


使用 PyTorch 编写分布式应用程序¶
创建时间:2017 年 10 月 06 日 | 最后更新时间:2025 年 02 月 20 日 | 最后验证时间:2024 年 11 月 05 日
作者:Séb Arnold
注意
 在 github 上查看和编辑此教程。
在 github 上查看和编辑此教程。
先决条件
在这个简短的教程中,我们将回顾 PyTorch 的分布式包。我们将了解如何设置分布式环境,使用不同的通信策略,并探讨包的一些内部机制。
设置¶
PyTorch 中包含的分布式包(即 torch.distributed)使研究人员和实践者能够轻松地跨进程和机器集群并行化计算。为此,它利用消息传递语义,允许每个进程与其他任何进程通信数据。与多进程 (torch.multiprocessing) 包不同,进程可以使用不同的通信后端,并且不局限于在同一台机器上执行。
为了开始使用,我们需要能够同时运行多个进程。如果你有计算集群的访问权限,你应该咨询你的本地系统管理员或使用你喜欢的协调工具(例如,pdsh、clustershell 或 slurm)。出于本教程的目的,我们将使用单台机器并使用以下模板生成多个进程。
"""run.py:"""
#!/usr/bin/env python
import os
import sys
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
def run(rank, size):
""" Distributed function to be implemented later. """
pass
def init_process(rank, size, fn, backend='gloo'):
""" Initialize the distributed environment. """
os.environ['MASTER_ADDR'] = '127.0.0.1'
os.environ['MASTER_PORT'] = '29500'
dist.init_process_group(backend, rank=rank, world_size=size)
fn(rank, size)
if __name__ == "__main__":
world_size = 2
processes = []
if "google.colab" in sys.modules:
print("Running in Google Colab")
mp.get_context("spawn")
else:
mp.set_start_method("spawn")
for rank in range(world_size):
p = mp.Process(target=init_process, args=(rank, world_size, run))
p.start()
processes.append(p)
for p in processes:
p.join()
上面的脚本会生成两个进程,它们将各自设置分布式环境,初始化进程组 (dist.init_process_group),并最终执行给定的 run 函数。
让我们看看 init_process 函数。它确保每个进程都能通过一个主节点协调,使用相同的 IP 地址和端口。请注意,我们使用了 gloo 后端,但还有其他后端可用。(参见 第 5.1 节)我们将在本教程的最后介绍 dist.init_process_group 中的“魔法”,但它本质上是通过共享进程位置来实现彼此通信。
点对点通信¶
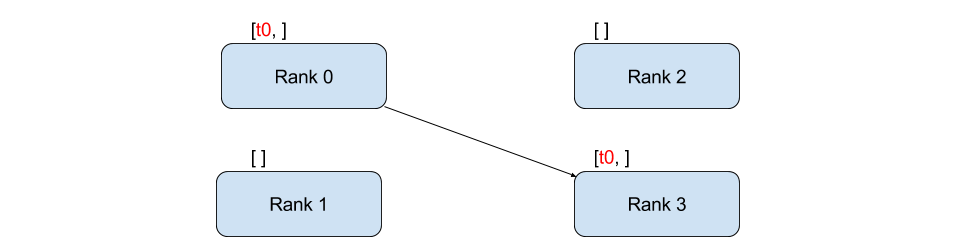
发送和接收 (Send and Recv)¶
数据从一个进程传输到另一个进程称为点对点通信。这可以通过 send 和 recv 函数或其立即对应的 isend 和 irecv 函数来实现。
"""Blocking point-to-point communication."""
def run(rank, size):
tensor = torch.zeros(1)
if rank == 0:
tensor += 1
# Send the tensor to process 1
dist.send(tensor=tensor, dst=1)
else:
# Receive tensor from process 0
dist.recv(tensor=tensor, src=0)
print('Rank ', rank, ' has data ', tensor[0])
在上面的示例中,两个进程都以一个零张量开始,然后进程 0 增加该张量并将其发送给进程 1,以便它们都最终得到 1.0。请注意,进程 1 需要分配内存来存储它将接收的数据。
还要注意 send/recv 是阻塞的:两个进程都会阻塞直到通信完成。另一方面,立即操作是非阻塞的;脚本继续执行,方法返回一个 Work 对象,我们可以选择对其调用 wait()。
"""Non-blocking point-to-point communication."""
def run(rank, size):
tensor = torch.zeros(1)
req = None
if rank == 0:
tensor += 1
# Send the tensor to process 1
req = dist.isend(tensor=tensor, dst=1)
print('Rank 0 started sending')
else:
# Receive tensor from process 0
req = dist.irecv(tensor=tensor, src=0)
print('Rank 1 started receiving')
req.wait()
print('Rank ', rank, ' has data ', tensor[0])
使用立即操作时,我们必须谨慎使用发送和接收的张量。由于我们不知道数据何时会传输到另一个进程,我们不应该修改发送的张量,也不应该在 req.wait() 完成之前访问接收的张量。
在
dist.isend()之后写入tensor将导致未定义的行为。在
dist.irecv()之后读取tensor将导致未定义的行为,直到req.wait()执行完成。
然而,在 req.wait() 执行完成后,我们可以保证通信已经发生,并且存储在 tensor[0] 中的值为 1.0。
点对点通信在我们需要更精细地控制进程间通信时非常有用。它们可以用于实现复杂的算法,例如 百度 DeepSpeech 或 Facebook 大规模实验中使用的算法。(参见 第 4.1 节)
集体通信¶
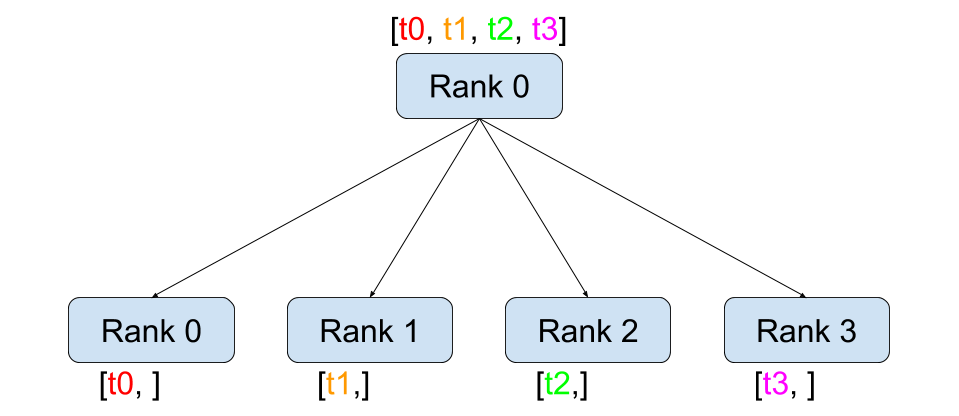
分散 (Scatter)¶ |
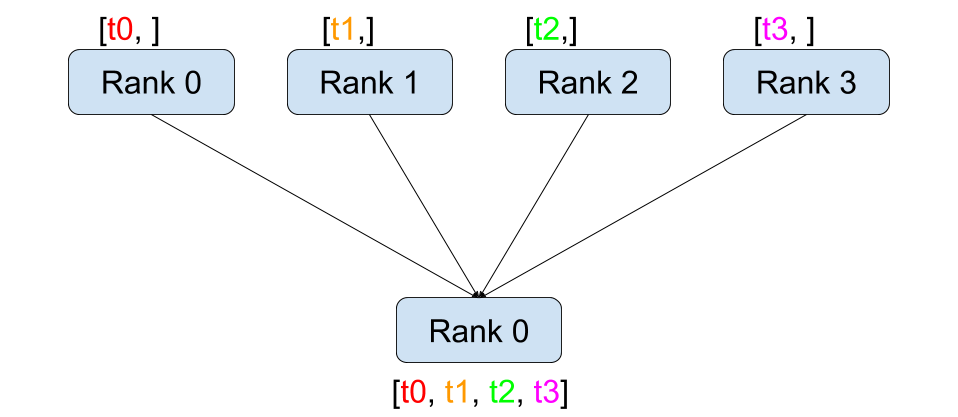
收集 (Gather)¶ |
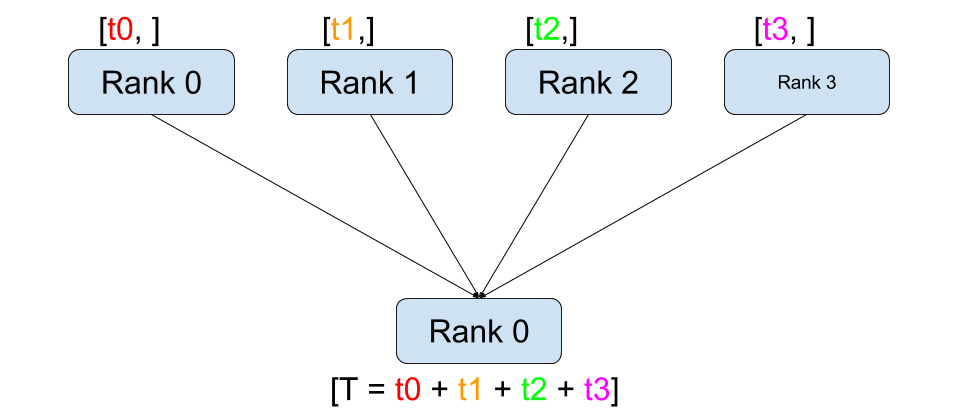
规约 (Reduce)¶ |
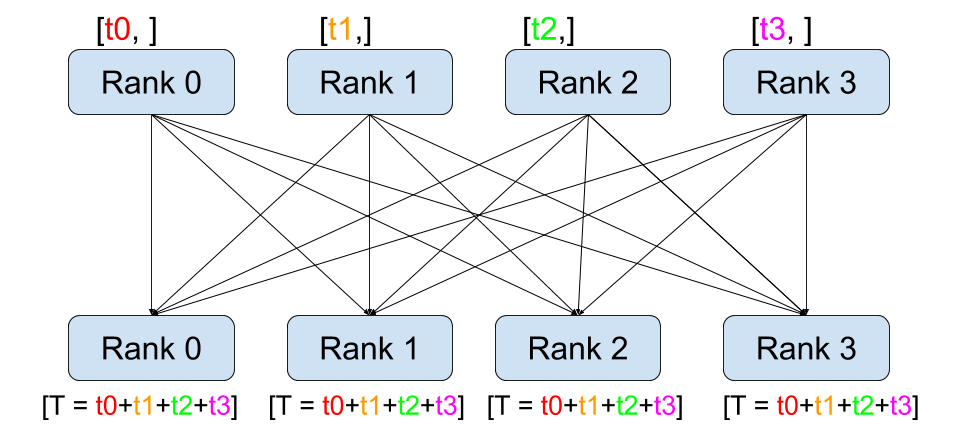
全局规约 (All-Reduce)¶ |
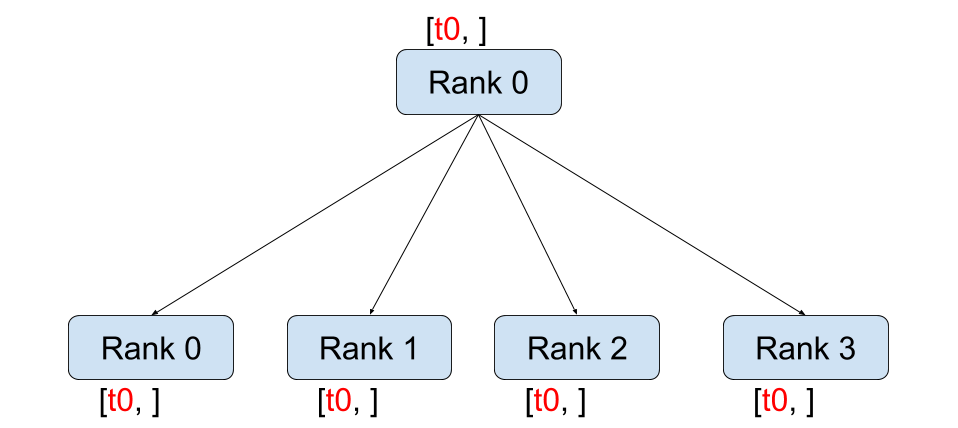
广播 (Broadcast)¶ |
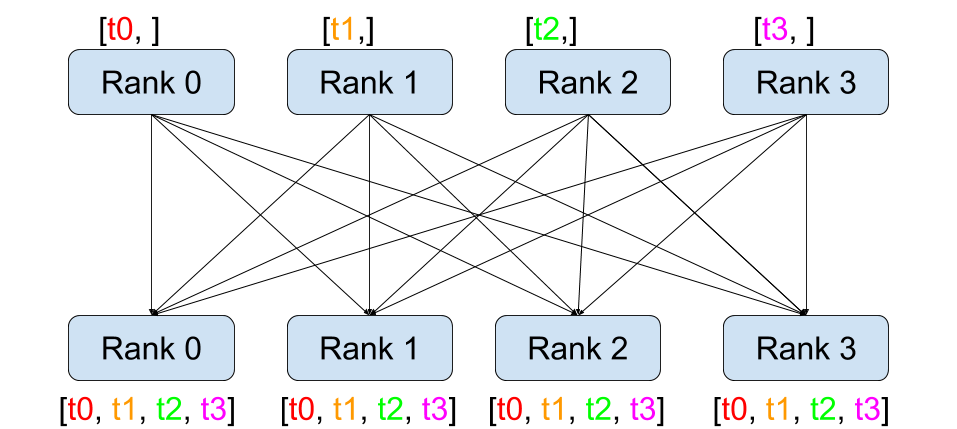
全局收集 (All-Gather)¶ |
与点对点通信相反,集体通信允许跨组中的所有进程进行通信模式。一个组是我们所有进程的子集。要创建一个组,我们可以将一个等级列表传递给 dist.new_group(group)。默认情况下,集体通信在所有进程上执行,这也称为世界。例如,为了获得所有进程上所有张量的总和,我们可以使用 dist.all_reduce(tensor, op, group) 集体操作。
""" All-Reduce example."""
def run(rank, size):
""" Simple collective communication. """
group = dist.new_group([0, 1])
tensor = torch.ones(1)
dist.all_reduce(tensor, op=dist.ReduceOp.SUM, group=group)
print('Rank ', rank, ' has data ', tensor[0])
由于我们想要组中所有张量的总和,因此我们使用 dist.ReduceOp.SUM 作为规约算子。一般来说,任何可交换的数学运算都可以用作算子。PyTorch 开箱即用地提供了许多此类算子,它们都在元素级别上工作:
dist.ReduceOp.SUM (求和),dist.ReduceOp.PRODUCT (乘积),dist.ReduceOp.MAX (最大值),dist.ReduceOp.MIN (最小值),dist.ReduceOp.BAND (按位与),dist.ReduceOp.BOR (按位或),dist.ReduceOp.BXOR (按位异或),dist.ReduceOp.PREMUL_SUM (前乘求和).
支持的算子完整列表可在此处找到。
除了 dist.all_reduce(tensor, op, group) 外,PyTorch 中当前还实现了许多其他集体操作。以下是一些支持的集体操作:
dist.broadcast(tensor, src, group):将tensor从src复制到所有其他进程。dist.reduce(tensor, dst, op, group):将op应用于每个tensor并将结果存储在等级为dst的进程中。dist.all_reduce(tensor, op, group):与 reduce 相同,但结果存储在所有进程中。dist.scatter(tensor, scatter_list, src, group):将scatter_list[i]的第 \(i^{\text{th}}\) 个张量复制到第 \(i^{\text{th}}\) 个进程。dist.gather(tensor, gather_list, dst, group):从所有进程将tensor收集到等级为dst的进程的gather_list中。dist.all_gather(tensor_list, tensor, group):将tensor从所有进程复制到所有进程上的tensor_list中。dist.barrier(group):阻塞 group 中的所有进程,直到每个进程都进入此函数。dist.all_to_all(output_tensor_list, input_tensor_list, group):将输入张量列表分散到组中的所有进程,并在输出列表中返回收集到的张量列表。
通过查阅 PyTorch 分布式模块的最新文档,可以找到支持的集体操作完整列表 (链接)。
分布式训练¶
注意:你可以在这个 GitHub 仓库中找到本节的示例脚本。
既然我们了解了分布式模块的工作原理,接下来让我们用它来编写一些有用的东西。我们的目标是复制 DistributedDataParallel 的功能。当然,这只是一个教学示例,在实际应用中,你应该使用上面链接的官方的、经过充分测试和优化的版本。
简单来说,我们想要实现随机梯度下降的分布式版本。我们的脚本将让所有进程计算各自模型在其批处理数据上的梯度,然后对这些梯度求平均。为了确保在改变进程数量时获得相似的收敛结果,我们首先需要对数据集进行分区。(你也可以使用 torch.utils.data.random_split,而不是下面的代码片段。)
""" Dataset partitioning helper """
class Partition(object):
def __init__(self, data, index):
self.data = data
self.index = index
def __len__(self):
return len(self.index)
def __getitem__(self, index):
data_idx = self.index[index]
return self.data[data_idx]
class DataPartitioner(object):
def __init__(self, data, sizes=[0.7, 0.2, 0.1], seed=1234):
self.data = data
self.partitions = []
rng = Random() # from random import Random
rng.seed(seed)
data_len = len(data)
indexes = [x for x in range(0, data_len)]
rng.shuffle(indexes)
for frac in sizes:
part_len = int(frac * data_len)
self.partitions.append(indexes[0:part_len])
indexes = indexes[part_len:]
def use(self, partition):
return Partition(self.data, self.partitions[partition])
有了上面的代码片段,我们现在可以使用以下几行代码轻松地对任何数据集进行分区:
""" Partitioning MNIST """
def partition_dataset():
dataset = datasets.MNIST('./data', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
]))
size = dist.get_world_size()
bsz = 128 // size
partition_sizes = [1.0 / size for _ in range(size)]
partition = DataPartitioner(dataset, partition_sizes)
partition = partition.use(dist.get_rank())
train_set = torch.utils.data.DataLoader(partition,
batch_size=bsz,
shuffle=True)
return train_set, bsz
假设我们有 2 个副本,那么每个进程将拥有一个包含 60000 / 2 = 30000 个样本的 train_set。我们还将批量大小除以副本数量,以保持整体批量大小为 128。
现在我们可以编写通常的前向-反向-优化训练代码,并添加一个函数调用来平均我们模型的梯度。(以下内容主要受到官方 PyTorch MNIST 示例的启发。)
""" Distributed Synchronous SGD Example """
def run(rank, size):
torch.manual_seed(1234)
train_set, bsz = partition_dataset()
model = Net()
optimizer = optim.SGD(model.parameters(),
lr=0.01, momentum=0.5)
num_batches = ceil(len(train_set.dataset) / float(bsz))
for epoch in range(10):
epoch_loss = 0.0
for data, target in train_set:
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
epoch_loss += loss.item()
loss.backward()
average_gradients(model)
optimizer.step()
print('Rank ', dist.get_rank(), ', epoch ',
epoch, ': ', epoch_loss / num_batches)
剩下要实现的是 average_gradients(model) 函数,它简单地接受一个模型并对它在整个世界范围内的梯度进行平均。
""" Gradient averaging. """
def average_gradients(model):
size = float(dist.get_world_size())
for param in model.parameters():
dist.all_reduce(param.grad.data, op=dist.ReduceOp.SUM)
param.grad.data /= size
瞧!我们成功地实现了分布式同步 SGD,并且可以在大型计算机集群上训练任何模型。
注意:虽然上一句话在技术上是正确的,但要实现生产级别的同步 SGD 版本,还需要更多的技巧。再次强调,请使用经过测试和优化的版本。
我们自己的环形 All-reduce¶
作为额外的挑战,想象一下我们想要实现 DeepSpeech 高效的环形 All-reduce。使用点对点集体操作实现这一点相当容易。
""" Implementation of a ring-reduce with addition. """
def allreduce(send, recv):
rank = dist.get_rank()
size = dist.get_world_size()
send_buff = send.clone()
recv_buff = send.clone()
accum = send.clone()
left = ((rank - 1) + size) % size
right = (rank + 1) % size
for i in range(size - 1):
if i % 2 == 0:
# Send send_buff
send_req = dist.isend(send_buff, right)
dist.recv(recv_buff, left)
accum[:] += recv_buff[:]
else:
# Send recv_buff
send_req = dist.isend(recv_buff, right)
dist.recv(send_buff, left)
accum[:] += send_buff[:]
send_req.wait()
recv[:] = accum[:]
在上面的脚本中,allreduce(send, recv) 函数的签名与 PyTorch 中的有所不同。它接受一个 recv 张量,并将所有 send 张量的总和存储在其中。作为一个留给读者的练习,我们的版本与 DeepSpeech 的实现还有一个区别:他们的实现将梯度张量分成块,以便最佳地利用通信带宽。(提示:torch.chunk)
高级主题¶
现在我们准备好探索 torch.distributed 的一些更高级功能。由于内容很多,本节分为两个子节:
通信后端:在这里我们学习如何使用 MPI 和 Gloo 进行 GPU 到 GPU 的通信。
初始化方法:在这里我们了解如何在
dist.init_process_group()中最好地设置初始协调阶段。
通信后端¶
torch.distributed 最优雅的方面之一是它能够抽象并在不同后端之上构建。如前所述,PyTorch 中实现了多个后端。其中一些最受欢迎的是 Gloo、NCCL 和 MPI。根据所需用例,它们各自具有不同的规范和权衡。支持函数对比表可在此处找到。
Gloo 后端
到目前为止,我们已经广泛使用了 Gloo 后端。作为一个开发平台,它非常方便,因为它包含在预编译的 PyTorch 二进制文件中,并且在 Linux (从 0.2 版本开始) 和 macOS (从 1.3 版本开始) 上都可以工作。它支持 CPU 上的所有点对点和集体操作,以及 GPU 上的所有集体操作。Gloo 后端对 CUDA 张量的集体操作实现不如 NCCL 后端提供的优化得好。
正如你肯定已经注意到的,如果你将 model 放在 GPU 上,我们的分布式 SGD 示例将无法工作。为了使用多个 GPU,我们还需要进行以下修改:
使用
device = torch.device("cuda:{}".format(rank))model = Net()\(\rightarrow\)model = Net().to(device)使用
data, target = data.to(device), target.to(device)
经过以上修改,我们的模型现在正在两个 GPU 上训练,你可以使用 watch nvidia-smi 监控它们的利用率。
MPI 后端
消息传递接口 (MPI) 是高性能计算领域的一个标准化工具。它允许进行点对点和集体通信,并且是 torch.distributed API 的主要灵感来源。存在多种 MPI 实现(例如 Open-MPI、MVAPICH2、Intel MPI),每种都针对不同目的进行了优化。使用 MPI 后端的优势在于 MPI 在大型计算机集群上的广泛可用性和高优化水平。一些 最新的 实现还能够利用 CUDA IPC 和 GPU Direct 技术来避免通过 CPU 进行内存拷贝。
遗憾的是,PyTorch 的二进制文件不能包含 MPI 实现,我们需要手动重新编译。幸运的是,这个过程相当简单,因为在编译时,PyTorch 会自行查找可用的 MPI 实现。以下步骤通过从源码安装 PyTorch 来安装 MPI 后端。
创建并激活你的 Anaconda 环境,按照指南安装所有先决条件,但暂不运行
python setup.py install。选择并安装你喜欢的 MPI 实现。请注意,启用 CUDA-aware MPI 可能需要一些额外步骤。在本例中,我们将坚持使用不带 GPU 支持的 Open-MPI:
conda install -c conda-forge openmpi现在,进入你克隆的 PyTorch 仓库,执行
python setup.py install。
为了测试我们新安装的后端,需要进行一些修改。
将
if __name__ == '__main__':下的内容替换为init_process(0, 0, run, backend='mpi')。运行
mpirun -n 4 python myscript.py。
这些更改的原因是 MPI 在启动进程之前需要创建自己的环境。MPI 还会启动自己的进程并执行 初始化方法 中描述的握手,这使得 init_process_group 函数的 rank 和 size 参数变得多余。这实际上非常强大,因为你可以向 mpirun 传递额外的参数,以便为每个进程量身定制计算资源。(比如每个进程的核心数,手动将机器分配给特定的 rank,以及 更多内容)这样做,你应该会获得与其他通信后端相同的熟悉输出。
NCCL 后端
NCCL 后端 提供了针对 CUDA tensors 的集体操作的优化实现。如果你的集体操作只使用 CUDA tensors,那么考虑使用此后端以获得最佳性能。包含 CUDA 支持的预构建二进制文件已包含 NCCL 后端。
初始化方法¶
在本教程的最后,让我们研究一下我们最初调用的函数:dist.init_process_group(backend, init_method)。具体来说,我们将讨论负责每个进程之间初步协调步骤的各种初始化方法。这些方法使你能够定义如何完成这种协调。
初始化方法的选择取决于你的硬件设置,某些方法可能比其他方法更适合。除了以下各节之外,请参阅官方文档以获取更多信息。
环境变量
在本教程中,我们一直使用环境变量初始化方法。通过在所有机器上设置以下四个环境变量,所有进程都将能够正确连接到 master,获取关于其他进程的信息,并最终与它们握手。
MASTER_PORT: 将托管 rank 为 0 的进程的机器上的一个空闲端口。MASTER_ADDR: 将托管 rank 为 0 的进程的机器的 IP 地址。WORLD_SIZE: 进程总数,master 知道要等待多少个 worker。RANK: 每个进程的 rank,以便它们知道自己是 master 还是 worker。
共享文件系统
共享文件系统要求所有进程都能访问共享文件系统,并将通过共享文件进行协调。这意味着每个进程都会打开文件,写入其信息,并等待直到所有进程都完成写入。之后,所有所需信息即可供所有进程使用。为了避免竞态条件,文件系统必须支持通过 fcntl 进行锁定。
dist.init_process_group(
init_method='file:///mnt/nfs/sharedfile',
rank=args.rank,
world_size=4)
TCP
通过 TCP 进行初始化可以通过提供 rank 为 0 的进程的 IP 地址和一个可到达的端口号来实现。在此,所有 worker 都能够连接到 rank 为 0 的进程并交换如何相互通信的信息。
dist.init_process_group(
init_method='tcp://10.1.1.20:23456',
rank=args.rank,
world_size=4)
致谢
我要感谢 PyTorch 开发人员在实现、文档和测试方面所做的出色工作。当代码不清楚时,我总能依靠文档或测试来找到答案。特别感谢 Soumith Chintala、Adam Paszke 和 Natalia Gimelshein 对早期草稿提供了富有见地的评论并回答了问题。
