


注意
点击此处下载完整的示例代码
从零开始学自然语言处理:使用字符级 RNN 对名字进行分类¶
创建日期: 2017 年 3 月 24 日 | 最后更新: 2025 年 3 月 14 日 | 最后验证: 2024 年 11 月 5 日
作者: Sean Robertson
本教程是一个三部分系列的一部分
我们将构建并训练一个基本的字符级循环神经网络 (RNN) 来对单词进行分类。本教程与另外两个“从零开始”的自然语言处理 (NLP) 教程从零开始学自然语言处理:使用字符级 RNN 生成名字和从零开始学自然语言处理:使用序列到序列网络和注意力机制进行翻译一起,展示了如何预处理数据以建模 NLP。特别是,这些教程展示了如何以低层次处理数据来建模 NLP。
字符级 RNN 将单词读取为一系列字符 - 在每个步骤输出一个预测和“隐藏状态”,并将其先前的隐藏状态馈送到下一个步骤中。我们将最终预测作为输出,即单词所属的类别。
具体来说,我们将训练数据集包含来自 18 种语言的数千个姓氏,并根据拼写预测名字来自哪种语言。
推荐准备¶
开始本教程之前,建议您已安装 PyTorch,并对 Python 编程语言和张量(Tensors)有基本的了解
使用 PyTorch 进行深度学习:60 分钟速成 总体上了解 PyTorch 并学习张量基础知识
通过示例学习 PyTorch 获取广泛而深入的概述
PyTorch for Former Torch Users 如果您曾是 Lua Torch 用户
了解 RNN 及其工作原理也很有用
循环神经网络令人惊叹的有效性 展示了大量现实生活中的示例
理解 LSTM 网络 专门关于 LSTM,但也提供关于 RNN 的通用信息
准备 Torch¶
设置 torch,使其默认使用正确的设备,并根据您的硬件(CPU 或 CUDA)使用 GPU 加速。
import torch
# Check if CUDA is available
device = torch.device('cpu')
if torch.cuda.is_available():
device = torch.device('cuda')
torch.set_default_device(device)
print(f"Using device = {torch.get_default_device()}")
Using device = cuda:0
准备数据¶
从此处下载数据并将其解压到当前目录。
data/names 目录中包含 18 个文本文件,文件名格式为 [Language].txt。每个文件包含许多名字,每行一个,大部分已罗马化(但我们仍然需要从 Unicode 转换为 ASCII)。
第一步是定义和清理我们的数据。首先,我们需要将 Unicode 转换为纯 ASCII 以限制 RNN 输入层。这通过将 Unicode 字符串转换为 ASCII 并只允许一小部分允许的字符来实现。
import string
import unicodedata
# We can use "_" to represent an out-of-vocabulary character, that is, any character we are not handling in our model
allowed_characters = string.ascii_letters + " .,;'" + "_"
n_letters = len(allowed_characters)
# Turn a Unicode string to plain ASCII, thanks to https://stackoverflow.com/a/518232/2809427
def unicodeToAscii(s):
return ''.join(
c for c in unicodedata.normalize('NFD', s)
if unicodedata.category(c) != 'Mn'
and c in allowed_characters
)
这是一个将 Unicode 字母名字转换为纯 ASCII 的示例。这简化了输入层
print (f"converting 'Ślusàrski' to {unicodeToAscii('Ślusàrski')}")
converting 'Ślusàrski' to Slusarski
将名字转换为张量(Tensors)¶
现在我们已经组织好所有名字,我们需要将它们转换为张量才能使用它们。
为了表示单个字母,我们使用大小为 <1 x n_letters> 的“one-hot 向量”。one-hot 向量除了当前字母索引处为 1 外,其余均为 0,例如 "b" = <0 1 0 0 0 ...>。
为了构成一个单词,我们将这些向量连接成一个 2D 矩阵 <line_length x 1 x n_letters>。
额外的维度 1 是因为 PyTorch 假定所有内容都是批量的 - 我们这里仅使用批量大小为 1。
# Find letter index from all_letters, e.g. "a" = 0
def letterToIndex(letter):
# return our out-of-vocabulary character if we encounter a letter unknown to our model
if letter not in allowed_characters:
return allowed_characters.find("_")
else:
return allowed_characters.find(letter)
# Turn a line into a <line_length x 1 x n_letters>,
# or an array of one-hot letter vectors
def lineToTensor(line):
tensor = torch.zeros(len(line), 1, n_letters)
for li, letter in enumerate(line):
tensor[li][0][letterToIndex(letter)] = 1
return tensor
这里有一些如何对单个字符或多个字符字符串使用 lineToTensor() 的示例。
print (f"The letter 'a' becomes {lineToTensor('a')}") #notice that the first position in the tensor = 1
print (f"The name 'Ahn' becomes {lineToTensor('Ahn')}") #notice 'A' sets the 27th index to 1
The letter 'a' becomes tensor([[[1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0.]]], device='cuda:0')
The name 'Ahn' becomes tensor([[[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0.]],
[[0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0.]],
[[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0.]]], device='cuda:0')
恭喜您,您已经为这项学习任务构建了基础张量对象!您可以使用类似的方法处理其他文本相关的 RNN 任务。
接下来,我们需要将所有示例组合成一个数据集,以便我们可以训练、测试和验证我们的模型。为此,我们将使用 Dataset and DataLoader 类来存储我们的数据集。每个 Dataset 需要实现三个函数:__init__、__len__ 和 __getitem__。
from io import open
import glob
import os
import time
import torch
from torch.utils.data import Dataset
class NamesDataset(Dataset):
def __init__(self, data_dir):
self.data_dir = data_dir #for provenance of the dataset
self.load_time = time.localtime #for provenance of the dataset
labels_set = set() #set of all classes
self.data = []
self.data_tensors = []
self.labels = []
self.labels_tensors = []
#read all the ``.txt`` files in the specified directory
text_files = glob.glob(os.path.join(data_dir, '*.txt'))
for filename in text_files:
label = os.path.splitext(os.path.basename(filename))[0]
labels_set.add(label)
lines = open(filename, encoding='utf-8').read().strip().split('\n')
for name in lines:
self.data.append(name)
self.data_tensors.append(lineToTensor(name))
self.labels.append(label)
#Cache the tensor representation of the labels
self.labels_uniq = list(labels_set)
for idx in range(len(self.labels)):
temp_tensor = torch.tensor([self.labels_uniq.index(self.labels[idx])], dtype=torch.long)
self.labels_tensors.append(temp_tensor)
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
data_item = self.data[idx]
data_label = self.labels[idx]
data_tensor = self.data_tensors[idx]
label_tensor = self.labels_tensors[idx]
return label_tensor, data_tensor, data_label, data_item
在这里,我们可以将示例数据加载到 NamesDataset 中
alldata = NamesDataset("data/names")
print(f"loaded {len(alldata)} items of data")
print(f"example = {alldata[0]}")
loaded 20074 items of data
example = (tensor([2], device='cuda:0'), tensor([[[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0.]],
[[0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0.]],
[[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0.]],
[[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0.]],
[[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0.]],
[[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0.]]], device='cuda:0'), 'Arabic', 'Khoury')
- 使用数据集对象,我们可以轻松地将数据分成训练集和测试集。这里我们创建了一个 80/20
分割,但
torch.utils.data提供了更多有用的工具。这里我们指定一个生成器,因为我们需要使用与 PyTorch 上面默认的设备相同的设备。
上面默认的设备。
train_set, test_set = torch.utils.data.random_split(alldata, [.85, .15], generator=torch.Generator(device=device).manual_seed(2024))
print(f"train examples = {len(train_set)}, validation examples = {len(test_set)}")
train examples = 17063, validation examples = 3011
现在我们拥有一个包含 20074 个示例的基础数据集,其中每个示例都是标签和名字的配对。我们还将数据集分成了训练集和测试集,以便我们可以验证构建的模型。
创建网络¶
在使用 autograd 之前,在 Torch 中创建循环神经网络需要将层的参数在多个时间步上进行克隆。这些层持有隐藏状态和梯度,现在这些都完全由图本身处理。这意味着您可以以非常“纯粹”的方式实现 RNN,就像常规的前馈层一样。
此 CharRNN 类实现了具有三个组件的 RNN。首先,我们使用 nn.RNN 实现。接下来,我们定义一个将 RNN 隐藏层映射到我们输出的层。最后,我们应用一个 softmax 函数。使用 nn.RNN 带来了显著的性能提升,例如 cuDNN 加速的内核,而如果将每个层实现为 nn.Linear 则不然。这也简化了 forward() 中的实现。
import torch.nn as nn
import torch.nn.functional as F
class CharRNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(CharRNN, self).__init__()
self.rnn = nn.RNN(input_size, hidden_size)
self.h2o = nn.Linear(hidden_size, output_size)
self.softmax = nn.LogSoftmax(dim=1)
def forward(self, line_tensor):
rnn_out, hidden = self.rnn(line_tensor)
output = self.h2o(hidden[0])
output = self.softmax(output)
return output
然后我们可以创建一个具有 58 个输入节点、128 个隐藏节点和 18 个输出的 RNN
n_hidden = 128
rnn = CharRNN(n_letters, n_hidden, len(alldata.labels_uniq))
print(rnn)
CharRNN(
(rnn): RNN(58, 128)
(h2o): Linear(in_features=128, out_features=18, bias=True)
(softmax): LogSoftmax(dim=1)
)
之后,我们可以将张量传递给 RNN 以获得预测输出。随后,我们使用辅助函数 label_from_output 来导出类别的文本标签。
def label_from_output(output, output_labels):
top_n, top_i = output.topk(1)
label_i = top_i[0].item()
return output_labels[label_i], label_i
input = lineToTensor('Albert')
output = rnn(input) #this is equivalent to ``output = rnn.forward(input)``
print(output)
print(label_from_output(output, alldata.labels_uniq))
tensor([[-2.8627, -2.8503, -2.8578, -3.0326, -2.8298, -2.8469, -2.9527, -2.9330,
-2.9295, -2.9728, -2.8209, -2.7876, -2.9343, -2.9412, -2.8902, -2.9107,
-2.8262, -2.8812]], device='cuda:0', grad_fn=<LogSoftmaxBackward0>)
('Italian', 11)
训练¶
训练网络¶
现在训练这个网络所需要做的就是向它展示大量示例,让它进行猜测,然后告诉它是否猜错了。
我们通过定义一个 train() 函数来实现这一点,该函数使用小批量对给定数据集进行训练。RNN 的训练方式与其他网络类似;因此,为了完整性,这里包含了一个批量训练方法。循环 (for i in batch) 计算批量中每个项目的损失,然后调整权重。此操作重复进行,直到达到指定的 epoch 数。
import random
import numpy as np
def train(rnn, training_data, n_epoch = 10, n_batch_size = 64, report_every = 50, learning_rate = 0.2, criterion = nn.NLLLoss()):
"""
Learn on a batch of training_data for a specified number of iterations and reporting thresholds
"""
# Keep track of losses for plotting
current_loss = 0
all_losses = []
rnn.train()
optimizer = torch.optim.SGD(rnn.parameters(), lr=learning_rate)
start = time.time()
print(f"training on data set with n = {len(training_data)}")
for iter in range(1, n_epoch + 1):
rnn.zero_grad() # clear the gradients
# create some minibatches
# we cannot use dataloaders because each of our names is a different length
batches = list(range(len(training_data)))
random.shuffle(batches)
batches = np.array_split(batches, len(batches) //n_batch_size )
for idx, batch in enumerate(batches):
batch_loss = 0
for i in batch: #for each example in this batch
(label_tensor, text_tensor, label, text) = training_data[i]
output = rnn.forward(text_tensor)
loss = criterion(output, label_tensor)
batch_loss += loss
# optimize parameters
batch_loss.backward()
nn.utils.clip_grad_norm_(rnn.parameters(), 3)
optimizer.step()
optimizer.zero_grad()
current_loss += batch_loss.item() / len(batch)
all_losses.append(current_loss / len(batches) )
if iter % report_every == 0:
print(f"{iter} ({iter / n_epoch:.0%}): \t average batch loss = {all_losses[-1]}")
current_loss = 0
return all_losses
现在我们可以使用小批量训练数据集,指定 epoch 数。为了加快构建速度,此示例的 epoch 数已减少。使用不同的参数可以获得更好的结果。
start = time.time()
all_losses = train(rnn, train_set, n_epoch=27, learning_rate=0.15, report_every=5)
end = time.time()
print(f"training took {end-start}s")
training on data set with n = 17063
5 (19%): average batch loss = 0.879241389256809
10 (37%): average batch loss = 0.6880160899297428
15 (56%): average batch loss = 0.5751259022999389
20 (74%): average batch loss = 0.49494854703054325
25 (93%): average batch loss = 0.4307829880331761
training took 340.6842153072357s
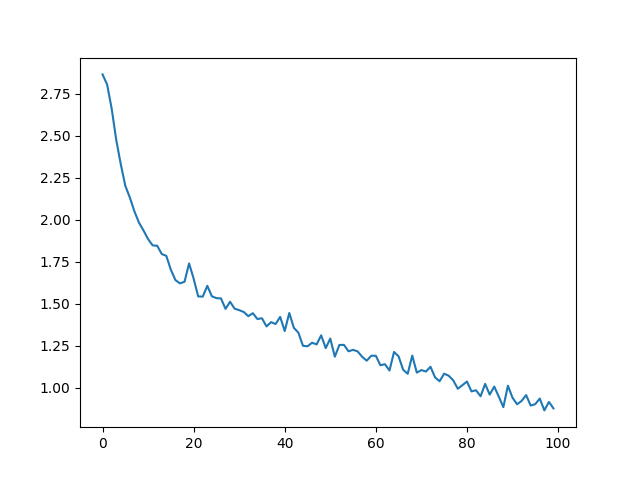
绘制结果¶
绘制来自 all_losses 的历史损失曲线可以显示网络的学习情况
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
plt.figure()
plt.plot(all_losses)
plt.show()
评估结果¶
为了了解网络在不同类别上的表现,我们将创建一个混淆矩阵(confusion matrix),显示对于每个实际语言(行),网络预测的语言(列)。要计算混淆矩阵,需要通过 evaluate() 运行大量样本,evaluate() 与 train() 相同,只是没有反向传播。
def evaluate(rnn, testing_data, classes):
confusion = torch.zeros(len(classes), len(classes))
rnn.eval() #set to eval mode
with torch.no_grad(): # do not record the gradients during eval phase
for i in range(len(testing_data)):
(label_tensor, text_tensor, label, text) = testing_data[i]
output = rnn(text_tensor)
guess, guess_i = label_from_output(output, classes)
label_i = classes.index(label)
confusion[label_i][guess_i] += 1
# Normalize by dividing every row by its sum
for i in range(len(classes)):
denom = confusion[i].sum()
if denom > 0:
confusion[i] = confusion[i] / denom
# Set up plot
fig = plt.figure()
ax = fig.add_subplot(111)
cax = ax.matshow(confusion.cpu().numpy()) #numpy uses cpu here so we need to use a cpu version
fig.colorbar(cax)
# Set up axes
ax.set_xticks(np.arange(len(classes)), labels=classes, rotation=90)
ax.set_yticks(np.arange(len(classes)), labels=classes)
# Force label at every tick
ax.xaxis.set_major_locator(ticker.MultipleLocator(1))
ax.yaxis.set_major_locator(ticker.MultipleLocator(1))
# sphinx_gallery_thumbnail_number = 2
plt.show()
evaluate(rnn, test_set, classes=alldata.labels_uniq)
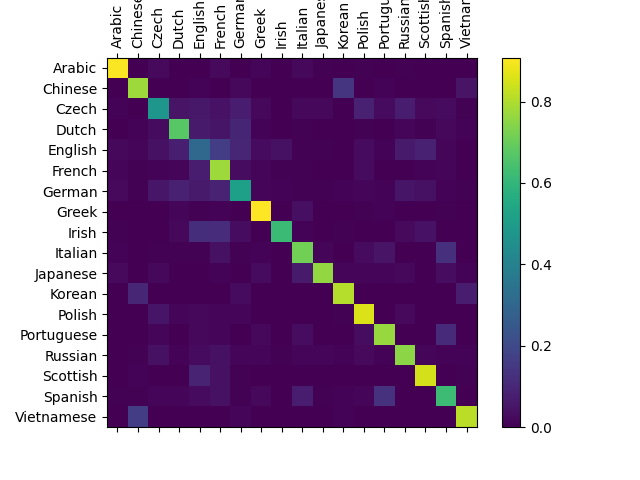
您可以在主对角线之外找出亮点,显示它错误猜测的语言,例如将朝鲜语猜成中文,将意大利语猜成西班牙语。它在希腊语上表现非常好,而在英语上表现非常差(可能是因为与其它语言有重叠)。
练习¶
使用更大和/或形状更好的网络获得更好的结果
调整超参数以提高性能,例如更改 epoch 数、批量大小和学习率
尝试
nn.LSTM和nn.GRU层修改层的大小,例如增加或减少隐藏节点的数量或添加额外的线性层
将这些 RNN 中的多个组合成一个更高层次的网络
尝试使用不同的 line -> label 数据集,例如
任意单词 -> 语言
名字 -> 性别
角色名 -> 作者
页面标题 -> 博客或 subreddit
脚本总运行时间: ( 5 分 46.422 秒)
