


PyTorch 2 Export 量化通过 Inductor 在 Intel GPU 后端实现¶
作者: Yan Zhiwei, Wang Eikan, Zhang Liangang, Liu River, Cui Yifeng
前提条件¶
PyTorch 2.7 或更高版本
介绍¶
本教程介绍 XPUInductorQuantizer,其目标是为 Intel GPU 上的推理提供量化模型。XPUInductorQuantizer 使用 PyTorch Export 量化流程并将量化模型下层到 inductor。
PyTorch 2 Export 量化流程使用 torch.export 将模型捕获到图中,并在 ATen 图之上执行量化转换。这种方法预计将显著提高模型覆盖率,并具有更好的可编程性和简化的用户体验。TorchInductor 是一个编译器后端,它将由 TorchDynamo 生成的 FX Graph 转换为优化的 C++/Triton 内核。
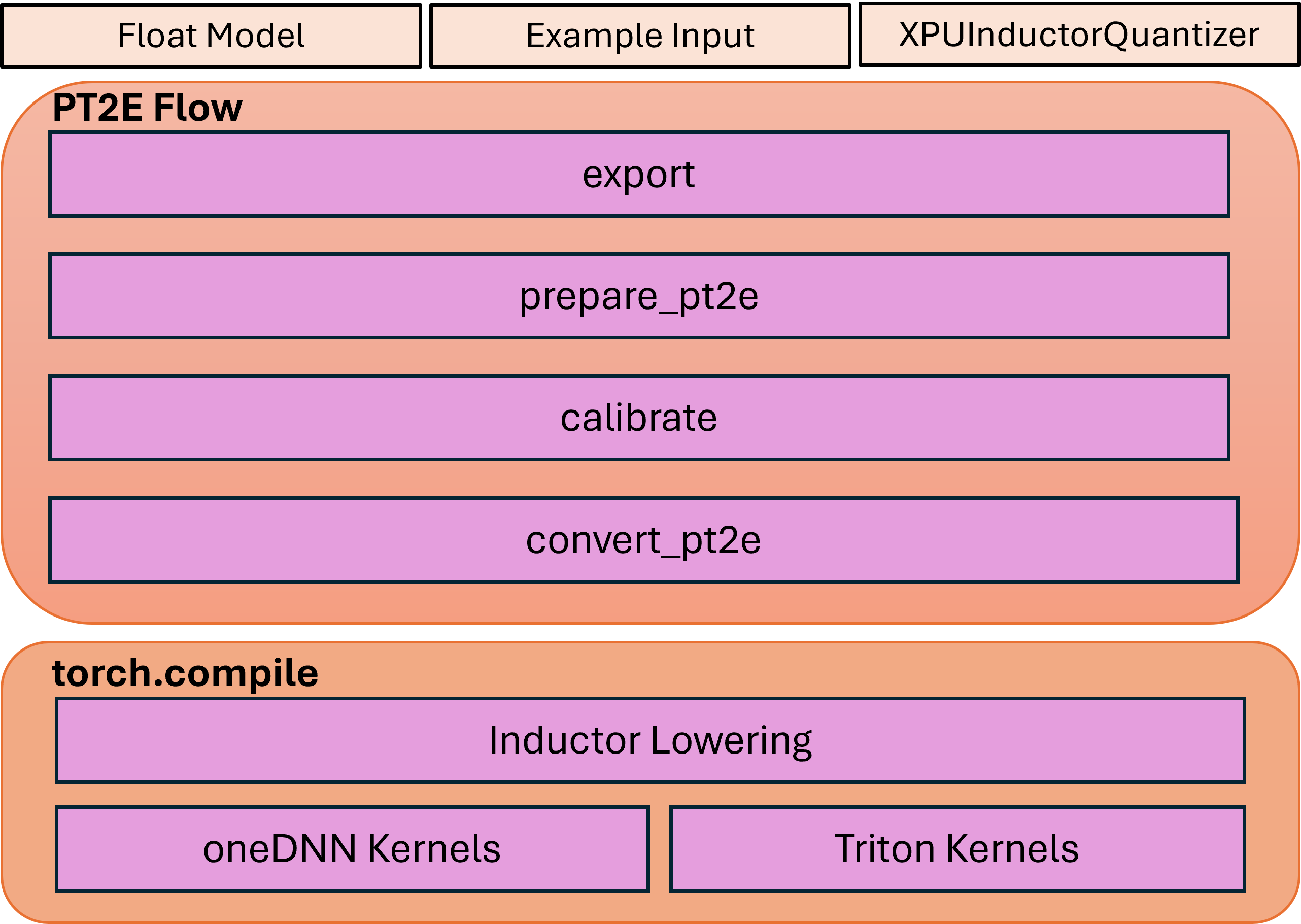
量化流程包含三个步骤
步骤 1:基于 torch export 机制从 eager 模型捕获 FX Graph。
步骤 2:基于捕获的 FX Graph 应用量化流程,包括定义后端特定的量化器、生成带有观察器的准备模型、执行准备模型的校准以及将准备模型转换为量化模型。
步骤 3:使用 API
torch.compile将量化模型下层到 inductor,这将调用 Triton 内核或 oneDNN GEMM/卷积内核。
该流程的高级架构如下所示
训练后量化¶
静态量化是我们目前唯一支持的方法。
建议通过 Intel GPU 通道安装以下依赖项
pip3 install torch torchvision torchaudio pytorch-triton-xpu --index-url https://download.pytorch.org/whl/xpu
请注意,由于 inductor 的 freeze 功能尚未默认开启,你必须使用 TORCHINDUCTOR_FREEZING=1 运行示例代码。
例如
TORCHINDUCTOR_FREEZING=1 python xpu_inductor_quantizer_example.py
1. 捕获 FX Graph¶
我们将首先执行必要的导入,从 eager 模块捕获 FX Graph。
import torch
import torchvision.models as models
from torch.ao.quantization.quantize_pt2e import prepare_pt2e, convert_pt2e
import torch.ao.quantization.quantizer.xpu_inductor_quantizer as xpuiq
from torch.ao.quantization.quantizer.xpu_inductor_quantizer import XPUInductorQuantizer
from torch.export import export_for_training
# Create the Eager Model
model_name = "resnet18"
model = models.__dict__[model_name](weights=models.ResNet18_Weights.DEFAULT)
# Set the model to eval mode
model = model.eval().to("xpu")
# Create the data, using the dummy data here as an example
traced_bs = 50
x = torch.randn(traced_bs, 3, 224, 224, device="xpu").contiguous(memory_format=torch.channels_last)
example_inputs = (x,)
# Capture the FX Graph to be quantized
with torch.no_grad():
exported_model = export_for_training(
model,
example_inputs,
).module()
接下来,我们将对 FX 模块进行量化。
2. 应用量化¶
捕获 FX 模块后,我们将导入用于 Intel GPU 的后端量化器并配置它来量化模型。
quantizer = XPUInductorQuantizer()
quantizer.set_global(xpuiq.get_default_xpu_inductor_quantization_config())
XPUInductorQuantizer 中的默认量化配置对激活和权重都使用有符号 8 位。张量采用逐张量(per-tensor)量化,而权重采用有符号 8 位逐通道(per-channel)量化。
可选地,除了使用非对称量化激活的默认量化配置外,还支持有符号 8 位对称量化激活,这有可能提供更好的性能。
from torch.ao.quantization.observer import HistogramObserver, PerChannelMinMaxObserver
from torch.ao.quantization.quantizer.quantizer import QuantizationSpec
from torch.ao.quantization.quantizer.xnnpack_quantizer_utils import QuantizationConfig
from typing import Any, Optional, TYPE_CHECKING
if TYPE_CHECKING:
from torch.ao.quantization.qconfig import _ObserverOrFakeQuantizeConstructor
def get_xpu_inductor_symm_quantization_config():
extra_args: dict[str, Any] = {"eps": 2**-12}
act_observer_or_fake_quant_ctr = HistogramObserver
act_quantization_spec = QuantizationSpec(
dtype=torch.int8,
quant_min=-128,
quant_max=127,
qscheme=torch.per_tensor_symmetric, # Change the activation quant config to symmetric
is_dynamic=False,
observer_or_fake_quant_ctr=act_observer_or_fake_quant_ctr.with_args(
**extra_args
),
)
weight_observer_or_fake_quant_ctr: _ObserverOrFakeQuantizeConstructor = (
PerChannelMinMaxObserver
)
weight_quantization_spec = QuantizationSpec(
dtype=torch.int8,
quant_min=-128,
quant_max=127,
qscheme=torch.per_channel_symmetric, # Same as the default config, the only supported option for weight
ch_axis=0, # 0 corresponding to weight shape = (oc, ic, kh, kw) of conv
is_dynamic=False,
observer_or_fake_quant_ctr=weight_observer_or_fake_quant_ctr.with_args(
**extra_args
),
)
bias_quantization_spec = None # will use placeholder observer by default
quantization_config = QuantizationConfig(
act_quantization_spec,
act_quantization_spec,
weight_quantization_spec,
bias_quantization_spec,
False,
)
return quantization_config
# Then, set the quantization configuration to the quantizer.
quantizer = XPUInductorQuantizer()
quantizer.set_global(get_xpu_inductor_symm_quantization_config())
导入后端特定的量化器后,准备模型进行训练后量化。prepare_pt2e 将 BatchNorm 算子折叠到其前面的 Conv2d 算子中,并在模型的适当位置插入观察器。
prepared_model = prepare_pt2e(exported_model, quantizer)
(仅适用于静态量化) 在观察器插入模型后,校准 prepared_model。
# We use the dummy data as an example here
prepared_model(*example_inputs)
# Alternatively: user can define the dataset to calibrate
# def calibrate(model, data_loader):
# model.eval()
# with torch.no_grad():
# for image, target in data_loader:
# model(image)
# calibrate(prepared_model, data_loader_test) # run calibration on sample data
最后,将校准的模型转换为量化模型。convert_pt2e 接收一个校准模型并生成一个量化模型。
converted_model = convert_pt2e(prepared_model)
完成这些步骤后,量化流程就完成了,量化模型即可使用。
3. 下层到 Inductor¶
然后,量化模型将被下层到 inductor 后端。
with torch.no_grad():
optimized_model = torch.compile(converted_model)
# Running some benchmark
optimized_model(*example_inputs)
在更高级的场景中,int8-mixed-bf16 量化开始发挥作用。在这种情况下,在没有后续量化节点时,卷积或 GEMM 算子会产生 BFloat16 而不是 Float32 输出。随后,BFloat16 张量会无缝地通过后续的逐点(pointwise)算子传播,有效减少内存使用并可能提升性能。此功能的使用方法与常规 BFloat16 Autocast 相似,只需将脚本包裹在 BFloat16 Autocast 上下文中即可。
with torch.amp.autocast(device_type="xpu", dtype=torch.bfloat16), torch.no_grad():
# Turn on Autocast to use int8-mixed-bf16 quantization. After lowering into indcutor backend,
# For operators such as QConvolution and QLinear:
# * The input data type is consistently defined as int8, attributable to the presence of a pair
# of quantization and dequantization nodes inserted at the input.
# * The computation precision remains at int8.
# * The output data type may vary, being either int8 or BFloat16, contingent on the presence
# of a pair of quantization and dequantization nodes at the output.
# For non-quantizable pointwise operators, the data type will be inherited from the previous node,
# potentially resulting in a data type of BFloat16 in this scenario.
# For quantizable pointwise operators such as QMaxpool2D, it continues to operate with the int8
# data type for both input and output.
optimized_model = torch.compile(converted_model)
# Running some benchmark
optimized_model(*example_inputs)
结论¶
在本教程中,我们学习了如何利用 XPUInductorQuantizer 对模型进行训练后量化,以便在 Intel GPU 上进行推理,并利用了 PyTorch 2 的 Export 量化流程。我们涵盖了捕获 FX Graph、应用量化以及使用 torch.compile 将量化模型下层到 inductor 后端的逐步过程。此外,我们还探讨了使用 int8-mixed-bf16 量化带来的内存效率提升和潜在性能优势,尤其是在使用 BFloat16 autocast 时。
