使用分析工具理解 torch.compile 性能¶
torch.profiler 的用途:¶
torch.profiler 对于理解程序在内核级别的性能很有帮助——例如,它可以显示图中断和资源利用情况。分析器提供的数据通常可以帮助用户理解应该进一步调查哪些方面来了解模型性能。
要理解内核级别的性能,可以使用其他工具,例如 Nvidia Nsight compute tool, AMD Omnitrace, Intel® VTune™ Profiler 或 inductor 的分析工具。
另请参阅 通用的 PyTorch 分析器指南。
使用 torch.profiler 和查看 trace 的基础知识¶
示例程序:我们将使用这个分析 resnet18 的例子。请注意这个示例程序的以下部分:
包含一次热身运行,以等待编译完成(这将预热 CUDA 缓存分配器等系统)。
使用
torch.profiler.profile()上下文来分析我们感兴趣的部分。使用
prof.export_chrome_trace("trace.json")导出分析工件。
import torch
from torchvision.models import resnet18
device = 'cuda' # or 'cpu', 'xpu', etc.
model = resnet18().to(device)
inputs = [torch.randn((5, 3, 224, 224), device=device) for _ in range(10)]
model_c = torch.compile(model)
def fwd_bwd(inp):
out = model_c(inp)
out.sum().backward()
# warm up
fwd_bwd(inputs[0])
with torch.profiler.profile() as prof:
for i in range(1, 4):
fwd_bwd(inputs[i])
prof.step()
prof.export_chrome_trace("trace.json")
查看 chrome trace:在 Chrome 浏览器中,打开 chrome://tracing 并加载 json 文件。使用“w”和“s”键放大和缩小,使用“a”和“d”键左右滚动。“?” 将显示一个包含快捷方式列表的“帮助”屏幕。
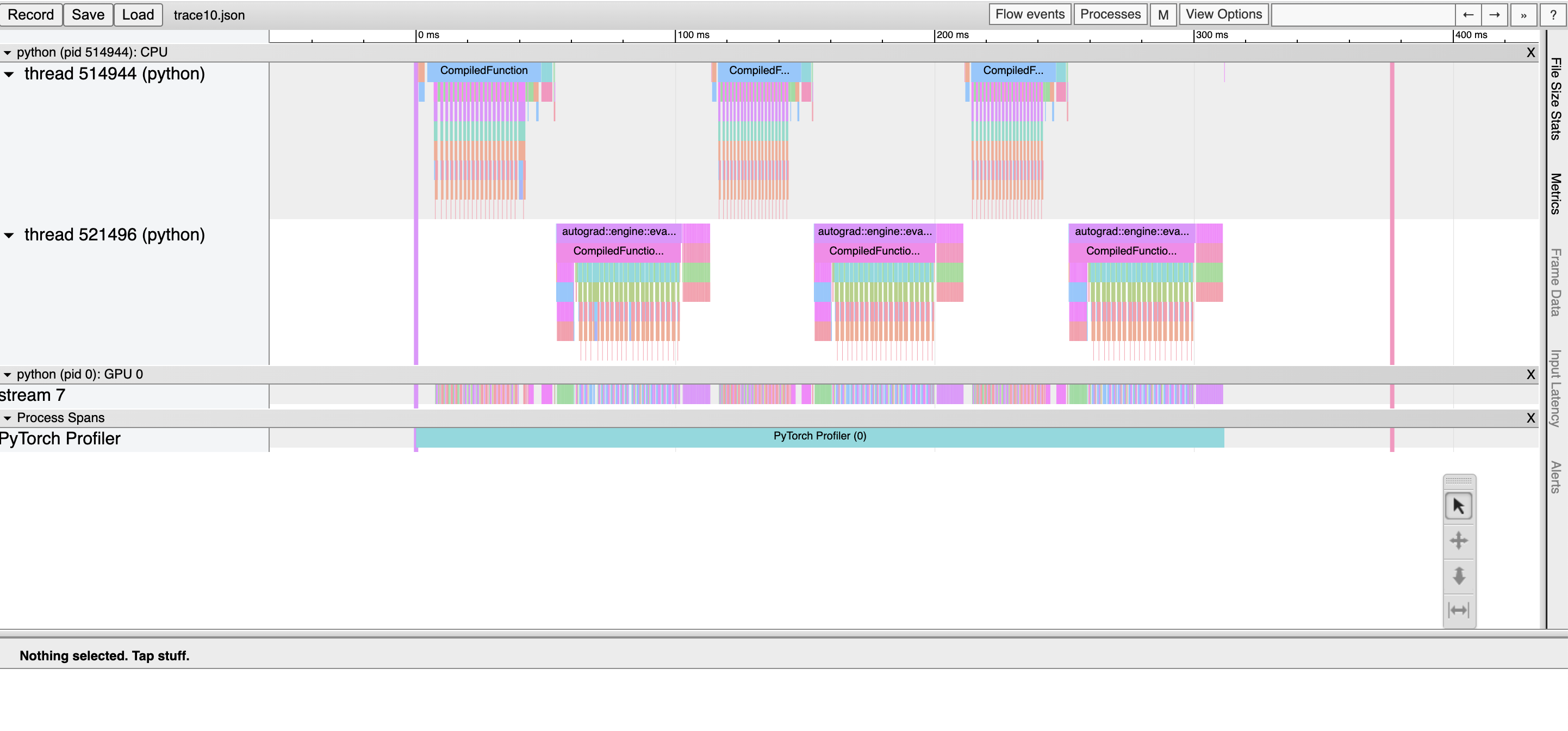
在这里,我们观察到:* CompiledFunction 和 CompiledFunctionBackward 事件,它们对应于 dynamo 编译的区域。* 顶部的 CPU 事件,底部的 GPU 事件。
CPU 和加速器事件之间的流程
加速器上的每个内核都在 CPU 上运行的代码启动后发生。分析器可以在加速器和 CPU 事件之间绘制连接(即“流程”),以显示哪个 CPU 事件启动了加速器内核。这特别有用,因为除了少数例外,加速器内核是异步启动的。
要查看流程连接,请单击 GPU 内核并单击“ac2g”。
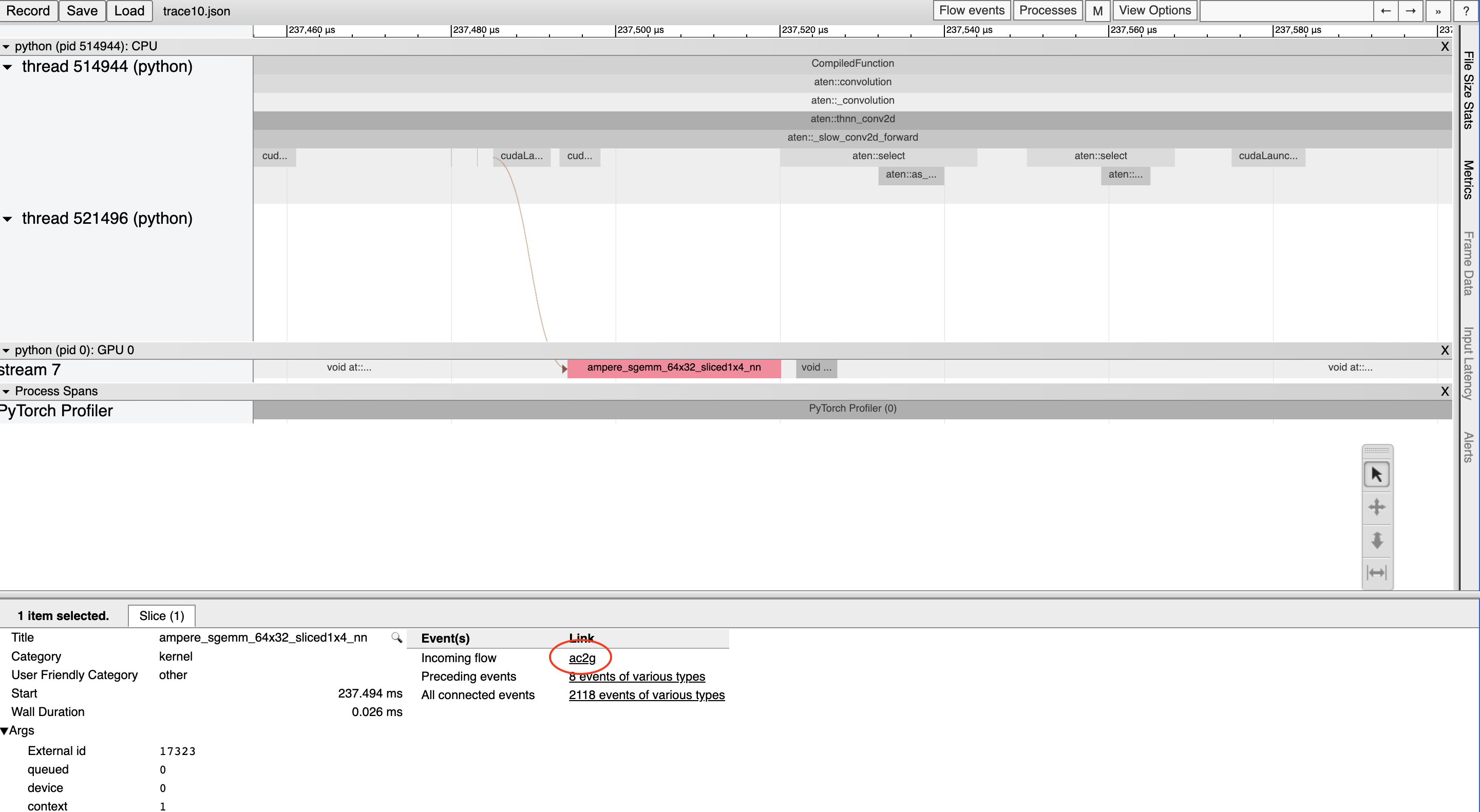
或者,通过顶部的“Flow events”下拉菜单打开 所有 流程。
解决 CUDA Graph 分析问题¶
启用 CUDA 图时,某些 CUDA 配置(驱动版本低于 525.85.12 或 CUDA < 12)可能会遇到分析工具和 CUDA 图之间的问题。要解决这些问题,请在程序顶部添加一个空的分析上下文:
import torch
torch.profiler._utils._init_for_cuda_graphs()
# ... rest of program
理解编译时间¶
要理解为什么编译花费时间很长,您可以分析 torch.compile 程序的第一次调用。请记住,编译的分析 trace 比典型分析更可能失真,因为编译工作负载可能与典型 PyTorch 工作负载大不相同。在某些情况下,trace 文件也可能非常大。大于 1GB 的 trace 很难用 chrome trace 工具打开。
注意:通过 torch._dynamo.utils.compile_times() 也可以获得大致相同的信息,格式非图形化。这个实用工具不会显示编译步骤何时发生,但会显示每个步骤花费的时间——并且时间不会受到任何分析开销的影响。
请参阅下面的示例:
import torch
from torchvision.models import resnet18
# user can switch between cuda and xpu
device = 'cuda'
model = resnet18().to(device)
inputs = [torch.randn((5, 3, 224, 224), device=device) for _ in range(10)]
model_c = torch.compile(model)
def fwd_bwd(inp):
out = model_c(inp)
out.sum().backward()
def warmup_compile():
def fn(x):
return x.sin().relu()
x = torch.rand((2, 2), device=device, requires_grad=True)
fn_c = torch.compile(fn)
out = fn_c(x)
out.sum().backward()
with torch.profiler.profile() as prof:
with torch.profiler.record_function("warmup compile"):
warmup_compile()
with torch.profiler.record_function("resnet18 compile"):
fwd_bwd(inputs[0])
prof.export_chrome_trace("trace_compile.json")
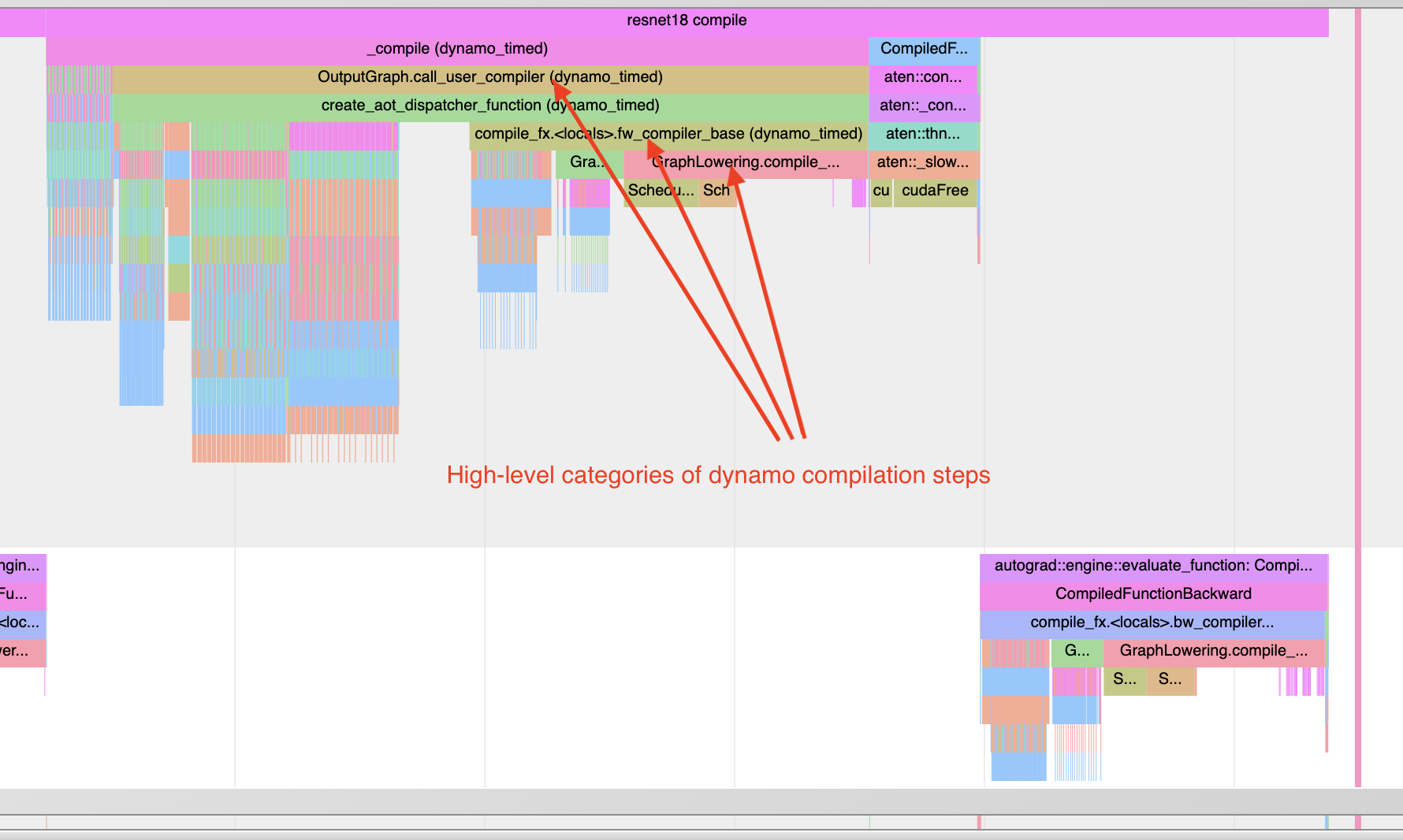
注意几点:
第一次调用应该在分析 期间 发生,以便捕获编译过程。
添加一次热身编译,以便初始化任何需要延迟初始化的系统。
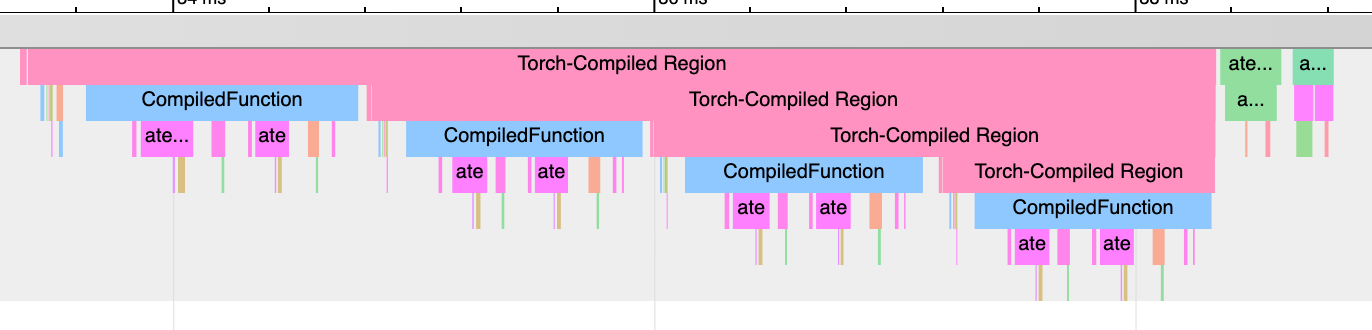
查找图中断:“Torch-Compiled Region” 和 “CompiledFunction”¶
虽然有用于识别图中断的日志记录工具,但分析器提供了一种快速直观的方法来识别图中断。需要查找两个分析器事件:Torch-Compiled Region 和 CompiledFunction。
Torch-Compiled Region - 在 PyTorch 2.2 中引入 - 是一个分析器事件,覆盖整个编译区域。图中断几乎总是看起来一样:嵌套的 “Torch-Compiled Region” 事件。
如果您运行两个单独的函数,并且每个都独立应用了 torch.compile(),通常您应该看到两个相邻的(即不堆叠/嵌套的)Torch-Compiled Region。同时,如果您遇到图中断(或 disable()/skipped 区域),则会看到嵌套的 “Torch-Compiled Region” 事件。
CompiledFunction - 在 PyTorch 2.0 中引入 - 是当任何输入需要梯度时出现的分析器事件。每个图中断都会打断一个 CompiledFunction 块,将其分成两部分。CompiledFunction 事件仅在涉及 Autograd 时出现,即图的一些输入张量 requires_grad=True。
当 CompiledFunction 出现在 trace 中时,通常会与反向传播中的 CompiledFunctionBackward 事件配对。如果调用了反向函数,trace 中应该会出现连接两者的“fwd-bwd 链接”。
如果您的用例包含一个不需要梯度且不包含“Torch-Compiled Region”事件的图,则可能更难以确定是否正确应用了 torch.compile。一个线索可能是存在 Inductor 生成的 Triton 内核。
请参阅下面的合成示例进行演示:
import torch
import torch._dynamo
# user can switch between cuda and xpu
device = 'cuda'
class ModelWithBreaks(torch.nn.Module):
def __init__(self):
super().__init__()
def create_sequential():
return torch.nn.Sequential(
torch.nn.Linear(128, 128),
torch.nn.ReLU(),
torch.nn.Linear(128, 128),
torch.nn.ReLU(),
)
self.mod1 = create_sequential()
self.mod2 = create_sequential()
self.mod3 = create_sequential()
self.mod4 = create_sequential()
def forward(self, inp):
mod1 = self.mod1(inp)
torch._dynamo.graph_break()
mod2 = self.mod2(mod1)
torch._dynamo.graph_break()
mod3 = self.mod3(mod2)
torch._dynamo.graph_break()
mod4 = self.mod4(mod3)
return mod4
model = ModelWithBreaks().to(device)
inputs = [torch.randn((128, 128), device=device) for _ in range(10)]
model_c = torch.compile(model)
def fwd_bwd(inp):
out = model_c(inp)
out.sum().backward()
# warm up
fwd_bwd(inputs[0])
with torch.profiler.profile() as prof:
for i in range(1, 4):
fwd_bwd(inputs[i])
prof.step()
prof.export_chrome_trace("trace_break.json")
算子内核¶
当一个算子启动时,我们期望看到几个事件:
CPU 端事件
内核启动(如果处理 GPU 内核)
GPU 端事件
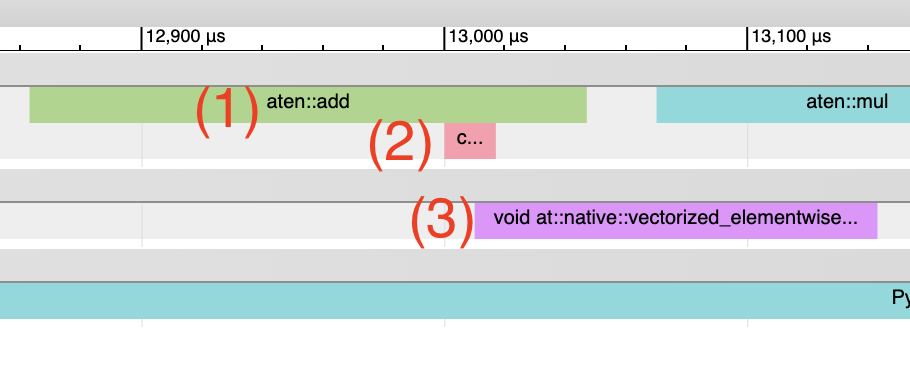
Inductor 生成的 Triton 内核: 1. CPU 端事件应显示为以“triton_”为前缀的事件。目前的事件信息很少——只有内核名称和启动信息,比典型的 aten 内核启动信息少(后者包含输入形状、类型等)。 2. 内核启动应显示为 cuLaunchKernel 而不是 cudaLaunchKernel(cudaLaunchKernel 是 aten 算子的典型启动方式)。 3. GPU 端事件应显示,其名称描述性取决于 inductor config 中的 unique_kernel_names 设置。
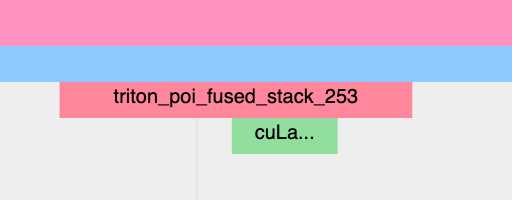
非 Inductor 生成的 Triton 内核
CPU 端事件可能不会出现在 trace 中;自动插入分析器事件的机制目前是在 Inductor 层面实现的,因此绕过 Inductor 的 Triton 内核可能不会出现在 trace 中,除非用户手动进行了标注。
内核启动应显示为 cuLaunchKernel 而不是 cudaLaunchKernel(cudaLaunchKernel 是 aten 算子的典型启动方式)。
GPU 端事件应显示,其命名方式类似于编写的 triton 内核。
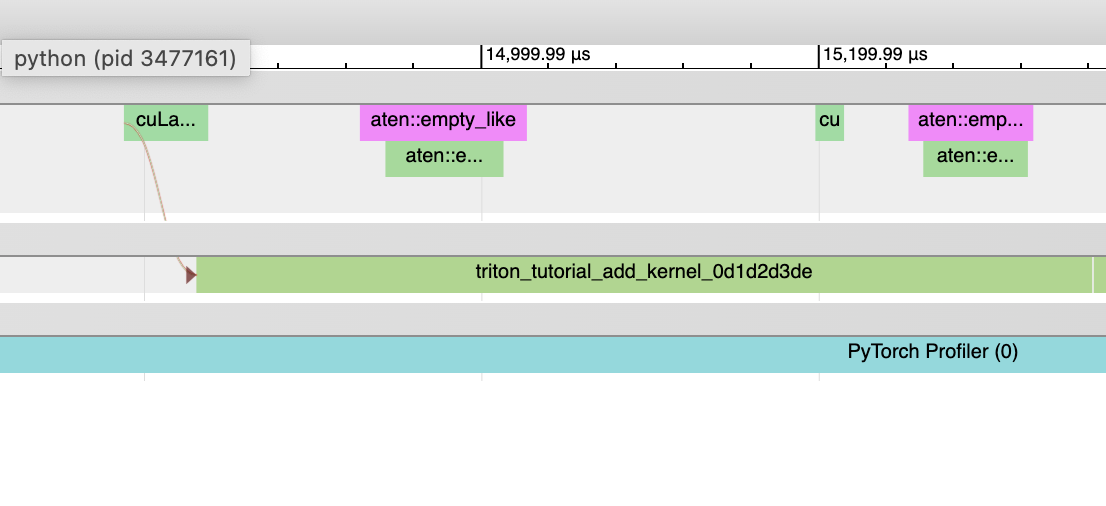
Inductor 生成的 CPU 内核
CPU 端事件将不会出现在 trace 中;我们尚未为此添加分析功能。
内核启动和GPU 端事件不存在。
非 Triton 内核(即 aten 内核或自定义算子)有时也应出现在 trace 中。有时,Inductor 会回退到原始算子实现,在这种情况下,您会看到对 aten 算子的调用。
启动开销¶
一个常见问题是 GPU 利用率不高。快速识别这个问题的方法是观察 GPU 内核之间是否存在较大的间隔。
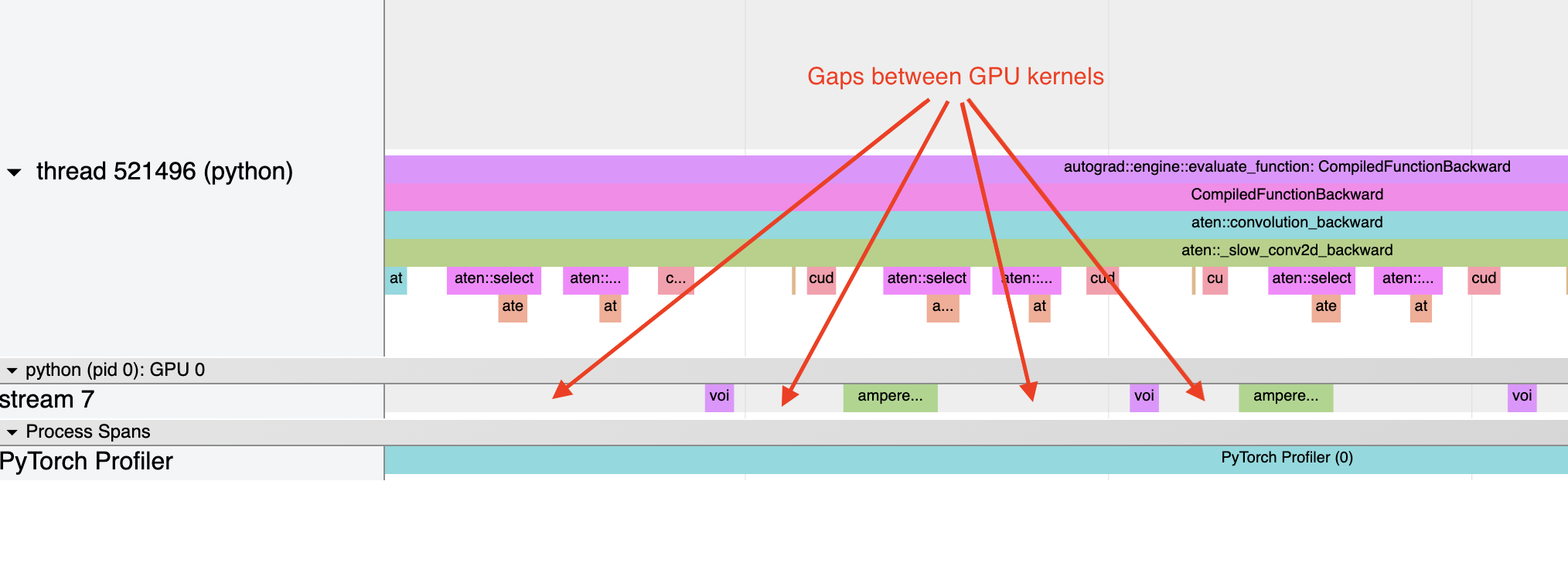
这通常是由于 CPU 开销造成的,例如 CPU 在内核启动之间花费的时间大于 GPU 处理内核的时间。对于小批量大小来说,这个问题更常见。
使用 inductor 时,在启动开销成为问题时,启用 CUDA 图通常有助于提高性能。
