


注意
点击此处下载完整的示例代码
入门 || 张量 || Autograd || 构建模型 || TensorBoard 支持 || 训练模型 || 模型理解
Autograd 的基础知识¶
创建于: 2021 年 11 月 30 日 | 最后更新于: 2024 年 2 月 26 日 | 最后验证于: 2024 年 11 月 05 日
观看下面的视频或在 youtube 上观看,一起学习。
PyTorch 的 Autograd 特性是 PyTorch 灵活且快速构建机器学习项目的关键之一。它允许在复杂的计算中快速轻松地计算多个偏导数(也称为梯度)。此操作是基于反向传播的神经网络学习的核心。
Autograd 的强大之处在于它在运行时动态跟踪你的计算,这意味着如果你的模型有决策分支,或循环长度直到运行时才确定,计算仍能被正确跟踪,并且你会获得正确的梯度来驱动学习。这一点,再加上你的模型是使用 Python 构建的,比那些依赖对更严格结构化模型进行静态分析来计算梯度的框架提供了更大的灵活性。
为什么我们需要 Autograd?¶
机器学习模型是一个函数,具有输入和输出。在本次讨论中,我们将输入视为一个 i 维向量 \(\vec{x}\),其元素为 \(x_{i}\)。然后,我们可以将模型 M 表示为输入的向量值函数:\(\vec{y} = \vec{M}(\vec{x})\)。(我们将 M 的输出值视为向量,因为一般来说,模型可以有任意数量的输出。)
由于我们主要在训练的背景下讨论 autograd,我们关注的输出将是模型的损失。损失函数 L(\(\vec{y}\)) = L(\(\vec{M}\)(\(\vec{x}\))) 是模型输出的单值标量函数。此函数表示我们的模型预测与特定输入的理想输出之间的偏差程度。注意:从此处开始,在上下文清晰的情况下,我们将经常省略向量符号 - 例如,使用 \(y\) 而不是 \(\vec y\)。
在训练模型时,我们希望最小化损失。在理想的完美模型情况下,这意味着调整其学习权重 - 即函数的参数 - 使所有输入的损失为零。在现实世界中,这意味着一个迭代过程,通过微调学习权重,直到我们看到对于各种输入都能获得可容忍的损失。
我们如何决定微调权重的幅度和方向?我们希望最小化损失,这意味着使其对输入的第一个导数等于 0:\(\frac{\partial L}{\partial x} = 0\)。
然而,回想一下,损失并非直接来自输入,而是模型输出的函数(模型输出又是输入的直接函数),\(\frac{\partial L}{\partial x}\) = \(\frac{\partial {L({\vec y})}}{\partial x}\)。根据微分学的链式法则,我们有 \(\frac{\partial {L({\vec y})}}{\partial x}\) = \(\frac{\partial L}{\partial y}\frac{\partial y}{\partial x}\) = \(\frac{\partial L}{\partial y}\frac{\partial M(x)}{\partial x}\)。
\(\frac{\partial M(x)}{\partial x}\) 是事情变得复杂的地方。模型的输出对输入的偏导数,如果我们使用链式法则再次展开表达式,将涉及模型中每个相乘的学习权重、每个激活函数以及所有其他数学变换的许多局部偏导数。每个此类偏导数的完整表达式是计算图中以我们试图测量其梯度的变量结束的每一条可能路径的局部梯度的乘积之和。
特别是,我们对学习权重上的梯度很感兴趣 - 它们告诉我们改变每个权重的方向,以使损失函数更接近于零。
由于此类局部导数的数量(每个都对应于通过模型计算图的一条独立路径)倾向于随着神经网络深度的增加呈指数级增长,因此计算它们的复杂性也随之增加。这就是 autograd 的作用所在:它跟踪每次计算的历史。PyTorch 模型中计算的每个张量都带有其输入张量和用于创建它的函数的历史记录。再结合 PyTorch 中旨在作用于张量的函数都内置了计算自身导数的实现,这极大地加速了学习所需的局部导数的计算。
一个简单的示例¶
理论讲了不少 - 但在实践中使用 autograd 是怎样的呢?
让我们从一个简单的例子开始。首先,我们将导入一些库,以便绘制结果图
# %matplotlib inline
import torch
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
import math
接下来,我们将创建一个包含区间 \([0, 2{\pi}]\) 上均匀分布值的输入张量,并指定 requires_grad=True。(与大多数创建张量的函数一样,torch.linspace() 接受一个可选的 requires_grad 选项。)设置此标志意味着在随后的每次计算中,autograd 将在该计算的输出张量中累积计算历史。
a = torch.linspace(0., 2. * math.pi, steps=25, requires_grad=True)
print(a)
tensor([0.0000, 0.2618, 0.5236, 0.7854, 1.0472, 1.3090, 1.5708, 1.8326, 2.0944,
2.3562, 2.6180, 2.8798, 3.1416, 3.4034, 3.6652, 3.9270, 4.1888, 4.4506,
4.7124, 4.9742, 5.2360, 5.4978, 5.7596, 6.0214, 6.2832],
requires_grad=True)
接下来,我们将执行计算,并根据其输入绘制其输出图
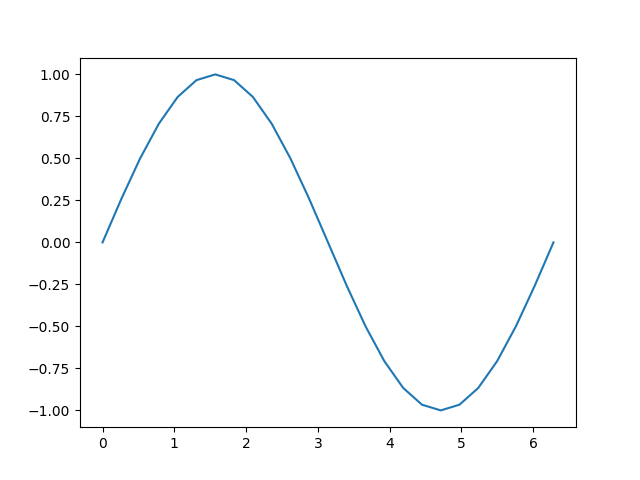
[<matplotlib.lines.Line2D object at 0x7f1316776380>]
让我们仔细看看张量 b。当我们打印它时,会看到一个指示符,表明它正在跟踪其计算历史
print(b)
tensor([ 0.0000e+00, 2.5882e-01, 5.0000e-01, 7.0711e-01, 8.6603e-01,
9.6593e-01, 1.0000e+00, 9.6593e-01, 8.6603e-01, 7.0711e-01,
5.0000e-01, 2.5882e-01, -8.7423e-08, -2.5882e-01, -5.0000e-01,
-7.0711e-01, -8.6603e-01, -9.6593e-01, -1.0000e+00, -9.6593e-01,
-8.6603e-01, -7.0711e-01, -5.0000e-01, -2.5882e-01, 1.7485e-07],
grad_fn=<SinBackward0>)
这个 grad_fn 提示我们,当我们执行反向传播步骤并计算梯度时,需要计算此张量所有输入的 \(\sin(x)\) 的导数。
让我们执行更多计算
tensor([ 0.0000e+00, 5.1764e-01, 1.0000e+00, 1.4142e+00, 1.7321e+00,
1.9319e+00, 2.0000e+00, 1.9319e+00, 1.7321e+00, 1.4142e+00,
1.0000e+00, 5.1764e-01, -1.7485e-07, -5.1764e-01, -1.0000e+00,
-1.4142e+00, -1.7321e+00, -1.9319e+00, -2.0000e+00, -1.9319e+00,
-1.7321e+00, -1.4142e+00, -1.0000e+00, -5.1764e-01, 3.4969e-07],
grad_fn=<MulBackward0>)
tensor([ 1.0000e+00, 1.5176e+00, 2.0000e+00, 2.4142e+00, 2.7321e+00,
2.9319e+00, 3.0000e+00, 2.9319e+00, 2.7321e+00, 2.4142e+00,
2.0000e+00, 1.5176e+00, 1.0000e+00, 4.8236e-01, -3.5763e-07,
-4.1421e-01, -7.3205e-01, -9.3185e-01, -1.0000e+00, -9.3185e-01,
-7.3205e-01, -4.1421e-01, 4.7684e-07, 4.8236e-01, 1.0000e+00],
grad_fn=<AddBackward0>)
最后,让我们计算一个单元素输出。当你对一个没有参数的张量调用 .backward() 时,它期望调用张量只包含一个元素,就像计算损失函数时一样。
tensor(25., grad_fn=<SumBackward0>)
每个与我们的张量一起存储的 grad_fn 都可以让你通过其 next_functions 属性一直回溯到其输入。我们可以看到,对 d 的此属性进行深入探究,会显示所有先前张量的梯度函数。注意,a.grad_fn 报告为 None,表明这是函数的输入,本身没有历史记录。
print('d:')
print(d.grad_fn)
print(d.grad_fn.next_functions)
print(d.grad_fn.next_functions[0][0].next_functions)
print(d.grad_fn.next_functions[0][0].next_functions[0][0].next_functions)
print(d.grad_fn.next_functions[0][0].next_functions[0][0].next_functions[0][0].next_functions)
print('\nc:')
print(c.grad_fn)
print('\nb:')
print(b.grad_fn)
print('\na:')
print(a.grad_fn)
d:
<AddBackward0 object at 0x7f12e5ab6230>
((<MulBackward0 object at 0x7f12e5ab6200>, 0), (None, 0))
((<SinBackward0 object at 0x7f12e5ab6200>, 0), (None, 0))
((<AccumulateGrad object at 0x7f12e5ab6230>, 0),)
()
c:
<MulBackward0 object at 0x7f12e5ab6200>
b:
<SinBackward0 object at 0x7f12e5ab6200>
a:
None
有了所有这些机制,我们如何获取导数呢?你可以在输出上调用 backward() 方法,并检查输入的 grad 属性以查看梯度
out.backward()
print(a.grad)
plt.plot(a.detach(), a.grad.detach())
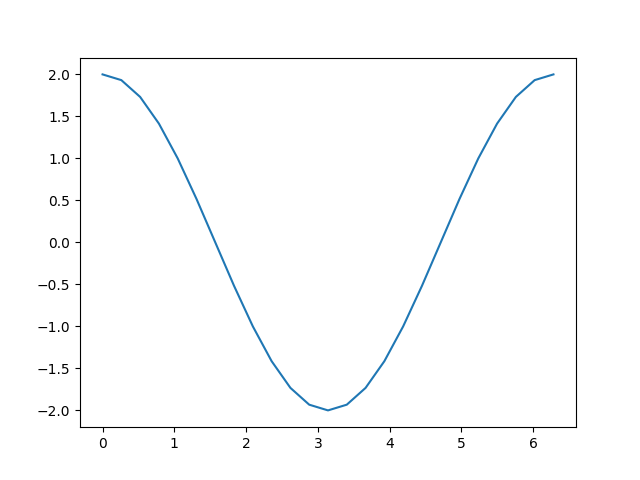
tensor([ 2.0000e+00, 1.9319e+00, 1.7321e+00, 1.4142e+00, 1.0000e+00,
5.1764e-01, -8.7423e-08, -5.1764e-01, -1.0000e+00, -1.4142e+00,
-1.7321e+00, -1.9319e+00, -2.0000e+00, -1.9319e+00, -1.7321e+00,
-1.4142e+00, -1.0000e+00, -5.1764e-01, 2.3850e-08, 5.1764e-01,
1.0000e+00, 1.4142e+00, 1.7321e+00, 1.9319e+00, 2.0000e+00])
[<matplotlib.lines.Line2D object at 0x7f12e5cc5240>]
回顾一下我们到达这里所采取的计算步骤
像我们计算 d 那样添加一个常数,不会改变导数。剩下的就是 \(c = 2 * b = 2 * \sin(a)\),其导数应该是 \(2 * \cos(a)\)。看看上面的图,这就是我们看到的结果。
请注意,只有计算图的叶子节点才会计算梯度。例如,如果你尝试 print(c.grad),你会得到 None。在这个简单的例子中,只有输入是叶子节点,因此只有它计算了梯度。
训练中的 Autograd¶
我们简要了解了 autograd 的工作原理,但当它用于其预期目的时是什么样的呢?让我们定义一个小模型,并检查它在一个训练批次后如何变化。首先,定义一些常量、我们的模型以及一些输入和输出的替身
BATCH_SIZE = 16
DIM_IN = 1000
HIDDEN_SIZE = 100
DIM_OUT = 10
class TinyModel(torch.nn.Module):
def __init__(self):
super(TinyModel, self).__init__()
self.layer1 = torch.nn.Linear(DIM_IN, HIDDEN_SIZE)
self.relu = torch.nn.ReLU()
self.layer2 = torch.nn.Linear(HIDDEN_SIZE, DIM_OUT)
def forward(self, x):
x = self.layer1(x)
x = self.relu(x)
x = self.layer2(x)
return x
some_input = torch.randn(BATCH_SIZE, DIM_IN, requires_grad=False)
ideal_output = torch.randn(BATCH_SIZE, DIM_OUT, requires_grad=False)
model = TinyModel()
你可能会注意到的一件事是,我们从未为模型的层指定 requires_grad=True。在 torch.nn.Module 的子类中,我们假定希望跟踪层权重的梯度以进行学习。
如果我们查看模型的层,可以检查权重的数值,并验证尚未计算任何梯度
print(model.layer2.weight[0][0:10]) # just a small slice
print(model.layer2.weight.grad)
tensor([ 0.0920, 0.0916, 0.0121, 0.0083, -0.0055, 0.0367, 0.0221, -0.0276,
-0.0086, 0.0157], grad_fn=<SliceBackward0>)
None
让我们看看运行一个训练批次后会有什么变化。对于损失函数,我们将使用我们的 prediction 和 ideal_output 之间的欧几里得距离的平方,我们将使用一个基本的随机梯度下降优化器。
optimizer = torch.optim.SGD(model.parameters(), lr=0.001)
prediction = model(some_input)
loss = (ideal_output - prediction).pow(2).sum()
print(loss)
tensor(211.2634, grad_fn=<SumBackward0>)
现在,让我们调用 loss.backward(),看看会发生什么
loss.backward()
print(model.layer2.weight[0][0:10])
print(model.layer2.weight.grad[0][0:10])
tensor([ 0.0920, 0.0916, 0.0121, 0.0083, -0.0055, 0.0367, 0.0221, -0.0276,
-0.0086, 0.0157], grad_fn=<SliceBackward0>)
tensor([12.8997, 2.9572, 2.3021, 1.8887, 5.0710, 7.3192, 3.5169, 2.4319,
0.1732, -5.3835])
我们可以看到,每个学习权重的梯度都已计算出来,但权重保持不变,因为我们还没有运行优化器。优化器负责根据计算出的梯度更新模型权重。
optimizer.step()
print(model.layer2.weight[0][0:10])
print(model.layer2.weight.grad[0][0:10])
tensor([ 0.0791, 0.0886, 0.0098, 0.0064, -0.0106, 0.0293, 0.0186, -0.0300,
-0.0088, 0.0211], grad_fn=<SliceBackward0>)
tensor([12.8997, 2.9572, 2.3021, 1.8887, 5.0710, 7.3192, 3.5169, 2.4319,
0.1732, -5.3835])
你应该看到 layer2 的权重已经改变了。
关于这个过程,重要的一点是:在调用 optimizer.step() 后,你需要调用 optimizer.zero_grad(),否则每次运行 loss.backward() 时,学习权重的梯度都会累积
print(model.layer2.weight.grad[0][0:10])
for i in range(0, 5):
prediction = model(some_input)
loss = (ideal_output - prediction).pow(2).sum()
loss.backward()
print(model.layer2.weight.grad[0][0:10])
optimizer.zero_grad(set_to_none=False)
print(model.layer2.weight.grad[0][0:10])
tensor([12.8997, 2.9572, 2.3021, 1.8887, 5.0710, 7.3192, 3.5169, 2.4319,
0.1732, -5.3835])
tensor([ 19.2095, -15.9459, 8.3306, 11.5096, 9.5471, 0.5391, -0.3370,
8.6386, -2.5141, -30.1419])
tensor([0., 0., 0., 0., 0., 0., 0., 0., 0., 0.])
运行上面的单元格后,你应该会看到,在多次运行 loss.backward() 后,大多数梯度的幅度会大得多。如果在运行下一个训练批次之前未能将梯度归零,将导致梯度以这种方式爆炸,从而导致错误和不可预测的学习结果。
开启和关闭 Autograd¶
在某些情况下,你需要精细控制是否启用 autograd。根据情况不同,有多种方法可以做到这一点。
最简单的方法是直接更改张量上的 requires_grad 标志
tensor([[1., 1., 1.],
[1., 1., 1.]], requires_grad=True)
tensor([[2., 2., 2.],
[2., 2., 2.]], grad_fn=<MulBackward0>)
tensor([[2., 2., 2.],
[2., 2., 2.]])
在上面的单元格中,我们看到 b1 有一个 grad_fn(即跟踪的计算历史),这是我们期望的,因为它派生自一个启用了 autograd 的张量 a。当我们使用 a.requires_grad = False 显式关闭 autograd 时,计算历史不再被跟踪,正如我们在计算 b2 时所看到的。
如果你只需要暂时关闭 autograd,更好的方法是使用 torch.no_grad()
tensor([[5., 5., 5.],
[5., 5., 5.]], grad_fn=<AddBackward0>)
tensor([[5., 5., 5.],
[5., 5., 5.]])
tensor([[6., 6., 6.],
[6., 6., 6.]], grad_fn=<MulBackward0>)
torch.no_grad() 也可以用作函数或方法的装饰器
tensor([[5., 5., 5.],
[5., 5., 5.]], grad_fn=<AddBackward0>)
tensor([[5., 5., 5.],
[5., 5., 5.]])
有一个对应的上下文管理器 torch.enable_grad(),用于在 autograd 未启用时将其开启。它也可以用作装饰器。
最后,你可能有一个需要跟踪梯度的张量,但你想要一个不跟踪的副本。为此,我们可以使用 Tensor 对象的 detach() 方法 - 它会创建一个张量副本,该副本与计算历史分离。
tensor([0.0670, 0.3890, 0.7264, 0.3559, 0.6584], requires_grad=True)
tensor([0.0670, 0.3890, 0.7264, 0.3559, 0.6584])
我们之前为了绘制一些张量图时就这样做了。这是因为 matplotlib 期望输入是 NumPy 数组,而对于 requires_grad=True 的张量,PyTorch 张量到 NumPy 数组的隐式转换是未启用的。创建一个分离的副本可以让我们继续进行。
Autograd 和就地操作¶
到目前为止,此 Notebook 中的每个示例都使用了变量来捕获计算的中间值。Autograd 需要这些中间值来执行梯度计算。因此,在使用 autograd 时必须谨慎使用就地操作。这样做可能会破坏在 backward() 调用中计算导数所需的信息。如果你尝试对需要 autograd 的叶子变量执行就地操作,PyTorch 甚至会阻止你,如下所示。
注意
以下代码单元格会抛出运行时错误。这是预期结果。
a = torch.linspace(0., 2. * math.pi, steps=25, requires_grad=True)
torch.sin_(a)
Autograd 性能分析器¶
Autograd 详细跟踪你计算的每一步。这样的计算历史,结合时序信息,会是一个方便的性能分析器 - autograd 内置了这项功能。这里有一个快速使用示例
device = torch.device('cpu')
run_on_gpu = False
if torch.cuda.is_available():
device = torch.device('cuda')
run_on_gpu = True
x = torch.randn(2, 3, requires_grad=True)
y = torch.rand(2, 3, requires_grad=True)
z = torch.ones(2, 3, requires_grad=True)
with torch.autograd.profiler.profile(use_cuda=run_on_gpu) as prf:
for _ in range(1000):
z = (z / x) * y
print(prf.key_averages().table(sort_by='self_cpu_time_total'))
/var/lib/workspace/beginner_source/introyt/autogradyt_tutorial.py:485: FutureWarning:
The attribute `use_cuda` will be deprecated soon, please use ``use_device = 'cuda'`` instead.
------------------------- ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------
Name Self CPU % Self CPU CPU total % CPU total CPU time avg Self CUDA Self CUDA % CUDA total CUDA time avg # of Calls
------------------------- ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------
cudaEventRecord 54.48% 8.843ms 54.48% 8.843ms 2.211us 0.000us 0.00% 0.000us 0.000us 4000
aten::div 22.89% 3.715ms 22.89% 3.715ms 3.715us 7.605ms 50.42% 7.605ms 7.605us 1000
aten::mul 22.53% 3.656ms 22.53% 3.656ms 3.656us 7.479ms 49.58% 7.479ms 7.479us 1000
cudaDeviceSynchronize 0.10% 16.120us 0.10% 16.120us 16.120us 0.000us 0.00% 0.000us 0.000us 1
------------------------- ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------
Self CPU time total: 16.230ms
Self CUDA time total: 15.084ms
性能分析器还可以标记代码的单个子块,按输入张量形状细分数据,并将数据导出为 Chrome 追踪工具文件。有关 API 的完整详细信息,请参阅文档。
进阶主题:更多 Autograd 细节和高级 API¶
如果你有一个输入为 n 维、输出为 m 维的函数 \(\vec{y}=f(\vec{x})\),完整的梯度是一个包含每个输出对每个输入导数的矩阵,称为雅可比矩阵 (Jacobian):
如果你有第二个函数 \(l=g\left(\vec{y}\right)\),它接受 m 维输入(即与上面输出具有相同维度),并返回一个标量输出,你可以将其对 \(\vec{y}\) 的梯度表示为一个列向量 \(v=\left(\begin{array}{ccc}\frac{\partial l}{\partial y_{1}} & \cdots & \frac{\partial l}{\partial y_{m}}\end{array}\right)^{T}\) - 这实际上就是一个单列的雅可比矩阵。
更具体地说,想象第一个函数是你的 PyTorch 模型(可能有很多输入和输出),第二个函数是损失函数(以模型的输出为输入,损失值为标量输出)。
如果我们用第一个函数的雅可比矩阵乘以第二个函数的梯度,并应用链式法则,我们会得到
注意:你也可以使用等效的操作 \(v^{T}\cdot J\),得到一个行向量。
结果列向量是第二个函数对第一个函数输入的梯度 - 或者在我们模型和损失函数的情况下,是损失对模型输入的梯度。
``torch.autograd`` 是计算这些乘积的引擎。这就是我们在反向传播过程中累积学习权重上的梯度的方式。
因此,backward() 调用也可以接受一个可选的向量输入。这个向量代表一组张量上的梯度,它们将乘以先前的 autograd 跟踪张量的雅可比矩阵。让我们用一个小向量来尝试一个具体的例子
x = torch.randn(3, requires_grad=True)
y = x * 2
while y.data.norm() < 1000:
y = y * 2
print(y)
tensor([ 299.4868, 425.4009, -1082.9885], grad_fn=<MulBackward0>)
如果我们现在尝试调用 y.backward(),会得到一个运行时错误,并提示梯度只能为标量输出隐式计算。对于多维输出,autograd 期望我们提供这三个输出的梯度,以便将其乘以雅可比矩阵
v = torch.tensor([0.1, 1.0, 0.0001], dtype=torch.float) # stand-in for gradients
y.backward(v)
print(x.grad)
tensor([1.0240e+02, 1.0240e+03, 1.0240e-01])
(注意,输出梯度都与 2 的幂有关 - 这是重复加倍操作的预期结果。)
高级 API¶
autograd 上有一个 API,可以让你直接访问重要的微分矩阵和向量操作。特别是,它允许你计算特定函数在特定输入下的雅可比矩阵和海森矩阵 (Hessian)。(海森矩阵类似于雅可比矩阵,但表示所有偏二阶导数。)它还提供了计算与这些矩阵的向量乘积的方法。
让我们计算一个简单函数在两个单元素输入下的雅可比矩阵
def exp_adder(x, y):
return 2 * x.exp() + 3 * y
inputs = (torch.rand(1), torch.rand(1)) # arguments for the function
print(inputs)
torch.autograd.functional.jacobian(exp_adder, inputs)
(tensor([0.7212]), tensor([0.2079]))
(tensor([[4.1137]]), tensor([[3.]]))
仔细观察,第一个输出应该等于 \(2e^x\) (因为 \(e^x\) 的导数就是 \(e^x\)),第二个值应该为 3。
当然,你可以使用高阶张量来执行此操作
inputs = (torch.rand(3), torch.rand(3)) # arguments for the function
print(inputs)
torch.autograd.functional.jacobian(exp_adder, inputs)
(tensor([0.2080, 0.2604, 0.4415]), tensor([0.5220, 0.9867, 0.4288]))
(tensor([[2.4623, 0.0000, 0.0000],
[0.0000, 2.5950, 0.0000],
[0.0000, 0.0000, 3.1102]]), tensor([[3., 0., 0.],
[0., 3., 0.],
[0., 0., 3.]]))
方法 torch.autograd.functional.hessian() 的工作方式相同(假设你的函数是二次可微的),但返回所有二阶导数的矩阵。
如果你提供了向量,还有一个函数可以直接计算向量-雅可比积
def do_some_doubling(x):
y = x * 2
while y.data.norm() < 1000:
y = y * 2
return y
inputs = torch.randn(3)
my_gradients = torch.tensor([0.1, 1.0, 0.0001])
torch.autograd.functional.vjp(do_some_doubling, inputs, v=my_gradients)
(tensor([-665.7186, -866.7054, -58.4194]), tensor([1.0240e+02, 1.0240e+03, 1.0240e-01]))
方法 torch.autograd.functional.jvp() 执行与 vjp() 相同的矩阵乘法,只是操作数顺序颠倒。方法 vhp() 和 hvp() 对向量-Hessian 积执行相同的操作。
有关更多信息,包括函数式 API 文档中的性能说明,请参阅 函数式高级 API 文档
脚本总运行时间: ( 0 分钟 0.519 秒)
