


Libuv TCPStore 后端入门¶
创建于: Jul 22, 2024 | 最后更新于: Jul 24, 2024 | 最后验证于: Nov 05, 2024
作者: Xilun Wu
注意
 在 github 查看并编辑此教程。
在 github 查看并编辑此教程。
新的 TCPStore 后端是什么
比较新的 libuv 后端与传统后端
如何启用使用传统后端
PyTorch 2.4 或更高版本
阅读关于 TCPStore API 的文档。
引言¶
最近,我们推出了一个使用 libuv(一个用于异步 I/O 的第三方库)的新 TCPStore 服务器后端。这个新的服务器后端旨在解决大规模分布式训练作业(例如超过 1024 个 rank 的作业)中的可伸缩性和鲁棒性挑战。我们进行了一系列基准测试,比较了 libuv 后端与旧后端,实验结果表明在存储初始化时间方面有显著改进,并且在存储 I/O 操作中保持了可比的性能。
基于这些发现,libuv 后端在 PyTorch 2.4 中被设置为默认的 TCPStore 服务器后端。这一更改预计将增强分布式训练作业的性能和可伸缩性。
这一更改给存储初始化带来了一些轻微的不兼容性。对于希望继续使用传统后端的用户,本教程将提供如何指定使用以前的 TCPStore 服务器后端的指导。
性能基准测试¶
为了更好地展示我们新的 libuv TCPStore 后端的优势,我们在一系列广泛的作业规模上设置了基准测试,从 1024 (1K) 个 rank 到 98304 (96K) 个 rank。我们首先使用以下代码片段测量了 TCPStore 初始化时间
import logging
import os
from time import perf_counter
import torch
import torch.distributed as dist
logger: logging.Logger = logging.getLogger(__name__)
# Env var are preset when launching the benchmark
env_rank = os.environ.get("RANK", 0)
env_world_size = os.environ.get("WORLD_SIZE", 1)
env_master_addr = os.environ.get("MASTER_ADDR", "localhost")
env_master_port = os.environ.get("MASTER_PORT", "23456")
start = perf_counter()
tcp_store = dist.TCPStore(
env_master_addr,
int(env_master_port),
world_size=int(env_world_size),
is_master=(int(env_rank) == 0),
)
end = perf_counter()
time_elapsed = end - start
logger.info(
f"Complete TCPStore init with rank={env_rank}, world_size={env_world_size} in {time_elapsed} seconds."
)
由于 TCPStore 服务器线程的执行会一直阻塞直到所有客户端成功连接,我们将 rank 0 上测量的时间作为总的 TCPStore 初始化运行时。实验数据如下图所示
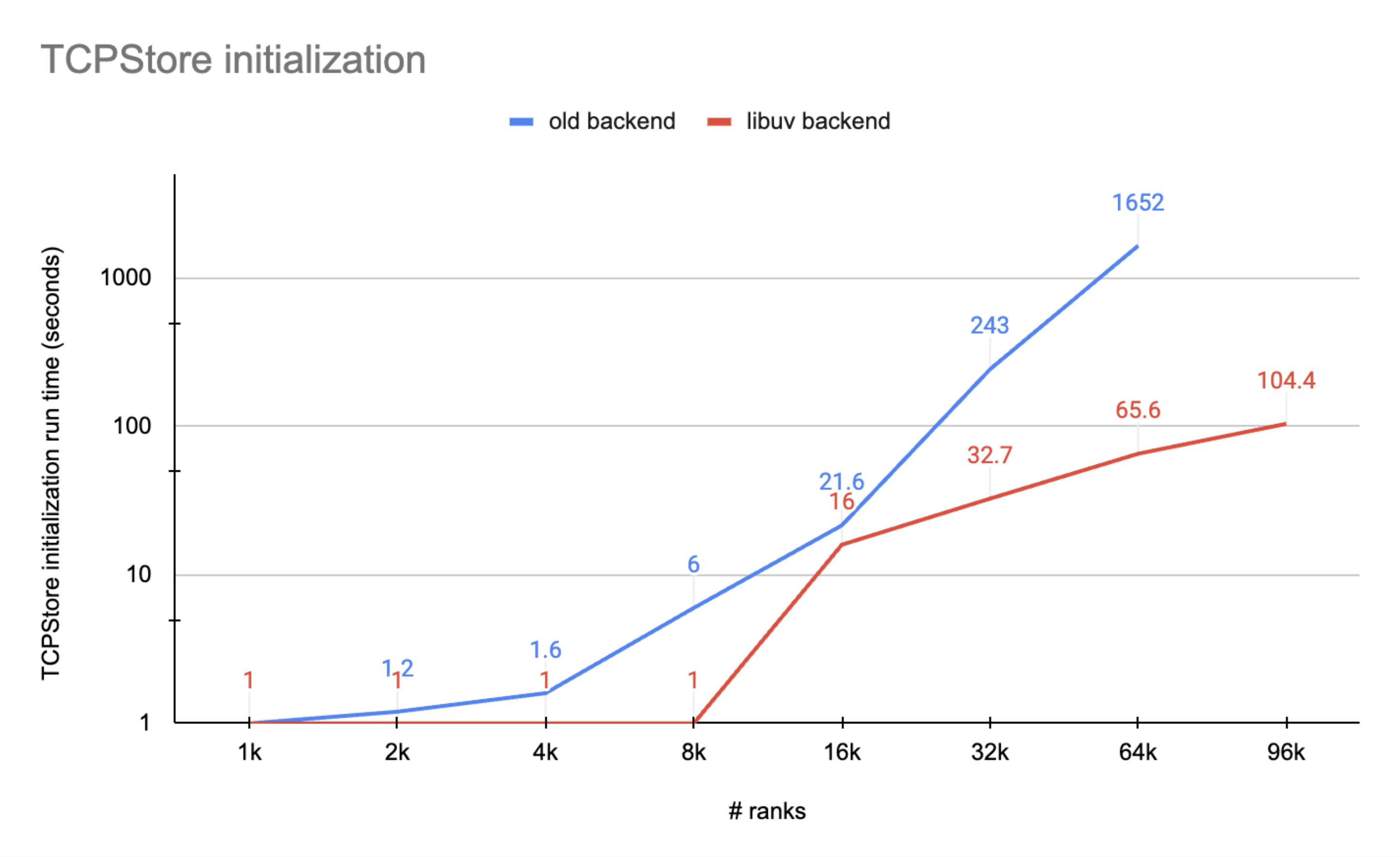
图 1. 显示了一些重要证据,表明 libuv 后端优于传统后端
使用 libuv 后端的 TCPStore 初始化速度总是比传统后端更快,尤其是在超大规模下
传统后端在 96K 规模下(例如,超过 30 分钟)的服务器-客户端连接会超时,而 libuv 后端在 100 秒内完成了初始化。
我们进行的第二个基准测试是测量 TCPStore store_based_barrier 操作的运行时
import logging
import os
import time
from datetime import timedelta
from time import perf_counter
import torch
import torch.distributed as dist
DistStoreError = torch._C._DistStoreError
logger: logging.Logger = logging.getLogger(__name__)
# since dist._store_based_barrier is a private function and cannot be directly called, we need to write a function which does the same
def store_based_barrier(
rank,
store,
group_name,
rendezvous_count,
timeout=dist.constants.default_pg_timeout,
logging_interval=timedelta(seconds=10),
):
store_key = f"store_based_barrier_key:{group_name}"
store.add(store_key, 1)
world_size = rendezvous_count
worker_count = store.add(store_key, 0)
last_worker_key = f"{store_key}:last_worker"
if worker_count == world_size:
store.set(last_worker_key, "1")
start = time.time()
while True:
try:
# This will throw an exception after the logging_interval in which we print out
# the status of the group or time out officially, throwing runtime error
store.wait([last_worker_key], logging_interval)
break
except RuntimeError as e:
worker_count = store.add(store_key, 0)
# Print status periodically to keep track.
logger.info(
"Waiting in store based barrier to initialize process group for "
"rank: %s, key: %s (world_size=%s, num_workers_joined=%s, timeout=%s)"
"error: %s",
rank,
store_key,
world_size,
worker_count,
timeout,
e,
)
if timedelta(seconds=(time.time() - start)) > timeout:
raise DistStoreError(
"Timed out initializing process group in store based barrier on "
"rank {}, for key: {} (world_size={}, num_workers_joined={}, timeout={})".format(
rank, store_key, world_size, worker_count, timeout
)
)
logger.info(
"Rank %s: Completed store-based barrier for key:%s with %s nodes.",
rank,
store_key,
world_size,
)
# Env var are preset when launching the benchmark
env_rank = os.environ.get("RANK", 0)
env_world_size = os.environ.get("WORLD_SIZE", 1)
env_master_addr = os.environ.get("MASTER_ADDR", "localhost")
env_master_port = os.environ.get("MASTER_PORT", "23456")
tcp_store = dist.TCPStore(
env_master_addr,
int(env_master_port),
world_size=int(env_world_size),
is_master=(int(env_rank) == 0),
)
# sync workers
store_based_barrier(int(env_rank), tcp_store, "tcpstore_test", int(env_world_size))
number_runs = 10
start = perf_counter()
for _ in range(number_runs):
store_based_barrier(
int(env_rank), tcp_store, "tcpstore_test", int(env_world_size)
)
end = perf_counter()
time_elapsed = end - start
logger.info(
f"Complete {number_runs} TCPStore barrier runs with rank={env_rank}, world_size={env_world_size} in {time_elapsed} seconds."
)
我们通过将 rank 0 上测量的运行时除以 number_runs 计算平均值,并在下图中报告
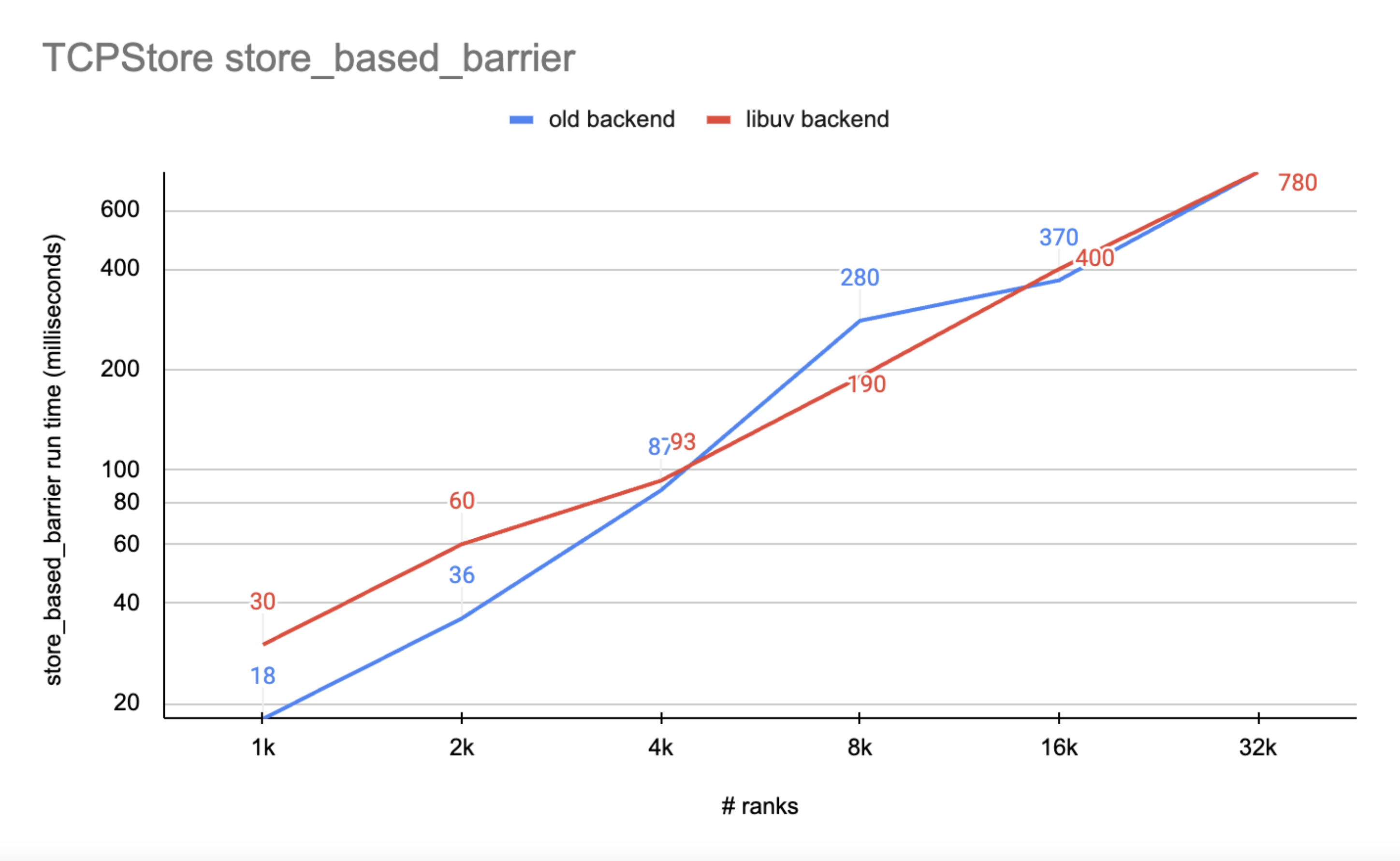
图 2. 显示 libuv 后端的 I/O 性能与传统后端可比
就 rank 数量而言,libuv 后端在整个范围内的性能与传统后端可比
随着 rank 数量的增长,libuv 后端的运行时比传统后端更稳定
影响¶
用户可能需要注意的一个不兼容性是,使用 libuv 后端时,TCPStore 当前不支持使用 listen_fd 进行初始化。如果用户希望继续使用这种初始化方法,只需传递 use_libuv=False 即可继续使用旧的 TCPStore 后端。
import socket
import torch
import torch.distributed as dist
listen_sock: socket.socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
listen_sock.bind(("localhost", 0))
addr, port, *_ = listen_sock.getsockname()
listen_fd = listen_sock.detach()
tcpstore = dist.TCPStore(addr, port, 1, True, master_listen_fd=listen_fd) # expect NotImplementedError
tcpstore = dist.TCPStore(addr, port, 1, True, master_listen_fd=listen_fd, use_libuv=False) # OK. Use legacy backend
退出路径 1:在 TCPStore 初始化时传递 use_libuv=False¶
如上述代码片段所示,如果用户调用 TCPStore init 方法创建存储,只需传递 use_libuv=False 即可继续使用旧的 TCPStore 后端。这种覆盖方式具有最高优先级,高于其他决定 TCPStore 服务器应选择哪个后端的方法。
退出路径 2:在 ProcessGroup 初始化时向 init_method 添加 use_libuv=0¶
如果用户在初始化时没有显式传递 TCPStore,ProcessGroup 会创建一个 TCPStore。用户可以在初始化 ProcessGroup 时向 init_method 添加查询选项 use_libuv=0。此方法的优先级低于退出路径 1。
import torch
import torch.distributed as dist
addr = "localhost"
port = 23456
dist.init_process_group(
backend="cpu:gloo,cuda:nccl",
rank=0,
world_size=1,
init_method=f"tcp://{addr}:{port}?use_libuv=0",
)
dist.destroy_process_group()
退出路径 3:将环境变量 USE_LIBUV 设置为 0¶
当 ProcessGroup 创建 TCPStore 时,它也会检查环境变量 USE_LIBUV 以确定使用哪个 TCPStore 后端。用户可以将环境变量 "USE_LIBUV" 设置为 "0" 来指定使用旧的 TCPStore 后端。此方法的优先级低于退出路径 2,例如,如果用户将环境变量 USE_LIBUV 设置为 1,同时在 init_method 中传递 use_libuv=0,则会选择旧的存储后端。
import os
import torch
import torch.distributed as dist
addr = "localhost"
port = 23456
os.environ["USE_LIBUV"] = "0"
dist.init_process_group(
backend="cpu:gloo,cuda:nccl",
rank=0,
world_size=1,
init_method=f"tcp://{addr}:{port}",
)
dist.destroy_process_group()
结论¶
在 PyTorch 2.4 中,我们将新的 libuv TCPStore 后端设置为默认。虽然新后端与从 listen_fd 初始化不兼容,但在大规模下,它在存储初始化方面显示出显著的性能提升,并且在小/中/大规模下的存储 I/O 性能与传统后端兼容,这为分布式训练的控制平面带来了主要优势。本教程解释了我们的动机,回顾了性能基准测试,通知了用户潜在的影响,并介绍了三个退出路径以继续使用传统后端。从长远来看,我们的目标是最终弃用传统后端。
