


使用张量并行 (TP) 训练大规模 Transformer 模型¶
创建于:2024 年 4 月 19 日 | 最后更新于:2024 年 8 月 19 日 | 最后验证于:2024 年 11 月 5 日
注意
 在 github 查看和编辑本教程。
在 github 查看和编辑本教程。
本教程演示了如何使用张量并行和 Fully Sharded Data Parallel 跨数百到数千个 GPU 训练大型类 Transformer 模型。
先决条件
已安装 PyTorch 2.3.0 或更高版本(含 CUDA/Linux)
张量并行是如何工作的?¶
张量并行 (TP) 最初在 Megatron-LM 论文中提出,它是一种用于训练大规模 Transformer 模型的高效模型并行技术。本教程中提到的序列并行 (SP) 是张量并行的一种变体,它在序列维度上对 nn.LayerNorm 或 RMSNorm 进行分片,以在训练期间进一步节省激活内存。随着模型变大,激活内存成为瓶颈,因此在张量并行训练中,通常将序列并行应用于 LayerNorm 或 RMSNorm 层。
概括来说,PyTorch 张量并行的工作原理如下
分片初始化
确定将哪种
ParallelStyle应用于每一层,并通过调用parallelize_module对初始化后的模块进行分片。并行化后的模块将把其模型参数替换为 DTensors,DTensor 将负责使用分片计算运行并行化后的模块。
运行时前向/反向传播
根据用户为每种
ParallelStyle指定的输入/输出 DTensor 布局,它将运行适当的通信操作来转换输入/输出的 DTensor 布局(例如allreduce、allgather和reduce_scatter)。为并行化的层运行分片计算,以节省计算/内存(例如,
nn.Linear、nn.Embedding)。
何时以及为何应该应用张量并行¶
PyTorch Fully Sharded Data Parallel (FSDP) 已经具备将模型训练扩展到一定数量 GPU 的能力。然而,当需要根据模型大小和 GPU 数量进一步扩展模型训练时,会出现许多额外的挑战,这可能需要将张量并行与 FSDP 结合使用。
随着全局规模(GPU 数量)变得过大(超过 128/256 个 GPU),FSDP 集体操作(如
allgather)将受到环形延迟的主导。通过在 FSDP 之上实现 TP/SP,并且仅在主机间应用 FSDP,FSDP 全局规模可以减少 8 倍,从而将延迟成本降低相同幅度。达到数据并行限制,由于收敛和 GPU 内存限制,你无法将全局批大小提高到超过 GPU 数量,此时张量/序列并行是唯一已知的方法来“粗略估计”全局批大小并继续使用更多 GPU 进行扩展。这意味着模型大小和 GPU 数量都可以继续扩展。
对于某些类型的模型,当本地批大小变小时,TP/SP 可以产生更适合浮点运算 (FLOPS) 的矩阵乘法形状。
那么,在预训练时,达到这些限制有多容易?截至目前,预训练一个包含数十亿或数万亿个 token 的大型语言模型 (LLM) 可能需要数月时间,即使使用数千个 GPU。
在大规模训练 LLM 时,总是会达到限制 1。例如,Llama 2 70B 使用 2k 个 GPU 训练了 35 天,在 2k 规模下需要多维并行。
当 Transformer 模型变得更大(例如 Llama2 70B)时,它也将很快达到限制 2。由于内存和收敛性限制,即使本地
batch_size=1,也无法仅使用 FSDP。例如,Llama 2 的全局批大小为 1K,因此在 2K 个 GPU 下无法单独使用数据并行。
如何应用张量并行¶
PyTorch 张量并行 API 提供了一组模块级原语 (ParallelStyle),用于配置模型每个独立层的分片,包括:
ColwiseParallel和RowwiseParallel:以列或行的方式对nn.Linear和nn.Embedding进行分片。SequenceParallel:对nn.LayerNorm、nn.Dropout、RMSNormPython等执行分片计算。PrepareModuleInput和PrepareModuleOutput:使用适当的通信操作配置模块输入/输出的分片布局。
为了演示如何使用 PyTorch 原生张量并行 API,让我们看一个常见的 Transformer 模型。在本教程中,我们使用最新的 Llama2 模型作为参考 Transformer 模型实现,因为它也在社区中广泛使用。
由于张量并行在一组设备上分片单个张量,因此我们首先需要设置分布式环境(例如 NCCL 通信器)。张量并行是一种类似于 PyTorch DDP/FSDP 的单程序多数据 (SPMD) 分片算法,它在底层利用 PyTorch DTensor 来执行分片。它还利用 DeviceMesh 抽象(在底层管理 ProcessGroups)进行设备管理和分片。要了解如何利用 DeviceMesh 设置多维并行,请参考本教程。张量并行通常在每个主机内部工作,因此我们首先初始化一个连接一个主机内 8 个 GPU 的 DeviceMesh。
from torch.distributed.device_mesh import init_device_mesh
tp_mesh = init_device_mesh("cuda", (8,))
现在我们已经初始化了 DeviceMesh,让我们详细了解 Llama 2 模型架构,并看看我们应该如何执行张量并行分片。这里我们重点关注核心 TransformerBlock,Transformer 模型通过堆叠相同的 TransformerBlock 来扩大模型规模。
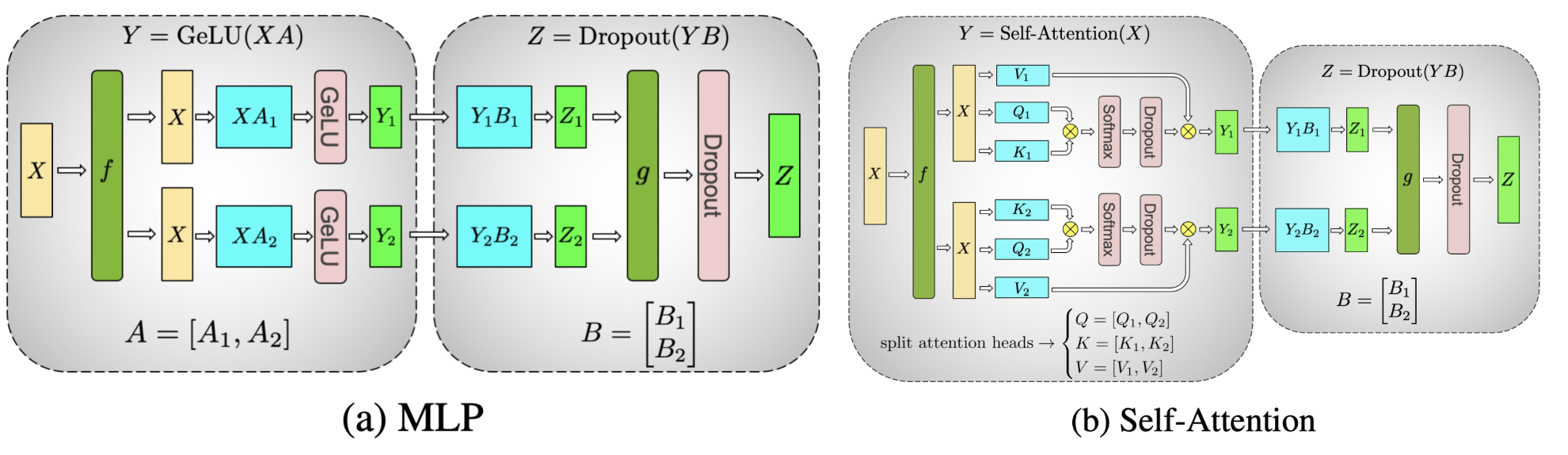
核心 TransformerBlock 由一个 Attention 层和一个 FeedForward 层组成。让我们首先看看更简单的 FeedForward 层。对于 FeedForward 层,它由三个 Linear 层组成,执行 SwiGLU 风格的 MLP。查看其前向传播函数:
# forward in the FeedForward layer
def forward(self, x):
return self.w2(F.silu(self.w1(x)) * self.w3(x))
它同时执行 w1 和 w3 的矩阵乘法,然后与 w2 执行矩阵乘法,使用组合 w1/w3 线性投影的结果。这意味着我们可以使用张量并行论文中的想法,以列的方式分片 w1/w3 Linear 层,并以行的方式分片 w2 Linear 层,从而在所有这三个层的末端仅发生一次 allreduce 通信。使用 PyTorch 原生张量并行,我们可以像下面这样为 FeedForward 层简单地创建一个 parallelize_plan:
from torch.distributed.tensor.parallel import ColwiseParallel, RowwiseParallel, parallelize_module
layer_tp_plan = {
# by default ColwiseParallel input layouts is replicated
# and RowwiseParallel output layouts is replicated
"feed_foward.w1": ColwiseParallel(),
"feed_forward.w2": RowwiseParallel(),
"feed_forward.w3": ColwiseParallel(),
}
这就是我们使用 PyTorch 张量并行 API 配置 FeedForward 层分片的方式。请注意,用户只需要指定如何对单个层进行分片,通信(例如 allreduce)将在底层自动发生。
接下来是 Attention 层。它包含 wq、wk、wv Linear 层,将输入投影到 q/k/v,然后使用 wo Linear 层执行注意力计算和输出投影。这里的张量并行旨在对 q/k/v 投影进行列式分片,并对 wo 线性投影进行行式分片。所以我们可以将 Attention 计划添加到我们刚刚起草的 tp_plan 中:
layer_tp_plan = {
# by default ColwiseParallel input layouts is replicated
# and RowwiseParallel output layouts is replicated
"attention.wq": ColwiseParallel(),
"attention.wk": ColwiseParallel(),
"attention.wv": ColwiseParallel(),
"attention.wo": RowwiseParallel(),
"feed_forward.w1": ColwiseParallel(),
"feed_forward.w2": RowwiseParallel(),
"feed_forward.w3": ColwiseParallel(),
}
这几乎就是我们需要应用于 TransformerBlock 以实现张量并行的 layer_tp_plan。然而,我们需要注意一点:当对线性层进行列式分片时,线性层的输出将在最后一个张量维度上变成 sharded,而行式分片线性层直接接受一个在最后一个维度上进行分片的输入。如果在列式线性层和行式线性层之间存在任何其他的张量操作(例如 view 操作),我们需要将相关的形状相关操作调整为分片后的形状。
对于 Llama 模型,在注意力层中有几个与形状相关的 view 操作。特别是对于 wq/wk/wv 线性层的列式并行,激活张量在 num_heads 维度上进行分片,因此我们需要将 num_heads 调整为本地的 num_heads。
最后,我们需要调用 parallelize_module API,使每个 TransformerBlock 的计划生效。在底层,它将 Attention 和 FeedForward 层内部的模型参数分发到 DTensors,并在需要时注册模型输入和输出(分别在每个模块之前和之后)的通信钩子。
for layer_id, transformer_block in enumerate(model.layers):
layer_tp_plan = {...} # i.e. the plan we just generated
# Adjust attention module to use the local number of heads
attn_layer = transformer_block.attention
attn_layer.n_heads = attn_layer.n_heads // tp_mesh.size()
attn_layer.n_kv_heads = attn_layer.n_kv_heads // tp_mesh.size()
parallelize_module(
module=transformer_block,
device_mesh=tp_mesh,
parallelize_plan=layer_tp_plan,
)
现在我们已经详细阐述了每个 TransformerBlock 的分片计划,通常在第一层有一个 nn.Embedding 和一个最终的 nn.Linear 投影层,用户可以选择对第一个 nn.Embedding 进行行式或列式分片,并对最后一个 nn.Linear 投影层进行列式分片,同时指定适当的输入和输出布局。这是一个示例:
model = parallelize_module(
model,
tp_mesh,
{
"tok_embeddings": RowwiseParallel(
input_layouts=Replicate(),
),
"output": ColwiseParallel(
output_layouts=Replicate(),
),
}
)
注意
如果要分区的模型太大,无法放入 CPU 内存,可以使用 meta 设备初始化(例如,首先在 meta 设备上初始化模型,然后对层进行分片,最后实例化模型),或者在 Transformer 模型初始化期间逐层并行化 TransformerBlock。
将序列并行应用于 LayerNorm/RMSNorm 层¶
序列并行工作在上述张量并行之上。与基本的张量并行相比(它只在 Attention 模块和 FeedForward 模块内分片张量,并保持其模块输入和输出(即前向传播中的激活和反向传播中的梯度)是复制的),序列并行将它们在序列维度上进行分片。
在典型的 TransformerBlock 中,前向传播函数结合了范数层(LayerNorm 或 RMSNorm)、一个注意力层、一个前馈层和残差连接。例如:
# forward in a TransformerBlock
def forward(self, x):
h = x + self.attention(self.attention_norm(x))
out = h + self.feed_forward(self.ffn_norm(h))
return out
在大多数使用场景中,激活(和梯度)在 Attention 和 FeedForward 模块外部的形状是 [batch size, sequence length, hidden dimension]。用 DTensor 的语言来说,序列并行使用 Shard(1) 布局执行模块前向/反向传播的激活计算。遵循之前的代码示例,下面的代码演示了如何在 TransformerBlock 中将序列并行应用于范数层:
首先导入序列并行所需的依赖:
from torch.distributed.tensor.parallel import (
PrepareModuleInput,
SequenceParallel,
)
接下来调整 layer_tp_plan,在 RMSNorm 层上启用序列并行:
layer_tp_plan = {
# Now the input and output of SequenceParallel has Shard(1) layouts,
# to represent the input/output tensors sharded on the sequence dimension
"attention_norm": SequenceParallel(),
"attention": PrepareModuleInput(
input_layouts=(Shard(1),),
desired_input_layouts=(Replicate(),),
),
"attention.wq": ColwiseParallel(),
"attention.wk": ColwiseParallel(),
"attention.wv": ColwiseParallel(),
"attention.wo": RowwiseParallel(output_layouts=Shard(1)),
"ffn_norm": SequenceParallel(),
"feed_forward": PrepareModuleInput(
input_layouts=(Shard(1),),
desired_input_layouts=(Replicate(),),
),
"feed_forward.w1": ColwiseParallel(),
"feed_forward.w2": RowwiseParallel(output_layouts=Shard(1)),
"feed_forward.w3": ColwiseParallel(),
}
可以看到,我们现在使用 PrepareModuleInput 将 Attention 和 FeedForward 层的模块输入布局从 Shard(1) 修改为 Replicate(),并将其输出布局标记为 Shard(1)。就像张量并行一样,只需指定输入和输出的张量分片布局,层之间的通信将自动发生。
请注意,使用序列并行时,我们假定 TransformerBlock 的输入和输出始终在序列维度上进行分片,以便多个 TransformerBlock 可以无缝地连接在一起。这可以通过明确指定起始 nn.Embedding 层的输出和最终 nn.Linear 投影层的输入为 Shard(1) 来实现。
model = parallelize_module(
model,
tp_mesh,
{
"tok_embeddings": RowwiseParallel(
input_layouts=Replicate(),
output_layouts=Shard(1),
),
"norm": SequenceParallel(),
"output": ColwiseParallel(
input_layouts=Shard(1),
output_layouts=Replicate()
),
}
)
应用损失并行¶
损失并行是一种相关的技术,用于在计算损失函数时节省内存和通信,因为模型输出通常非常大。在损失并行中,当模型输出在(通常巨大的)词汇维度上进行分片时,可以高效地计算交叉熵损失,而无需将所有模型输出收集到每个 GPU。这不仅显著降低了内存消耗,而且通过减少通信开销和并行执行分片计算来提高训练速度。下图简要说明了损失并行如何通过执行分片计算来避免将所有模型输出收集到每个 GPU。
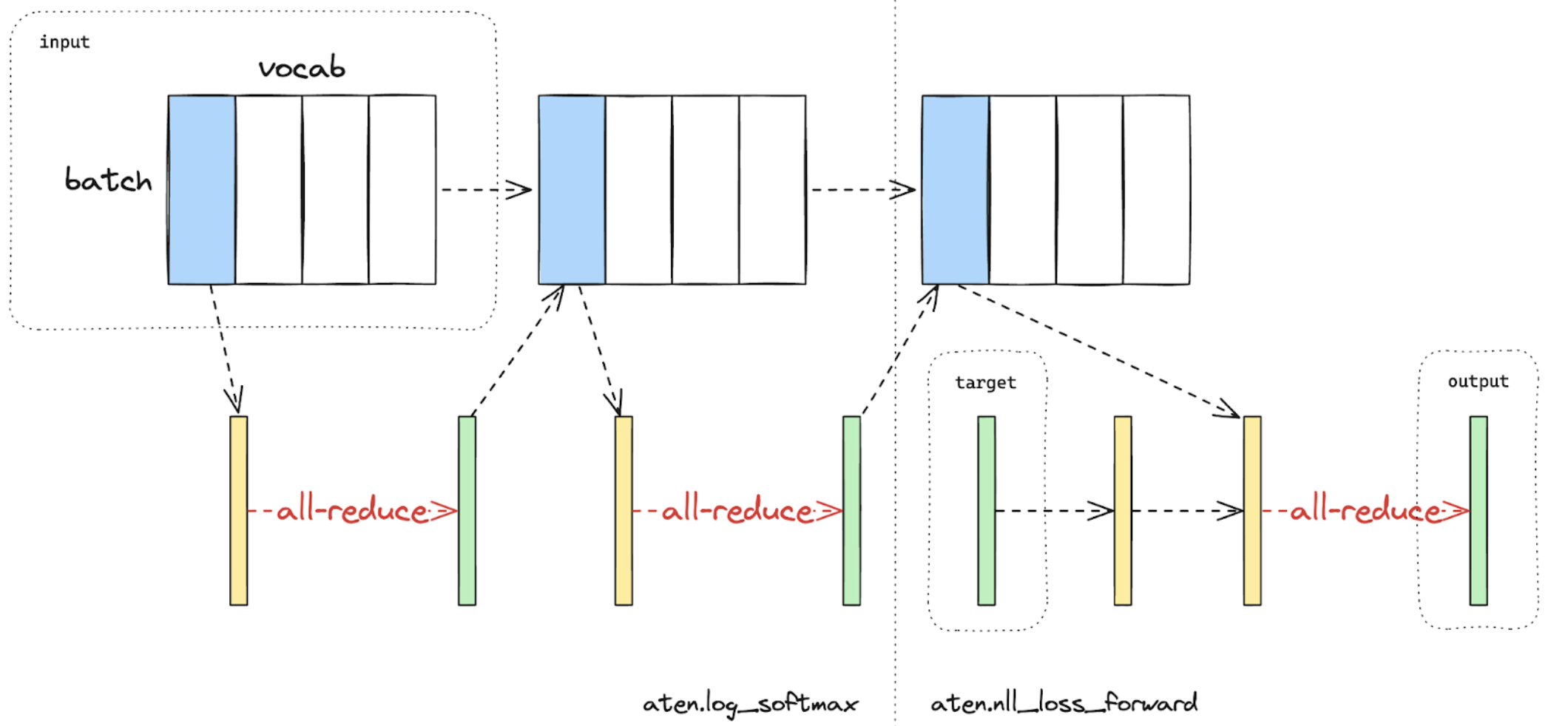
图 2. 在一个 GPU 上使用损失并行计算交叉熵损失的前向传播。蓝色表示分片张量;绿色表示复制张量;黄色表示具有部分值(待 all-reduce)的张量。黑色箭头表示本地计算;红色箭头表示 GPU 之间的函数式集合操作。¶
在 PyTorch 张量并行 API 中,可以通过上下文管理器 loss_parallel 启用损失并行,有了它,可以直接使用 torch.nn.functional.cross_entropy 或 torch.nn.CrossEntropyLoss,而无需修改代码的其他部分。
要应用损失并行,模型预测结果(通常形状为 [batch size, sequence length, vocabulary size])应该在词汇维度上进行分片。这可以通过标记最后一个线性投影层输出的布局来轻松完成:
model = parallelize_module(
model,
tp_mesh,
{
"tok_embeddings": RowwiseParallel(
input_layouts=Replicate(),
output_layouts=Shard(1),
),
"norm": SequenceParallel(),
"output": ColwiseParallel(
input_layouts=Shard(1),
# use DTensor as the output
use_local_output=False,
),
},
)
在上面的代码中,我们还对输出前的范数层应用了序列并行。我们应用 use_local_output=False,让输出保持为 DTensor,以便与 loss_parallel 上下文管理器一起工作。之后,可以简单地调用交叉熵损失函数,如下所示。请注意,反向计算也需要在该上下文内发生。
import torch.nn.functional as F
from torch.distributed.tensor.parallel import loss_parallel
pred = model(input_ids)
with loss_parallel():
# assuming pred and labels are of the shape [batch, seq, vocab]
loss = F.cross_entropy(pred.flatten(0, 1), labels.flatten(0, 1))
loss.backward()
将张量并行与 Fully Sharded Data Parallel 结合使用¶
现在我们已经展示了如何将张量/序列并行应用于模型,接下来我们也看看张量并行和完全分片数据并行如何协同工作。由于张量并行会产生阻塞计算的通信开销,我们希望确保它在快速通信通道(例如 NVLink)中运行。在实践中,我们通常在每个主机内应用张量并行,并在主机间应用完全分片数据并行。
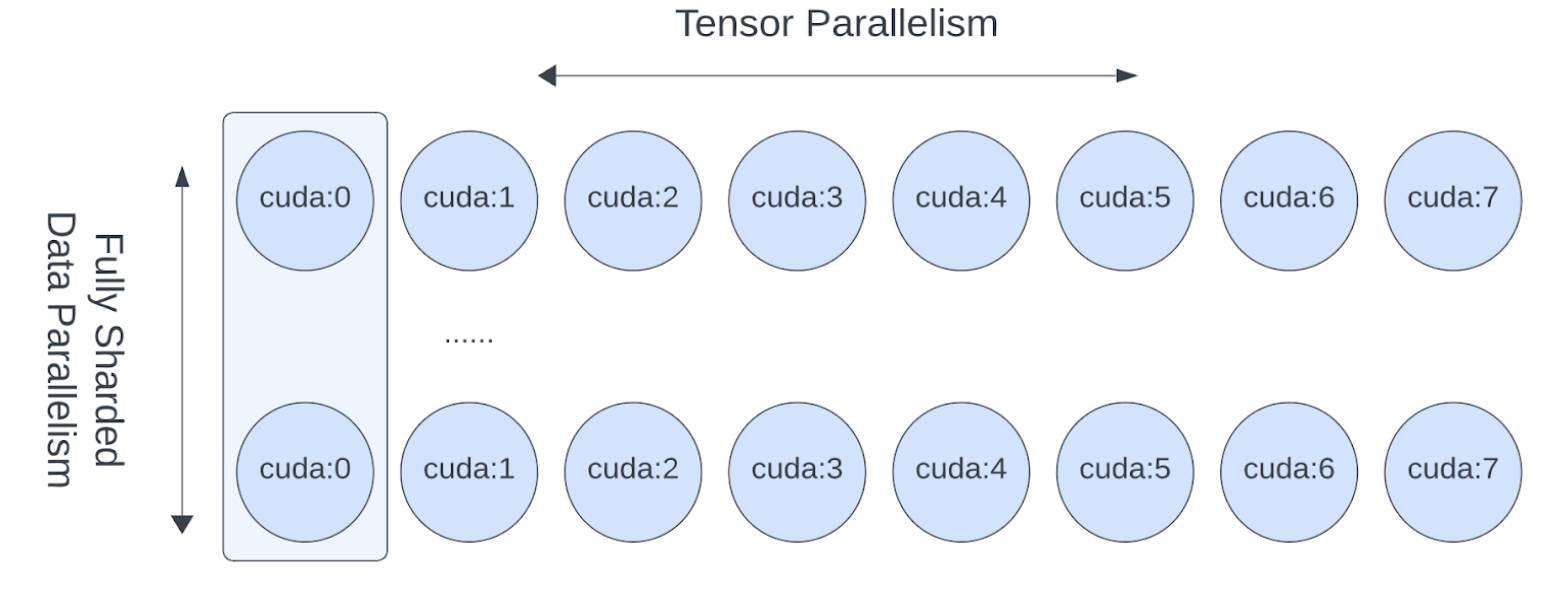
图 3. FSDP 和 TP 在不同的设备维度上工作,FSDP 通信发生在主机间,TP 通信发生在主机内。¶
这种二维并行模式可以通过二维设备网格(2-D DeviceMesh)轻松表达,我们只需要将每个“子”设备网格传递给各个并行 API。
from torch.distributed.device_mesh import init_device_mesh
from torch.distributed.tensor.parallel import ColwiseParallel, RowwiseParallel, parallelize_module
from torch.distributed.fsdp import FullyShardedDataParallel as FSDP
# i.e. 2-D mesh is [dp, tp], training on 64 GPUs that performs 8 way DP and 8 way TP
mesh_2d = init_device_mesh("cuda", (8, 8))
tp_mesh = mesh_2d["tp"] # a submesh that connects intra-host devices
dp_mesh = mesh_2d["dp"] # a submesh that connects inter-host devices
model = Model(...)
tp_plan = {...}
# apply Tensor Parallel intra-host on tp_mesh
model_tp = parallelize_module(model, tp_mesh, tp_plan)
# apply FSDP inter-host on dp_mesh
model_2d = FSDP(model_tp, device_mesh=dp_mesh, use_orig_params=True, ...)
这使得我们可以轻松地在每个主机内(主机内)应用张量并行,并在主机间(主机间)应用 FSDP,而且对 Llama 模型无需进行任何代码修改。张量(模型)并行和数据并行技术的结合提供了继续增加模型大小以及利用大量 GPU 进行高效训练的能力。
