


从基础原理深入理解 PyTorch 在 Intel CPU 上的性能表现¶
创建日期:2022 年 4 月 15 日 | 最后更新:2025 年 1 月 23 日 | 最后验证:2024 年 11 月 5 日
一篇关于使用 Intel® Extension for PyTorch* 优化的 TorchServe 推理框架的案例研究。
作者:Min Jean Cho, Mark Saroufim
审阅者:Ashok Emani, Jiong Gong
在 CPU 上为深度学习获得强大的开箱即用性能可能有些棘手,但如果您了解影响性能的主要问题、如何衡量它们以及如何解决它们,就会容易得多。
摘要
问题 |
如何衡量 |
解决方案 |
GEMM 执行单元瓶颈 |
通过核心绑定将线程亲和性设置为物理核心,从而避免使用逻辑核心 |
|
非统一内存访问 (NUMA) |
|
通过核心绑定将线程亲和性设置为特定 Socket,从而避免跨 Socket 计算 |
多 Socket 系统具有
牢记这些原则,适当的 CPU 运行时配置可以显著提升开箱即用性能。
在这篇博客中,我们将引导您了解 CPU 性能调优指南中需要注意的重要运行时配置,解释它们的工作原理、如何进行性能分析以及如何通过易于使用的启动脚本将它们集成到像 TorchServe 这样的模型服务框架中,我们已经将其原生集成 1。
我们将从基础原理出发,通过大量性能分析,可视化地解释所有这些概念,并向您展示我们如何应用所学知识来改善 TorchServe 在 CPU 上的开箱即用性能。
该功能必须通过在 config.properties 中设置 cpu_launcher_enable=true 来显式启用。
避免在深度学习中使用逻辑核心¶
在深度学习工作负载中避免使用逻辑核心通常会提升性能。为了理解这一点,让我们回到 GEMM。
优化 GEMM 就是优化深度学习
深度学习训练或推理的大部分时间都花在数百万次重复的 GEMM 操作上,这是全连接层的核心。自多层感知机 (MLP) 被证明是任何连续函数的通用逼近器以来,全连接层已被使用了数十年。任何 MLP 都可以完全表示为 GEMM。甚至卷积也可以通过使用 Toeplitz 矩阵来表示为 GEMM。
回到最初的主题,大多数 GEMM 算子受益于不使用超线程,因为深度学习训练或推理的大部分时间都花在数百万次重复的 GEMM 操作上,这些操作运行在超线程核心共享的融合乘加 (FMA) 或点积 (DP) 执行单元上。启用了超线程时,OpenMP 线程将争用相同的 GEMM 执行单元。
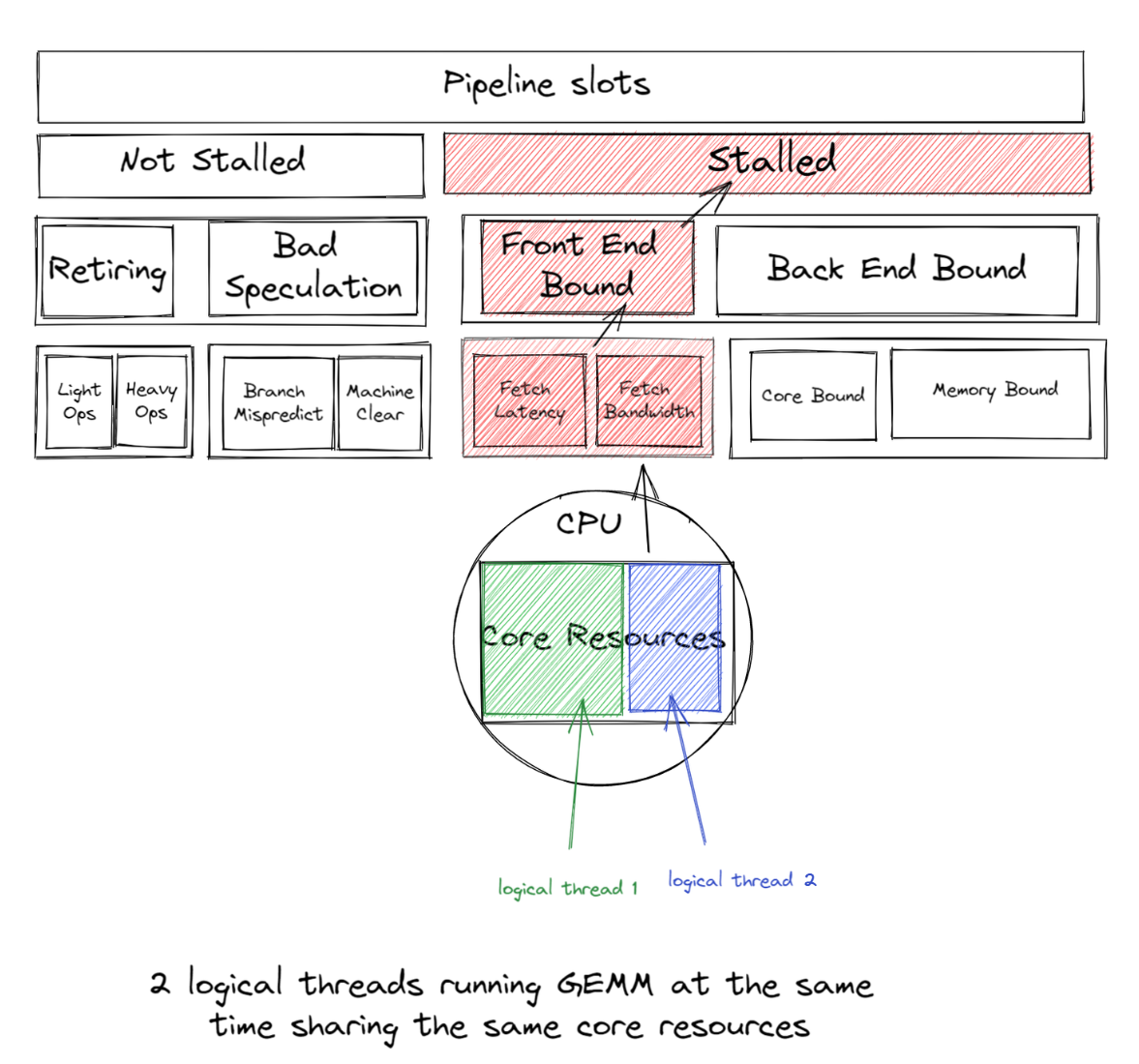
如果 2 个逻辑线程同时运行 GEMM,它们将共享相同的核心资源,导致前端限制,这种前端限制带来的开销大于同时运行两个逻辑线程带来的收益。
因此,我们通常建议在深度学习工作负载中避免使用逻辑核心,以获得良好的性能。启动脚本默认只使用物理核心;但是,用户可以很容易地通过简单地切换 --use_logical_core 启动脚本选项来实验逻辑核心与物理核心。
练习
我们将使用以下示例,向 ResNet50 馈送虚拟张量
import torch
import torchvision.models as models
import time
model = models.resnet50(pretrained=False)
model.eval()
data = torch.rand(1, 3, 224, 224)
# warm up
for _ in range(100):
model(data)
start = time.time()
for _ in range(100):
model(data)
end = time.time()
print('Inference took {:.2f} ms in average'.format((end-start)/100*1000))
在整个博客中,我们将使用 Intel® VTune™ Profiler 进行性能分析和验证优化。我们将在配有两颗 Intel(R) Xeon(R) Platinum 8180M CPU 的机器上运行所有练习。CPU 信息如 图 2.1 所示。
环境变量 OMP_NUM_THREADS 用于设置并行区域的线程数。我们将比较 OMP_NUM_THREADS=2 在 (1) 使用逻辑核心和 (2) 仅使用物理核心的情况。
两个 OpenMP 线程试图利用超线程核心 (0, 56) 共享的同一 GEMM 执行单元
我们可以通过在 Linux 上运行 htop 命令来可视化,如下所示。
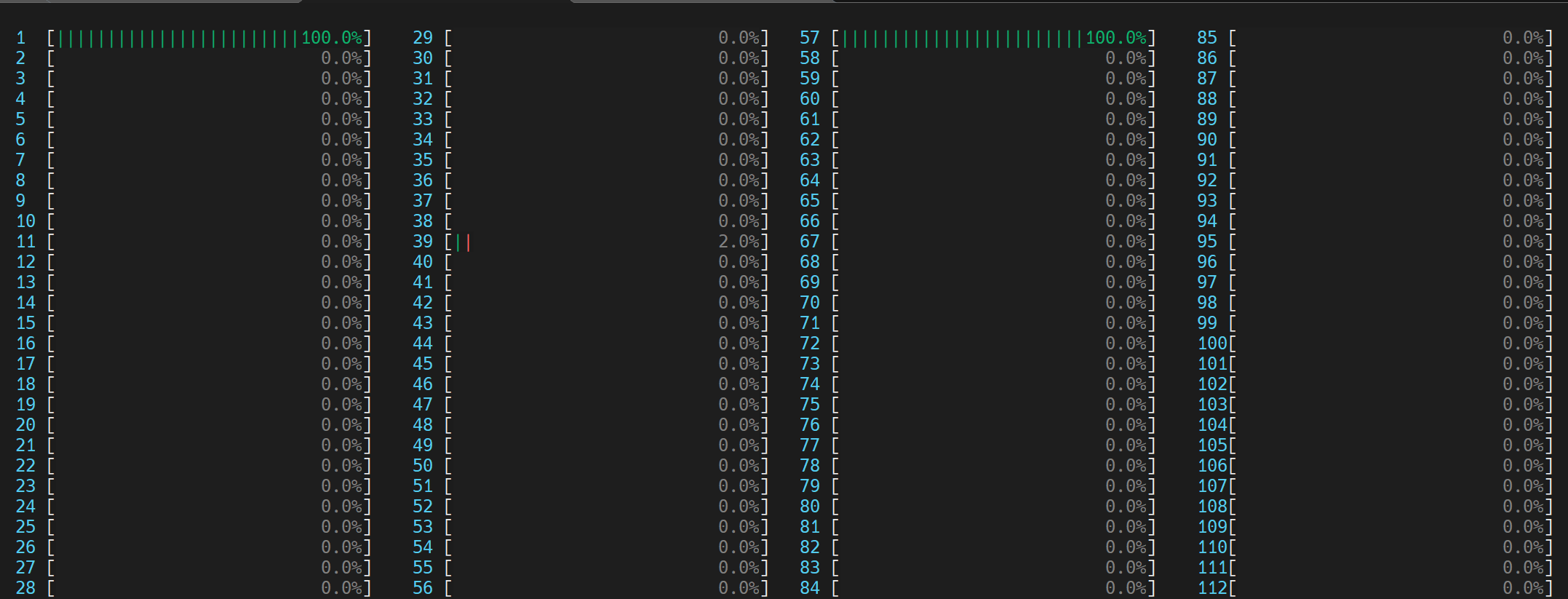
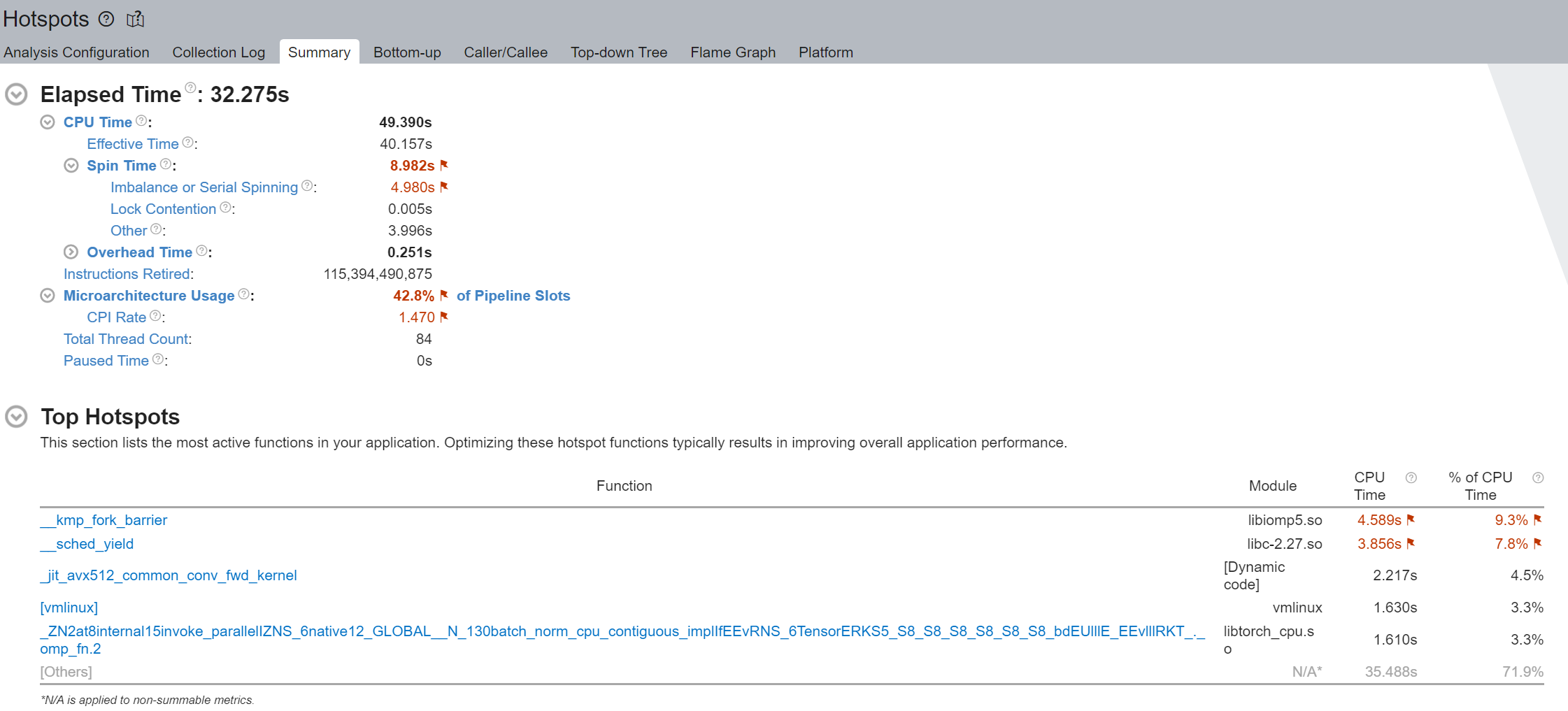
我们注意到“空转时间”被标记出来,并且“失衡或串行忙等”占了其中的大部分——8.982 秒总时间中的 4.980 秒。使用逻辑核心时的“失衡或串行忙等”是由于工作线程并发度不足,因为每个逻辑线程都争用相同的核心资源。
执行摘要的“热点Top”部分表明 __kmp_fork_barrier 花费了 4.589 秒的 CPU 时间——在 9.33% 的 CPU 执行时间内,线程由于线程同步在此屏障处空转。
每个 OpenMP 线程利用各自物理核心 (0,1) 中的 GEMM 执行单元
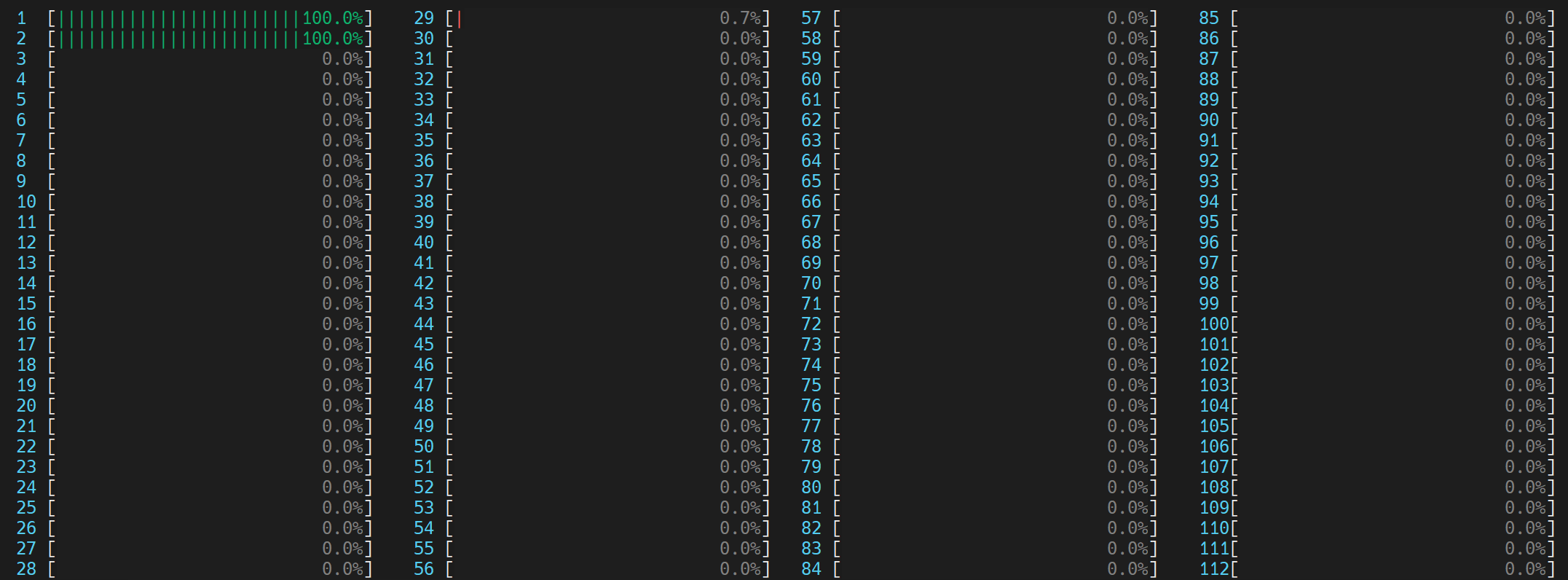
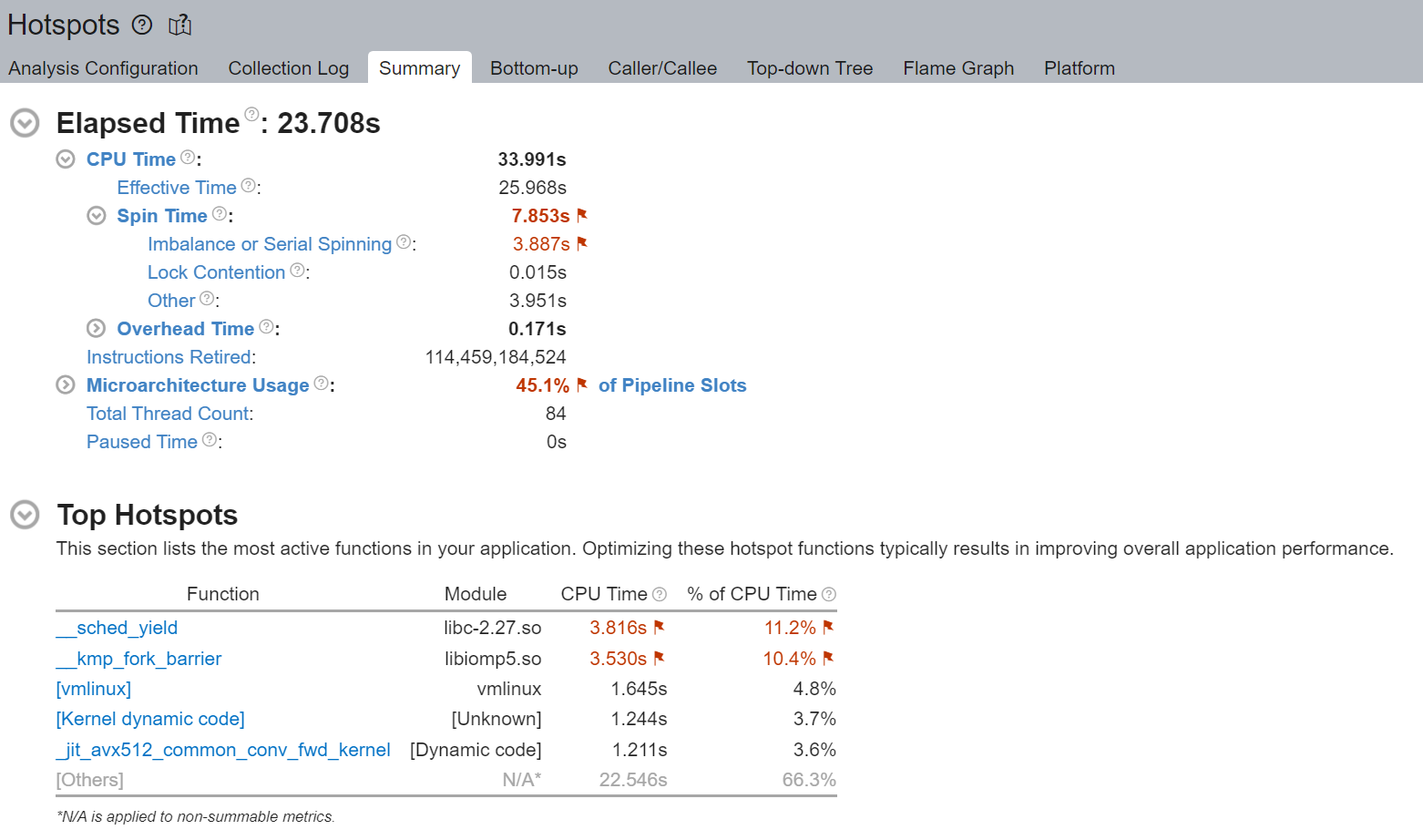
我们首先注意到,通过避免使用逻辑核心,执行时间从 32 秒下降到 23 秒。虽然仍然存在一些不可忽略的“失衡或串行忙等”,但我们注意到它从 4.980 秒相对改善到 3.887 秒。
通过不使用逻辑线程(而是每个物理核心使用 1 个线程),我们避免了逻辑线程争用相同的核心资源。“热点Top”部分也表明 __kmp_fork_barrier 时间从 4.589 秒相对改善到 3.530 秒。
本地内存访问总是比远程内存访问快¶
我们通常建议将进程绑定到本地 Socket,以防止进程跨 Socket 迁移。这样做的目标通常是利用本地内存上的高速缓存,并避免可能慢约 2 倍的远程内存访问。
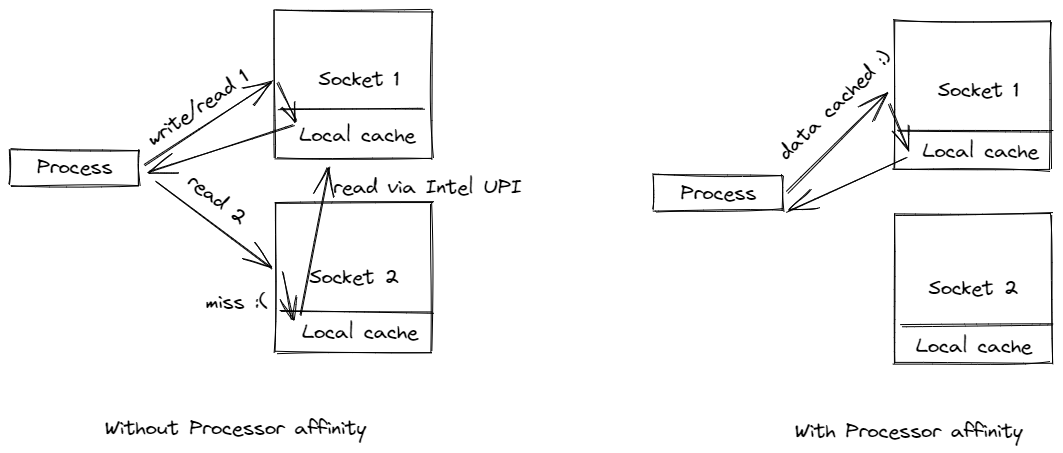
图 1. 双 Socket 配置
图 1. 显示了典型的双 Socket 配置。注意,每个 Socket 都有自己的本地内存。Socket 之间通过 Intel Ultra Path Interconnect (UPI) 连接,这允许每个 Socket 访问另一个 Socket 的本地内存,称为远程内存。本地内存访问总是比远程内存访问快。
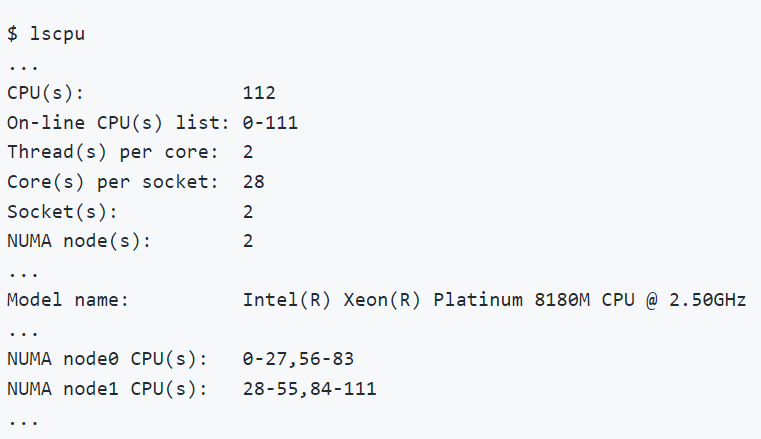
图 2.1. CPU 信息
用户可以通过在其 Linux 机器上运行 lscpu 命令来获取其 CPU 信息。图 2.1. 显示了在配有两颗 Intel(R) Xeon(R) Platinum 8180M CPU 的机器上执行 lscpu 的示例。注意,每个 Socket 有 28 个核心,每个核心有 2 个线程(即启用了超线程)。换句话说,除了 28 个物理核心外,还有 28 个逻辑核心,每个 Socket 总共有 56 个核心。共有 2 个 Socket,总共有 112 个核心(Thread(s) per core x Core(s) per socket x Socket(s))。
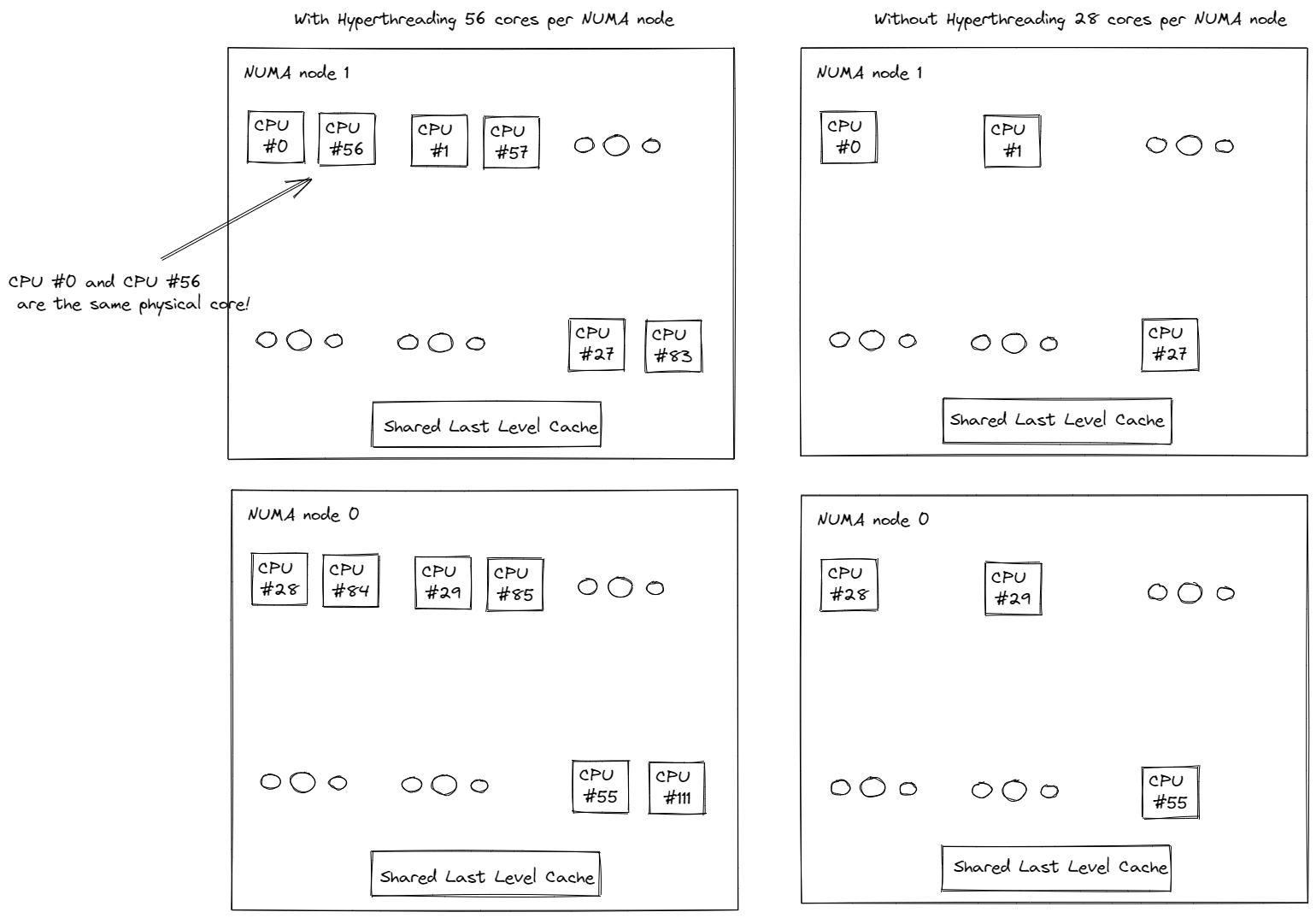
图 2.2. CPU 信息
2 个 Socket 分别被映射到 2 个 NUMA 节点(NUMA 节点 0、NUMA 节点 1)。物理核心的索引优先于逻辑核心。如图 2.2. 所示,第一个 Socket 上的前 28 个物理核心 (0-27) 和前 28 个逻辑核心 (56-83) 位于 NUMA 节点 0 上。第二个 Socket 上的第二个 28 个物理核心 (28-55) 和第二个 28 个逻辑核心 (84-111) 位于 NUMA 节点 1 上。同一个 Socket 上的核心共享本地内存和末级缓存 (LLC),这比通过 Intel UPI 进行跨 Socket 通信快得多。
现在我们了解了 NUMA、跨 Socket (UPI) 流量以及多处理器系统中的本地与远程内存访问,接下来进行性能分析并验证我们的理解。
练习
我们将复用上面的 ResNet50 示例。
由于我们没有将线程绑定到特定 Socket 的处理器核心,操作系统会定期将线程调度到位于不同 Socket 的处理器核心上。
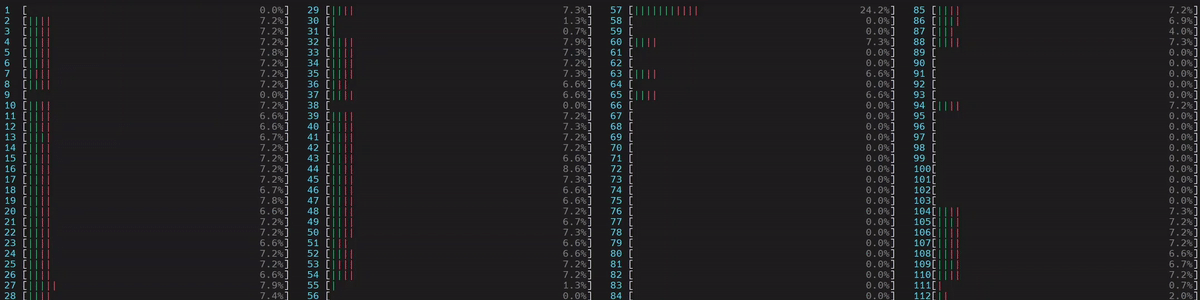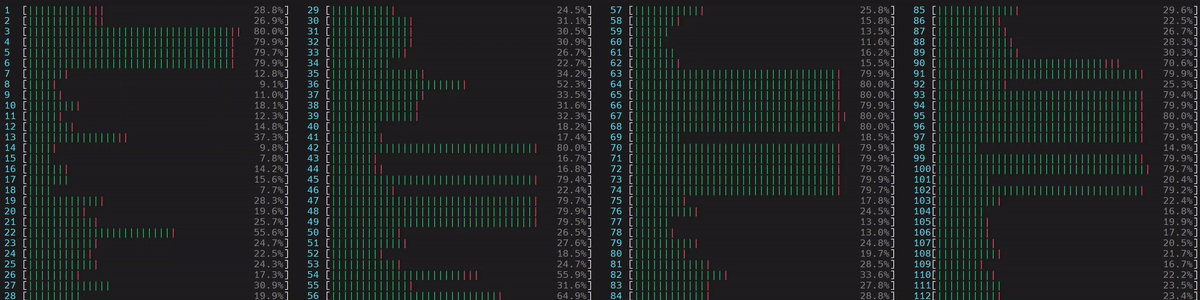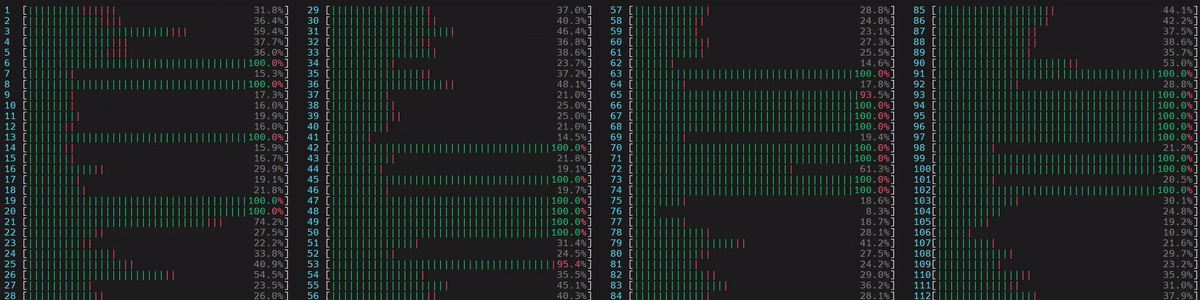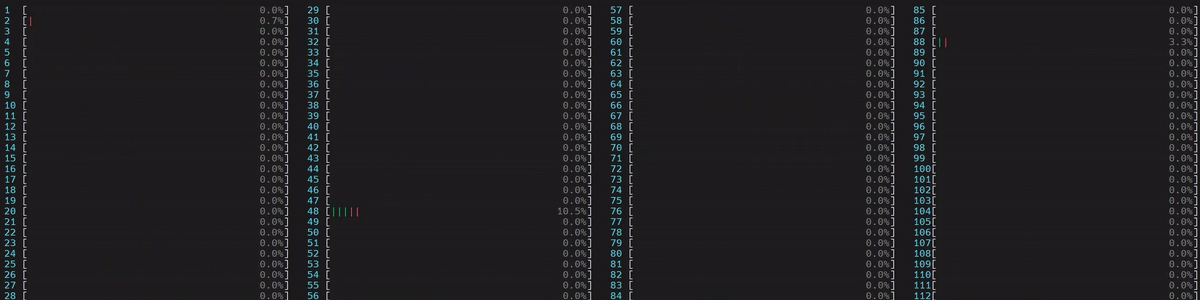
图 3. 非 NUMA 感知应用的 CPU 使用情况。启动了 1 个主工作线程,然后它在所有核心(包括逻辑核心)上启动了物理核心数量 (56) 的线程。
(旁注:如果线程数未通过 torch.set_num_threads 设置,则在启用了超线程的系统中,默认线程数是物理核心的数量。这可以通过 torch.get_num_threads 进行验证。因此,我们看到上面大约一半的核心忙于运行示例脚本。)

图 4. 非统一内存访问分析图
图 4. 比较了本地内存访问与远程内存访问随时间的变化。我们验证了远程内存的使用,这可能导致次优性能。
设置线程亲和性以减少远程内存访问和跨 Socket (UPI) 流量
将线程绑定到同一 Socket 上的核心有助于保持内存访问的局部性。在此示例中,我们将绑定到第一个 NUMA 节点 (0-27) 上的物理核心。通过启动脚本,用户可以很容易地通过简单地切换 --node_id 启动脚本选项来实验 NUMA 节点配置。
现在让我们可视化 CPU 使用情况。
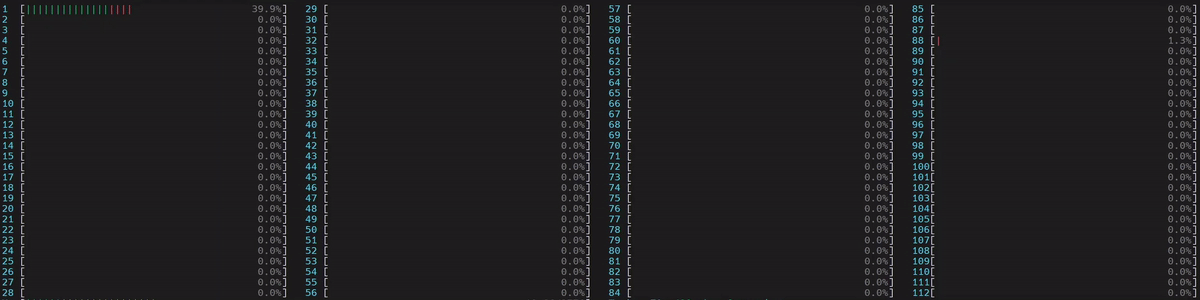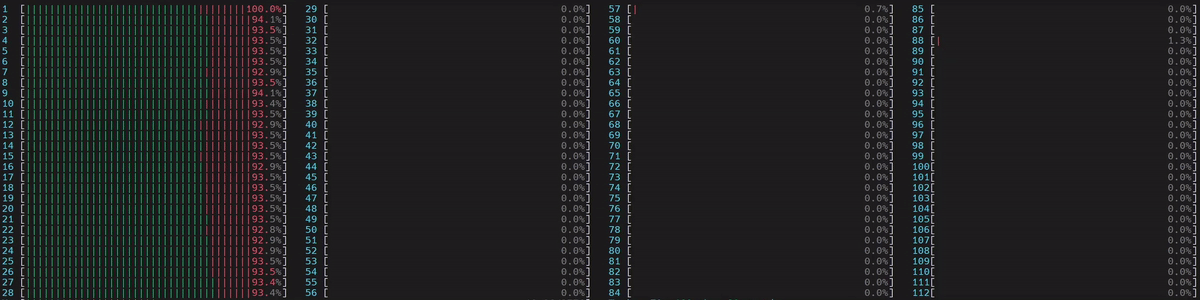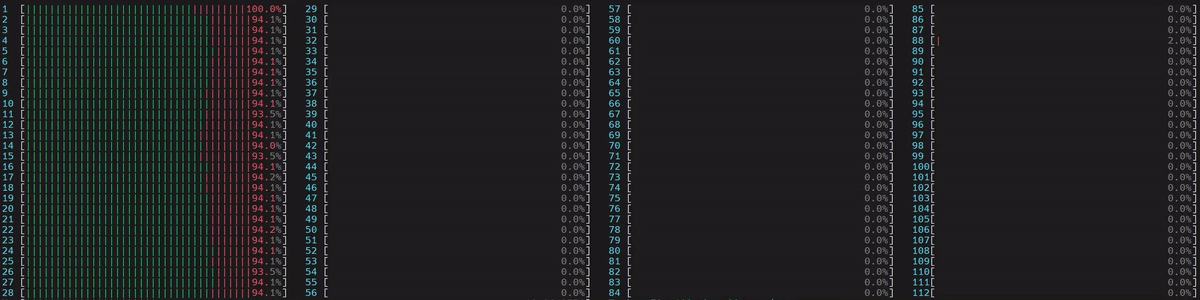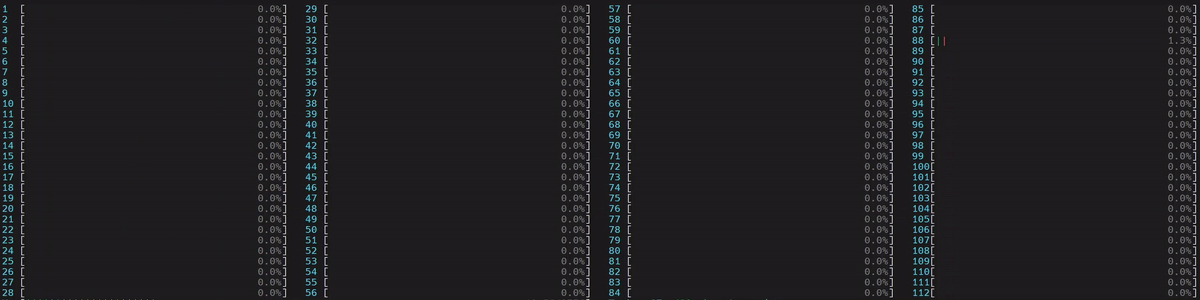
图 5. NUMA 感知应用的 CPU 使用情况
启动了 1 个主工作线程,然后它在第一个 NUMA 节点上的所有物理核心上启动了线程。

图 6. 非统一内存访问分析图
如图 6 所示,现在几乎所有的内存访问都是本地访问。
通过核心绑定实现多 worker 推理的高效 CPU 使用¶
运行多 worker 推理时,核心会在 worker 之间重叠(或共享),导致 CPU 使用效率低下。为了解决这个问题,启动脚本将可用核心数平均分配给 worker 数,以便每个 worker 在运行时被绑定到指定的核心。
TorchServe 练习
在此练习中,我们将把迄今讨论的 CPU 性能调优原则和建议应用于 TorchServe apache-bench 基准测试。
我们将使用 ResNet50,设置 4 个 worker,并发度 100,请求数 10,000。所有其他参数(例如 batch_size、输入等)与默认参数相同。
我们将比较以下三种配置:
默认 TorchServe 设置(无核心绑定)
torch.set_num_threads =
物理核心数 / worker 数(无核心绑定)通过启动脚本进行核心绑定(需要 Torchserve >= 0.6.1)
完成此练习后,我们将通过一个真实的 TorchServe 用例来验证我们更倾向于避免使用逻辑核心,并通过核心绑定来实现本地内存访问。
1. 默认 TorchServe 设置(无核心绑定)¶
base_handler 没有显式设置 torch.set_num_threads。因此,如此处所述,默认线程数是物理 CPU 核心的数量。用户可以在 base_handler 中通过 torch.get_num_threads 检查线程数。4 个主 worker 线程中的每一个都启动了物理核心数量 (56) 的线程,总共启动了 56x4 = 224 个线程,这超过了总核心数 112。因此,核心肯定会严重重叠,逻辑核心利用率很高——多个 worker 同时使用多个核心。此外,由于线程未绑定到特定的 CPU 核心,操作系统会定期将线程调度到位于不同 Socket 的核心上。
CPU 使用情况
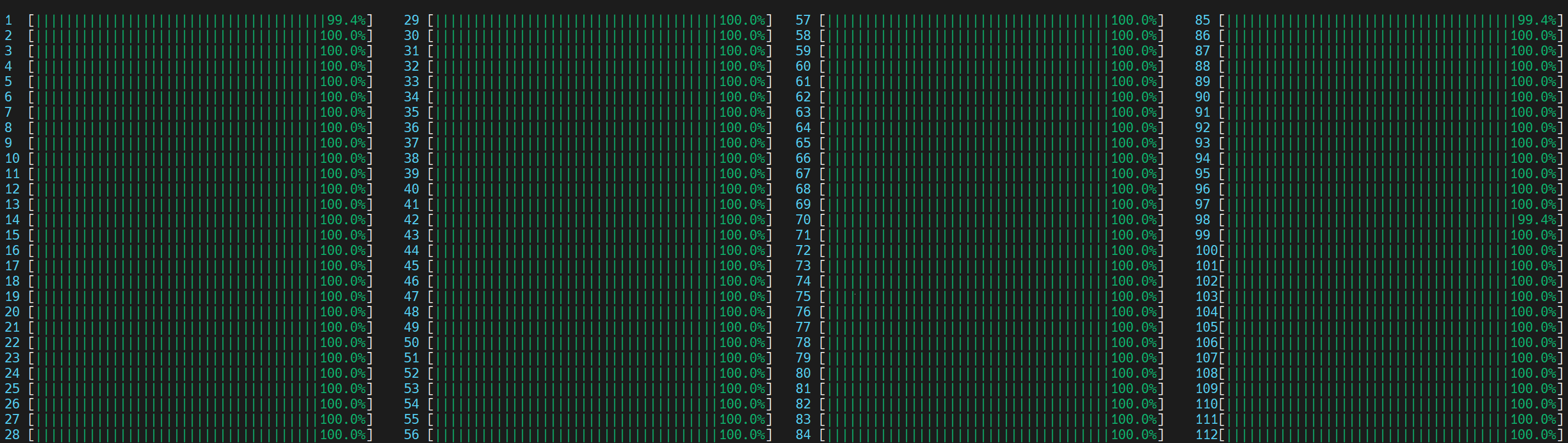
启动了 4 个主 worker 线程,然后每个都在所有核心(包括逻辑核心)上启动了物理核心数量 (56) 的线程。
核心限制停顿
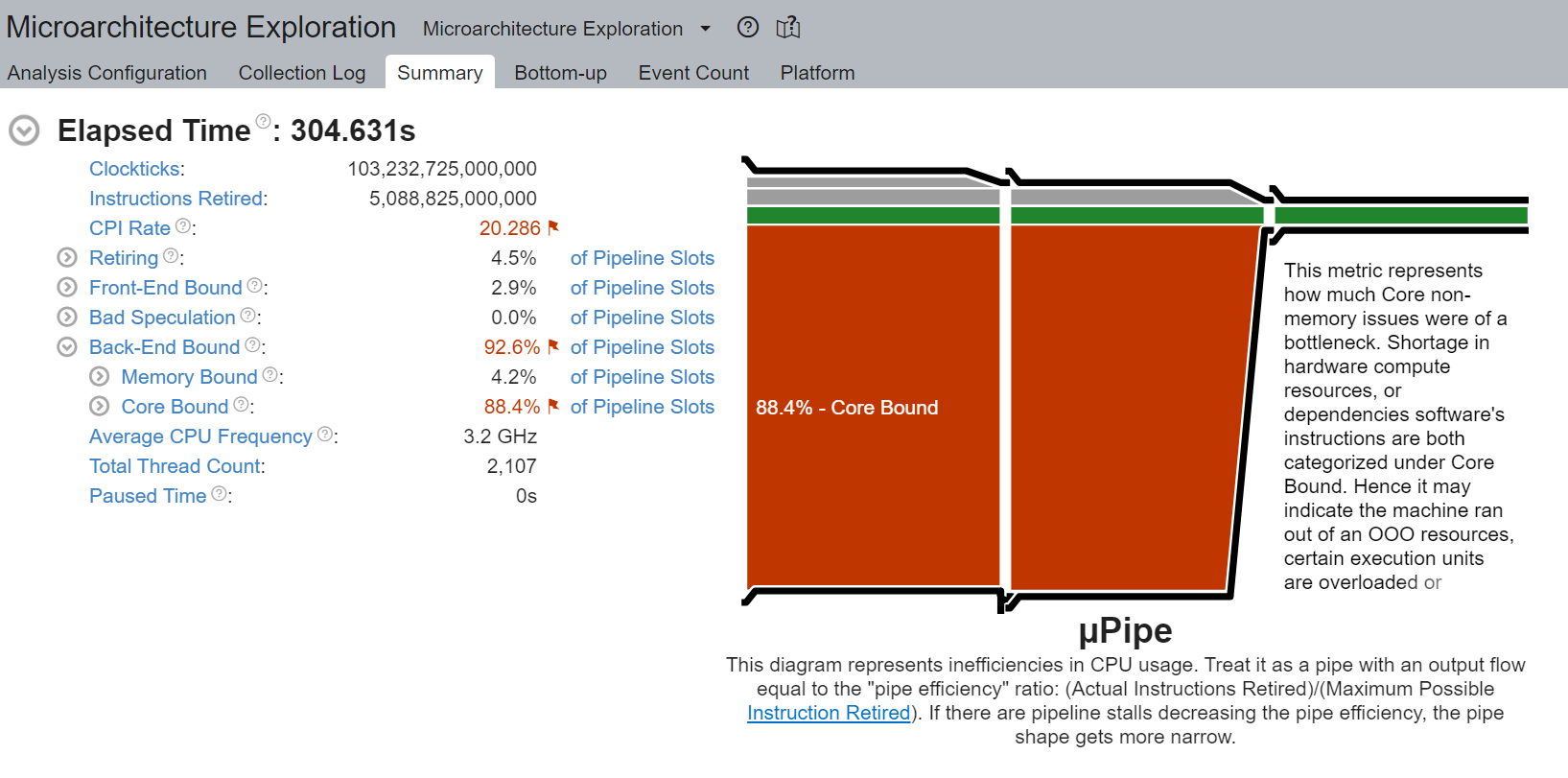
我们观察到非常高的核心限制停顿,高达 88.4%,降低了流水线效率。核心限制停顿表明 CPU 中可用执行单元的使用次优。例如,一系列 GEMM 指令争用超线程核心共享的融合乘加 (FMA) 或点积 (DP) 执行单元可能导致核心限制停顿。如前一部分所述,使用逻辑核心会加剧此问题。
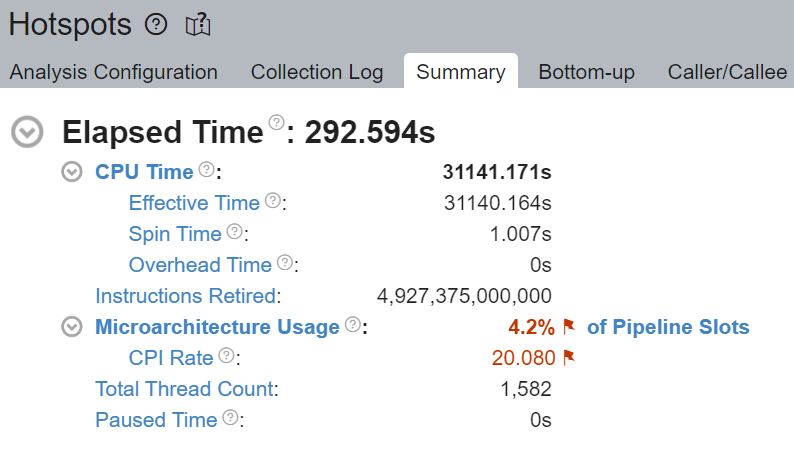
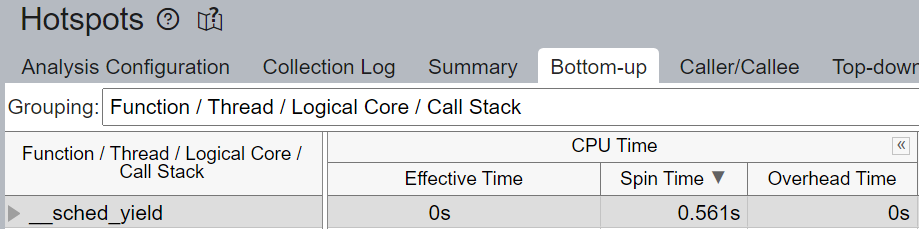
流水线中未填充微操作 (uOps) 的空槽归因于停顿。例如,未进行核心绑定时,CPU 使用可能不是有效地用于计算,而是用于 Linux 内核的线程调度等其他操作。我们看到上面 __sched_yield 导致了大部分的空转时间。
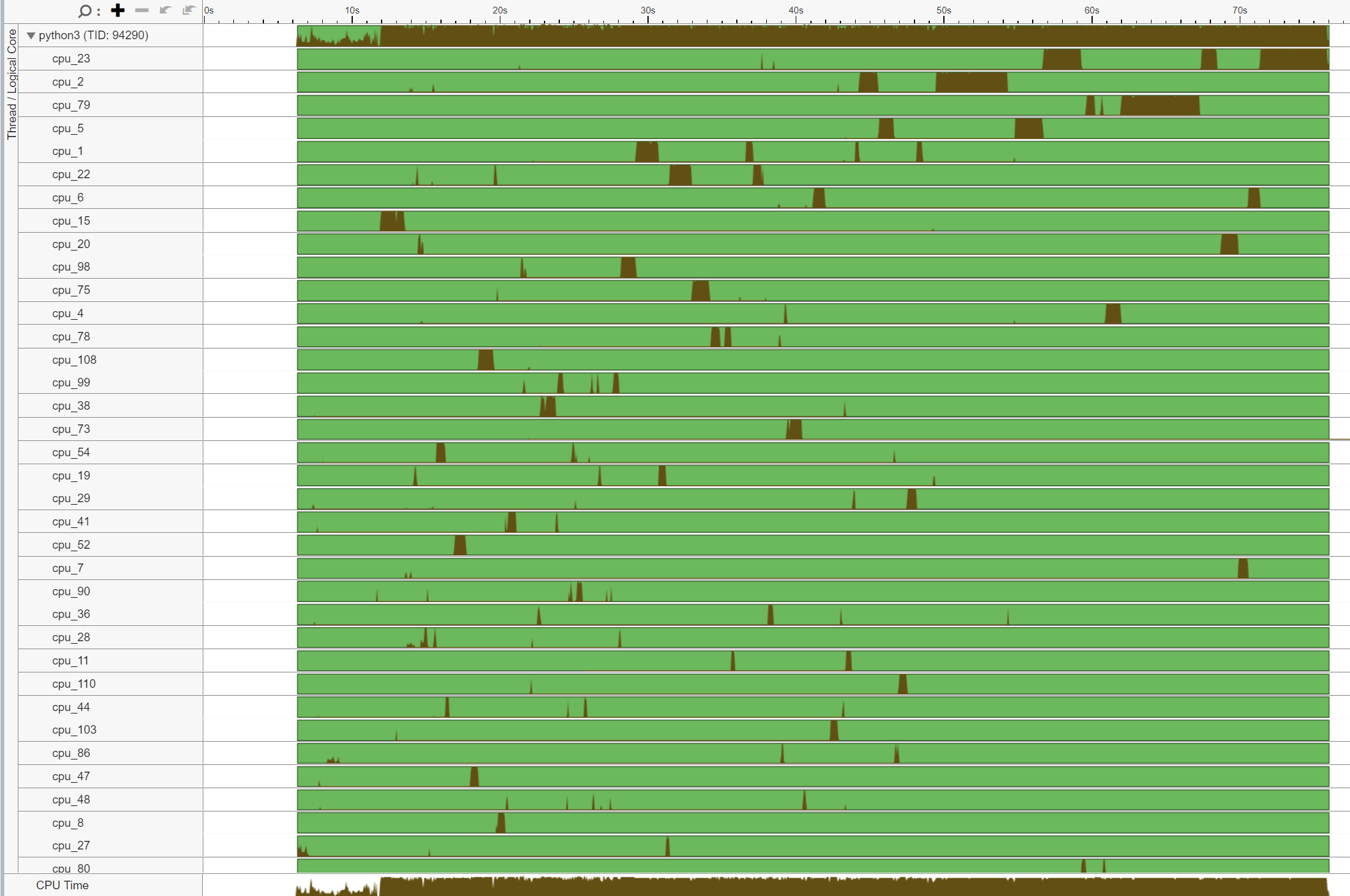
线程迁移
未进行核心绑定时,调度器可能将在一个核心上执行的线程迁移到不同的核心。线程迁移可能导致线程与其已获取到缓存中的数据分离,导致更长的数据访问延迟。在 NUMA 系统中,当线程跨 Socket 迁移时,此问题会加剧。已获取到本地内存高速缓存中的数据现在变为远程内存,这会慢得多。
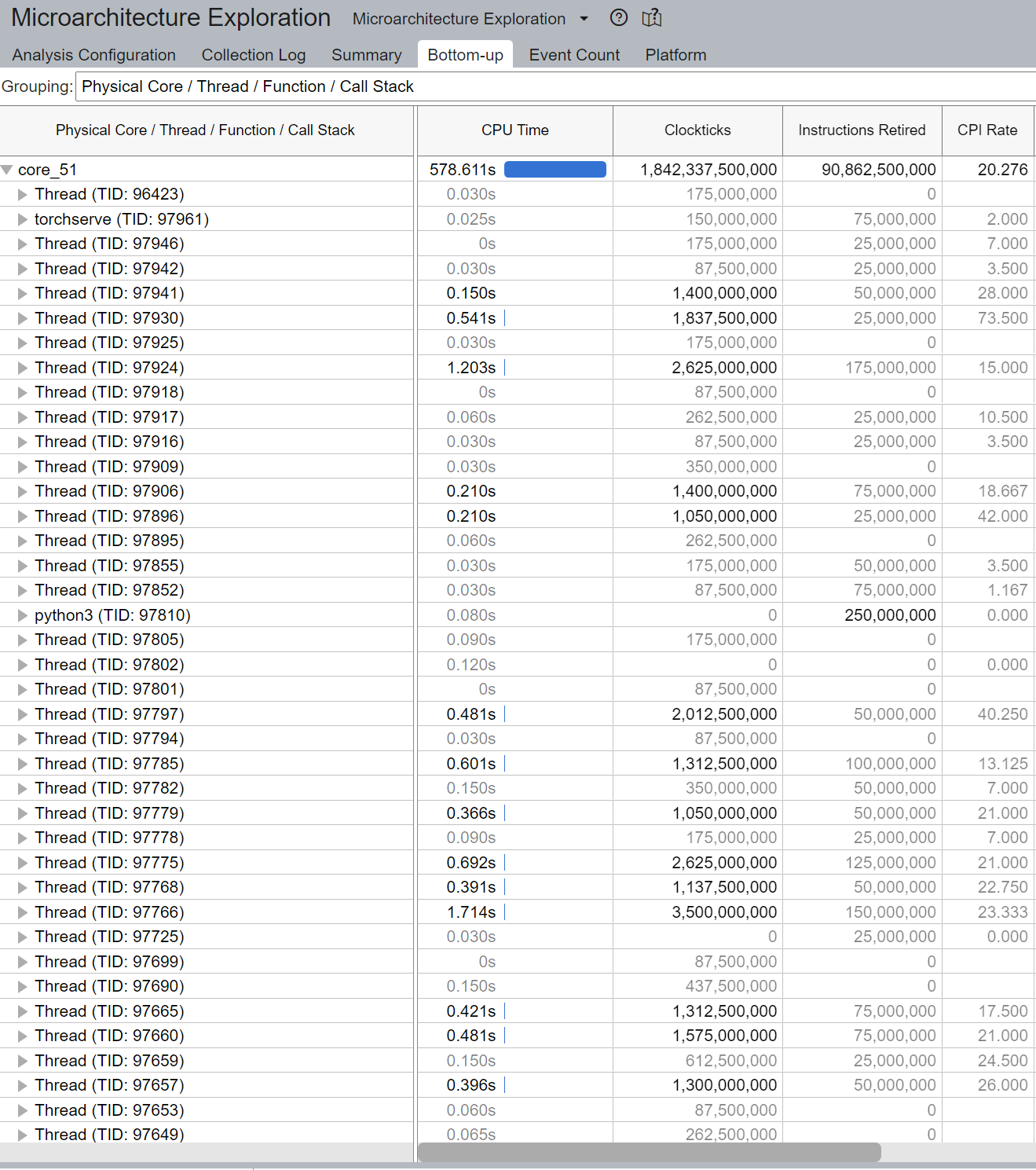
通常,线程总数应小于或等于核心支持的线程总数。在上面的示例中,我们注意到 core_51 上执行的线程数量很大,而不是预期的 2 个线程(因为 Intel(R) Xeon(R) Platinum 8180 CPU 中启用了超线程)。这表明存在线程迁移。
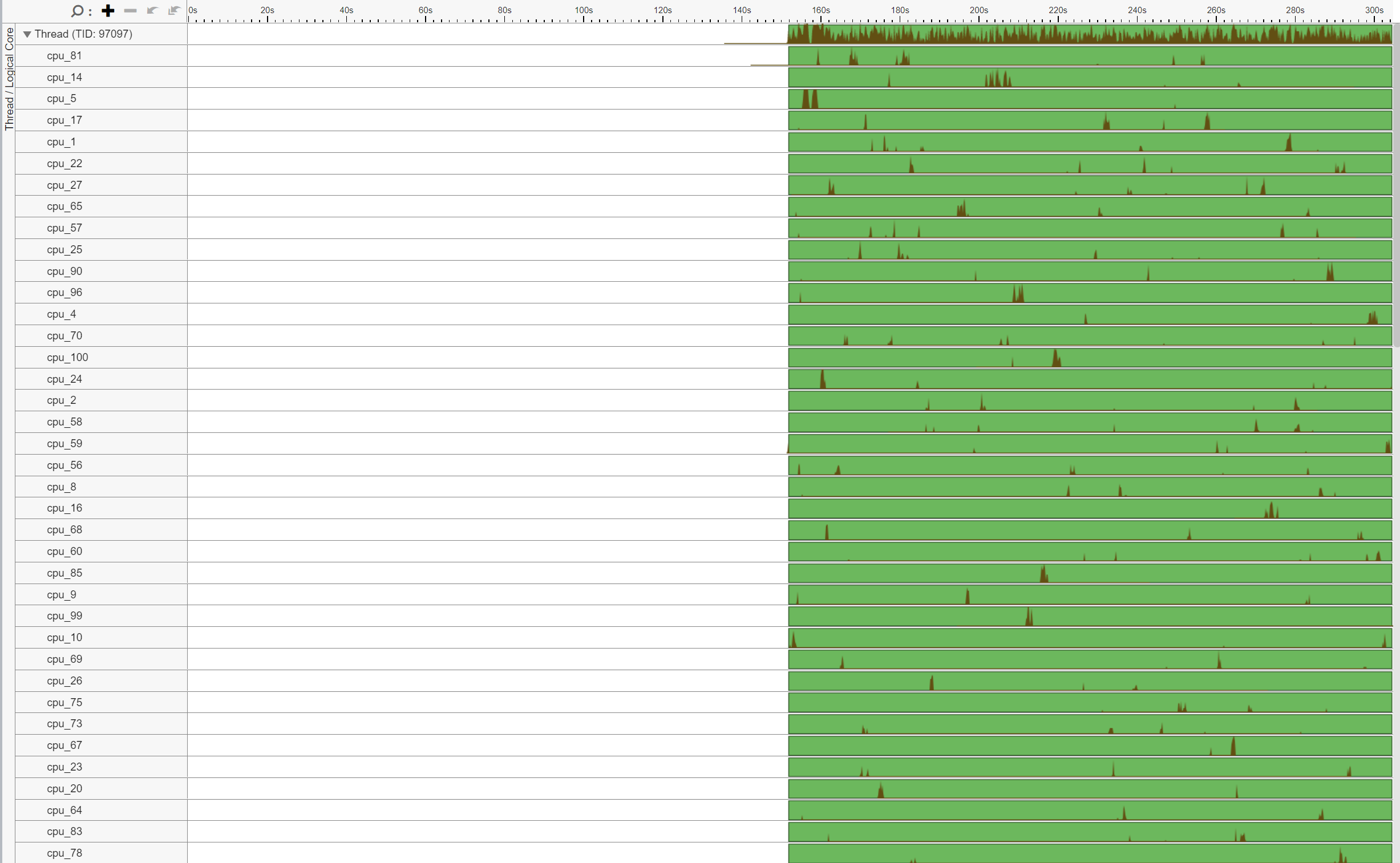
此外,注意线程 (TID:97097) 在大量 CPU 核心上执行,表明 CPU 迁移。例如,此线程在 cpu_81 上执行,然后迁移到 cpu_14,再迁移到 cpu_5,等等。此外,注意此线程多次来回跨 Socket 迁移,导致非常低效的内存访问。例如,此线程在 cpu_70 (NUMA 节点 0) 上执行,然后迁移到 cpu_100 (NUMA 节点 1),再迁移到 cpu_24 (NUMA 节点 0)。
非统一内存访问分析

比较本地内存访问与远程内存访问随时间的变化。我们观察到大约一半,即 51.09% 的内存访问是远程访问,表明 NUMA 配置次优。
2. torch.set_num_threads = 物理核心数 / worker 数(无核心绑定)¶
为了与启动器的核心绑定进行同等比较,我们将线程数设置为核心数除以 worker 数(启动器在内部执行此操作)。在 base_handler 中添加以下代码片段
torch.set_num_threads(num_physical_cores/num_workers)
与之前未进行核心绑定一样,这些线程未绑定到特定的 CPU 核心,导致操作系统定期将线程调度到位于不同 Socket 的核心上。
CPU 使用情况
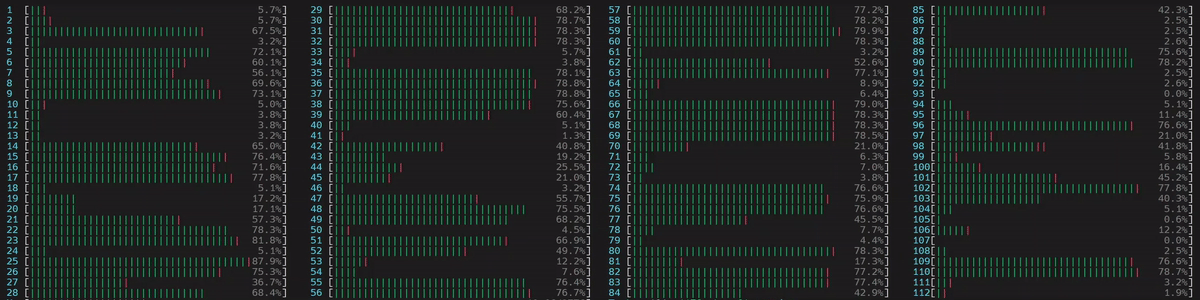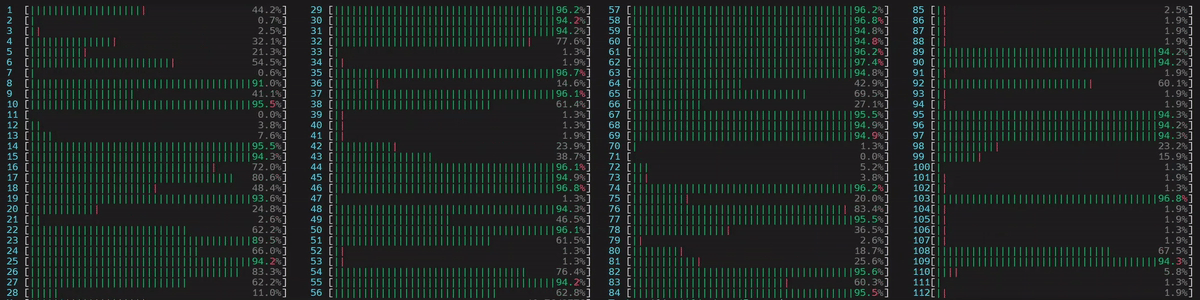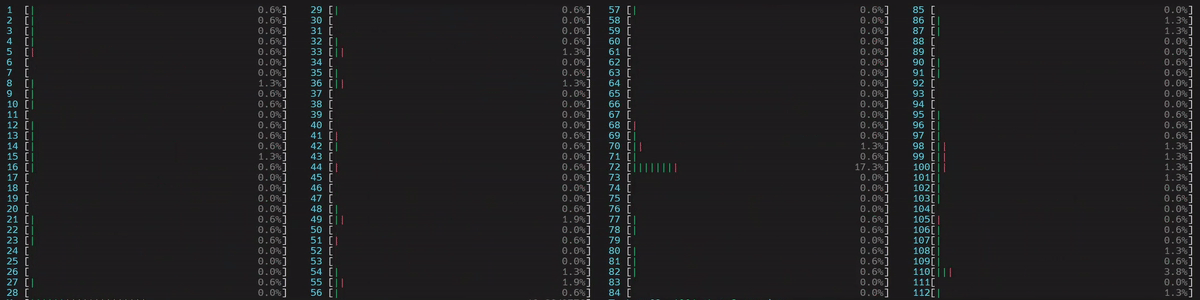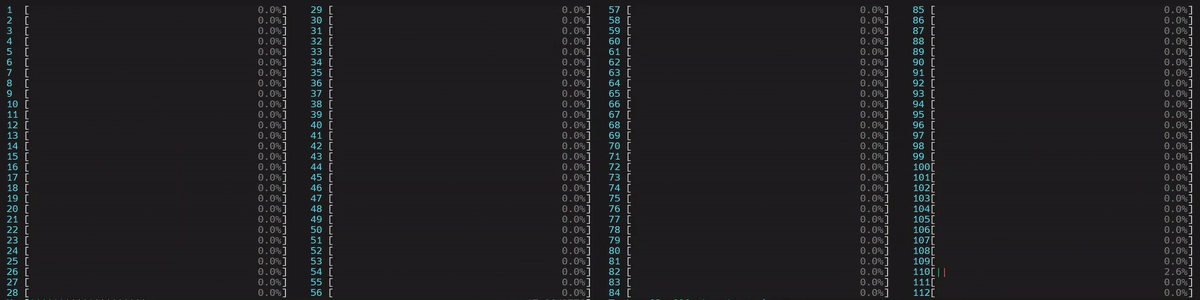
启动了 4 个主工作线程,然后每个线程在所有核心(包括逻辑核心)上启动了 num_physical_cores/num_workers 个(14 个)线程。
核心限制停顿
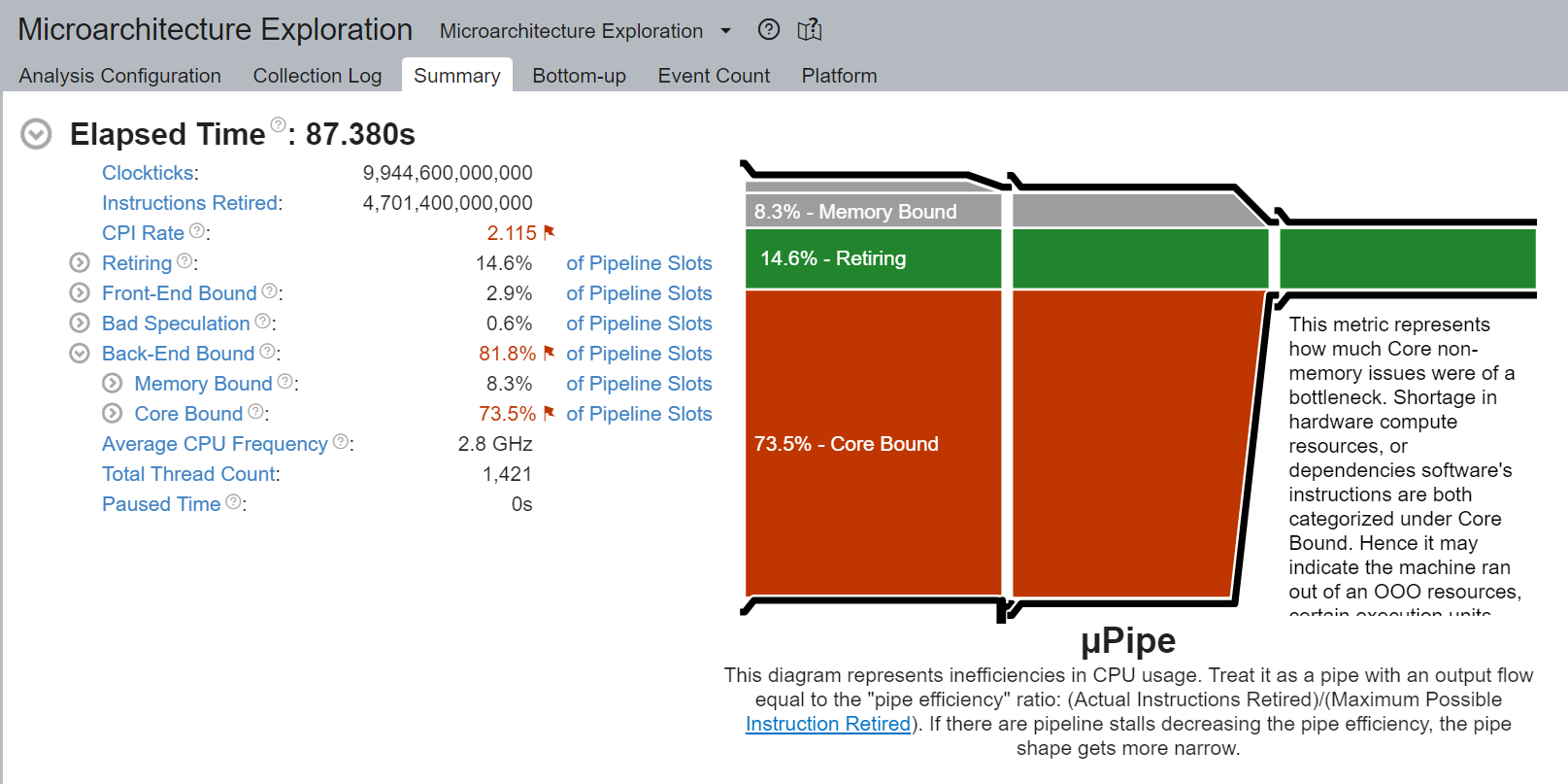
尽管核心受限(Core Bound)停顿的百分比从 88.4% 下降到 73.5%,但核心受限仍然非常高。
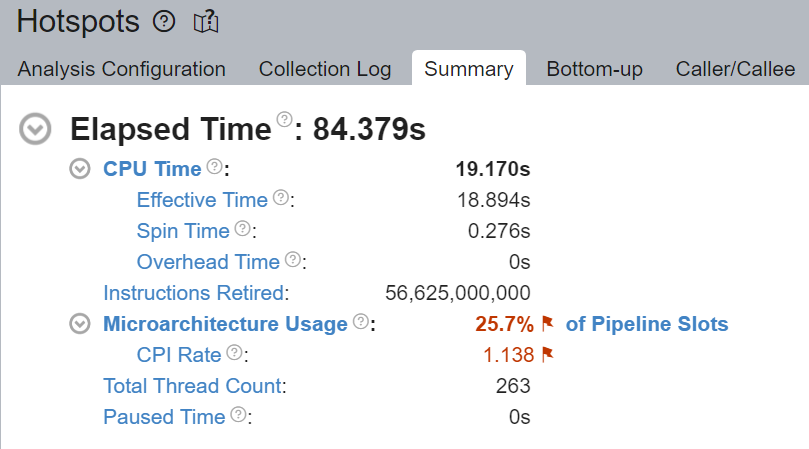
线程迁移
与之前类似,在没有进行核心绑定(core pinning)的情况下,线程 (TID:94290) 在大量 CPU 核心上执行,这表明存在 CPU 迁移。我们再次注意到跨插槽(cross-socket)线程迁移,导致内存访问非常低效。例如,该线程先在 cpu_78 (NUMA node 0) 上执行,然后迁移到 cpu_108 (NUMA node 1) 上。
非统一内存访问分析

尽管较原始的 51.09% 有所改善,但仍有 40.45% 的内存访问是远程访问,这表明 NUMA 配置不是最优的。
3. launcher 核心绑定¶
Launcher 将在内部将物理核心平均分配给 worker,并将它们绑定到每个 worker。提醒一下,launcher 默认仅使用物理核心。在本例中,launcher 将 worker 0 绑定到核心 0-13 (NUMA node 0),worker 1 绑定到核心 14-27 (NUMA node 0),worker 2 绑定到核心 28-41 (NUMA node 1),以及 worker 3 绑定到核心 42-55 (NUMA node 1)。这样做可以确保核心在 worker 之间不重叠,并避免使用逻辑核心。
CPU 使用情况
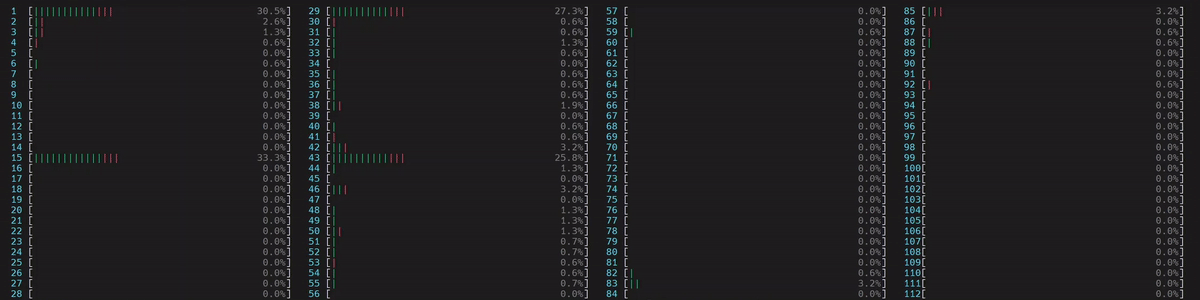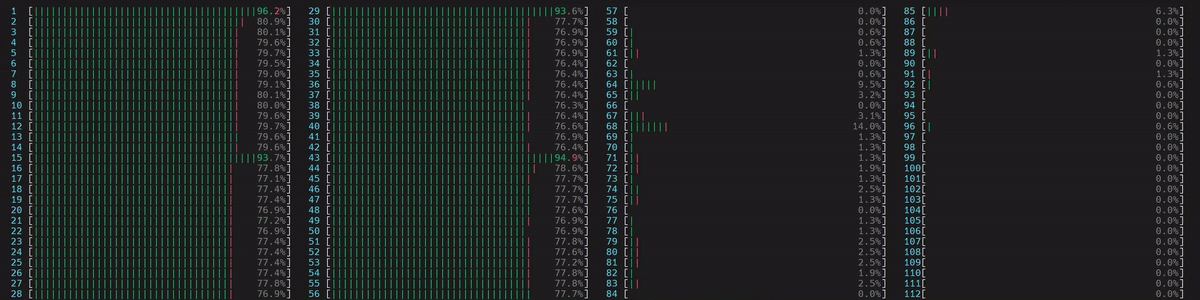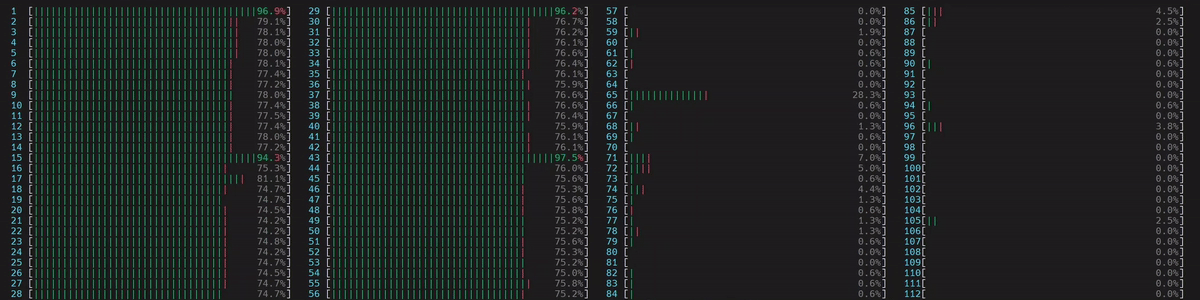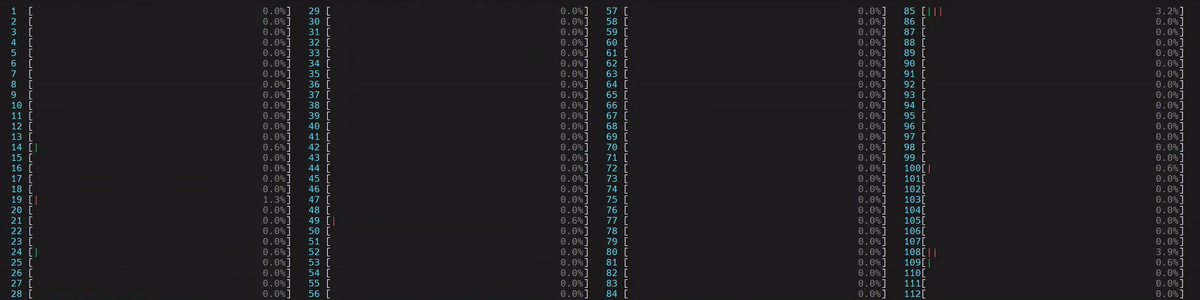
启动了 4 个主工作线程,然后每个线程启动了 num_physical_cores/num_workers 个(14 个)与分配的物理核心亲和(affinitized)的线程。
核心限制停顿
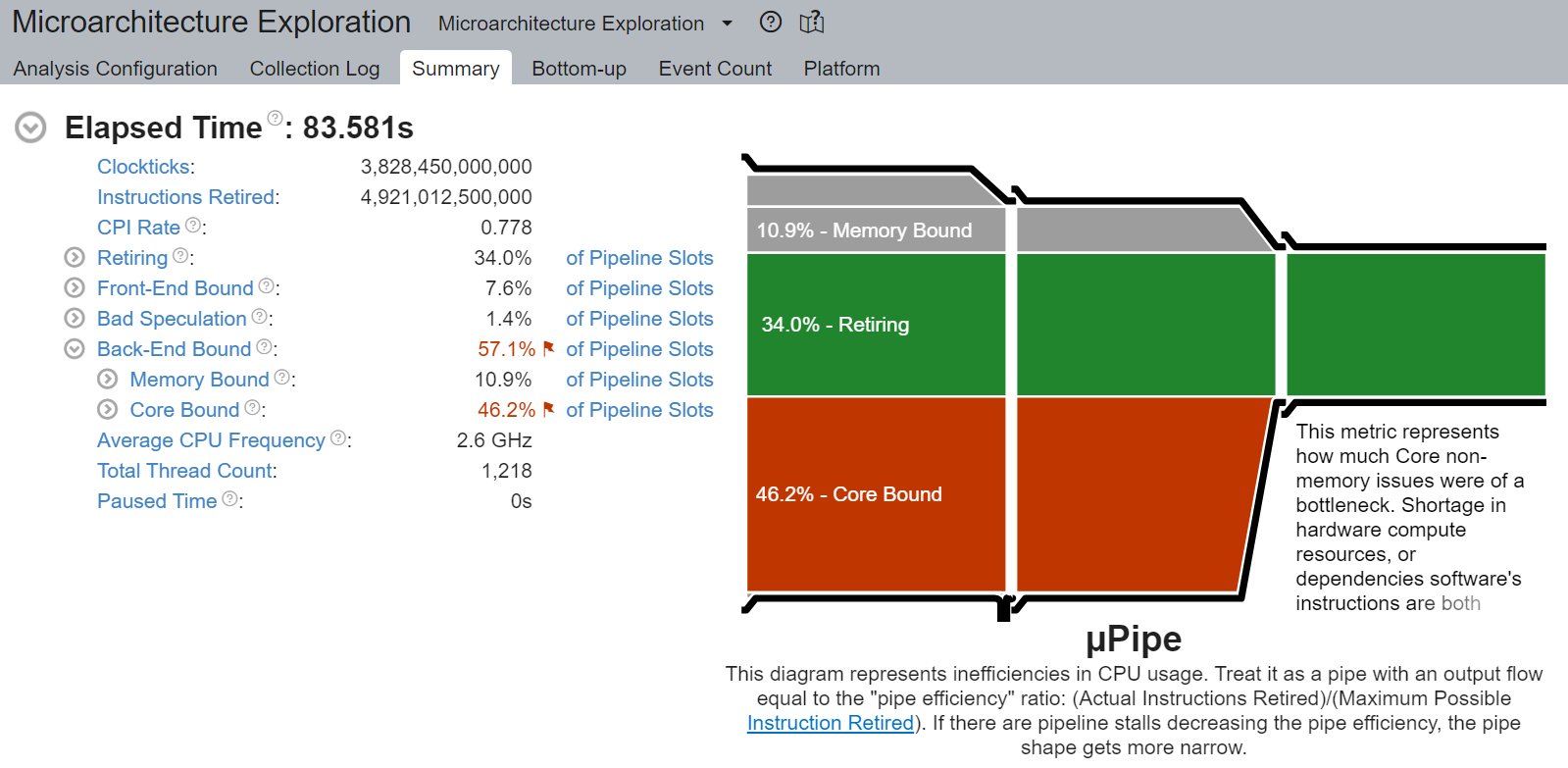
核心受限停顿从原始的 88.4% 显著下降到 46.2% - 几乎是 2 倍的改进。
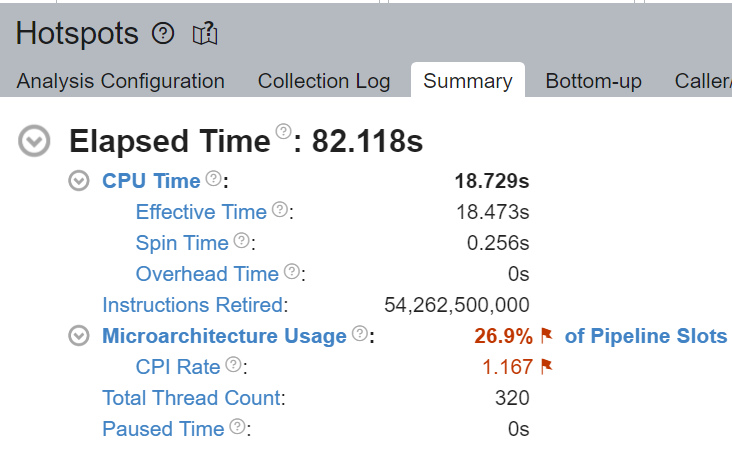
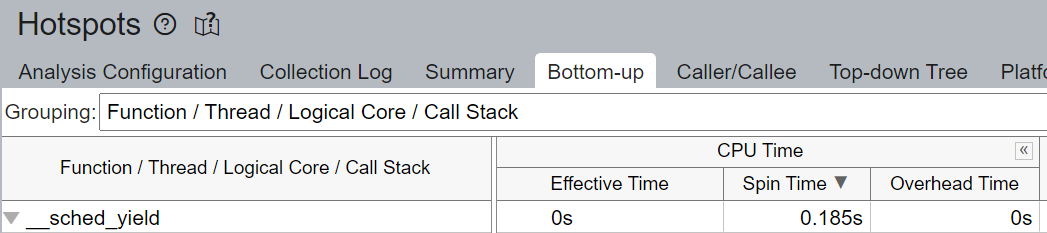
我们验证了通过核心绑定,大部分 CPU 时间被有效用于计算 - 自旋时间(Spin Time)为 0.256 秒。
线程迁移

我们验证了 OMP 主线程 #0 被绑定到分配的物理核心 (42-55),并且没有发生跨插槽迁移。
非统一内存访问分析

现在几乎所有的内存访问(89.52%)都是本地访问。
结论¶
在这篇博文中,我们展示了正确设置 CPU 运行时配置可以显著提升开箱即用的 CPU 性能。
我们介绍了一些通用的 CPU 性能调优原则和建议
在启用超线程(hyperthreading)的系统中,通过核心绑定将线程亲和性设置为仅物理核心,以避免使用逻辑核心。
在具有 NUMA 的多插槽系统中,通过核心绑定将线程亲和性设置为特定的插槽,以避免跨插槽远程内存访问。
我们从基本原理出发直观地解释了这些想法,并通过性能分析(profiling)验证了性能提升。最后,我们将所有学到的知识应用于 TorchServe,以提升开箱即用的 TorchServe CPU 性能。
这些原则可以通过一个易于使用的启动脚本自动配置,该脚本已集成到 TorchServe 中。
对于感兴趣的读者,请查阅以下文档
请继续关注后续文章,了解通过 Intel® Extension for PyTorch* 在 CPU 上进行的优化内核以及诸如内存分配器等高级 launcher 配置。
致谢¶
我们要感谢 Ashok Emani (Intel) 和 Jiong Gong (Intel) 在本博文的许多步骤中提供的巨大指导和支持,以及详尽的反馈和审阅。我们还要感谢 Hamid Shojanazeri (Meta)、Li Ning (AWS) 和 Jing Xu (Intel) 在代码审阅中提供的有益反馈。同时感谢 Suraj Subramanian (Meta) 和 Geeta Chauhan (Meta) 对博文提供的有益反馈。
