


DeviceMesh 入门¶
创建于:Jan 24, 2024 | 最后更新于:Feb 24, 2025 | 最后验证于:Nov 05, 2024
作者: Iris Zhang, Wanchao Liang
注意
 在 github 中查看和编辑本教程。
在 github 中查看和编辑本教程。
前提条件
Python 3.8 - 3.11
PyTorch 2.2
为分布式训练设置分布式通信器,即 NVIDIA Collective Communication Library (NCCL) 通信器,可能是一个重大的挑战。对于用户需要组合不同并行模式的工作负载,用户需要为每种并行解决方案手动设置和管理 NCCL 通信器(例如,ProcessGroup)。这个过程可能既复杂又容易出错。DeviceMesh 可以简化这个过程,使其更易于管理且不易出错。
什么是 DeviceMesh¶
DeviceMesh 是一个更高级别的抽象,用于管理 ProcessGroup。它允许用户轻松创建节点间和节点内进程组,而无需担心如何为不同的子进程组正确设置 rank。用户还可以通过 DeviceMesh 轻松管理底层进程组/设备,用于多维并行。
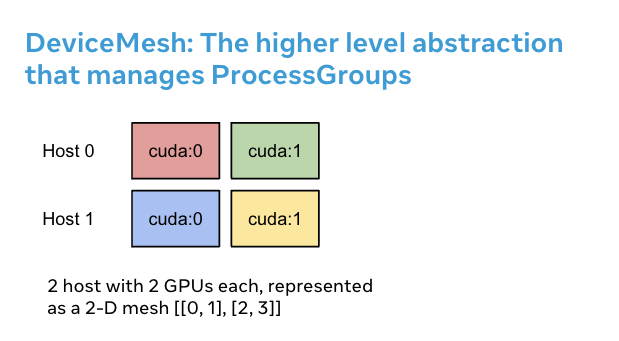
DeviceMesh 为何有用¶
DeviceMesh 在处理需要并行组合的多维并行(即 3D 并行)工作负载时非常有用。例如,当你的并行解决方案既需要跨主机通信,也需要每台主机内部通信时。上图显示,我们可以创建一个 2D mesh,它连接每台主机内部的设备,并在同构设置中将每台设备与其在其他主机上的对应设备连接起来。
如果没有 DeviceMesh,用户需要在应用任何并行之前手动设置 NCCL 通信器和每个进程上的 cuda 设备,这可能非常复杂。以下代码片段演示了如何在没有 DeviceMesh 的情况下设置一个混合分片 2D 并行模式。首先,我们需要手动计算分片组 (shard group) 和复制组 (replicate group)。然后,我们需要将正确的分片组和复制组分配给每个 rank。
import os
import torch
import torch.distributed as dist
# Understand world topology
rank = int(os.environ["RANK"])
world_size = int(os.environ["WORLD_SIZE"])
print(f"Running example on {rank=} in a world with {world_size=}")
# Create process groups to manage 2-D like parallel pattern
dist.init_process_group("nccl")
torch.cuda.set_device(rank)
# Create shard groups (e.g. (0, 1, 2, 3), (4, 5, 6, 7))
# and assign the correct shard group to each rank
num_node_devices = torch.cuda.device_count()
shard_rank_lists = list(range(0, num_node_devices // 2)), list(range(num_node_devices // 2, num_node_devices))
shard_groups = (
dist.new_group(shard_rank_lists[0]),
dist.new_group(shard_rank_lists[1]),
)
current_shard_group = (
shard_groups[0] if rank in shard_rank_lists[0] else shard_groups[1]
)
# Create replicate groups (for example, (0, 4), (1, 5), (2, 6), (3, 7))
# and assign the correct replicate group to each rank
current_replicate_group = None
shard_factor = len(shard_rank_lists[0])
for i in range(num_node_devices // 2):
replicate_group_ranks = list(range(i, num_node_devices, shard_factor))
replicate_group = dist.new_group(replicate_group_ranks)
if rank in replicate_group_ranks:
current_replicate_group = replicate_group
要运行上述代码片段,我们可以利用 PyTorch Elastic。让我们创建一个名为 2d_setup.py 的文件。然后,运行以下 torch elastic/torchrun 命令。
torchrun --nproc_per_node=8 --rdzv_id=100 --rdzv_endpoint=localhost:29400 2d_setup.py
注意
为简化演示,我们仅使用一个节点来模拟 2D 并行。注意,此代码片段也可用于多主机设置。
借助 init_device_mesh(),我们只需两行代码即可完成上述 2D 设置,并且如果需要,仍然可以访问底层的 ProcessGroup。
from torch.distributed.device_mesh import init_device_mesh
mesh_2d = init_device_mesh("cuda", (2, 4), mesh_dim_names=("replicate", "shard"))
# Users can access the underlying process group thru `get_group` API.
replicate_group = mesh_2d.get_group(mesh_dim="replicate")
shard_group = mesh_2d.get_group(mesh_dim="shard")
让我们创建一个名为 2d_setup_with_device_mesh.py 的文件。然后,运行以下 torch elastic/torchrun 命令。
torchrun --nproc_per_node=8 2d_setup_with_device_mesh.py
如何将 DeviceMesh 与 HSDP 结合使用¶
Hybrid Sharding Data Parallel (HSDP) 是一种 2D 策略,用于在主机内执行 FSDP,在主机间执行 DDP。
让我们看一个例子,了解 DeviceMesh 如何通过简单设置帮助将 HSDP 应用于你的模型。使用 DeviceMesh,用户无需手动创建和管理分片组和复制组。
import torch
import torch.nn as nn
from torch.distributed.device_mesh import init_device_mesh
from torch.distributed.fsdp import FullyShardedDataParallel as FSDP, ShardingStrategy
class ToyModel(nn.Module):
def __init__(self):
super(ToyModel, self).__init__()
self.net1 = nn.Linear(10, 10)
self.relu = nn.ReLU()
self.net2 = nn.Linear(10, 5)
def forward(self, x):
return self.net2(self.relu(self.net1(x)))
# HSDP: MeshShape(2, 4)
mesh_2d = init_device_mesh("cuda", (2, 4))
model = FSDP(
ToyModel(), device_mesh=mesh_2d, sharding_strategy=ShardingStrategy.HYBRID_SHARD
)
让我们创建一个名为 hsdp.py 的文件。然后,运行以下 torch elastic/torchrun 命令。
torchrun --nproc_per_node=8 hsdp.py
如何将 DeviceMesh 用于自定义并行解决方案¶
在进行大规模训练时,你可能会有更复杂的自定义并行训练组合。例如,你可能需要为不同的并行解决方案切分出子 mesh。DeviceMesh 允许用户从父 mesh 中切分出子 mesh,并重用父 mesh 初始化时已创建的 NCCL 通信器。
from torch.distributed.device_mesh import init_device_mesh
mesh_3d = init_device_mesh("cuda", (2, 2, 2), mesh_dim_names=("replicate", "shard", "tp"))
# Users can slice child meshes from the parent mesh.
hsdp_mesh = mesh_3d["replicate", "shard"]
tp_mesh = mesh_3d["tp"]
# Users can access the underlying process group thru `get_group` API.
replicate_group = hsdp_mesh["replicate"].get_group()
shard_group = hsdp_mesh["shard"].get_group()
tp_group = tp_mesh.get_group()
