


从第一性原理掌握 PyTorch Intel CPU 性能 (第二部分)¶
创建于: 2022 年 10 月 14 日 | 最后更新于: 2024 年 1 月 16 日 | 最后验证: 未验证
作者: Min Jean Cho, Jing Xu, Mark Saroufim
在从第一性原理掌握 PyTorch Intel CPU 性能教程中,我们介绍了如何调整 CPU 运行时配置、如何对其进行性能分析以及如何将它们集成到TorchServe 中以优化 CPU 性能。
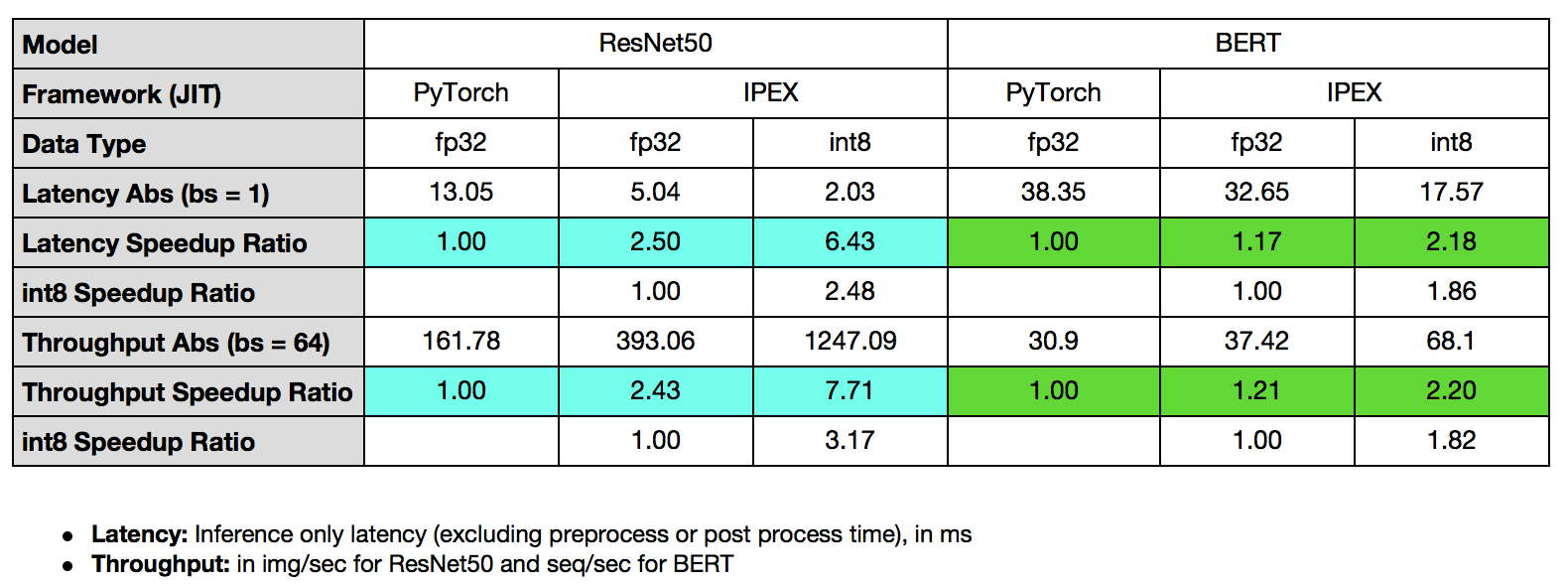
在本教程中,我们将演示如何通过Intel® Extension for PyTorch* Launcher 使用内存分配器提升性能,以及如何通过Intel® Extension for PyTorch* 在 CPU 上使用优化过的内核,并将这些技术应用于 TorchServe,展示 ResNet50 的吞吐量提速 7.71 倍,BERT 的吞吐量提速 2.20 倍。
先决条件¶
在本教程中,我们将使用自顶向下微架构分析 (TMA) 来分析并展示,对于未充分优化或未充分调优的深度学习工作负载,后端瓶颈 (内存瓶颈、核心瓶颈) 通常是主要的瓶颈,并演示如何通过 Intel® Extension for PyTorch* 改进后端瓶颈的优化技术。我们将使用 toplev,它是基于 Linux perf 构建的 pmu-tools 工具集的一部分,用于进行 TMA 分析。
我们还将使用Intel® VTune™ Profiler 的 instrumentation and Tracing Technology (ITT) 进行更细粒度的性能分析。
自顶向下微架构分析方法 (TMA)¶
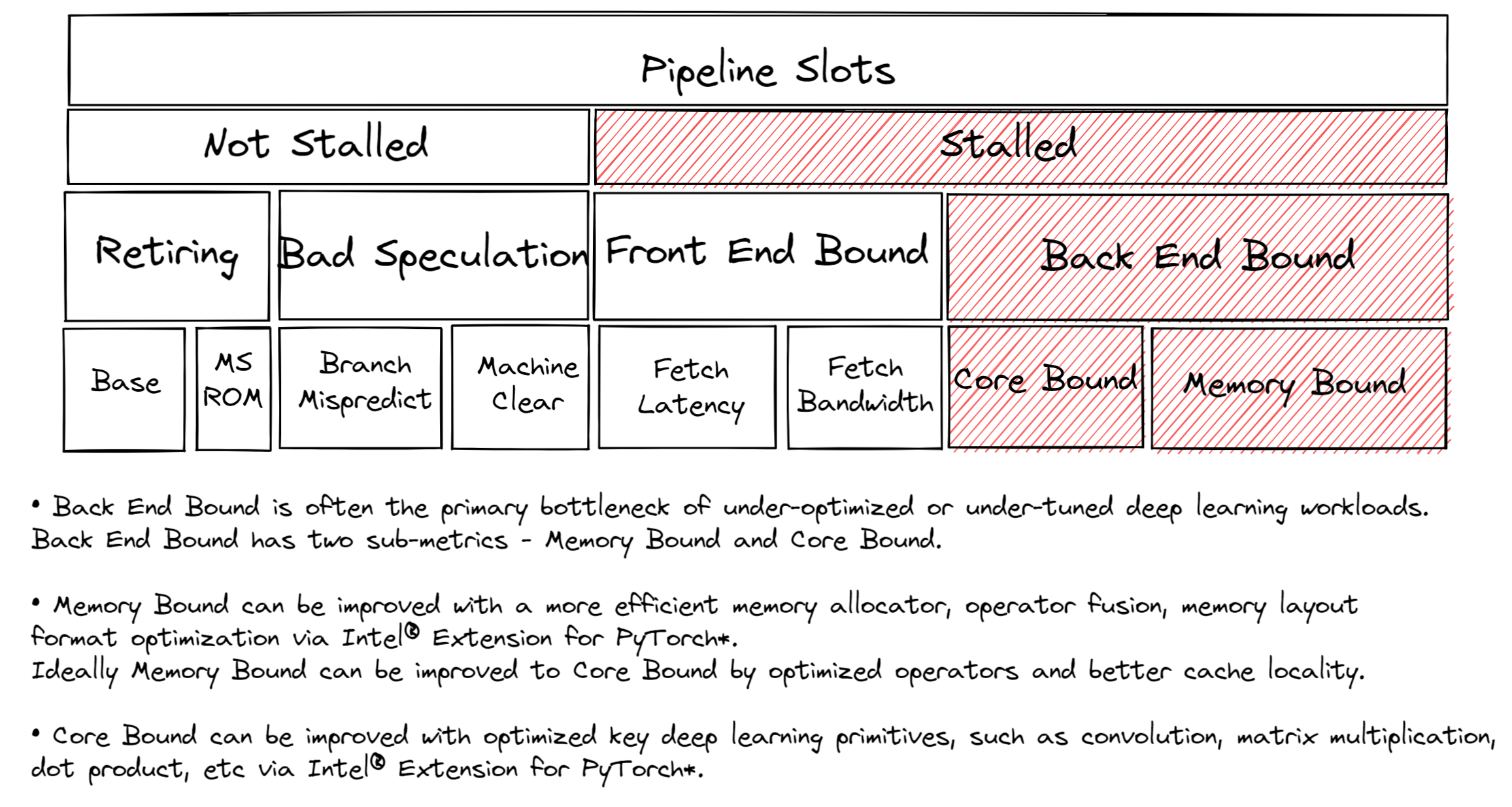
在调优 CPU 以获得最佳性能时,了解瓶颈所在非常有用。大多数 CPU 核心都带有片上性能监控单元 (PMUs)。PMUs 是 CPU 核心内部专门的逻辑单元,用于计算系统上发生的特定硬件事件。这些事件的例子可能包括缓存未命中或分支预测错误。PMUs 用于自顶向下微架构分析 (TMA) 以识别瓶颈。TMA 包含如下所示的分层级别
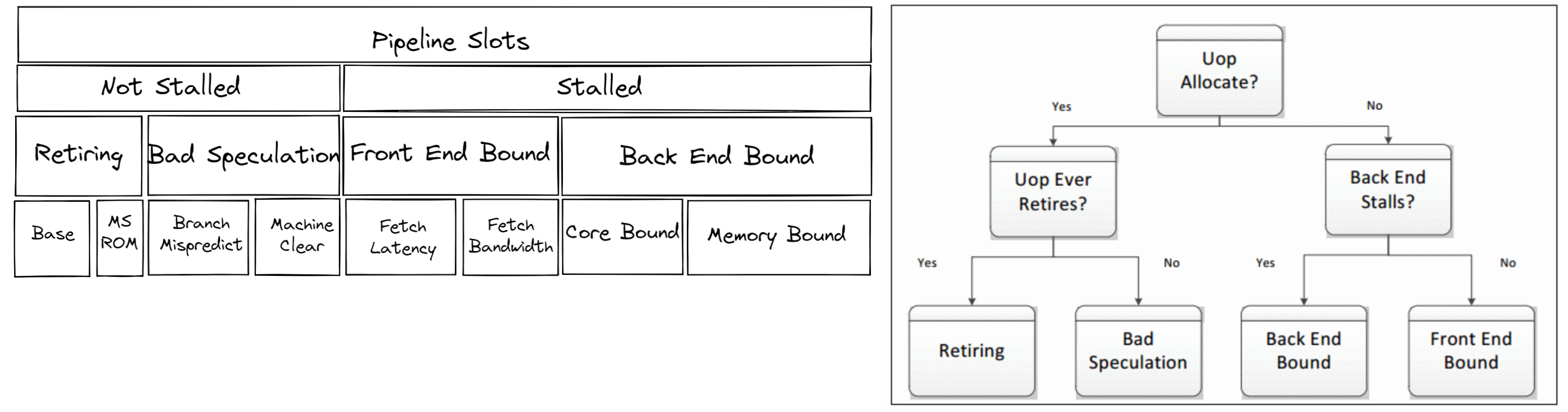
顶级指标,即 level-1 指标,收集 Retiring、Bad Speculation、Front End Bound、Back End Bound。CPU 的流水线概念上可以简化分为两部分:前端和后端。前端负责获取程序代码并将其解码为低级硬件操作,称为微操作 (uOps)。然后,uOps 通过称为分配的过程馈送到后端。一旦分配,后端负责在可用的执行单元中执行 uOp。uOp 执行的完成称为 retirement。相反,bad speculation 是指推测获取的 uOps 在退休前被取消,例如在分支预测错误的情况下。这些指标中的每一个都可以进一步分解到后续级别以精确定位瓶颈。
针对后端瓶颈进行调优¶
大多数未调优的深度学习工作负载都会受后端瓶颈限制。解决后端瓶颈通常是解决导致退休时间比必要时间更长的延迟源。如上所示,后端瓶颈有两个子指标——核心瓶颈和内存瓶颈。
内存瓶颈停顿的原因与内存子系统有关。例如,最后一级缓存(LLC 或 L3 缓存)未命中导致访问 DRAM。扩展深度学习模型通常需要大量的计算。高计算利用率要求在执行单元需要数据来执行微操作 (uOps) 时,数据是可用的。这需要预取数据并在缓存中重用数据,而不是多次从主内存中获取相同的数据,这会导致执行单元在数据返回时处于饥饿状态。在本教程中,我们将展示,更高效的内存分配器、算子融合、内存布局格式优化可以减少内存瓶颈的开销,并带来更好的缓存局部性。
核心瓶颈停顿表明在没有未完成的内存访问时,对可用执行单元的使用未达到最佳状态。例如,连续的多个通用矩阵乘法 (GEMM) 指令竞争融合乘加 (FMA) 或点积 (DP) 执行单元可能会导致核心瓶颈停顿。关键的深度学习内核,包括 DP 内核,已经通过 oneDNN 库 (oneAPI 深度神经网络库) 得到了很好的优化,从而降低了核心瓶颈的开销。
像 GEMM、卷积、反卷积这样的操作是计算密集型的。而像池化、批量归一化、ReLU 这样的激活函数是内存密集型的。
Intel® VTune™ Profiler 的 instrumentation and Tracing Technology (ITT)¶
Intel® VTune Profiler 的 ITT API 是一个有用的工具,可以标记工作负载的某个区域进行追踪,以便在更细粒度的标记级别(例如 OP/函数/子函数)进行性能分析和可视化。通过在 PyTorch 模型的操作 (OPs) 级别进行标记,Intel® VTune Profiler 的 ITT 可以实现操作级别的性能分析。Intel® VTune Profiler 的 ITT 已集成到 PyTorch Autograd Profiler 中。1
该功能必须通过 with torch.autograd.profiler.emit_itt() 显式启用。
将 TorchServe 与 Intel® Extension for PyTorch* 结合使用¶
Intel® Extension for PyTorch* 是一个 Python 包,用于扩展 PyTorch,提供优化功能,以在 Intel 硬件上额外提升性能。
Intel® Extension for PyTorch* 已集成到 TorchServe 中,可直接提供性能提升。2 对于自定义处理程序脚本,我们建议添加 intel_extension_for_pytorch 包。
该功能必须通过在 config.properties 中设置 ipex_enable=true 显式启用。
在本节中,我们将展示后端瓶颈通常是未充分优化或未充分调优的深度学习工作负载的主要瓶颈,并演示如何通过 Intel® Extension for PyTorch* 改进后端瓶颈的优化技术,后端瓶颈有两个子指标——内存瓶颈和核心瓶颈。更高效的内存分配器、算子融合、内存布局格式优化可以改进内存瓶颈。理想情况下,通过优化算子和更好的缓存局部性,可以将内存密集型操作改进为核心密集型操作。而关键的深度学习原语,如卷积、矩阵乘法、点积等,已通过 Intel® Extension for PyTorch* 和 oneDNN 库得到了很好的优化,从而改进了核心瓶颈。
利用高级启动器配置:内存分配器¶
从性能角度来看,内存分配器起着重要作用。更高效的内存使用减少了不必要的内存分配或销毁开销,从而加快执行速度。在实践中,对于深度学习工作负载,尤其是在大型多核系统或像 TorchServe 这样的服务器上运行的工作负载,TCMalloc 或 JeMalloc 通常比默认的 PyTorch 内存分配器 PTMalloc 具有更好的内存使用效率。
TCMalloc, JeMalloc, PTMalloc¶
TCMalloc 和 JeMalloc 都使用线程本地缓存来减少线程同步开销,并分别通过使用自旋锁和每线程竞技场来减少锁竞争。TCMalloc 和 JeMalloc 减少了不必要的内存分配和解除分配的开销。两种分配器都根据大小对内存分配进行分类,以减少内存碎片化的开销。
通过启动器,用户可以通过选择以下三个启动器旋钮中的一个轻松尝试不同的内存分配器:–enable_tcmalloc (TCMalloc),–enable_jemalloc (JeMalloc),–use_default_allocator (PTMalloc)。
练习¶
让我们对 PTMalloc 与 JeMalloc 进行性能分析。
我们将使用启动器指定内存分配器,并将工作负载绑定到第一个 socket 的物理核心上,以避免任何 NUMA 复杂性——仅分析内存分配器的影响。
以下示例测量 ResNet50 的平均推理时间
import torch
import torchvision.models as models
import time
model = models.resnet50(pretrained=False)
model.eval()
batch_size = 32
data = torch.rand(batch_size, 3, 224, 224)
# warm up
for _ in range(100):
model(data)
# measure
# Intel® VTune Profiler's ITT context manager
with torch.autograd.profiler.emit_itt():
start = time.time()
for i in range(100):
# Intel® VTune Profiler's ITT to annotate each step
torch.profiler.itt.range_push('step_{}'.format(i))
model(data)
torch.profiler.itt.range_pop()
end = time.time()
print('Inference took {:.2f} ms in average'.format((end-start)/100*1000))
让我们收集 level-1 TMA 指标。

Level-1 TMA 显示 PTMalloc 和 JeMalloc 都受后端限制。超过一半的执行时间被后端停顿。让我们深入一层。

Level-2 TMA 显示后端瓶颈是由内存瓶颈引起的。让我们再深入一层。
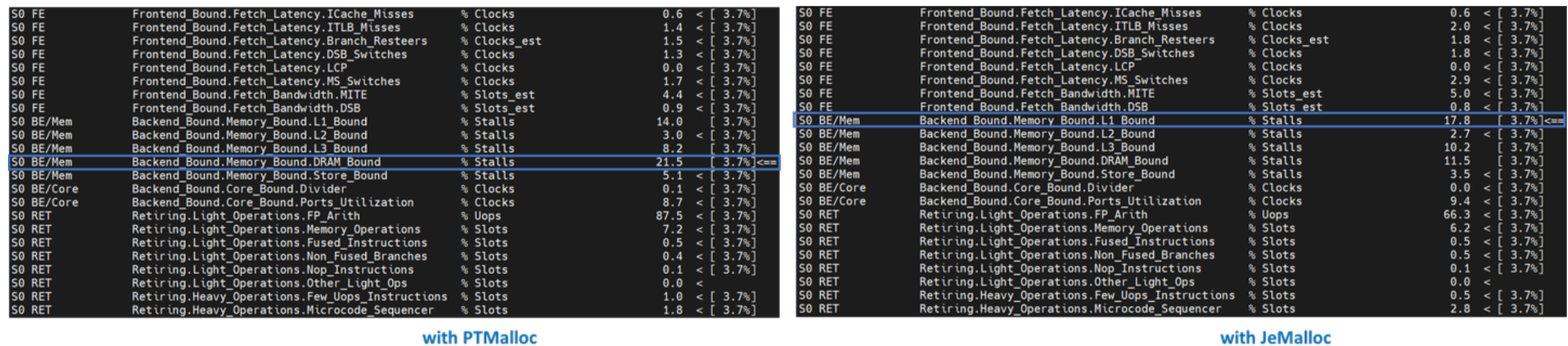
内存瓶颈下的指标大多用于识别从 L1 缓存到主内存的内存层次结构中哪个级别是瓶颈。在给定级别受限制的热点表明大部分数据是从该缓存或内存级别检索的。优化应专注于将数据移近核心。Level-3 TMA 显示 PTMalloc 受 DRAM 瓶颈限制。另一方面,JeMalloc 受 L1 瓶颈限制——JeMalloc 将数据移近了核心,从而加快了执行速度。
让我们看看 Intel® VTune Profiler ITT 追踪。在示例脚本中,我们标记了推理循环的每个 step_x。
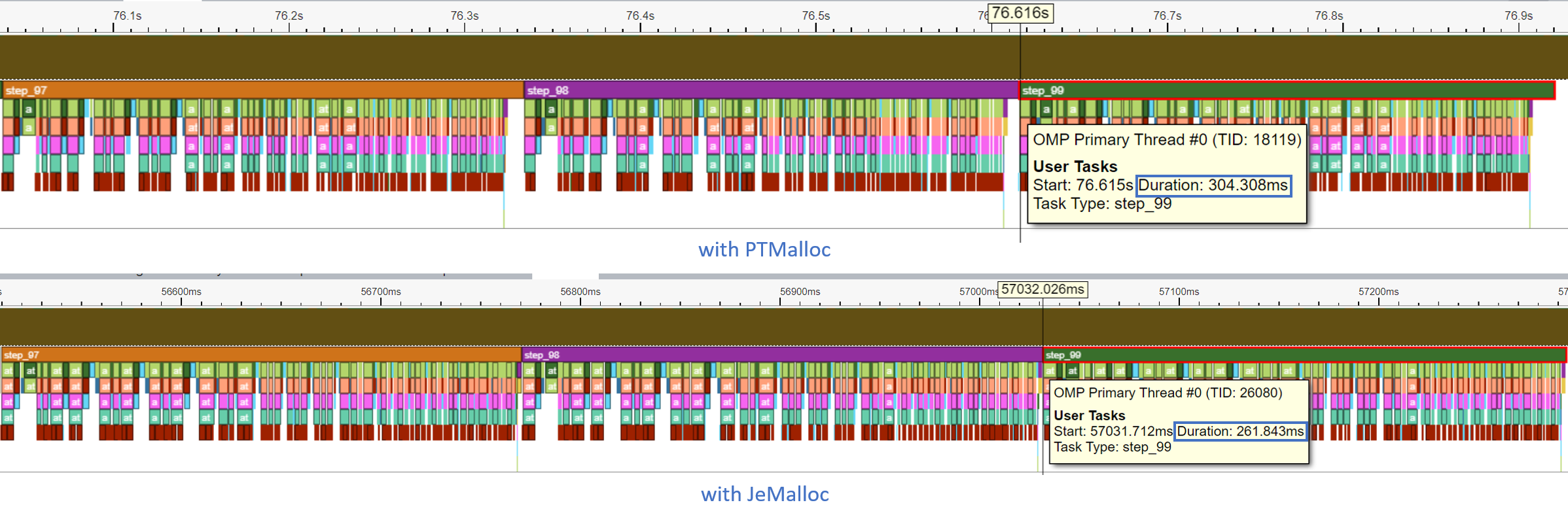
每个步骤都在时间轴图中进行了追踪。模型推理在最后一步 (step_99) 的持续时间从 304.308 ms 减少到 261.843 ms。
TorchServe 练习¶
让我们使用 TorchServe 对 PTMalloc 与 JeMalloc 进行性能分析。
我们将使用 TorchServe apache-bench 基准测试,使用 ResNet50 FP32 模型,批量大小 32,并发度 32,请求数 8960。所有其他参数与默认参数相同。
与前面的练习一样,我们将使用启动器指定内存分配器,并将工作负载绑定到第一个 socket 的物理核心上。为此,用户只需在 config.properties 中添加几行代码
PTMalloc
cpu_launcher_enable=true
cpu_launcher_args=--node_id 0 --use_default_allocator
JeMalloc
cpu_launcher_enable=true
cpu_launcher_args=--node_id 0 --enable_jemalloc
让我们收集 level-1 TMA 指标。

让我们深入一层。

让我们使用 Intel® VTune Profiler ITT 标记 TorchServe 推理范围,以便在推理级别进行细粒度性能分析。由于 TorchServe 架构包含多个子组件,包括用于处理请求/响应的 Java 前端和用于对模型运行实际推理的 Python 后端,因此使用 Intel® VTune Profiler ITT 将追踪数据的收集限制在推理级别是有帮助的。

每次推理调用都在时间轴图中进行了追踪。最后一次模型推理的持续时间从 561.688 ms 减少到 251.287 ms - 提速 2.2 倍。
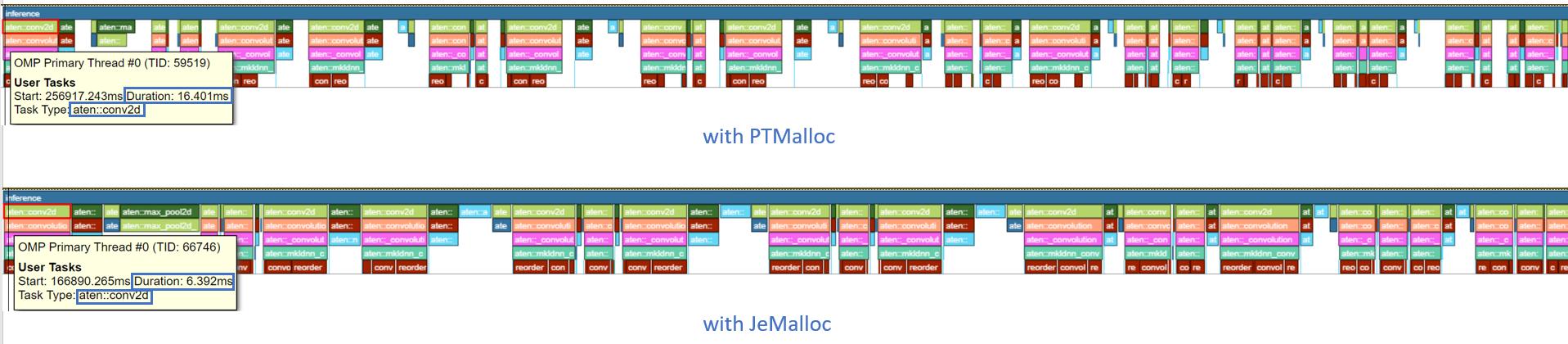
时间轴图可以展开以查看操作级别的性能分析结果。aten::conv2d 的持续时间从 16.401 ms 减少到 6.392 ms - 提速 2.6 倍。
在本节中,我们演示了 JeMalloc 比默认的 PyTorch 内存分配器 PTMalloc 具有更好的性能,其高效的线程本地缓存改进了后端瓶颈。
Intel® Extension for PyTorch*¶
Intel® Extension for PyTorch* 的三个主要优化技术——算子、图、运行时,如下所示
Intel® Extension for PyTorch* 优化技术 |
||
|---|---|---|
算子 |
图 |
运行时 |
|
|
|
算子优化¶
优化的算子和内核通过 PyTorch 的调度机制注册。这些算子和内核通过 Intel 硬件原生的向量化功能和矩阵计算功能得到加速。执行期间,Intel® Extension for PyTorch* 会拦截 ATen 算子的调用,并用这些优化的算子替换原始算子。诸如 Convolution、Linear 等常用算子已在 Intel® Extension for PyTorch* 中进行了优化。
练习¶
让我们使用 Intel® Extension for PyTorch* 对优化过的算子进行性能分析。我们将比较代码更改前后(即使用和不使用优化)的性能。
与前面的练习一样,我们将工作负载绑定到第一个 socket 的物理核心上。
import torch
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.conv = torch.nn.Conv2d(16, 33, 3, stride=2)
self.relu = torch.nn.ReLU()
def forward(self, x):
x = self.conv(x)
x = self.relu(x)
return x
model = Model()
model.eval()
data = torch.rand(20, 16, 50, 100)
#################### code changes ####################
import intel_extension_for_pytorch as ipex
model = ipex.optimize(model)
######################################################
print(model)
模型包含两个操作——Conv2d 和 ReLU。通过打印模型对象,我们得到以下输出。

让我们收集 level-1 TMA 指标。

注意后端瓶颈从 68.9 减少到 38.5 —— 提速 1.8 倍。
此外,让我们使用 PyTorch Profiler 进行性能分析。

注意 CPU 时间从 851 us 减少到 310 us —— 提速 2.7 倍。
图优化¶
强烈建议用户利用 Intel® Extension for PyTorch* 结合 TorchScript 进行进一步的图优化。为了通过 TorchScript 进一步优化性能,Intel® Extension for PyTorch* 支持 oneDNN 融合常用的 FP32/BF16 算子模式,如 Conv2D+ReLU、Linear+ReLU 等,以减少算子/内核调用开销,并获得更好的缓存局部性。某些算子融合允许维护临时计算、数据类型转换、数据布局以获得更好的缓存局部性。此外,对于 INT8,Intel® Extension for PyTorch* 内置了量化方案,可为包括 CNN、NLP 和推荐模型在内的常见 DL 工作负载提供良好的统计精度。然后,量化后的模型通过 oneDNN 融合支持进行优化。
练习¶
让我们使用 TorchScript 对 FP32 图优化进行性能分析。
与前面的练习一样,我们将工作负载绑定到第一个 socket 的物理核心上。
import torch
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.conv = torch.nn.Conv2d(16, 33, 3, stride=2)
self.relu = torch.nn.ReLU()
def forward(self, x):
x = self.conv(x)
x = self.relu(x)
return x
model = Model()
model.eval()
data = torch.rand(20, 16, 50, 100)
#################### code changes ####################
import intel_extension_for_pytorch as ipex
model = ipex.optimize(model)
######################################################
# torchscript
with torch.no_grad():
model = torch.jit.trace(model, data)
model = torch.jit.freeze(model)
让我们收集 level-1 TMA 指标。

注意后端瓶颈从 67.1 减少到 37.5 —— 提速 1.8 倍。
此外,让我们使用 PyTorch Profiler 进行性能分析。

注意,使用 Intel® Extension for PyTorch* 后,Conv + ReLU 算子被融合,CPU 时间从 803 us 减少到 248 us —— 提速 3.2 倍。oneDNN 的 eltwise 后处理操作使得可以将一个 primitive 与一个 elementwise primitive 融合。这是最常见的融合类型之一:将 elementwise(通常是 ReLU 等激活函数)与前面的卷积或内积融合。请参阅下一节中显示的 oneDNN 详细日志。
Channels Last 内存格式¶
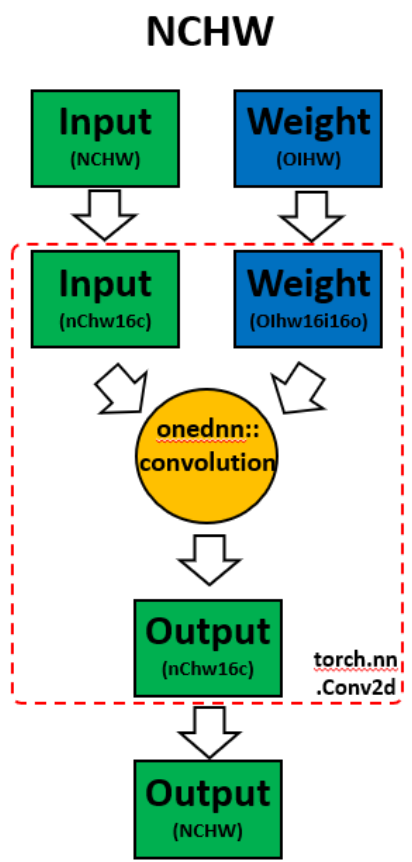
在模型上调用 ipex.optimize 时,Intel® Extension for PyTorch* 会自动将模型转换为优化的内存格式,即 channels last。Channels last 是一种对 Intel 架构更友好的内存格式。与 PyTorch 默认的 channels first NCHW(批量、通道、高度、宽度)内存格式相比,channels last NHWC(批量、高度、宽度、通道)内存格式通常通过更好的缓存局部性来加速卷积神经网络。
需要注意的一点是,转换内存格式的开销很大。因此,最好在部署前转换一次内存格式,并在部署过程中尽量减少内存格式转换。随着数据通过模型的层传播,channels last 内存格式会通过连续支持 channels last 的层(例如 Conv2d -> ReLU -> Conv2d)得到保留,转换仅在不支持 channels last 的层之间进行。有关更多详细信息,请参阅内存格式传播。
练习¶
让我们演示 channels last 优化。
import torch
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.conv = torch.nn.Conv2d(16, 33, 3, stride=2)
self.relu = torch.nn.ReLU()
def forward(self, x):
x = self.conv(x)
x = self.relu(x)
return x
model = Model()
model.eval()
data = torch.rand(20, 16, 50, 100)
import intel_extension_for_pytorch as ipex
############################### code changes ###############################
ipex.disable_auto_channels_last() # omit this line for channels_last (default)
############################################################################
model = ipex.optimize(model)
with torch.no_grad():
model = torch.jit.trace(model, data)
model = torch.jit.freeze(model)
我们将使用 oneDNN 详细模式,这是一个有助于在 oneDNN 图级别收集信息的工具,例如算子融合、执行 oneDNN primitives 所花费的内核执行时间。有关更多信息,请参阅 oneDNN 文档。
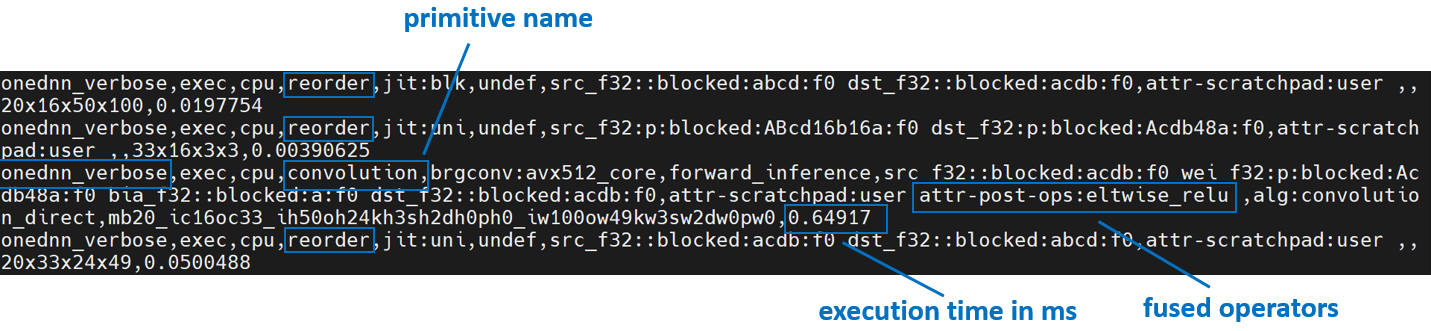
上面是来自 channels first 的 oneDNN 详细输出。我们可以验证,数据和权重会进行重新排序,然后进行计算,最后将输出重新排序回去。

上面是来自 channels last 的 oneDNN 详细输出。我们可以验证,channels last 内存格式避免了不必要的重新排序。
使用 Intel® Extension for PyTorch* 提升性能¶
下面总结了使用 Intel® Extension for PyTorch* 结合 TorchServe 对 ResNet50 和 BERT-base-uncased 的性能提升。
TorchServe 练习¶
让我们使用 TorchServe 对 Intel® Extension for PyTorch* 优化进行性能分析。
我们将使用 TorchServe apache-bench 基准测试,使用 ResNet50 FP32 TorchScript 模型,批量大小 32,并发度 32,请求数 8960。所有其他参数与默认参数相同。
与前面的练习一样,我们将使用启动器将工作负载绑定到第一个 socket 的物理核心上。为此,用户只需在 config.properties 中添加几行代码
cpu_launcher_enable=true
cpu_launcher_args=--node_id 0
让我们收集 level-1 TMA 指标。

Level-1 TMA 显示两者都受后端限制。正如前面讨论的,大多数未调优的深度学习工作负载都会受后端瓶颈限制。注意后端瓶颈从 70.0 减少到 54.1。让我们深入一层。

正如前面讨论的,后端瓶颈有两个子指标——内存瓶颈和核心瓶颈。内存瓶颈表示工作负载未充分优化或未充分利用,理想情况下,通过优化算子并改进缓存局部性,可以将内存密集型操作改进为核心密集型操作。Level-2 TMA 显示后端瓶颈从内存瓶颈改进为核心瓶颈。让我们再深入一层。
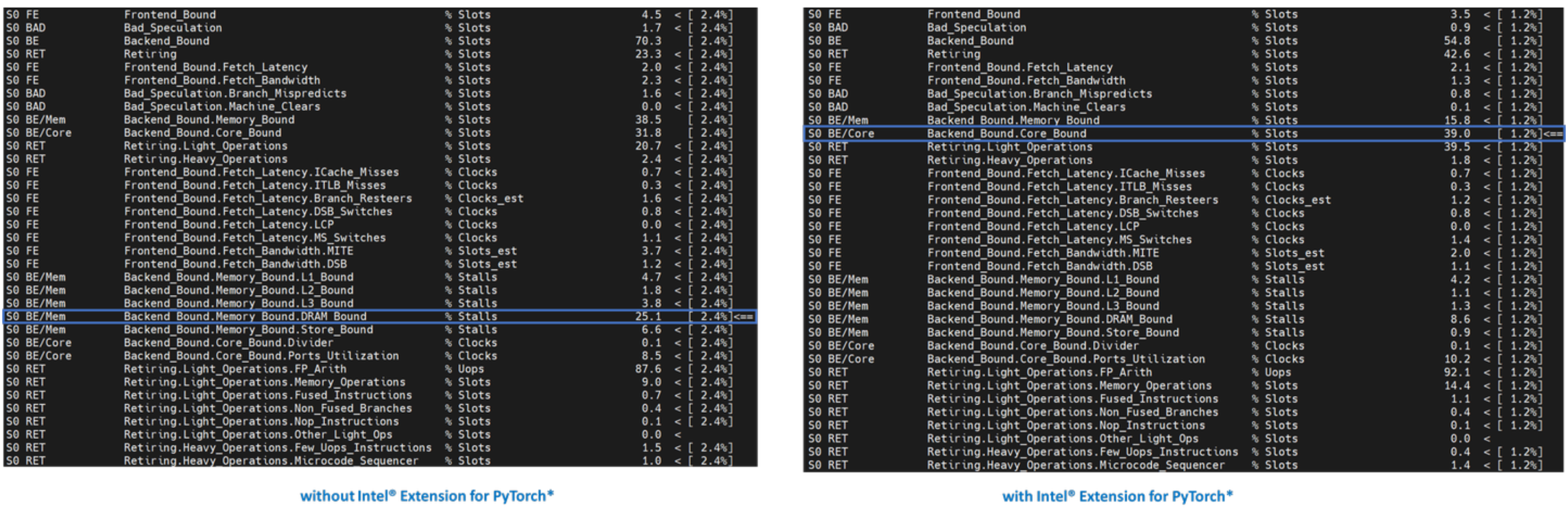
在像 TorchServe 这样的模型服务框架上扩展深度学习模型以用于生产环境需要高计算利用率。这要求在执行单元需要数据来执行微操作 (uOps) 时,数据可以通过预取和在缓存中重用而可用。Level-3 TMA 显示后端内存瓶颈从 DRAM 瓶颈改进为核心瓶颈。
与前面使用 TorchServe 的练习一样,让我们使用 Intel® VTune Profiler ITT 标记 TorchServe 推理范围,以便在推理级别进行细粒度性能分析。

每次推理调用都在时间轴图中进行了追踪。最后一次推理调用的持续时间从 215.731 ms 减少到 95.634 ms - 提速 2.3 倍。

时间轴图可以展开以查看操作级别的性能分析结果。注意 Conv + ReLU 已被融合,持续时间从 6.393 ms + 1.731 ms 减少到 3.408 ms - 提速 2.4 倍。
结论¶
在本教程中,我们使用了自顶向下微架构分析 (TMA) 和 Intel® VTune™ Profiler 的 Instrumentation and Tracing Technology (ITT) 来证明
未充分优化或未充分调优的深度学习工作负载的主要瓶颈通常是后端瓶颈,它有两个子指标:内存瓶颈和核心瓶颈。
更高效的内存分配器、算子融合、内存布局格式优化(由 Intel® Extension for PyTorch* 提供)可以改进内存瓶颈。
关键的深度学习原语,如卷积、矩阵乘法、点积等,已通过 Intel® Extension for PyTorch* 和 oneDNN 库得到了很好的优化,从而改进了核心瓶颈。
Intel® Extension for PyTorch* 已集成到 TorchServe 中,并提供了易于使用的 API。
集成 Intel® Extension for PyTorch* 的 TorchServe 在 ResNet50 上显示出 7.71 倍的吞吐量加速,在 BERT 上显示出 2.20 倍的吞吐量加速。
致谢¶
我们要感谢 Ashok Emani (Intel) 和 Jiong Gong (Intel) 在本教程的多个步骤中给予的巨大指导、支持、详尽反馈和评审。我们还要感谢 Hamid Shojanazeri (Meta) 和 Li Ning (AWS) 在代码评审和本教程中提供的有益反馈。
