


编译后的Autograd:为torch.compile捕获更大的反向图¶
创建日期:Oct 09, 2024 | 最后更新:Oct 23, 2024 | 最后验证:Oct 09, 2024
作者: Simon Fan
编译后的autograd如何与
torch.compile交互如何使用编译后的autograd API
如何使用
TORCH_LOGS检查日志
PyTorch 2.4
阅读PyTorch 2.x入门中的TorchDynamo和AOTAutograd部分
概述¶
编译后的Autograd是PyTorch 2.4中引入的一个torch.compile扩展,它允许捕获更大的反向图。
虽然torch.compile确实会捕获反向图,但它是部分捕获的。AOTAutograd组件会提前捕获反向图,但也存在某些限制:
前向过程中的图中断会导致反向过程中的图中断
反向钩子不会被捕获
编译后的Autograd通过直接与autograd引擎集成来解决这些限制,使其能够在运行时捕获完整的反向图。具有这两个特征的模型应该尝试编译后的Autograd,并有可能观察到更好的性能。
然而,编译后的Autograd也引入了自己的限制:
在反向传播开始时增加缓存查找的运行时开销
由于捕获更大,更容易在dynamo中导致重新编译和图中断
注意
编译后的Autograd正在积极开发中,尚未兼容所有现有的PyTorch功能。有关特定功能的最新状态,请参阅编译后的Autograd登陆页面。
设置¶
在本教程中,我们将基于这个简单的神经网络模型构建示例。它接受一个10维的输入向量,通过一个线性层进行处理,并输出另一个10维的向量。
import torch
class Model(torch.nn.Module):
def __init__(self):
super().__init__()
self.linear = torch.nn.Linear(10, 10)
def forward(self, x):
return self.linear(x)
基本用法¶
在调用torch.compile API之前,请确保将torch._dynamo.config.compiled_autograd设置为True
model = Model()
x = torch.randn(10)
torch._dynamo.config.compiled_autograd = True
@torch.compile
def train(model, x):
loss = model(x).sum()
loss.backward()
train(model, x)
在上面的代码中,我们创建了一个Model类的实例,并使用torch.randn(10)生成了一个随机的10维张量x。我们定义了训练循环函数train,并用@torch.compile装饰它来优化其执行。当调用train(model, x)时:
Python解释器调用Dynamo,因为此调用已用
@torch.compile装饰。Dynamo拦截Python字节码,模拟其执行并将操作记录到图中。
AOTDispatcher禁用钩子并调用autograd引擎来计算model.linear.weight和model.linear.bias的梯度,并将操作记录到图中。使用torch.autograd.Function,AOTDispatcher重写train的前向和反向实现。Inductor生成一个函数,该函数对应于AOTDispatcher前向和反向的优化实现。
Dynamo设置优化后的函数,由Python解释器下一步评估。
Python解释器执行优化后的函数,该函数执行
loss = model(x).sum()。Python解释器执行
loss.backward(),调用autograd引擎,由于我们设置了torch._dynamo.config.compiled_autograd = True,因此会路由到编译后的Autograd引擎。编译后的Autograd计算
model.linear.weight和model.linear.bias的梯度,并将操作记录到图中,包括遇到的任何钩子。在此过程中,它将记录先前由AOTDispatcher重写的反向传播。然后,编译后的Autograd生成一个新函数,该函数对应于loss.backward()的完全追踪实现,并在推理模式下使用torch.compile执行它。同样的步骤递归地应用于编译后的Autograd图,但这次AOTDispatcher将不再需要对图进行分区。
检查编译后的autograd日志¶
使用TORCH_LOGS环境变量运行脚本
仅打印编译后的autograd图,使用
TORCH_LOGS="compiled_autograd" python example.py以牺牲性能为代价,打印包含更多张量元数据和重新编译原因的图,使用
TORCH_LOGS="compiled_autograd_verbose" python example.py
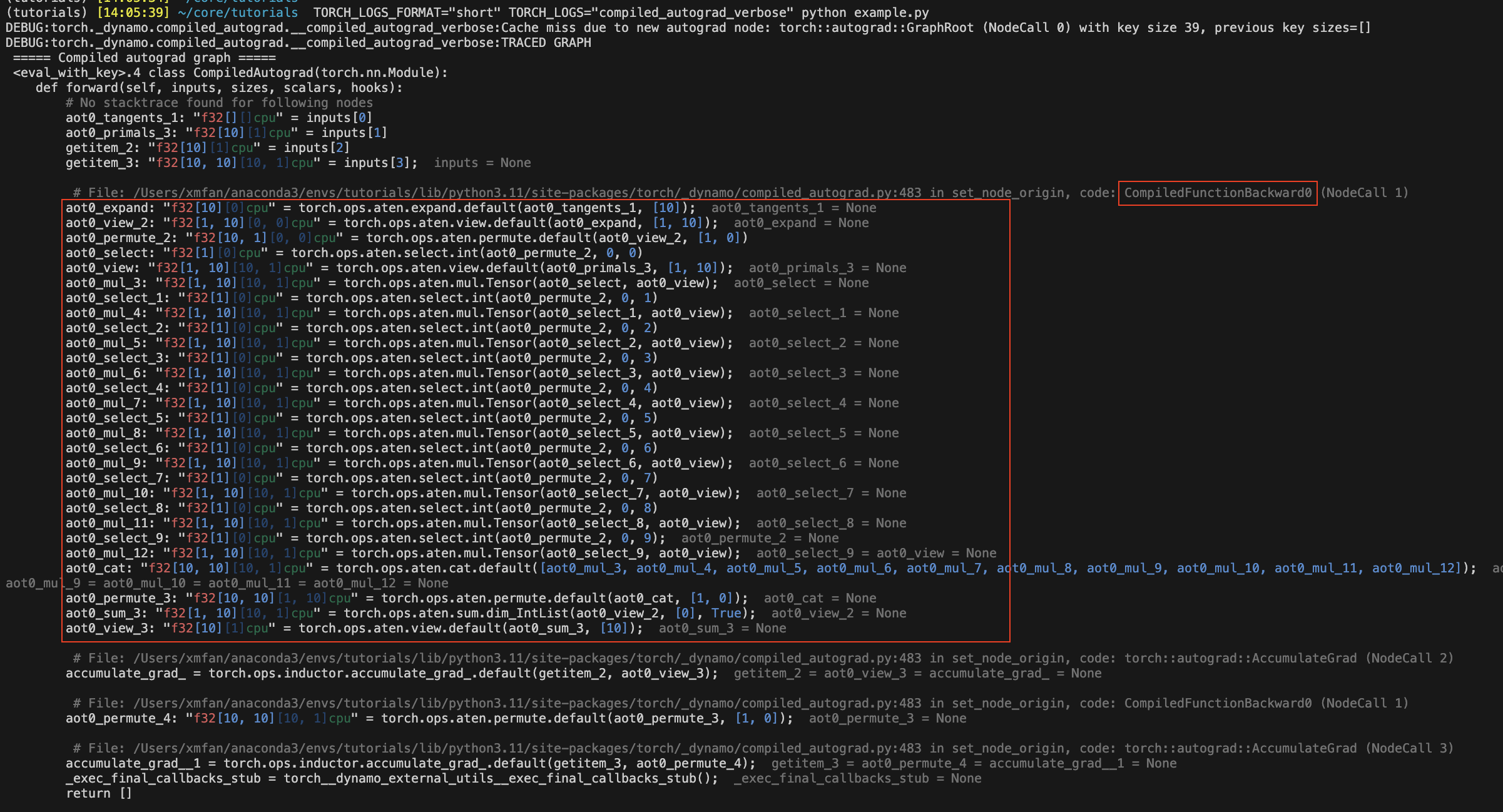
重新运行上面的代码片段,编译后的autograd图现在应该被记录到stderr中。某些图节点的名称将带有aot0_前缀,这些对应于先前在AOTAutograd反向图0中提前编译的节点,例如,aot0_view_2对应于id=0的AOT反向图的view_2。
在下面的图片中,红色框封装了在没有编译后的Autograd情况下被torch.compile捕获的AOT反向图。
注意
这是我们将调用torch.compile的图,不是优化后的图。编译后的Autograd本质上生成一些未优化的Python代码来表示整个C++ autograd执行。
使用不同标志编译前向和反向传播¶
你可以对两次编译使用不同的编译器配置,例如,即使前向传播中存在图中断,反向传播也可能是一个全图(fullgraph)。
def train(model, x):
model = torch.compile(model)
loss = model(x).sum()
torch._dynamo.config.compiled_autograd = True
torch.compile(lambda: loss.backward(), fullgraph=True)()
或者你可以使用上下文管理器,它将应用于其作用域内的所有autograd调用。
def train(model, x):
model = torch.compile(model)
loss = model(x).sum()
with torch._dynamo.compiled_autograd.enable(torch.compile(fullgraph=True)):
loss.backward()
编译后的Autograd解决了AOTAutograd的某些限制¶
前向传播中的图中断不再必然导致反向传播中的图中断
@torch.compile(backend="aot_eager")
def fn(x):
# 1st graph
temp = x + 10
torch._dynamo.graph_break()
# 2nd graph
temp = temp + 10
torch._dynamo.graph_break()
# 3rd graph
return temp.sum()
x = torch.randn(10, 10, requires_grad=True)
torch._dynamo.utils.counters.clear()
loss = fn(x)
# 1. base torch.compile
loss.backward(retain_graph=True)
assert(torch._dynamo.utils.counters["stats"]["unique_graphs"] == 3)
torch._dynamo.utils.counters.clear()
# 2. torch.compile with compiled autograd
with torch._dynamo.compiled_autograd.enable(torch.compile(backend="aot_eager")):
loss.backward()
# single graph for the backward
assert(torch._dynamo.utils.counters["stats"]["unique_graphs"] == 1)
在第一个torch.compile案例中,我们看到由于编译函数fn中的2个图中断,产生了3个反向图。而在使用编译后的autograd的第二个torch.compile案例中,我们看到尽管有图中断,仍然追踪到了一个完整的反向图。
注意
Dynamo在追踪由编译后的Autograd捕获的反向钩子时,仍然可能发生图中断。
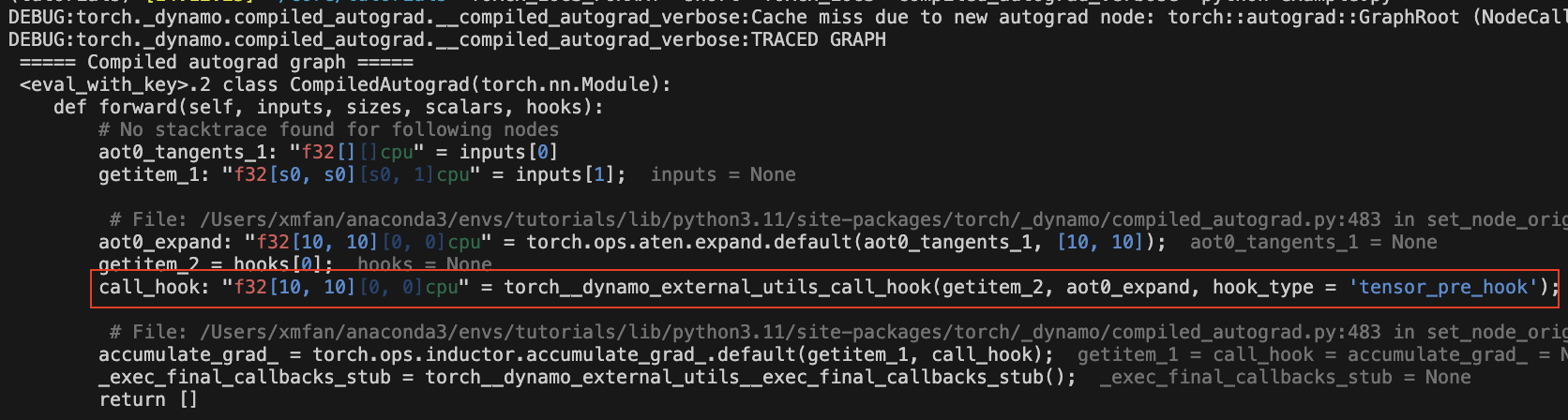
反向钩子现在可以被捕获
@torch.compile(backend="aot_eager")
def fn(x):
return x.sum()
x = torch.randn(10, 10, requires_grad=True)
x.register_hook(lambda grad: grad+10)
loss = fn(x)
with torch._dynamo.compiled_autograd.enable(torch.compile(backend="aot_eager")):
loss.backward()
图中应该有一个call_hook节点,Dynamo稍后会将其内联到以下内容
编译后的Autograd常见的重新编译原因¶
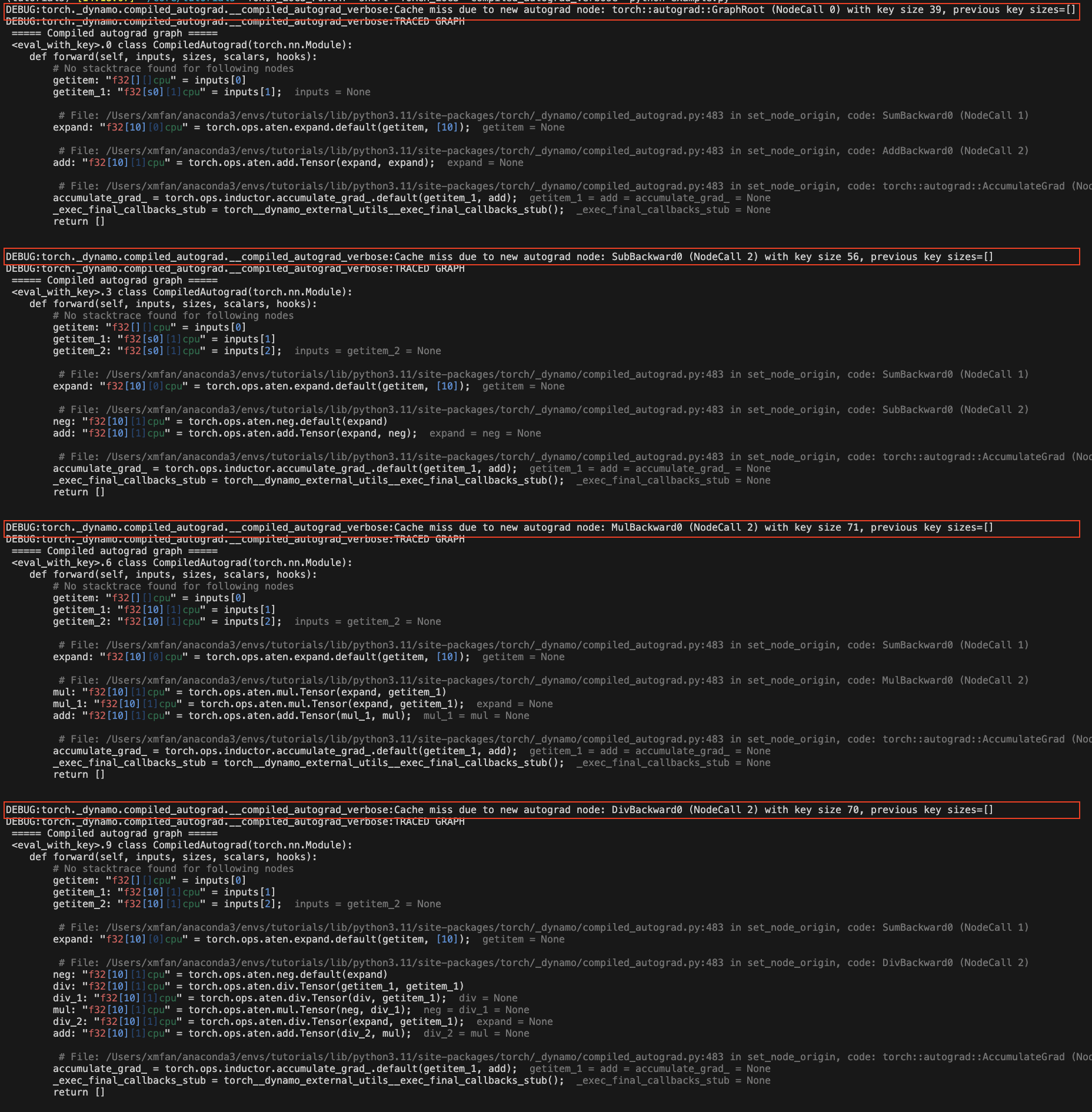
由于loss值的autograd结构发生变化
torch._dynamo.config.compiled_autograd = True
x = torch.randn(10, requires_grad=True)
for op in [torch.add, torch.sub, torch.mul, torch.div]:
loss = op(x, x).sum()
torch.compile(lambda: loss.backward(), backend="eager")()
在上面的示例中,我们在每次迭代时调用不同的操作符,导致loss每次跟踪不同的autograd历史。你应该会看到一些重新编译消息:Cache miss due to new autograd node。
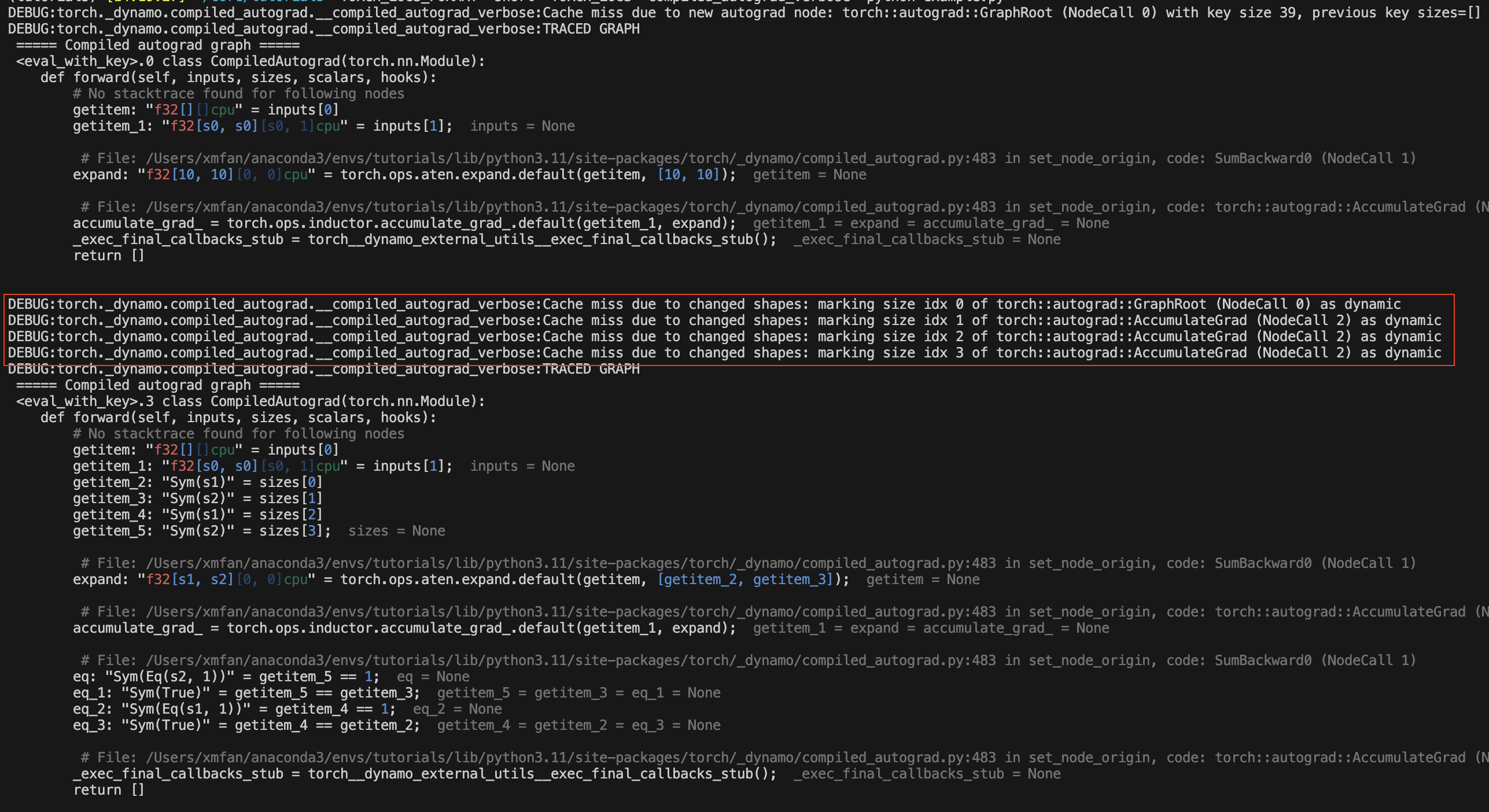
由于张量形状发生变化
torch._dynamo.config.compiled_autograd = True
for i in [10, 100, 10]:
x = torch.randn(i, i, requires_grad=True)
loss = x.sum()
torch.compile(lambda: loss.backward(), backend="eager")()
在上面的示例中,x的形状发生变化,编译后的autograd会在第一次变化后将x标记为动态形状张量。你应该会看到重新编译消息:Cache miss due to changed shapes。
结论¶
在本教程中,我们回顾了带有编译后的autograd的torch.compile的高层生态系统、编译后的autograd的基础知识以及一些常见的重新编译原因。请关注dev-discuss上的深入探讨。
