


注意
点击这里下载完整的示例代码
如何通过将优化器步骤融入反向传播来节省内存¶
创建于: Oct 02, 2023 | 最后更新于: Jan 16, 2024 | 最后验证于: Nov 05, 2024
大家好!本教程旨在展示一种通过减少**梯度**占用的内存来降低训练循环内存占用量的方法。假设你有一个模型,并且正在寻找优化内存的方法,以避免 Out of Memory (OOM) 错误,或者只是为了更好地利用 GPU。好吧,你_可能_很幸运(如果梯度占用了你内存的一部分,并且你不需要进行梯度累积)。我们将探讨以下内容:
在训练或微调循环中占用内存的因素,
如何捕获和可视化内存快照以确定瓶颈,
新的
Tensor.register_post_accumulate_grad_hook(hook)API,最后,如何用 10 行代码将所有内容整合在一起以实现内存节省。
要运行本教程,你需要:
安装了
torchvision的 PyTorch 2.1.0 或更高版本如果你想在本地运行内存可视化,需要 1 个 CUDA GPU。否则,这项技术在任何设备上都会有类似的收益。
首先导入所需的模块和模型。我们将使用 torchvision 中的 Vision Transformer 模型,但你可以随意替换成你自己的模型。我们还将使用 torch.optim.Adam 作为优化器,当然,你也可以随意替换成你自己的优化器。
import torch
from torchvision import models
from pickle import dump
model = models.vit_l_16(weights='DEFAULT').cuda()
optimizer = torch.optim.Adam(model.parameters())
Downloading: "https://download.pytorch.org/models/vit_l_16-852ce7e3.pth" to /var/lib/ci-user/.cache/torch/hub/checkpoints/vit_l_16-852ce7e3.pth
0%| | 0.00/1.13G [00:00<?, ?B/s]
3%|3 | 36.1M/1.13G [00:00<00:03, 379MB/s]
7%|6 | 79.6M/1.13G [00:00<00:02, 424MB/s]
11%|# | 123M/1.13G [00:00<00:02, 436MB/s]
14%|#4 | 166M/1.13G [00:00<00:02, 445MB/s]
18%|#8 | 210M/1.13G [00:00<00:02, 450MB/s]
22%|##1 | 254M/1.13G [00:00<00:02, 452MB/s]
26%|##5 | 298M/1.13G [00:00<00:01, 454MB/s]
29%|##9 | 341M/1.13G [00:00<00:01, 455MB/s]
33%|###3 | 385M/1.13G [00:00<00:01, 456MB/s]
37%|###6 | 429M/1.13G [00:01<00:01, 457MB/s]
41%|#### | 472M/1.13G [00:02<00:06, 113MB/s]
44%|####4 | 515M/1.13G [00:02<00:04, 146MB/s]
48%|####7 | 552M/1.13G [00:02<00:03, 173MB/s]
51%|##### | 587M/1.13G [00:03<00:07, 83.8MB/s]
54%|#####4 | 631M/1.13G [00:03<00:04, 114MB/s]
58%|#####8 | 675M/1.13G [00:03<00:03, 150MB/s]
62%|######1 | 719M/1.13G [00:03<00:02, 190MB/s]
66%|######5 | 763M/1.13G [00:03<00:01, 232MB/s]
70%|######9 | 807M/1.13G [00:03<00:01, 274MB/s]
73%|#######3 | 851M/1.13G [00:03<00:01, 313MB/s]
77%|#######7 | 895M/1.13G [00:04<00:00, 346MB/s]
81%|######## | 940M/1.13G [00:04<00:00, 375MB/s]
85%|########4 | 982M/1.13G [00:04<00:00, 380MB/s]
88%|########8 | 1.00G/1.13G [00:04<00:00, 395MB/s]
92%|#########1| 1.04G/1.13G [00:04<00:00, 411MB/s]
96%|#########5| 1.09G/1.13G [00:04<00:00, 424MB/s]
99%|#########9| 1.13G/1.13G [00:05<00:00, 112MB/s]
100%|##########| 1.13G/1.13G [00:05<00:00, 214MB/s]
现在让我们定义典型的训练循环。训练时应使用真实图像,但为了本教程的目的,我们传入了伪造的输入,不担心加载任何实际数据。
IMAGE_SIZE = 224
def train(model, optimizer):
# create our fake image input: tensor shape is batch_size, channels, height, width
fake_image = torch.rand(1, 3, IMAGE_SIZE, IMAGE_SIZE).cuda()
# call our forward and backward
loss = model.forward(fake_image)
loss.sum().backward()
# optimizer update
optimizer.step()
optimizer.zero_grad()
训练期间的内存使用¶
我们即将查看一些内存快照,因此应该做好适当分析它们的准备。通常,训练内存包括:
模型参数(大小 P)
为反向传播保存的激活(大小 A)
梯度,其大小与模型参数相同,因此大小 G = P。
优化器状态,其大小与参数大小成比例。在本例中,Adam 的状态需要模型参数的 2 倍,因此大小 O = 2P。
中间张量,它们在整个计算过程中分配。我们暂时不用担心它们,因为它们通常很小且短暂。
捕获和可视化内存快照¶
让我们获取一个内存快照!在你的代码运行时,考虑一下你期望 CUDA 内存时间线是什么样的。
# tell CUDA to start recording memory allocations
torch.cuda.memory._record_memory_history(enabled='all')
# train 3 steps
for _ in range(3):
train(model, optimizer)
# save a snapshot of the memory allocations
s = torch.cuda.memory._snapshot()
with open(f"snapshot.pickle", "wb") as f:
dump(s, f)
# tell CUDA to stop recording memory allocations now
torch.cuda.memory._record_memory_history(enabled=None)
现在通过拖放 snapshot.pickle 文件,在 CUDA 内存可视化工具 https://pytorch.ac.cn/memory_viz 中打开快照。内存时间线是否符合你的预期?
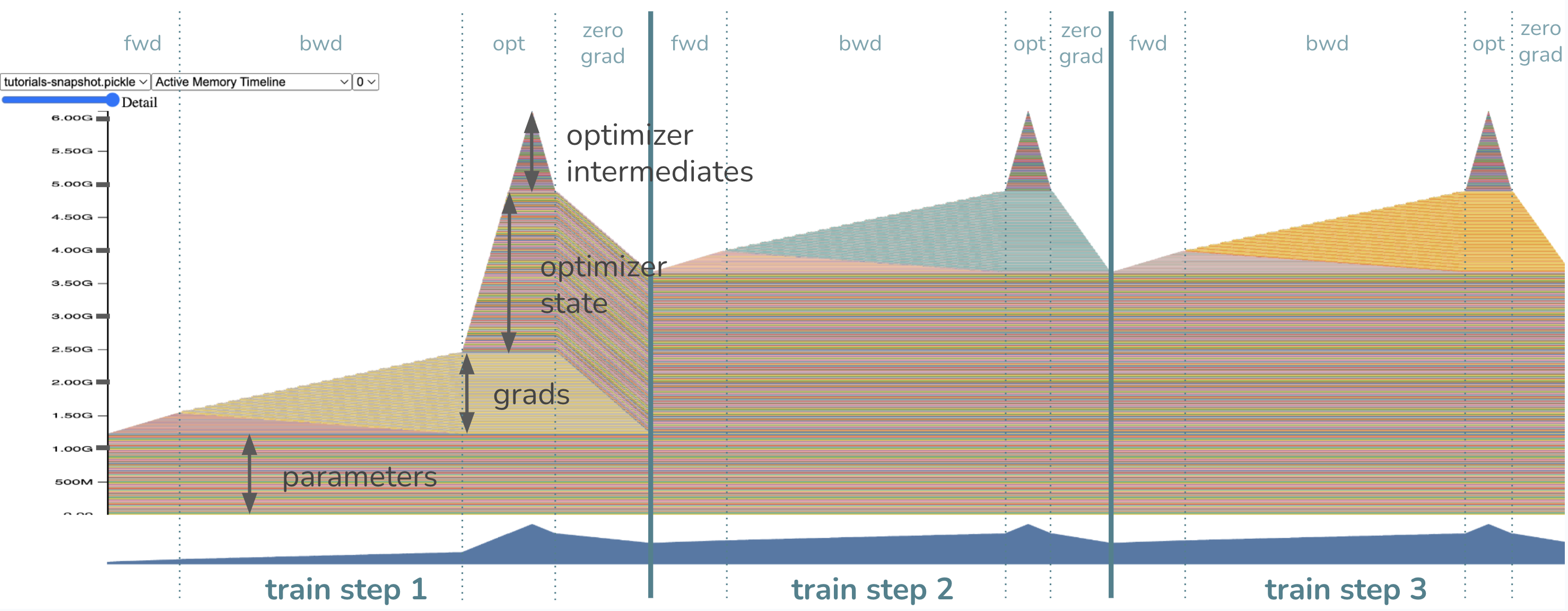
模型参数在训练步骤之前已经加载到内存中,因此我们首先看到一部分内存分配给了权重。当我们开始前向传播时,内存会逐渐分配给激活,即我们为了在反向传播中计算梯度而保存的张量。一旦我们开始反向传播,激活会逐渐释放,而梯度内存开始累积。
最后,当优化器开始工作时,其状态将被延迟初始化,因此我们应该只在第一个训练循环的优化器步骤中看到优化器状态内存逐渐增加。在未来的循环中,优化器内存将保留并在原地更新。然后,在每次训练循环结束时调用 zero_grad 时,相应的梯度内存会被释放。
在这个训练循环中,内存瓶颈在哪里?或者换句话说,峰值内存出现在哪里?
峰值内存使用是在优化器步骤期间!请注意,此时的内存正如预期,包括约 1.2GB 参数、约 1.2GB 梯度和约 2.4GB=2*1.2GB 优化器状态。最后的约 1.2GB 来自 Adam 优化器所需的中间内存,总计峰值内存约 6GB。理论上,如果你设置 Adam(model.parameters(), foreach=False),你可以消除对最后 1.2GB 优化器中间内存的需求,这将牺牲运行时性能来换取内存。如果你通过关闭 foreach 运行时优化获得了足够的内存节省,那很好,但如果你想了解本教程如何帮助你做得更好,请继续阅读!通过我们即将介绍的技术,我们将通过消除对约 1.2GB**梯度内存**以及**优化器中间内存**的需求来降低峰值内存。现在,你认为新的峰值内存会是多少?答案将在下一个快照中揭晓。
免责声明:这项技术**并非**适用于所有人¶
在我们过于兴奋之前,必须考虑这项技术是否适用于你的用例。这并不是万灵药!将优化器步骤融入反向传播的技术仅针对减少梯度内存(以及作为副作用也减少优化器中间内存)。因此,梯度占用的内存越显著,内存减少就越重要。在我们上面的示例中,梯度占用了内存的 20%,相当可观!
对你来说可能并非如此,例如,如果你的权重已经很小(比如由于应用了 LoRa),那么梯度在你的训练循环中不会占用太多空间,收益就没那么令人兴奋了。在这种情况下,你应该首先尝试其他技术,如激活检查点、分布式训练、量化或减小批量大小。然后,当梯度再次成为瓶颈时,再回到本教程!
还在吗?太好了,让我们介绍新的 Tensor.register_post_accumulate_grad_hook(hook) API 在 Tensor 上。
Tensor.register_post_accumulate_grad_hook(hook) API 和我们的技术¶
我们的技术依赖于在 backward() 期间不必保存梯度。相反,一旦梯度累积完成,我们将立即将优化器应用于相应的参数并完全丢弃该梯度!这消除了在优化器步骤之前需要保留一个大的梯度缓冲区的需求。
那么我们如何才能启用这种更积极地应用优化器的行为呢?在我们的 2.1 版本中,我们添加了一个新的 API torch.Tensor.register_post_accumulate_grad_hook(),它允许我们在 Tensor 的 .grad 字段累积完成后添加一个钩子 (hook)。我们将把优化器步骤封装到这个钩子中。怎么做?
如何用 10 行代码将所有内容整合在一起¶
还记得我们开头的模型和优化器设置吗?我把它们注释掉放在下面,这样我们就不会浪费资源重新运行代码了。
model = models.vit_l_16(weights='DEFAULT').cuda()
optimizer = torch.optim.Adam(model.parameters())
# Instead of having just *one* optimizer, we will have a ``dict`` of optimizers
# for every parameter so we could reference them in our hook.
optimizer_dict = {p: torch.optim.Adam([p], foreach=False) for p in model.parameters()}
# Define our hook, which will call the optimizer ``step()`` and ``zero_grad()``
def optimizer_hook(parameter) -> None:
optimizer_dict[parameter].step()
optimizer_dict[parameter].zero_grad()
# Register the hook onto every parameter
for p in model.parameters():
p.register_post_accumulate_grad_hook(optimizer_hook)
# Now remember our previous ``train()`` function? Since the optimizer has been
# fused into the backward, we can remove the optimizer step and zero_grad calls.
def train(model):
# create our fake image input: tensor shape is batch_size, channels, height, width
fake_image = torch.rand(1, 3, IMAGE_SIZE, IMAGE_SIZE).cuda()
# call our forward and backward
loss = model.forward(fake_image)
loss.sum().backward()
# optimizer update --> no longer needed!
# optimizer.step()
# optimizer.zero_grad()
在我们的示例模型中,这大概需要修改 10 行代码,这很不错。然而,对于实际模型来说,将优化器替换为优化器字典可能是一个相当侵入性的更改,特别是对于那些在训练周期中使用了 ``LRScheduler```` 或操作优化器配置的用户。将这个 API 与这些更改一起使用将更加复杂,并且可能需要将更多配置移到全局状态,但这并非不可能。话虽如此,PyTorch 的下一步是让这个 API 更容易与 LRScheduler 以及你已经习惯的其他特性一起采用。
但是,让我回到说服你这项技术是值得的。我们将咨询我们的朋友,内存快照。
# delete optimizer memory from before to get a clean slate for the next
# memory snapshot
del optimizer
# tell CUDA to start recording memory allocations
torch.cuda.memory._record_memory_history(enabled='all')
# train 3 steps. note that we no longer pass the optimizer into train()
for _ in range(3):
train(model)
# save a snapshot of the memory allocations
s = torch.cuda.memory._snapshot()
with open(f"snapshot-opt-in-bwd.pickle", "wb") as f:
dump(s, f)
# tell CUDA to stop recording memory allocations now
torch.cuda.memory._record_memory_history(enabled=None)
是的,花点时间将你的快照拖到 CUDA Memory Visualizer 中。
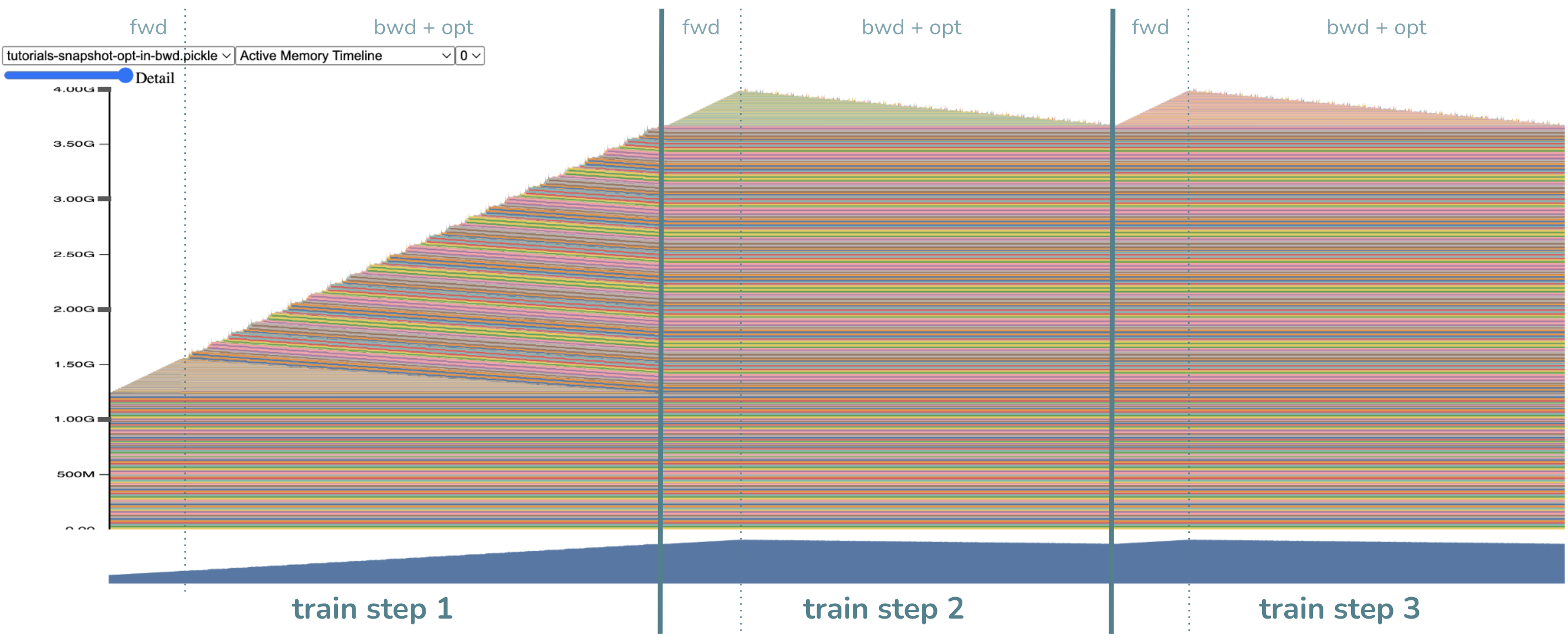
- 几项主要观察
没有了优化器步骤!没错……我们把它融入了反向传播。
同样,反向传播持续时间更长,并且中间计算的随机分配更多。这是预期的,因为优化器步骤需要中间计算。
最重要的是!峰值内存降低了!现在是约 4GB(希望这与你之前的预期非常接近)。
请注意,与之前相比,现在没有为梯度分配任何大的内存块,这节省了约 1.2GB 的内存。相反,我们将优化器步骤尽可能提前,在每个梯度计算完成后非常快速地释放了它们。太棒了!顺便说一下,另外约 1.2GB 的内存节省来自将优化器分解为按参数划分的优化器,因此中间内存也按比例缩小了。这个细节比梯度内存节省不那么重要,因为即使不使用这项技术,你也可以通过关闭 foreach=False 来获得优化器中间内存的节省。
你可能正确地想知道:如果我们节省了 2.4GB 的内存,为什么峰值内存不是 6GB - 2.4GB = 3.6GB?嗯,峰值位置变了!现在的峰值出现在反向传播步骤开始附近,那时内存中仍然有激活;而之前,峰值出现在优化器步骤期间,那时激活已经被释放。因此,约 4.0GB - 约 3.6GB = 约 0.4GB 的差异是由于激活内存。可以想象,这项技术可以与激活检查点相结合,以获得更多的内存收益。
结论¶
在本教程中,我们学习了通过新的 Tensor.register_post_accumulate_grad_hook() API 将优化器融入反向传播以节省内存的技术,以及何时应用这项技术(当梯度内存占用显著时)。在此过程中,我们还学习了内存快照,这在内存优化中通常非常有用。
脚本总运行时间: ( 0 minutes 11.480 seconds)
