


全分片数据并行 (FSDP) 入门¶
创建于: 2022 年 3 月 17 日 | 最后更新于: 2025 年 1 月 23 日 | 最后验证于: 2024 年 11 月 5 日
作者: Hamid Shojanazeri, Yanli Zhao, Shen Li
注意
 在 github 上查看和编辑本教程。
在 github 上查看和编辑本教程。
大规模训练 AI 模型是一项具有挑战性的任务,需要大量的计算能力和资源。它也伴随着处理这些超大型模型训练所带来的可观的工程复杂性。PyTorch 1.11 中发布的 PyTorch FSDP 让这项任务变得更容易。
在本教程中,我们将展示如何使用 FSDP API,针对简单的 MNIST 模型,其方法可以扩展到其他更大的模型,例如 HuggingFace BERT 模型、参数量高达 1 万亿的 GPT 3 模型。示例 DDP MNIST 代码由 Patrick Hu 提供。
FSDP 的工作原理¶
在分布式数据并行 (DDP) 训练中,每个进程/工作节点拥有一个模型的副本并处理一批数据,最后它使用 All-Reduce 来累加不同工作节点的梯度。在 DDP 中,模型权重和优化器状态在所有工作节点中复制。FSDP 是一种数据并行类型,它将模型参数、优化器状态和梯度在 DDP 进程间分片。
使用 FSDP 训练时,所有工作节点的 GPU 内存占用小于使用 DDP 训练。这使得训练一些非常大的模型变得可行,允许在设备上容纳更大的模型或批量大小。这带来了通信量增加的代价。通过内部优化(如重叠通信和计算)可以减少通信开销。
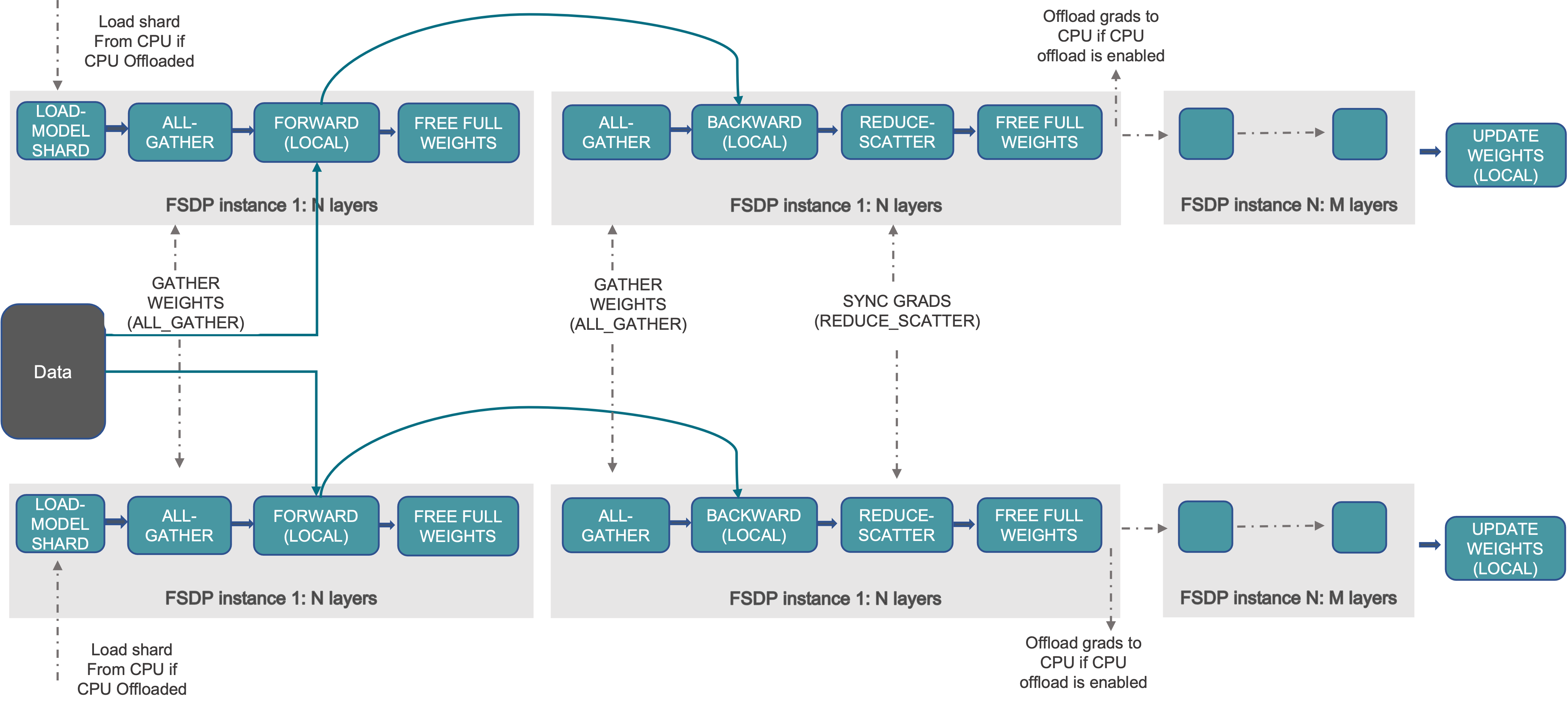
FSDP 工作流程¶
从高层来看,FSDP 的工作方式如下:
在构造函数中
分片模型参数,每个进程只保留自己的分片
在前向路径中
运行 All-Gather 从所有进程收集所有分片,以恢复此 FSDP 单元中的完整参数
运行前向计算
丢弃刚刚收集的参数分片
在反向路径中
运行 All-Gather 从所有进程收集所有分片,以恢复此 FSDP 单元中的完整参数
运行反向计算
运行 Reduce-Scatter 同步梯度
丢弃参数
可以将 FSDP 的分片视为将 DDP 梯度 All-Reduce 分解为 Reduce-Scatter 和 All-Gather。具体来说,在反向传播过程中,FSDP 进行梯度规约和分散 (reduce and scatter),确保每个进程拥有一部分梯度分片。然后它在优化器步骤中更新相应的参数分片。最后,在随后的前向传播中,它执行 All-Gather 操作来收集和组合更新后的参数分片。
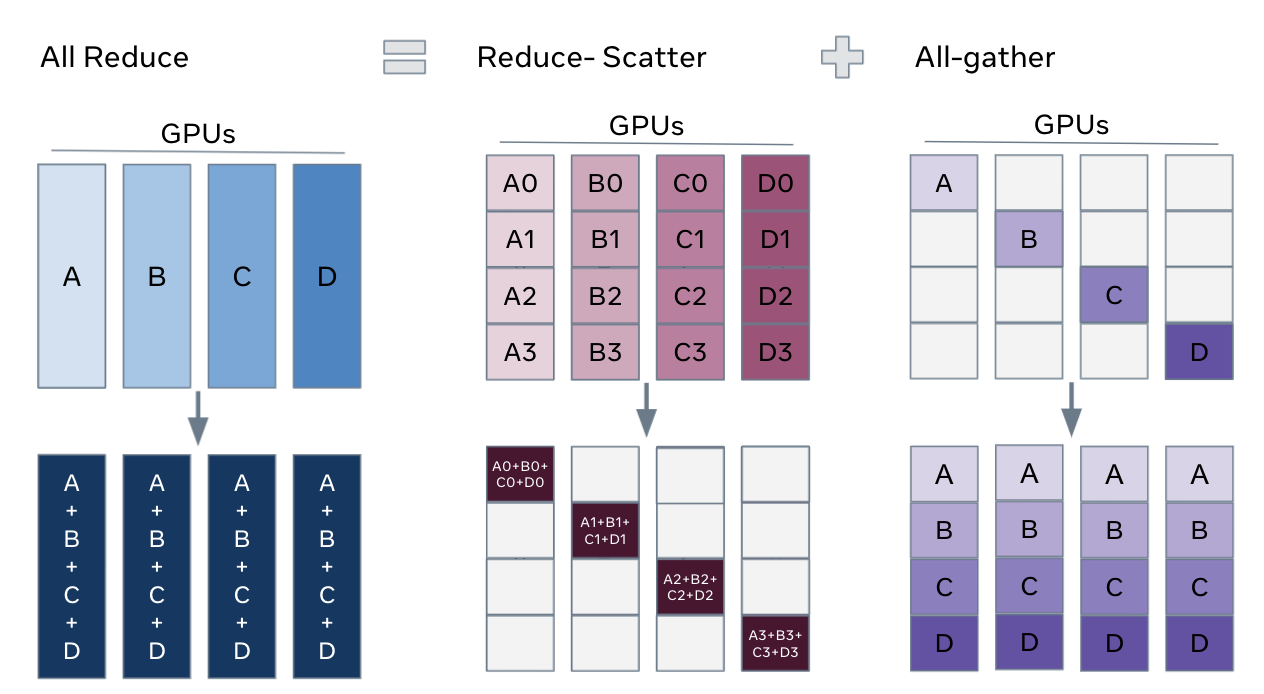
FSDP Allreduce¶
如何使用 FSDP¶
这里我们使用一个玩具模型在 MNIST 数据集上运行训练以进行演示。这些 API 和逻辑也可以应用于训练更大的模型。
设置
1.1 安装 PyTorch 和 Torchvision
有关安装信息,请参阅入门指南。
我们将以下代码片段添加到 Python 脚本 “FSDP_mnist.py” 中。
1.2 导入必要的包
注意
本教程适用于 PyTorch 1.12 及更高版本。如果您使用较早版本,请将所有 size_based_auto_wrap_policy 替换为 default_auto_wrap_policy,并将 fsdp_auto_wrap_policy 替换为 auto_wrap_policy。
# Based on: https://github.com/pytorch/examples/blob/master/mnist/main.py
import os
import argparse
import functools
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from torch.optim.lr_scheduler import StepLR
import torch.distributed as dist
import torch.multiprocessing as mp
from torch.nn.parallel import DistributedDataParallel as DDP
from torch.utils.data.distributed import DistributedSampler
from torch.distributed.fsdp import FullyShardedDataParallel as FSDP
from torch.distributed.fsdp.fully_sharded_data_parallel import (
CPUOffload,
BackwardPrefetch,
)
from torch.distributed.fsdp.wrap import (
size_based_auto_wrap_policy,
enable_wrap,
wrap,
)
1.3 分布式训练设置。正如我们提到的,FSDP 是一种需要分布式训练环境的数据并行类型,因此这里我们使用两个辅助函数来初始化分布式训练的进程并进行清理。
def setup(rank, world_size):
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '12355'
# initialize the process group
dist.init_process_group("nccl", rank=rank, world_size=world_size)
def cleanup():
dist.destroy_process_group()
2.1 定义我们用于手写数字分类的玩具模型。
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 32, 3, 1)
self.conv2 = nn.Conv2d(32, 64, 3, 1)
self.dropout1 = nn.Dropout(0.25)
self.dropout2 = nn.Dropout(0.5)
self.fc1 = nn.Linear(9216, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.conv2(x)
x = F.relu(x)
x = F.max_pool2d(x, 2)
x = self.dropout1(x)
x = torch.flatten(x, 1)
x = self.fc1(x)
x = F.relu(x)
x = self.dropout2(x)
x = self.fc2(x)
output = F.log_softmax(x, dim=1)
return output
2.2 定义一个训练函数
def train(args, model, rank, world_size, train_loader, optimizer, epoch, sampler=None):
model.train()
ddp_loss = torch.zeros(2).to(rank)
if sampler:
sampler.set_epoch(epoch)
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(rank), target.to(rank)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target, reduction='sum')
loss.backward()
optimizer.step()
ddp_loss[0] += loss.item()
ddp_loss[1] += len(data)
dist.all_reduce(ddp_loss, op=dist.ReduceOp.SUM)
if rank == 0:
print('Train Epoch: {} \tLoss: {:.6f}'.format(epoch, ddp_loss[0] / ddp_loss[1]))
2.3 定义一个验证函数
def test(model, rank, world_size, test_loader):
model.eval()
correct = 0
ddp_loss = torch.zeros(3).to(rank)
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(rank), target.to(rank)
output = model(data)
ddp_loss[0] += F.nll_loss(output, target, reduction='sum').item() # sum up batch loss
pred = output.argmax(dim=1, keepdim=True) # get the index of the max log-probability
ddp_loss[1] += pred.eq(target.view_as(pred)).sum().item()
ddp_loss[2] += len(data)
dist.all_reduce(ddp_loss, op=dist.ReduceOp.SUM)
if rank == 0:
test_loss = ddp_loss[0] / ddp_loss[2]
print('Test set: Average loss: {:.4f}, Accuracy: {}/{} ({:.2f}%)\n'.format(
test_loss, int(ddp_loss[1]), int(ddp_loss[2]),
100. * ddp_loss[1] / ddp_loss[2]))
2.4 定义一个用 FSDP 包装模型的分布式训练函数
注意:为了保存 FSDP 模型,我们需要在每个进程上调用 state_dict,然后在 Rank 0 上保存整体状态。
def fsdp_main(rank, world_size, args):
setup(rank, world_size)
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
dataset1 = datasets.MNIST('../data', train=True, download=True,
transform=transform)
dataset2 = datasets.MNIST('../data', train=False,
transform=transform)
sampler1 = DistributedSampler(dataset1, rank=rank, num_replicas=world_size, shuffle=True)
sampler2 = DistributedSampler(dataset2, rank=rank, num_replicas=world_size)
train_kwargs = {'batch_size': args.batch_size, 'sampler': sampler1}
test_kwargs = {'batch_size': args.test_batch_size, 'sampler': sampler2}
cuda_kwargs = {'num_workers': 2,
'pin_memory': True,
'shuffle': False}
train_kwargs.update(cuda_kwargs)
test_kwargs.update(cuda_kwargs)
train_loader = torch.utils.data.DataLoader(dataset1,**train_kwargs)
test_loader = torch.utils.data.DataLoader(dataset2, **test_kwargs)
my_auto_wrap_policy = functools.partial(
size_based_auto_wrap_policy, min_num_params=100
)
torch.cuda.set_device(rank)
init_start_event = torch.cuda.Event(enable_timing=True)
init_end_event = torch.cuda.Event(enable_timing=True)
model = Net().to(rank)
model = FSDP(model)
optimizer = optim.Adadelta(model.parameters(), lr=args.lr)
scheduler = StepLR(optimizer, step_size=1, gamma=args.gamma)
init_start_event.record()
for epoch in range(1, args.epochs + 1):
train(args, model, rank, world_size, train_loader, optimizer, epoch, sampler=sampler1)
test(model, rank, world_size, test_loader)
scheduler.step()
init_end_event.record()
if rank == 0:
init_end_event.synchronize()
print(f"CUDA event elapsed time: {init_start_event.elapsed_time(init_end_event) / 1000}sec")
print(f"{model}")
if args.save_model:
# use a barrier to make sure training is done on all ranks
dist.barrier()
states = model.state_dict()
if rank == 0:
torch.save(states, "mnist_cnn.pt")
cleanup()
2.5 最后,解析参数并设置主函数
if __name__ == '__main__':
# Training settings
parser = argparse.ArgumentParser(description='PyTorch MNIST Example')
parser.add_argument('--batch-size', type=int, default=64, metavar='N',
help='input batch size for training (default: 64)')
parser.add_argument('--test-batch-size', type=int, default=1000, metavar='N',
help='input batch size for testing (default: 1000)')
parser.add_argument('--epochs', type=int, default=10, metavar='N',
help='number of epochs to train (default: 14)')
parser.add_argument('--lr', type=float, default=1.0, metavar='LR',
help='learning rate (default: 1.0)')
parser.add_argument('--gamma', type=float, default=0.7, metavar='M',
help='Learning rate step gamma (default: 0.7)')
parser.add_argument('--no-cuda', action='store_true', default=False,
help='disables CUDA training')
parser.add_argument('--seed', type=int, default=1, metavar='S',
help='random seed (default: 1)')
parser.add_argument('--save-model', action='store_true', default=False,
help='For Saving the current Model')
args = parser.parse_args()
torch.manual_seed(args.seed)
WORLD_SIZE = torch.cuda.device_count()
mp.spawn(fsdp_main,
args=(WORLD_SIZE, args),
nprocs=WORLD_SIZE,
join=True)
我们记录了 CUDA 事件来测量 FSDP 模型特定操作的时间。CUDA 事件时间为 110.85 秒。
python FSDP_mnist.py
CUDA event elapsed time on training loop 40.67462890625sec
用 FSDP 包装模型后,模型将如下所示,我们可以看到模型被包装在一个 FSDP 单元中。另外,接下来我们将介绍如何添加 auto_wrap_policy 并讨论其差异。
FullyShardedDataParallel(
(_fsdp_wrapped_module): FlattenParamsWrapper(
(_fpw_module): Net(
(conv1): Conv2d(1, 32, kernel_size=(3, 3), stride=(1, 1))
(conv2): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1))
(dropout1): Dropout(p=0.25, inplace=False)
(dropout2): Dropout(p=0.5, inplace=False)
(fc1): Linear(in_features=9216, out_features=128, bias=True)
(fc2): Linear(in_features=128, out_features=10, bias=True)
)
)
)
以下是使用 PyTorch Profiler 捕获的 FSDP MNIST 训练在 g4dn.12.xlarge AWS EC2 实例(带 4 个 GPU)上的峰值内存使用情况。
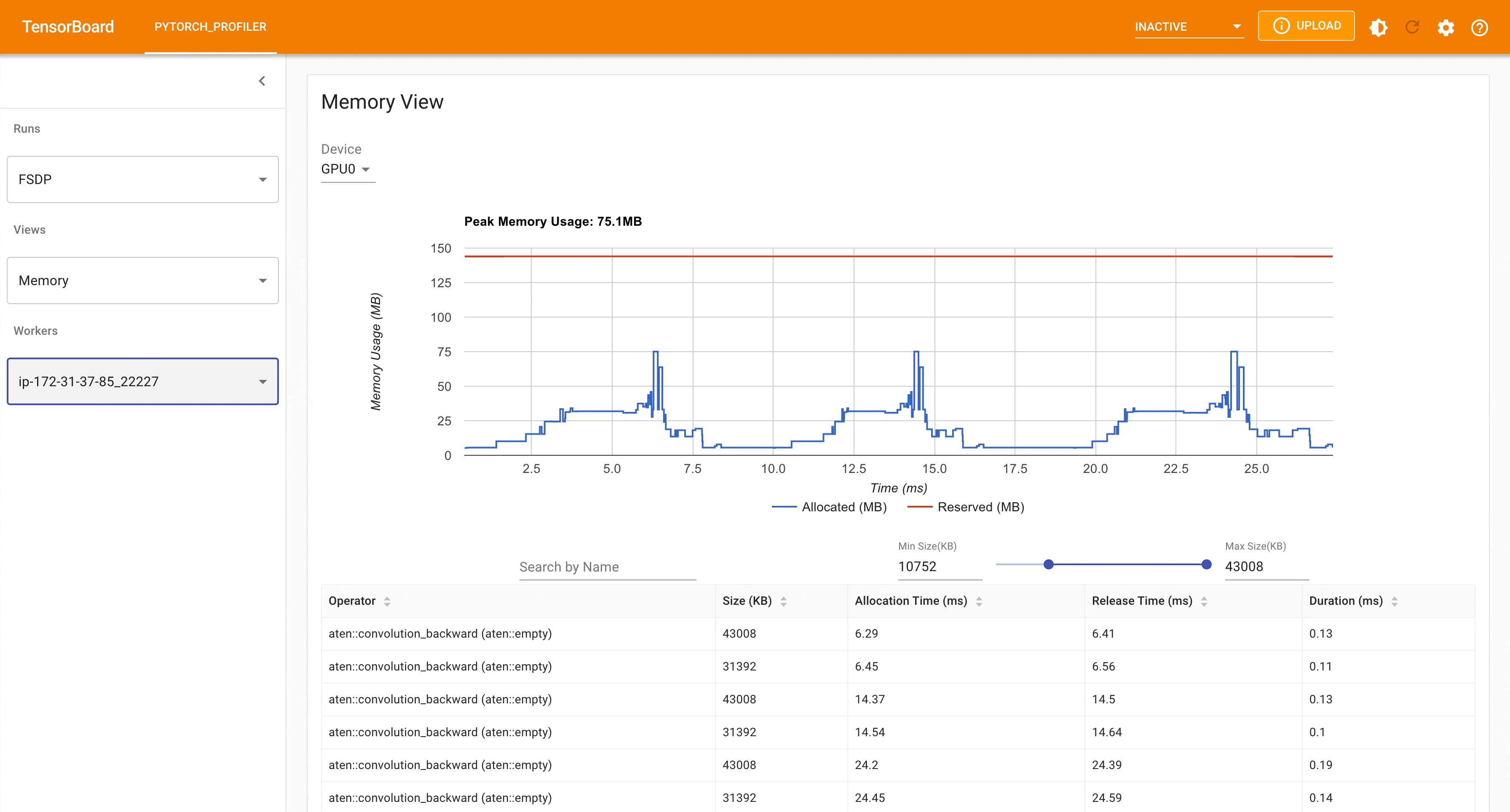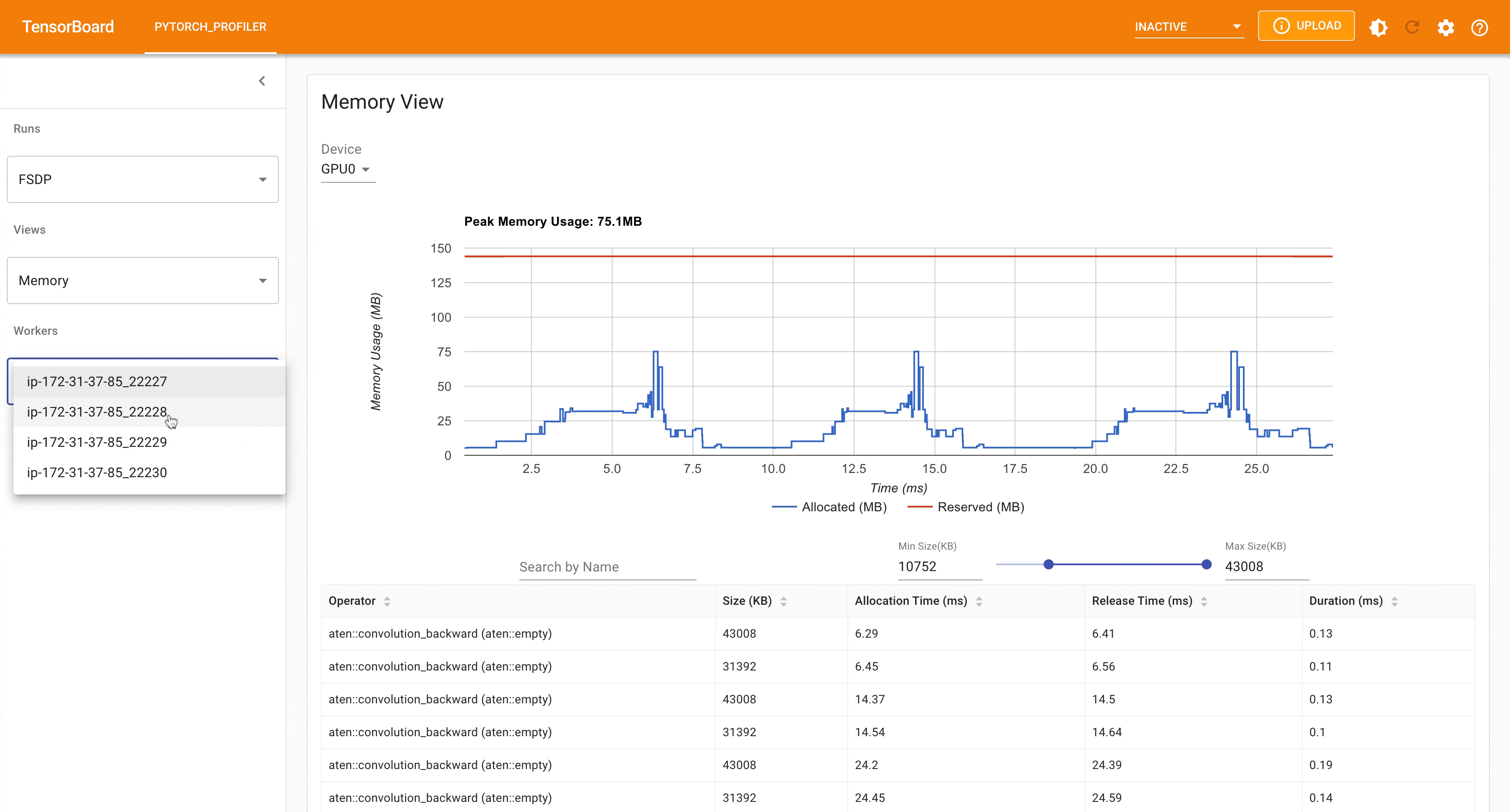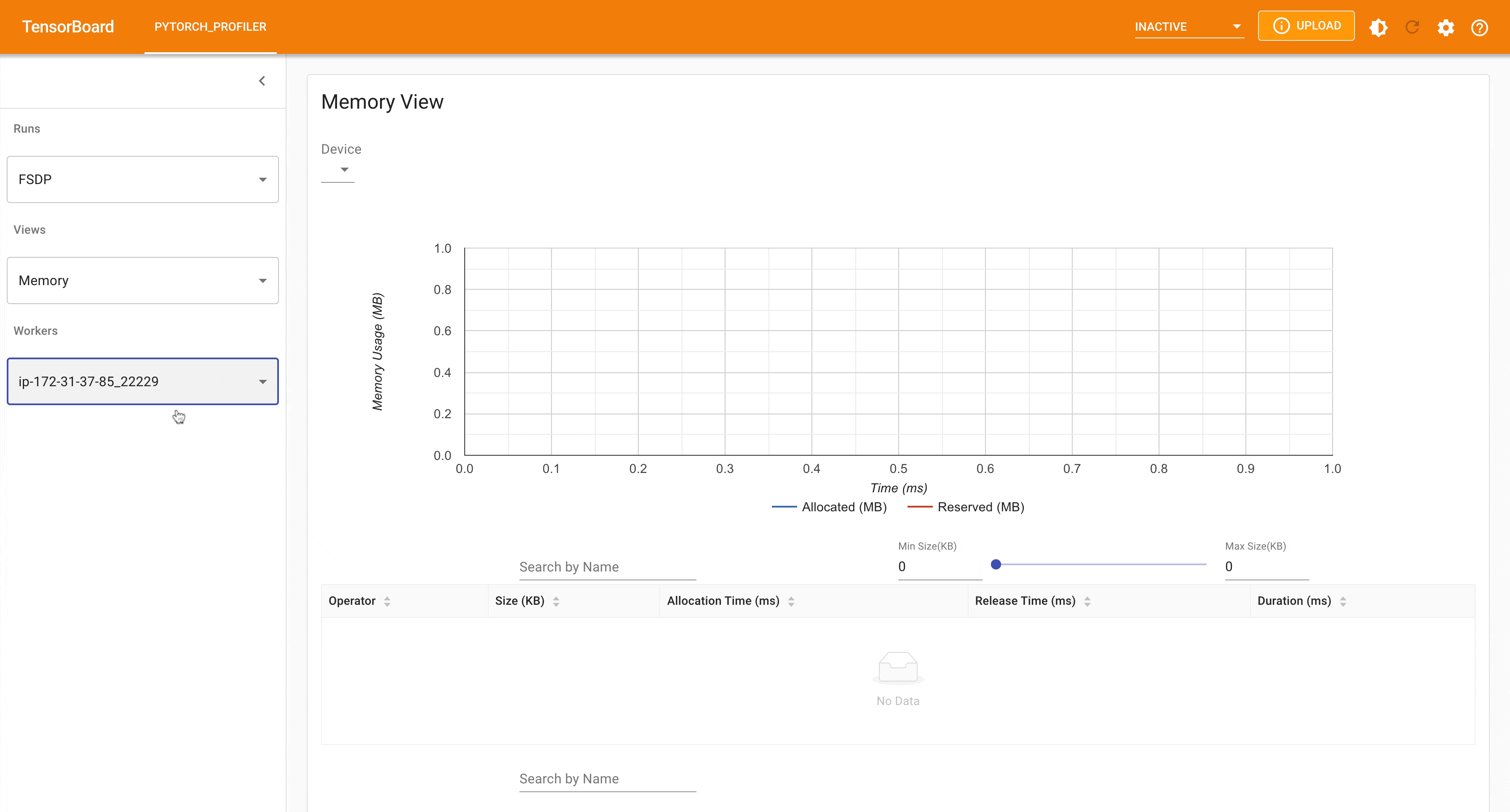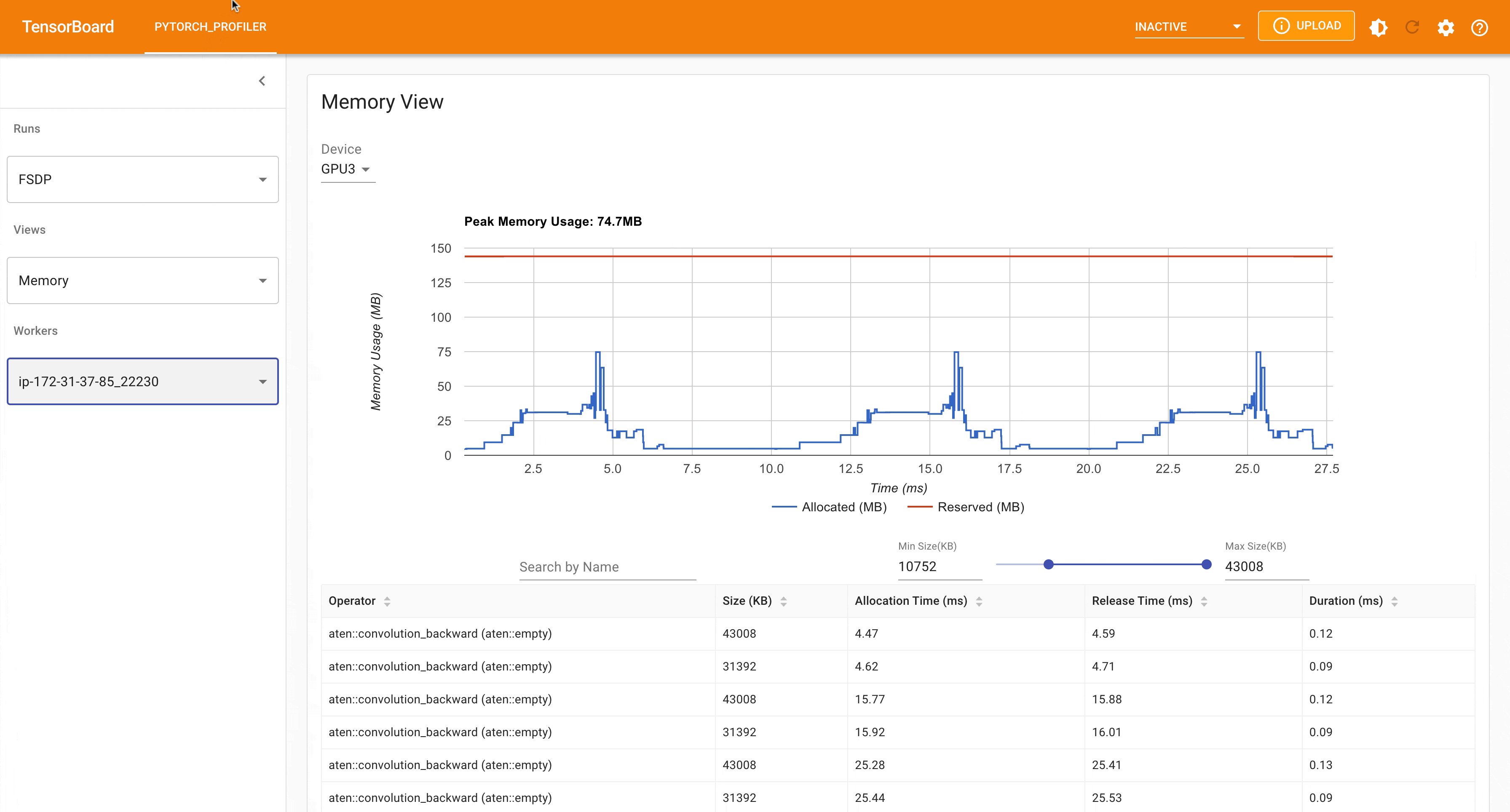
FSDP 峰值内存使用量¶
在 FSDP 中应用 auto_wrap_policy,否则 FSDP 会将整个模型放在一个 FSDP 单元中,这将降低计算效率和内存效率。其工作原理是,假设你的模型包含 100 个 Linear 层。如果你执行 FSDP(model),只会有一个 FSDP 单元包装整个模型。在这种情况下,allgather 会收集所有 100 个 Linear 层的全部参数,因此不会节省 CUDA 内存用于参数分片。此外,对于所有 100 个 Linear 层只有一个阻塞的 allgather 调用,层之间不会有通信和计算重叠。
为了避免这种情况,你可以传入一个 auto_wrap_policy,当满足指定条件(例如,大小限制)时,它会自动密封当前 FSDP 单元并启动一个新的单元。这样你将拥有多个 FSDP 单元,并且一次只需要一个 FSDP 单元收集完整的参数。例如,假设你有 5 个 FSDP 单元,每个单元包装 20 个 Linear 层。那么,在前向传播中,第一个 FSDP 单元会收集前 20 个 Linear 层的参数,进行计算,丢弃参数,然后继续处理接下来的 20 个 Linear 层。因此,在任何时间点,每个进程只实例化 20 个而不是 100 个 Linear 层的参数/梯度。
为此,在 2.4 中我们定义 auto_wrap_policy 并将其传递给 FSDP 包装器。在下面的示例中,my_auto_wrap_policy 定义如果层中的参数数量大于 100,则该层可以由 FSDP 包装或分片。如果层中的参数数量小于 100,它将与 FSDP 的其他小层一起包装。找到最优的自动封装策略具有挑战性,PyTorch 未来将为此配置添加自动调优功能。在没有自动调优工具的情况下,通过实验使用不同的自动封装策略来分析你的工作流程并找到最优策略是一个不错的方法。
my_auto_wrap_policy = functools.partial(
size_based_auto_wrap_policy, min_num_params=20000
)
torch.cuda.set_device(rank)
model = Net().to(rank)
model = FSDP(model,
auto_wrap_policy=my_auto_wrap_policy)
应用 auto_wrap_policy 后,模型将如下所示
FullyShardedDataParallel(
(_fsdp_wrapped_module): FlattenParamsWrapper(
(_fpw_module): Net(
(conv1): Conv2d(1, 32, kernel_size=(3, 3), stride=(1, 1))
(conv2): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1))
(dropout1): Dropout(p=0.25, inplace=False)
(dropout2): Dropout(p=0.5, inplace=False)
(fc1): FullyShardedDataParallel(
(_fsdp_wrapped_module): FlattenParamsWrapper(
(_fpw_module): Linear(in_features=9216, out_features=128, bias=True)
)
)
(fc2): Linear(in_features=128, out_features=10, bias=True)
)
)
python FSDP_mnist.py
CUDA event elapsed time on training loop 41.89130859375sec
以下是使用 PyTorch Profiler 捕获的带有 auto_wrap policy 的 FSDP MNIST 训练在 g4dn.12.xlarge AWS EC2 实例(带 4 个 GPU)上的峰值内存使用情况。可以看出,与未应用自动封装策略的 FSDP 相比,每个设备上的峰值内存使用量更小,从约 75 MB 降至 66 MB。
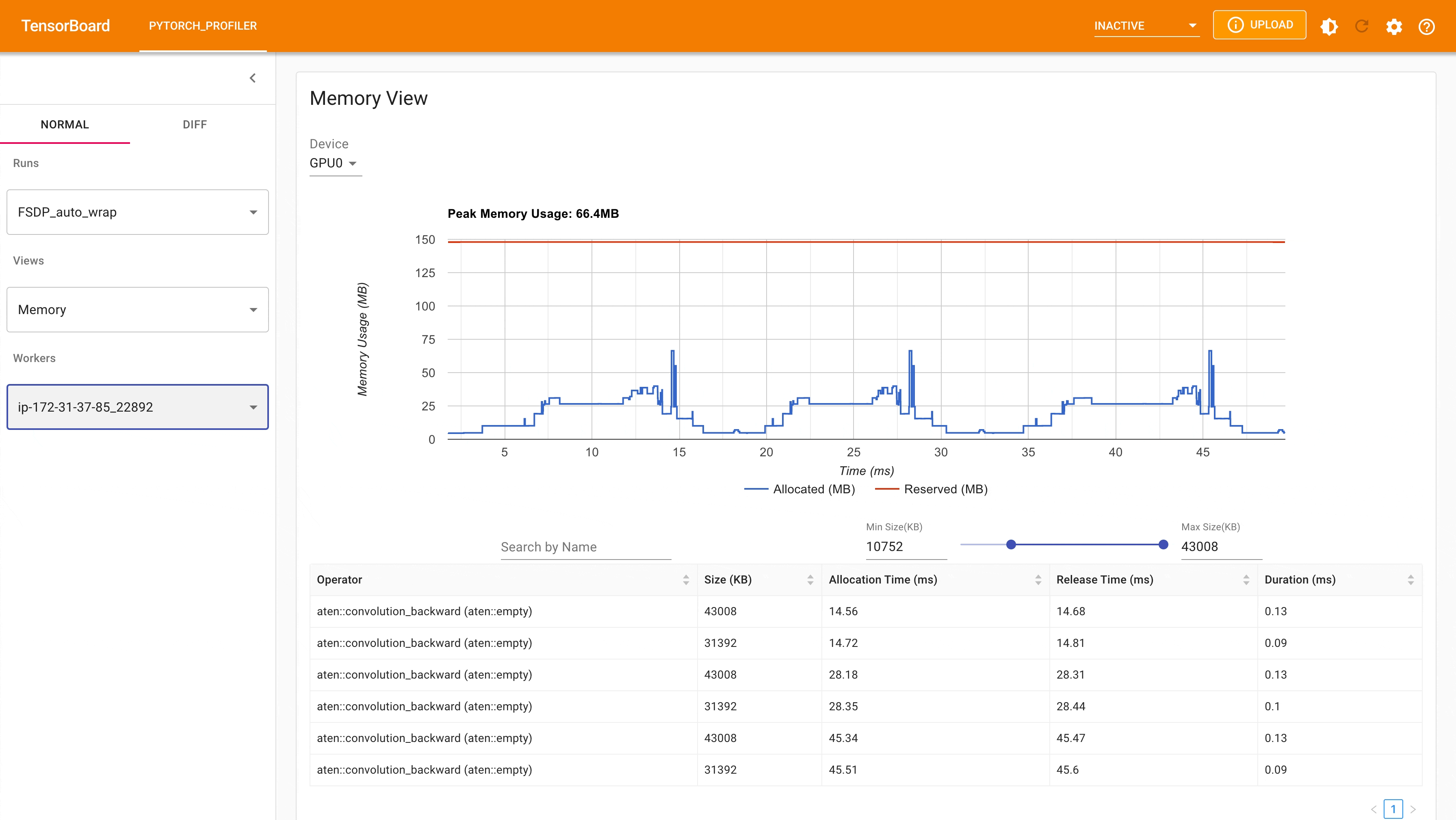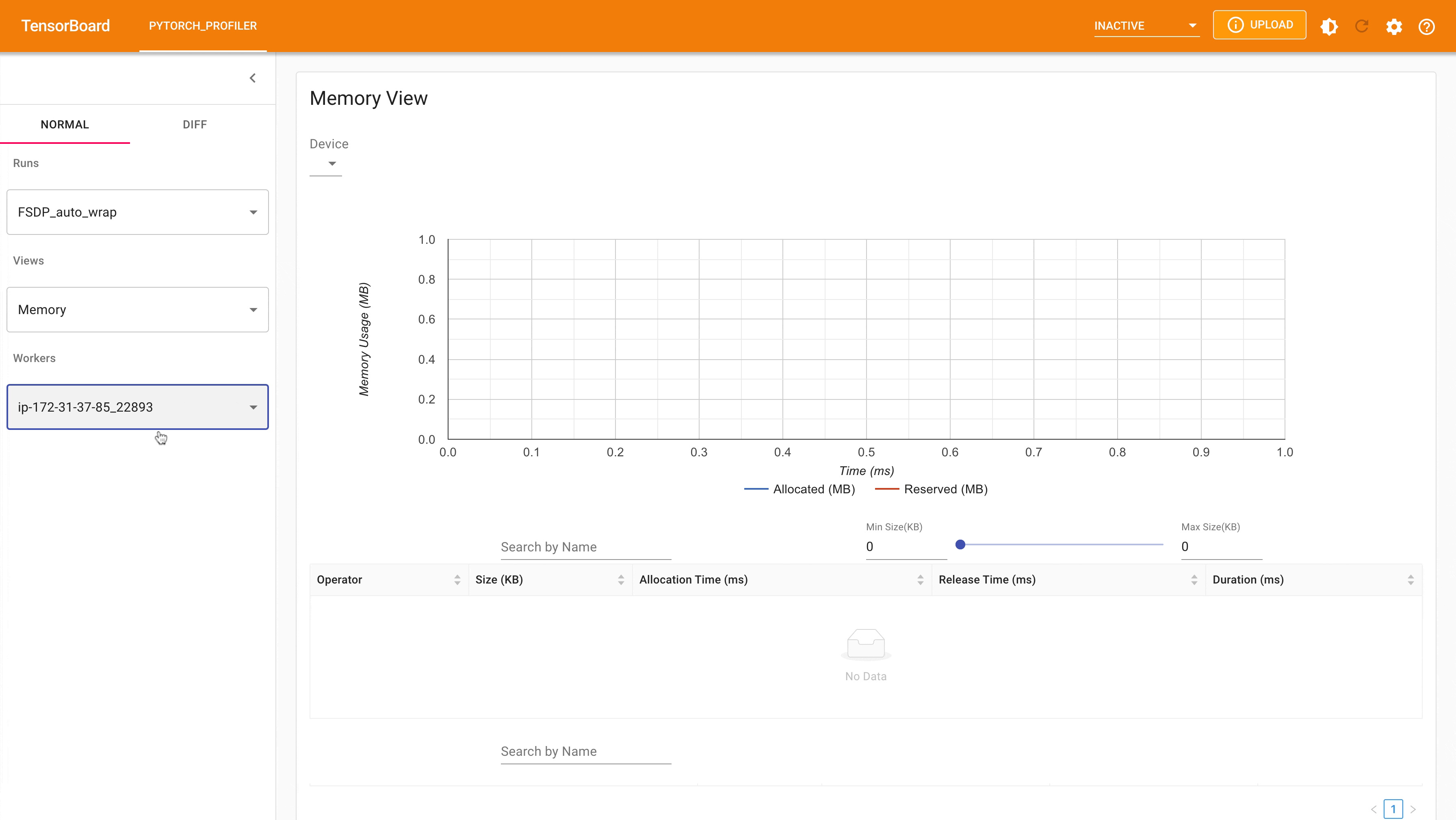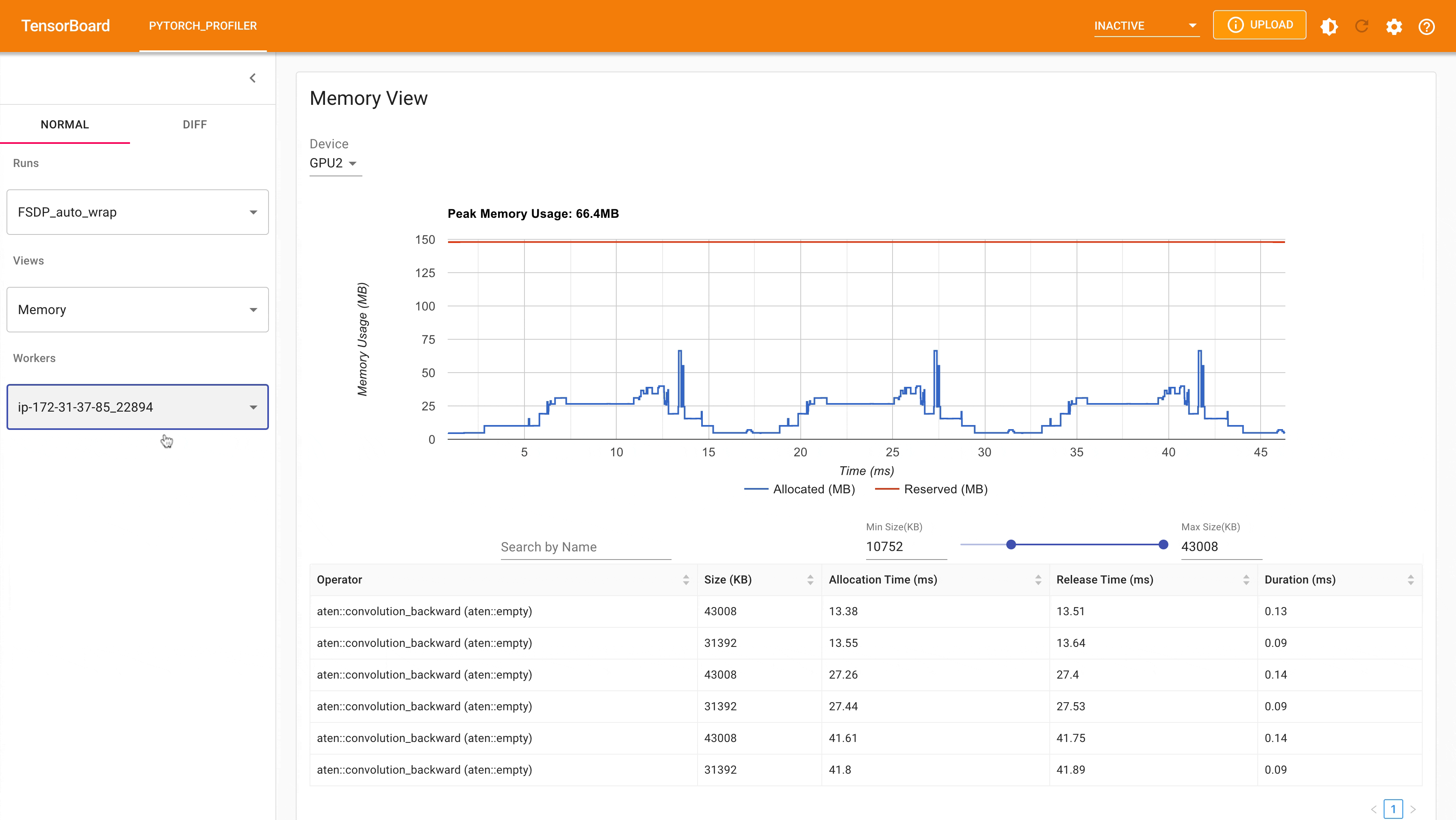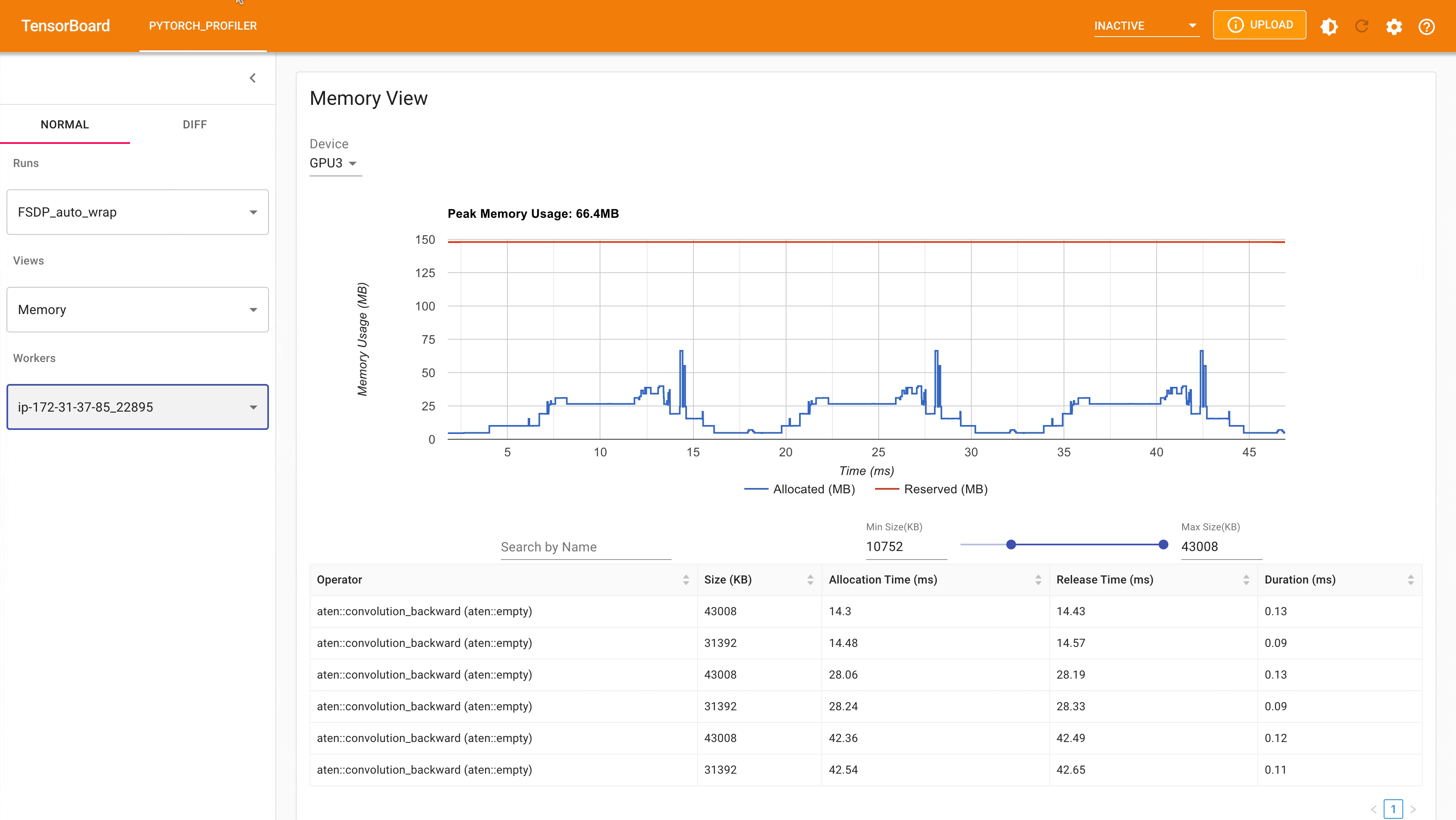
使用自动封装策略的 FSDP 峰值内存使用量¶
CPU 卸载:如果模型非常大,即使使用 FSDP 也无法适应 GPU,那么 CPU 卸载会有所帮助。
目前,仅支持参数和梯度 CPU 卸载。可以通过传入 cpu_offload=CPUOffload(offload_params=True) 来启用它。
请注意,这目前隐式地启用梯度卸载到 CPU,以便参数和梯度可以在同一设备上与优化器协同工作。此 API 可能会更改。默认值为 None,在这种情况下不会进行卸载。
使用此功能可能会显著降低训练速度,这是由于从主机到设备频繁复制张量造成的,但它可以帮助提高内存效率并训练更大规模的模型。
在 2.4 中,我们只需将其添加到 FSDP 包装器中
model = FSDP(model,
auto_wrap_policy=my_auto_wrap_policy,
cpu_offload=CPUOffload(offload_params=True))
将其与 DDP 进行比较,如果在 2.4 中我们只是正常地将模型包装在 DDP 中,并将更改保存在 “DDP_mnist.py” 中。
model = Net().to(rank)
model = DDP(model)
python DDP_mnist.py
CUDA event elapsed time on training loop 39.77766015625sec
以下是使用 PyTorch profiler 捕获的 DDP MNIST 训练在 g4dn.12.xlarge AWS EC2 实例(带 4 个 GPU)上的峰值内存使用情况。
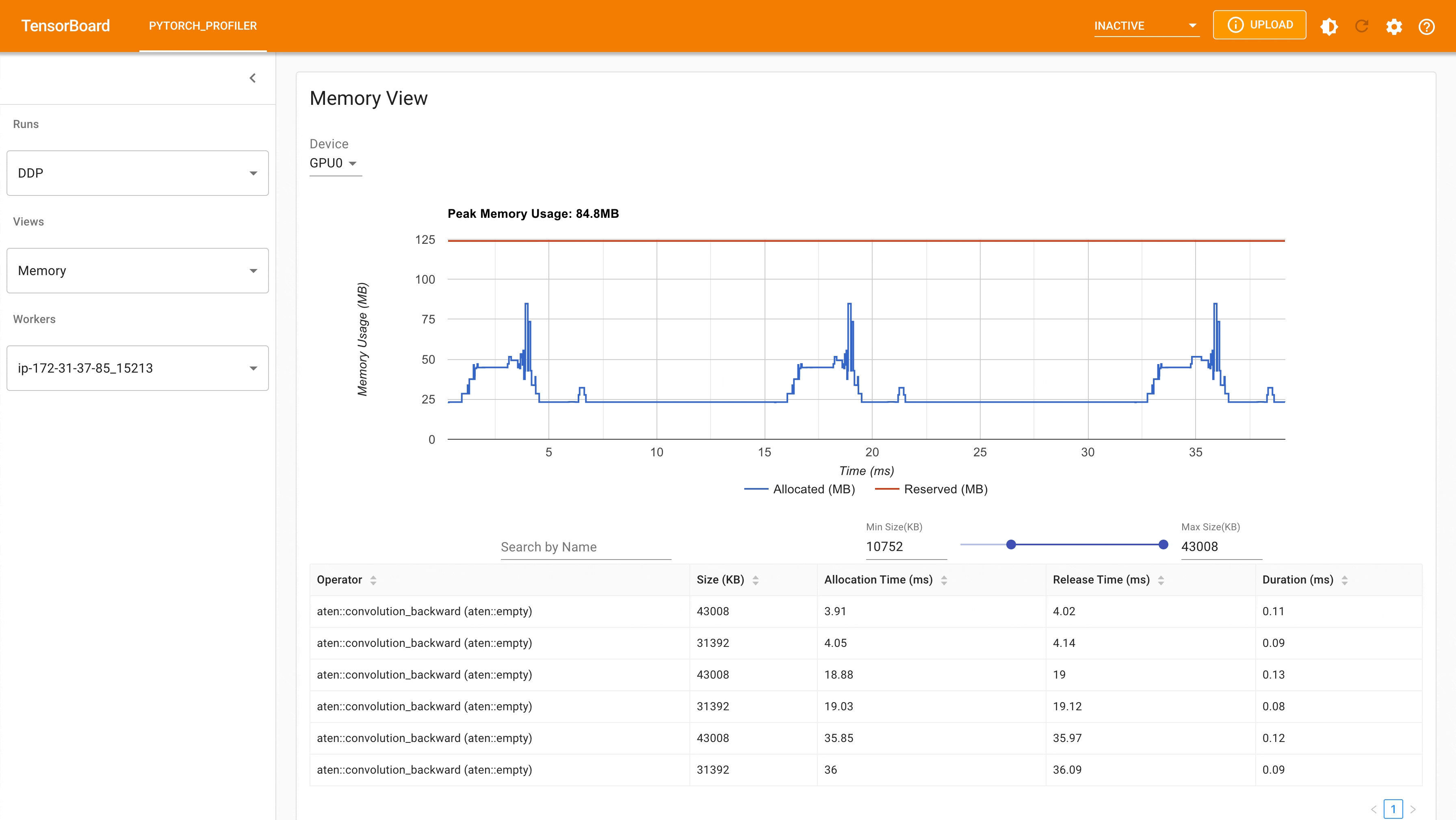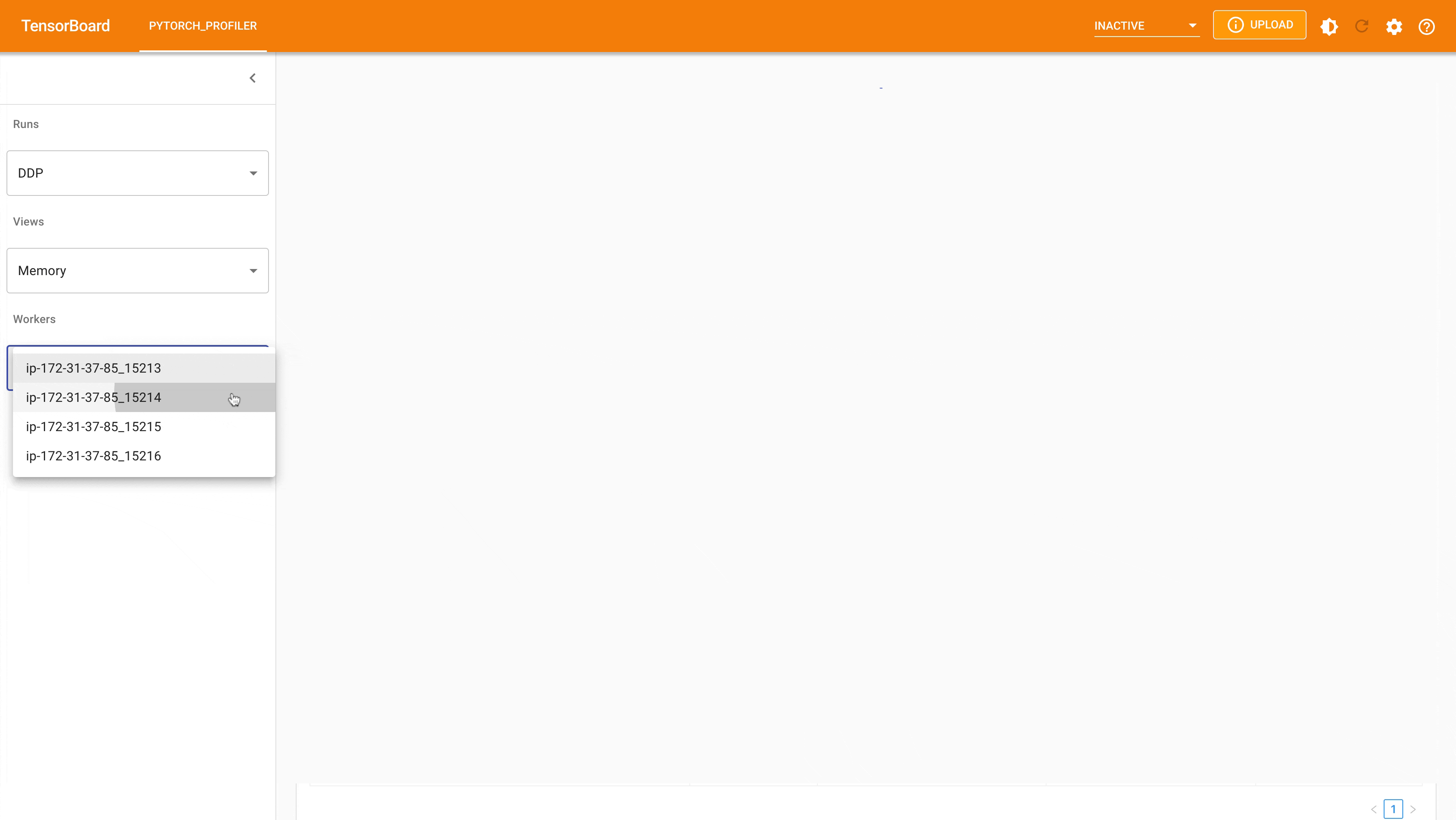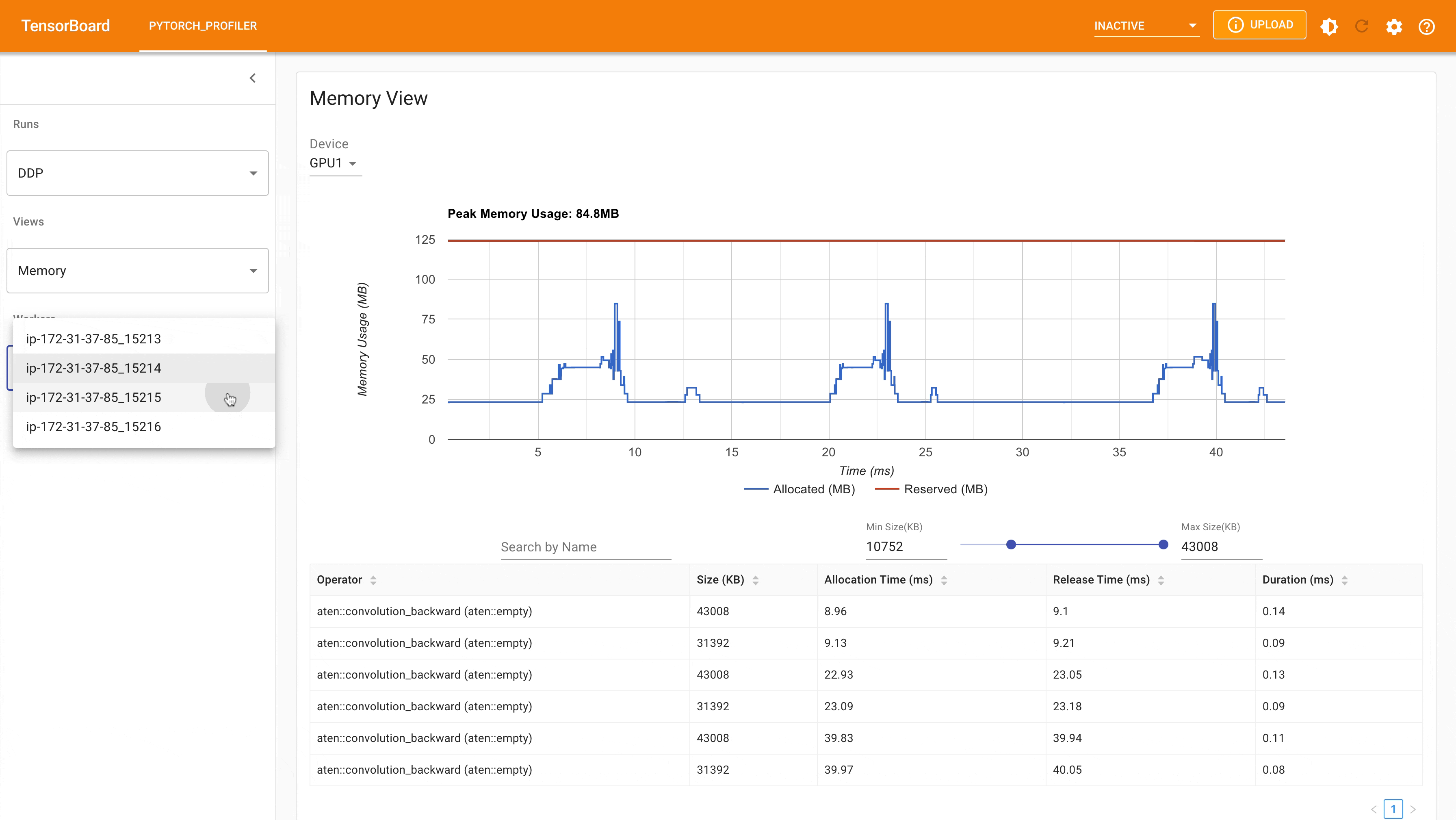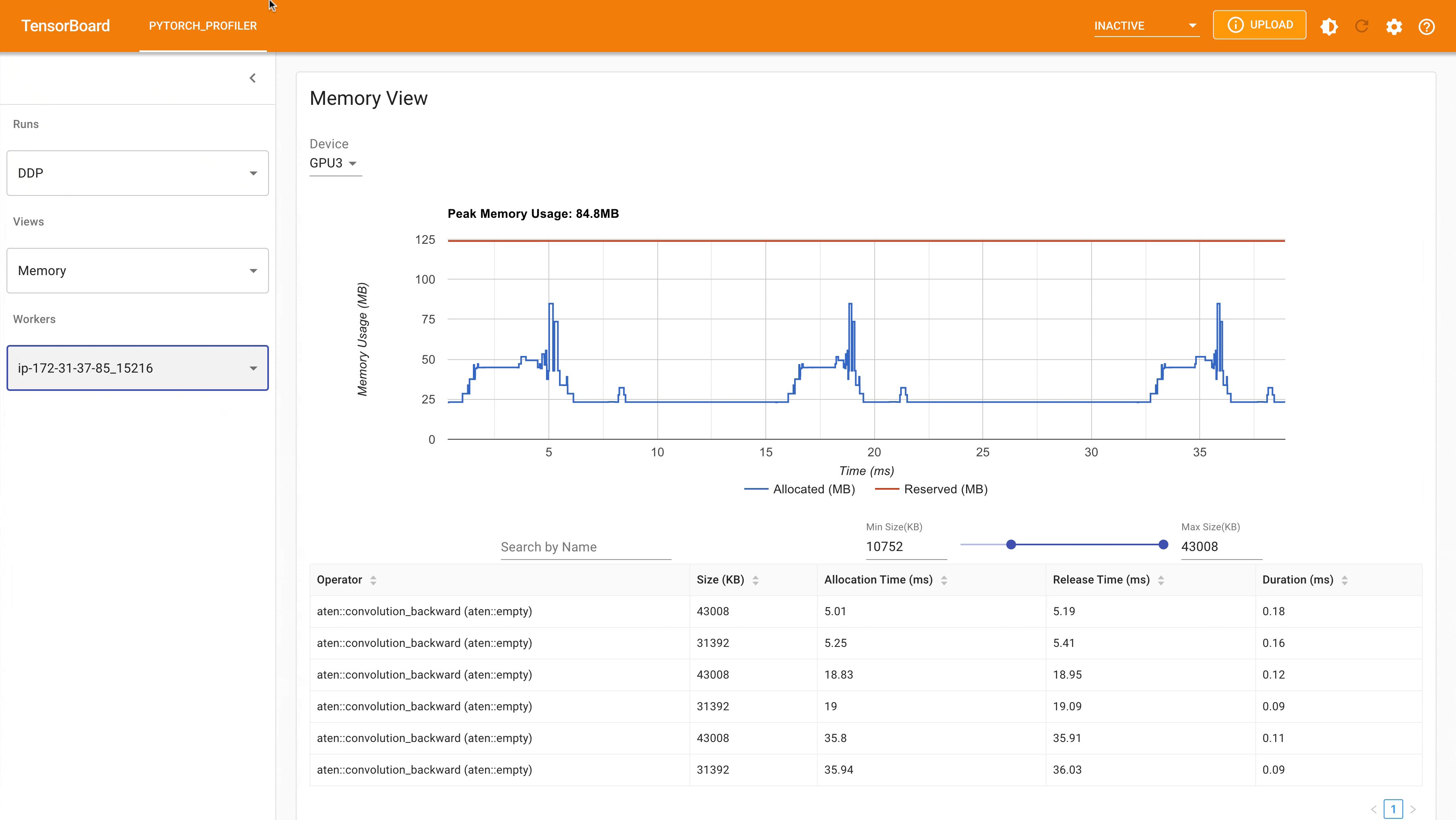
使用自动封装策略的 DDP 峰值内存使用量¶
考虑到我们在这里定义的玩具示例和微小的 MNIST 模型,我们可以观察到 DDP 和 FSDP 峰值内存使用量之间的差异。在 DDP 中,每个进程都持有一个模型的副本,因此内存占用量更高;而 FSDP 将模型参数、优化器状态和梯度分片到 DDP 进程中,内存占用量更小。使用带有 auto_wrap policy 的 FSDP 的峰值内存使用量最低,其次是 FSDP 和 DDP。
此外,从时间上看,考虑到小型模型并在单机上运行训练,带有和不带 auto_wrap policy 的 FSDP 几乎与 DDP 一样快。此示例不代表大多数实际应用,有关 DDP 和 FSDP 的详细分析和比较,请参阅这篇博客文章。
