代表特定数字的置信度。(由于此模型实例尚未学习任何内容,我们不应期望在输出中看到任何信号。)查看 output 的形状,我们可以看到它也具有批次维度,其大小应始终与输入批次维度匹配。如果我们传入了 16 个实例的输入批次,output 的形状将是 (16, 10)。
数据集和数据加载器¶
观看从 14:00 开始的视频。
下面,我们将演示如何使用 TorchVision 中一个随时可下载的开放访问数据集,如何转换图像以供模型使用,以及如何使用 DataLoader 向模型馈送批量数据。
我们需要做的第一件事是将输入的图像转换为 PyTorch 张量。
#%matplotlib inline
import torch
import torchvision
import torchvision.transforms as transforms
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2470, 0.2435, 0.2616))])
在这里,我们为输入指定两种变换
transforms.ToTensor()将 Pillow 加载的图像转换为 PyTorch 张量。transforms.Normalize()调整张量的值,使其平均值为零,标准差为 1.0。大多数激活函数在 x = 0 附近有最强的梯度,因此将数据居中可以加快学习速度。传递给变换的值是数据集中图像 rgb 值的平均值(第一个元组)和标准差(第二个元组)。您可以通过运行以下几行代码自己计算这些值- ```
from torch.utils.data import ConcatDataset transform = transforms.Compose([transforms.ToTensor()]) trainset = torchvision.datasets.CIFAR10(root=’./data’, train=True,
download=True, transform=transform)
#将所有训练图像堆叠成形状为 #(50000, 3, 32, 32) 的张量 x = torch.stack([sample[0] for sample in ConcatDataset([trainset])])
#获取每个通道的平均值 mean = torch.mean(x, dim=(0,2,3)) #tensor([0.4914, 0.4822, 0.4465]) std = torch.std(x, dim=(0,2,3)) #tensor([0.2470, 0.2435, 0.2616])
还有许多其他可用的变换,包括裁剪、居中、旋转和翻转。
接下来,我们将创建一个 CIFAR10 数据集的实例。这是一组 32x32 彩色图像块,代表 10 类对象:6 类动物(鸟、猫、鹿、狗、青蛙、马)和 4 类车辆(飞机、汽车、轮船、卡车)
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
0%| | 0.00/170M [00:00<?, ?B/s]
0%| | 459k/170M [00:00<00:37, 4.52MB/s]
5%|4 | 7.77M/170M [00:00<00:03, 44.6MB/s]
10%|# | 17.9M/170M [00:00<00:02, 70.2MB/s]
15%|#5 | 26.0M/170M [00:00<00:01, 72.6MB/s]
20%|## | 34.4M/170M [00:00<00:01, 76.4MB/s]
25%|##4 | 42.2M/170M [00:00<00:01, 77.0MB/s]
29%|##9 | 50.2M/170M [00:00<00:01, 77.7MB/s]
34%|###4 | 58.3M/170M [00:00<00:01, 78.7MB/s]
39%|###9 | 67.1M/170M [00:00<00:01, 81.6MB/s]
44%|####4 | 75.3M/170M [00:01<00:01, 80.0MB/s]
49%|####9 | 84.3M/170M [00:01<00:01, 83.1MB/s]
54%|#####4 | 92.7M/170M [00:01<00:00, 82.0MB/s]
59%|#####9 | 101M/170M [00:01<00:00, 80.7MB/s]
64%|######3 | 109M/170M [00:01<00:00, 80.1MB/s]
69%|######8 | 117M/170M [00:01<00:00, 80.3MB/s]
73%|#######3 | 125M/170M [00:01<00:00, 75.3MB/s]
80%|#######9 | 136M/170M [00:01<00:00, 85.5MB/s]
85%|########5 | 145M/170M [00:01<00:00, 84.2MB/s]
90%|######### | 153M/170M [00:01<00:00, 83.6MB/s]
95%|#########4| 162M/170M [00:02<00:00, 83.5MB/s]
100%|#########9| 170M/170M [00:02<00:00, 83.0MB/s]
100%|##########| 170M/170M [00:02<00:00, 78.5MB/s]
注意
当您运行上面的单元格时,数据集下载可能需要一些时间。
这是在 PyTorch 中创建数据集对象的一个例子。可下载的数据集(如上面的 CIFAR-10)是 torch.utils.data.Dataset 的子类。PyTorch 中的 Dataset 类包括 TorchVision、Torchtext 和 TorchAudio 中的可下载数据集,以及像 torchvision.datasets.ImageFolder 这样的实用数据集类,后者将读取带标签图像的文件夹。您也可以创建自己的 Dataset 子类。
当我们实例化数据集时,我们需要告诉它几件事
我们希望数据存放的文件系统路径。
我们是否将此集合用于训练;大多数数据集都会被分成训练集和测试集。
如果我们尚未下载数据集,是否希望下载它。
我们想要应用于数据的变换。
数据集准备好后,您可以将其提供给 DataLoader
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4,
shuffle=True, num_workers=2)
一个 Dataset 子类封装了对数据的访问,并且专门用于其提供的数据类型。DataLoader 对数据一无所知,但它根据您指定的参数,将由 Dataset 提供的输入张量组织成批次。
在上面的示例中,我们要求一个 DataLoader 从 trainset 中提供大小为 4 的图像批次,并随机打乱它们的顺序 (shuffle=True),并且告诉它启动两个工作进程从磁盘加载数据。
可视化 DataLoader 提供的批次是一个好习惯
import matplotlib.pyplot as plt
import numpy as np
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
def imshow(img):
img = img / 2 + 0.5 # unnormalize
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
# get some random training images
dataiter = iter(trainloader)
images, labels = next(dataiter)
# show images
imshow(torchvision.utils.make_grid(images))
# print labels
print(' '.join('%5s' % classes[labels[j]] for j in range(4)))

Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). Got range [-0.49473685..1.5632443].
ship car horse ship
运行上面的单元格应该会显示一排四张图像,以及每张图像的正确标签。
训练您的 PyTorch 模型¶
观看从 17:10 开始的视频。
让我们把所有部分组合起来,训练一个模型
#%matplotlib inline
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
import matplotlib
import matplotlib.pyplot as plt
import numpy as np
首先,我们需要训练集和测试集。如果您还没有下载数据集,请运行下面的单元格以确保数据集已下载。(可能需要一分钟。)
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4,
shuffle=True, num_workers=2)
testset = torchvision.datasets.CIFAR10(root='./data', train=False,
download=True, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=4,
shuffle=False, num_workers=2)
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
我们将在 DataLoader 的输出上运行检查
import matplotlib.pyplot as plt
import numpy as np
# functions to show an image
def imshow(img):
img = img / 2 + 0.5 # unnormalize
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
# get some random training images
dataiter = iter(trainloader)
images, labels = next(dataiter)
# show images
imshow(torchvision.utils.make_grid(images))
# print labels
print(' '.join('%5s' % classes[labels[j]] for j in range(4)))

cat cat deer frog
这是我们要训练的模型。如果它看起来很熟悉,那是因为它是 LeNet 的一个变体 - 在本视频前面讨论过 - 适配于 3 色图像。
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
net = Net()
我们需要的最后要素是损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
损失函数,如本视频前面讨论的,衡量模型预测与我们理想输出的偏离程度。交叉熵损失是像我们这样的分类模型典型的损失函数。
优化器是驱动学习的机制。在这里,我们创建了一个实现随机梯度下降的优化器,它是更直接的优化算法之一。除了算法的参数,如学习率 (lr) 和动量,我们还传入了 net.parameters(),这是模型中所有学习权重的集合——这就是优化器调整的对象。
最后,所有这些都组合到训练循环中。请继续运行此单元格,因为它可能需要几分钟才能执行完毕
for epoch in range(2): # loop over the dataset multiple times
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
# get the inputs
inputs, labels = data
# zero the parameter gradients
optimizer.zero_grad()
# forward + backward + optimize
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
if i % 2000 == 1999: # print every 2000 mini-batches
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 2000))
running_loss = 0.0
print('Finished Training')
[1, 2000] loss: 2.195
[1, 4000] loss: 1.879
[1, 6000] loss: 1.656
[1, 8000] loss: 1.576
[1, 10000] loss: 1.517
[1, 12000] loss: 1.461
[2, 2000] loss: 1.415
[2, 4000] loss: 1.368
[2, 6000] loss: 1.334
[2, 8000] loss: 1.327
[2, 10000] loss: 1.318
[2, 12000] loss: 1.261
Finished Training
在这里,我们只进行 2 个训练 epoch(第 1 行)- 也就是说,对训练数据集进行两次遍历。每次遍历都有一个内部循环,用于迭代训练数据(第 4 行),提供经过变换的输入图像及其正确标签的批次。
梯度清零(第 9 行)是一个重要的步骤。梯度会在一个批次中累积;如果我们不为每个批次重置它们,它们将持续累积,这将提供不正确的梯度值,使得学习不可能。
在第 12 行,我们要求模型对该批次进行预测。在下一行(第 13 行),我们计算损失 - outputs(模型预测)与 labels(正确输出)之间的差异。
在第 14 行,我们执行 backward() 传播,并计算将指导学习的梯度。
在第 15 行,优化器执行一步学习 - 它使用从 backward() 调用中获得的梯度来微调学习权重,使其朝着它认为会降低损失的方向移动。
循环的其余部分对 epoch 数、已完成的训练实例数以及整个训练循环中收集的损失进行了一些简要报告。
当您运行上面的单元格时,您应该会看到如下内容
[1, 2000] loss: 2.235
[1, 4000] loss: 1.940
[1, 6000] loss: 1.713
[1, 8000] loss: 1.573
[1, 10000] loss: 1.507
[1, 12000] loss: 1.442
[2, 2000] loss: 1.378
[2, 4000] loss: 1.364
[2, 6000] loss: 1.349
[2, 8000] loss: 1.319
[2, 10000] loss: 1.284
[2, 12000] loss: 1.267
Finished Training
请注意,损失是单调下降的,这表明我们的模型在训练数据集上的性能正在持续改进。
作为最后一步,我们应该检查模型是否真的在进行泛化学习,而不是简单地“记忆”数据集。这称为过拟合,通常表明数据集太小(没有足够的示例进行泛化学习),或者模型具有比正确建模数据集所需的更多的学习参数。
这就是将数据集分成训练集和测试集的原因——为了测试模型的泛化能力,我们要求它对它未训练过的数据进行预测
correct = 0
total = 0
with torch.no_grad():
for data in testloader:
images, labels = data
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: %d %%' % (
100 * correct / total))
Accuracy of the network on the 10000 test images: 54 %
如果您跟着操作,您应该会看到模型目前的大约准确率为 50%。这并非最先进水平,但这远好于我们从随机输出中期望的 10% 准确率。这表明模型确实发生了一些泛化学习。
脚本总运行时间: ( 1 分 20.320 秒)
