TorchInductor GPU 性能分析¶
本节列出了一些有用的命令和工作流程,可以帮助您深入了解模型在 TorchInductor 中的性能。当模型运行速度不如预期时,您可能需要检查模型的各个内核。通常,占用 GPU 时间最多的内核是最值得关注的。之后,您可能还想直接运行单个内核并检查其性能。PyTorch 提供了涵盖上述所有内容的工具。
相关环境变量¶
您可以在分析中使用以下环境变量
TORCHINDUCTOR_UNIQUE_KERNEL_NAMES默认情况下,TorchInductor 将 Triton 内核命名为
‘triton\_’。启用此环境变量后,inductor 会在 trace 中生成更有意义的内核名称,例如triton_poi_fused_cat_155,其中包含内核类别(poi表示逐点操作)和原始 ATen 算子。默认禁用此配置是为了提高编译缓存命中率。
TORCHINDUCTOR_BENCHMARK_KERNEL启用此选项将使 inductor 代码生成工具对单个 triton 内核进行基准测试。
TORCHINDUCTOR_MAX_AUTOTUNEInductor 自动调优器将对更多
triton.Configs进行基准测试,并选择性能最佳的配置。这会增加编译时间,以期提升性能。
分解模型的 GPU 时间¶
以下是将模型执行时间分解到单个内核的步骤。我们以 mixnet_l 为例。
运行模型的基准测试脚本
TORCHINDUCTOR_UNIQUE_KERNEL_NAMES=1 TORCHINDUCTOR_BENCHMARK_KERNEL=1 python -u benchmarks/dynamo/timm_models.py –backend inductor –amp –performance –dashboard –only mixnet_l –disable-cudagraphs –training
注意
该工具依赖内核名称来决定其类别。启用
TORCHINDUCTOR_UNIQUE_KERNEL_NAMES对此至关重要。在输出日志中,查找以下行
**Compiled module path: /tmp/torchinductor_shunting/qz/cqz7hvhood7y3psp7fy6msjxsxyli7qiwiybizdwtjw6ffyq5wwd.py**
每个已编译模块对应一行。如果没有额外的图中断,我们将在日志中看到 2 行此类信息,一行对应前向图,一行对应后向图。
对于我们的示例命令,我们分别获得了前向图和后向图的以下已编译模块
https://gist.github.com/shunting314/c2a4d8a28b00fcb5586d0e9d9bf77f9f
https://gist.github.com/shunting314/48efc83b12ec3ead950052e4a0220b10
现在我们可以深入了解每个已编译模块的性能。让我们选择前向图进行说明。为了方便,我将其命名为
fwd.py。使用-p参数直接运行它**> python fwd.py -p**
请在此示例 gist 中查看完整的输出日志。
在输出中,您会注意到以下内容
我们为性能分析写入了一个 Chrome trace 文件,以便我们可以加载 trace 并与之交互。在日志中,查找如下行以找到 trace 文件的路径。
性能分析的 Chrome trace 已写入 /tmp/compiled_module_profile.json
将 trace 加载到 Chrome 中(在 Chrome 浏览器中访问 chrome://tracing 并按照 UI 提示加载文件)将显示如下 UI
您可以放大和缩小以检查性能分析结果。
我们通过如下日志行报告 GPU 时间占 wall time 的百分比
GPU 忙碌时间百分比: 102.88%
有时您可能会看到大于 100% 的值。原因是 PyTorch 在启用性能分析时使用内核执行时间,而在禁用性能分析时使用 wall time。性能分析可能会稍微扭曲内核执行时间。但总的来说,这应该问题不大。
如果我们使用较小的批量大小运行像
densenet121这样的模型,我们会看到 GPU 忙碌时间百分比很低(Forward graph) Percent of time when GPU is busy: 32.69%
这意味着模型有很多 CPU 开销。这与启用 cudagraphs 可大幅提高 densenet121 性能的事实一致。
我们可以将 GPU 时间分解到不同类别的内核。在
mixnet_l示例中,我们看到逐点内核占用 28.58%
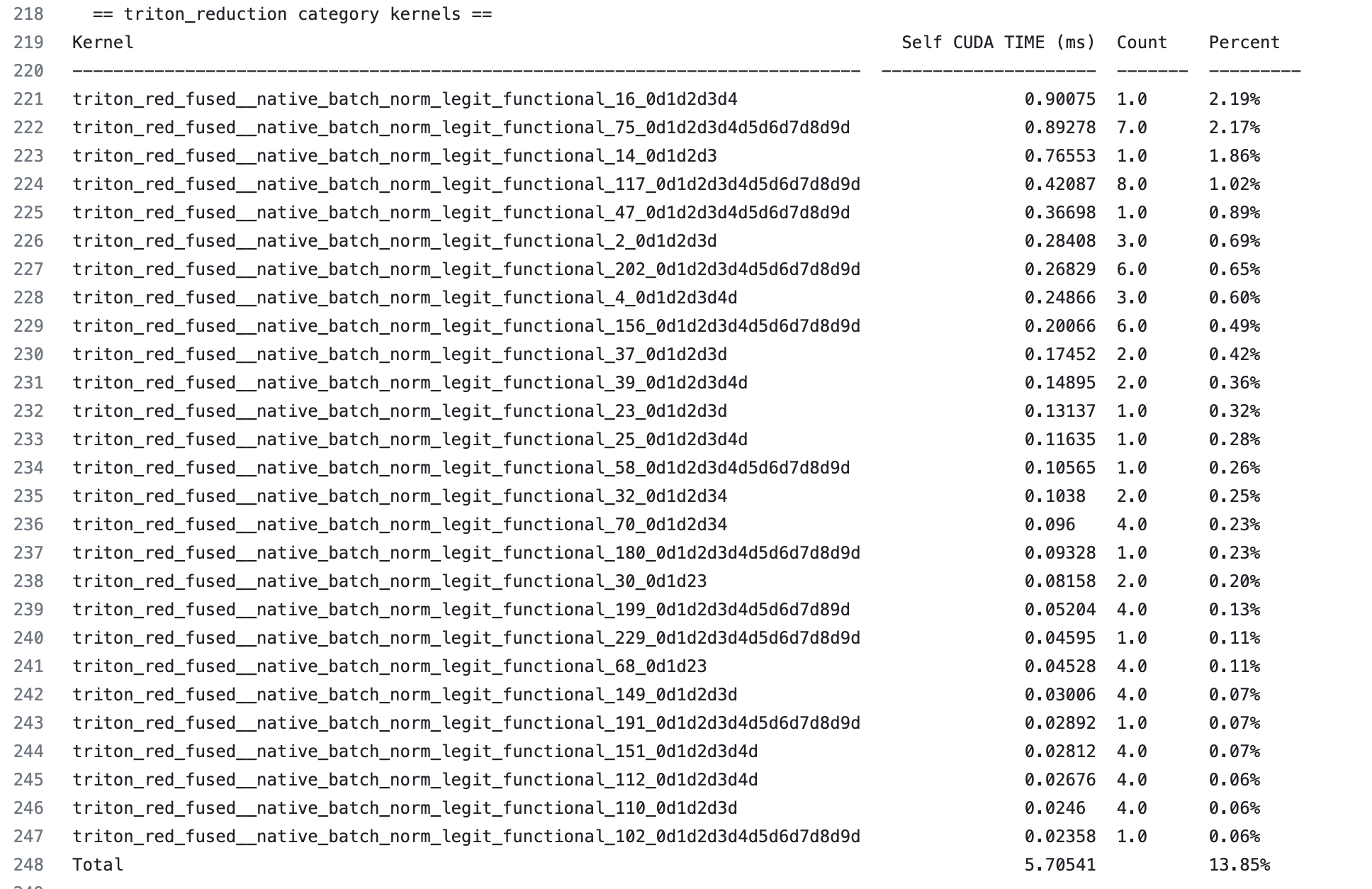
归约内核占用 13.85%
持久归约内核占用 3.89%
其余是用于 mm/conv 的 cutlass/cudnn 内核,占用 56.57%
此信息可在每种内核类别的报告的汇总行(最后一行)中找到。
我们还可以放大查看特定类别的内核。例如,让我们检查归约内核
我们可以看到每个归约内核执行时间的有序表格。我们还可以看到内核执行了多少次。这在以下几个方面很有帮助
如果一个内核只占用极少的时间,例如 0.1%,那么改进它最多只能带来 0.1% 的总体提升。不值得为此投入大量精力。
如果一个内核占用 2% 的时间,将其性能提高一倍将带来 1% 的总体提升,这值得投入精力。
对单个 Triton 内核进行基准测试¶
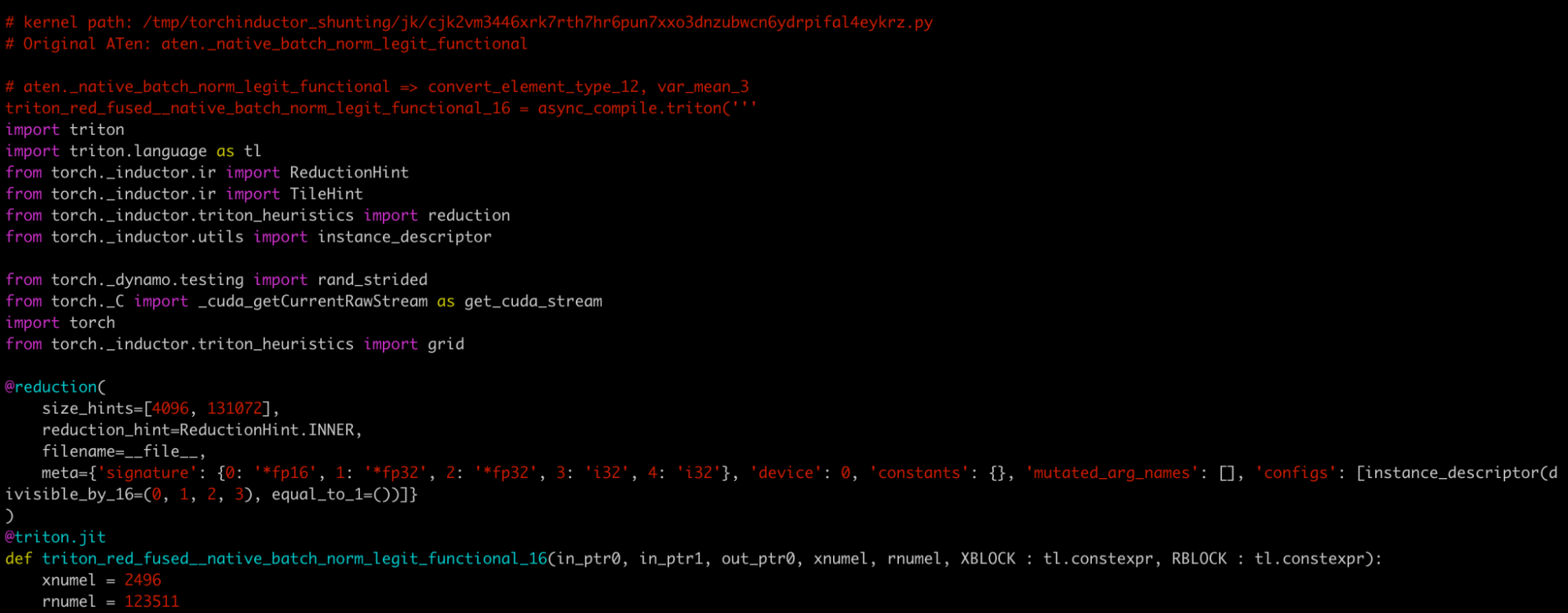
假设我们想仔细查看 triton_red_fused\__native_batch_norm_legit_functional_16,这是最耗时的归约内核,占前向图总 wall time 的 2.19%。
我们可以在 fwd.py 中查找内核名称,并找到类似如下的注释
# kernel path: /tmp/torchinductor_shunting/jk/cjk2vm3446xrk7rth7hr6pun7xxo3dnzubwcn6ydrpifal4eykrz.py

为方便起见,我将其重命名为 k.py。这是一个文件的粘贴内容。
k.py 是一个独立的 Python 模块,包含内核代码及其基准测试。
直接运行 k.py 将报告其执行时间和带宽

我们可以通过运行以下命令检查 max-autotune 是否对该内核有帮助
**TORCHINDUCTOR_MAX_AUTOTUNE=1 python /tmp/k.py**
我们还可以临时添加更多归约启发式方法并再次运行脚本,以检查这对内核有何帮助。
