torch.utils.tensorboard¶
在继续之前,可以在 https://tensorflowcn.cn/tensorboard/ 找到更多关于 TensorBoard 的详细信息
安装 TensorBoard 后,这些工具函数允许您将 PyTorch 模型和指标记录到目录中,以便在 TensorBoard UI 中进行可视化。支持 PyTorch 模型和张量以及 Caffe2 网络和 blob 的标量、图像、直方图、图表和嵌入可视化。
SummaryWriter 类是您记录数据供 TensorBoard 消费和可视化的主要入口。例如
import torch
import torchvision
from torch.utils.tensorboard import SummaryWriter
from torchvision import datasets, transforms
# Writer will output to ./runs/ directory by default
writer = SummaryWriter()
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (0.5,))])
trainset = datasets.MNIST('mnist_train', train=True, download=True, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True)
model = torchvision.models.resnet50(False)
# Have ResNet model take in grayscale rather than RGB
model.conv1 = torch.nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3, bias=False)
images, labels = next(iter(trainloader))
grid = torchvision.utils.make_grid(images)
writer.add_image('images', grid, 0)
writer.add_graph(model, images)
writer.close()
然后可以使用 TensorBoard 对其进行可视化,TensorBoard 可以通过以下方式安装和运行
pip install tensorboard
tensorboard --logdir=runs
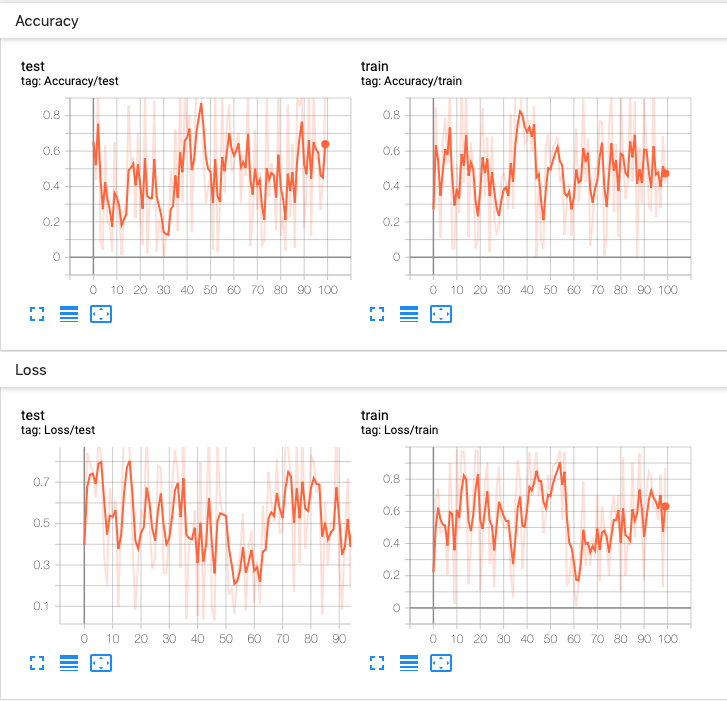
一个实验可以记录很多信息。为了避免 UI 混乱并更好地对结果进行聚类,我们可以通过分层命名来对图表进行分组。例如,“Loss/train” 和 “Loss/test” 将被分在一组,而 “Accuracy/train” 和 “Accuracy/test” 将在 TensorBoard 界面中单独分组。
from torch.utils.tensorboard import SummaryWriter
import numpy as np
writer = SummaryWriter()
for n_iter in range(100):
writer.add_scalar('Loss/train', np.random.random(), n_iter)
writer.add_scalar('Loss/test', np.random.random(), n_iter)
writer.add_scalar('Accuracy/train', np.random.random(), n_iter)
writer.add_scalar('Accuracy/test', np.random.random(), n_iter)
预期结果
- class torch.utils.tensorboard.writer.SummaryWriter(log_dir=None, comment='', purge_step=None, max_queue=10, flush_secs=120, filename_suffix='')[source][source]¶
将条目直接写入 log_dir 中的事件文件,供 TensorBoard 消费。
SummaryWriter 类提供了一个高级 API,用于在给定目录中创建事件文件并向其中添加摘要和事件。该类异步更新文件内容。这使得训练程序可以直接从训练循环中调用方法向文件添加数据,而不会减慢训练速度。
- __init__(log_dir=None, comment='', purge_step=None, max_queue=10, flush_secs=120, filename_suffix='')[source][source]¶
创建一个 SummaryWriter,它将事件和摘要写入事件文件。
- 参数
log_dir (str) – 保存目录位置。默认值为 runs/CURRENT_DATETIME_HOSTNAME,每次运行时都会更改。使用分层文件夹结构可以轻松比较不同运行。例如,对于每个新实验,传入 ‘runs/exp1’、‘runs/exp2’ 等以进行比较。
comment (str) – 注释 log_dir 后缀,附加到默认的
log_dir。如果log_dir已指定,此参数无效。purge_step (int) – 当日志记录在步骤 崩溃并在步骤 重启时,任何 global_step 大于或等于 的事件都将被清除并隐藏在 TensorBoard 中。请注意,崩溃后恢复的实验应具有相同的
log_dir。max_queue (int) – 待处理事件和摘要的队列大小,在某个 'add' 调用强制刷新到磁盘之前。默认是十项。
flush_secs (int) – 将待处理事件和摘要刷新到磁盘的频率,以秒为单位。默认是每两分钟。
filename_suffix (str) – 添加到 log_dir 目录中所有事件文件名中的后缀。更多文件名构建细节参见 tensorboard.summary.writer.event_file_writer.EventFileWriter。
示例
from torch.utils.tensorboard import SummaryWriter # create a summary writer with automatically generated folder name. writer = SummaryWriter() # folder location: runs/May04_22-14-54_s-MacBook-Pro.local/ # create a summary writer using the specified folder name. writer = SummaryWriter("my_experiment") # folder location: my_experiment # create a summary writer with comment appended. writer = SummaryWriter(comment="LR_0.1_BATCH_16") # folder location: runs/May04_22-14-54_s-MacBook-Pro.localLR_0.1_BATCH_16/
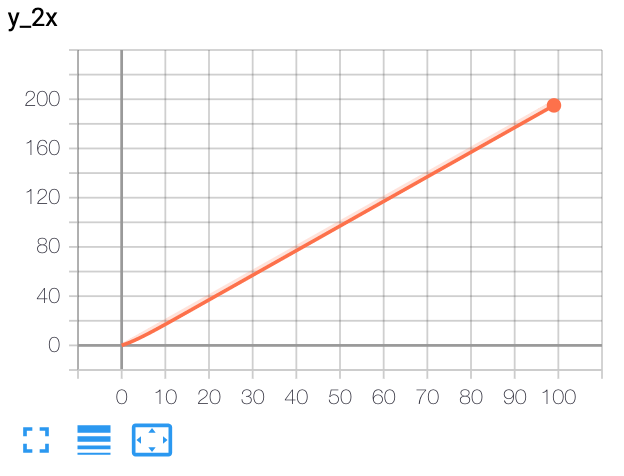
- add_scalar(tag, scalar_value, global_step=None, walltime=None, new_style=False, double_precision=False)[source][source]¶
向摘要添加标量数据。
- 参数
示例
from torch.utils.tensorboard import SummaryWriter writer = SummaryWriter() x = range(100) for i in x: writer.add_scalar('y=2x', i * 2, i) writer.close()
预期结果
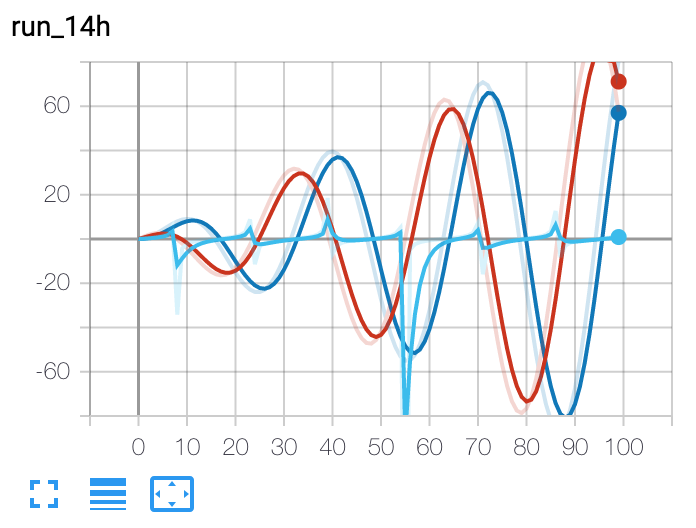
- add_scalars(main_tag, tag_scalar_dict, global_step=None, walltime=None)[source][source]¶
向摘要添加多个标量数据。
- 参数
示例
from torch.utils.tensorboard import SummaryWriter writer = SummaryWriter() r = 5 for i in range(100): writer.add_scalars('run_14h', {'xsinx':i*np.sin(i/r), 'xcosx':i*np.cos(i/r), 'tanx': np.tan(i/r)}, i) writer.close() # This call adds three values to the same scalar plot with the tag # 'run_14h' in TensorBoard's scalar section.
预期结果
- add_histogram(tag, values, global_step=None, bins='tensorflow', walltime=None, max_bins=None)[source][source]¶
向摘要添加直方图。
- 参数
tag (str) – 数据标识符
values (torch.Tensor, numpy.ndarray, 或 string/blobname) – 构建直方图的值
global_step (int) – 要记录的全局步骤值
bins (str) – {‘tensorflow’,’auto’, ‘fd’, …} 之一。这决定了如何创建 bin。您可以在以下链接中找到其他选项:https://docs.scipy.org.cn/doc/numpy/reference/generated/numpy.histogram.html
walltime (float) – 可选地覆盖默认 walltime (time.time()),使用事件的 epoch 后秒数
示例
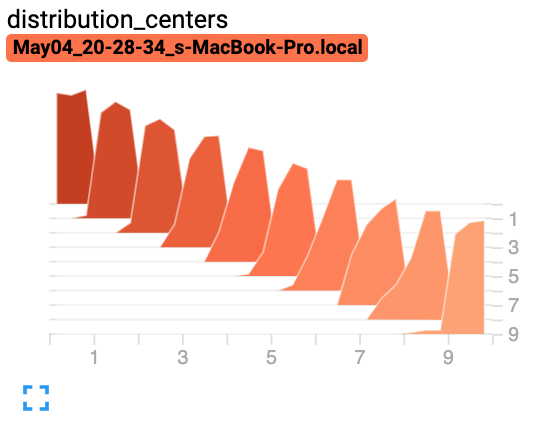
from torch.utils.tensorboard import SummaryWriter import numpy as np writer = SummaryWriter() for i in range(10): x = np.random.random(1000) writer.add_histogram('distribution centers', x + i, i) writer.close()
预期结果
- add_image(tag, img_tensor, global_step=None, walltime=None, dataformats='CHW')[source][source]¶
向摘要添加图像数据。
请注意,这需要安装
pillow包。- 参数
tag (str) – 数据标识符
img_tensor (torch.Tensor, numpy.ndarray, 或 string/blobname) – 图像数据
global_step (int) – 要记录的全局步骤值
walltime (float) – 可选地覆盖默认 walltime (time.time()),使用事件的 epoch 后秒数
dataformats (str) – 图像数据格式规范,形式为 CHW、HWC、HW、WH 等。
- 形状
img_tensor: 默认形状是 。您可以使用
torchvision.utils.make_grid()将批张量转换为 3xHxW 格式,或调用add_images并让我们来处理。形状为 、、 的张量也适用,只要传递相应的dataformats参数即可,例如CHW、HWC、HW。
示例
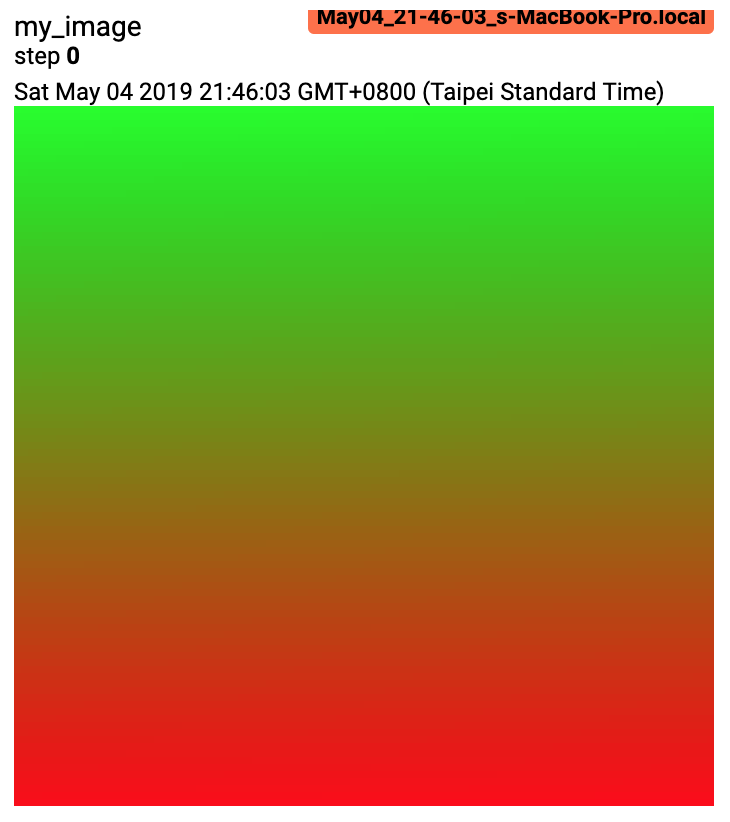
from torch.utils.tensorboard import SummaryWriter import numpy as np img = np.zeros((3, 100, 100)) img[0] = np.arange(0, 10000).reshape(100, 100) / 10000 img[1] = 1 - np.arange(0, 10000).reshape(100, 100) / 10000 img_HWC = np.zeros((100, 100, 3)) img_HWC[:, :, 0] = np.arange(0, 10000).reshape(100, 100) / 10000 img_HWC[:, :, 1] = 1 - np.arange(0, 10000).reshape(100, 100) / 10000 writer = SummaryWriter() writer.add_image('my_image', img, 0) # If you have non-default dimension setting, set the dataformats argument. writer.add_image('my_image_HWC', img_HWC, 0, dataformats='HWC') writer.close()
预期结果
- add_images(tag, img_tensor, global_step=None, walltime=None, dataformats='NCHW')[source][source]¶
向摘要添加批图像数据。
请注意,这需要安装
pillow包。- 参数
tag (str) – 数据标识符
img_tensor (torch.Tensor, numpy.ndarray, 或 string/blobname) – 图像数据
global_step (int) – 要记录的全局步骤值
walltime (float) – 可选地覆盖默认 walltime (time.time()),使用事件的 epoch 后秒数
dataformats (str) – 图像数据格式规范,形式为 NCHW、NHWC、CHW、HWC、HW、WH 等。
- 形状
img_tensor: 默认形状是 。如果指定了
dataformats,其他形状也将被接受。例如 NCHW 或 NHWC。
示例
from torch.utils.tensorboard import SummaryWriter import numpy as np img_batch = np.zeros((16, 3, 100, 100)) for i in range(16): img_batch[i, 0] = np.arange(0, 10000).reshape(100, 100) / 10000 / 16 * i img_batch[i, 1] = (1 - np.arange(0, 10000).reshape(100, 100) / 10000) / 16 * i writer = SummaryWriter() writer.add_images('my_image_batch', img_batch, 0) writer.close()
预期结果

- add_figure(tag, figure, global_step=None, close=True, walltime=None)[source][source]¶
将 matplotlib 图形渲染为图像并将其添加到摘要中。
请注意,这需要安装
matplotlib包。
- add_video(tag, vid_tensor, global_step=None, fps=4, walltime=None)[source][source]¶
向摘要添加视频数据。
请注意,这需要安装
moviepy包。- 参数
- 形状
vid_tensor: 。对于 uint8 类型,值应在 [0, 255] 范围内;对于 float 类型,值应在 [0, 1] 范围内。
- add_audio(tag, snd_tensor, global_step=None, sample_rate=44100, walltime=None)[source][source]¶
将音频数据添加到摘要。
- 参数
tag (str) – 数据标识符
snd_tensor (torch.Tensor) – 声音数据
global_step (int) – 要记录的全局步骤值
sample_rate (int) – 采样率,单位为 Hz
walltime (float) – 可选地覆盖默认 walltime (time.time()),使用事件的 epoch 后秒数
- 形状
snd_tensor: 。值应介于 [-1, 1] 之间。
- add_text(tag, text_string, global_step=None, walltime=None)[source][source]¶
将文本数据添加到摘要。
- 参数
示例
writer.add_text('lstm', 'This is an lstm', 0) writer.add_text('rnn', 'This is an rnn', 10)
- add_graph(model, input_to_model=None, verbose=False, use_strict_trace=True)[source][source]¶
将图数据添加到摘要。
- 参数
model (torch.nn.Module) – 要绘制的模型。
input_to_model (torch.Tensor or list of torch.Tensor) – 要输入的一个变量或一个变量元组。
verbose (bool) – 是否在控制台中打印图结构。
use_strict_trace (bool) – 是否将关键字参数 strict 传递给 torch.jit.trace。如果你希望追踪器记录你的可变容器类型(列表、字典),则传递 False
- add_embedding(mat, metadata=None, label_img=None, global_step=None, tag='default', metadata_header=None)[source][source]¶
将嵌入投影仪数据添加到摘要。
- 参数
mat (torch.Tensor or numpy.ndarray) – 一个矩阵,其每一行是数据点的特征向量
metadata (list) – 一个标签列表,每个元素将被转换为字符串
label_img (torch.Tensor) – 对应每个数据点的图像
global_step (int) – 要记录的全局步骤值
tag (str) – 嵌入的名称
metadata_header (list) – 多列元数据的标题列表。如果给定,每个元数据必须是一个列表,其中包含与标题对应的值。
- 形状
mat: ,其中 N 是数据点数量,D 是特征维度
label_img:
示例
import keyword import torch meta = [] while len(meta)<100: meta = meta+keyword.kwlist # get some strings meta = meta[:100] for i, v in enumerate(meta): meta[i] = v+str(i) label_img = torch.rand(100, 3, 10, 32) for i in range(100): label_img[i]*=i/100.0 writer.add_embedding(torch.randn(100, 5), metadata=meta, label_img=label_img) writer.add_embedding(torch.randn(100, 5), label_img=label_img) writer.add_embedding(torch.randn(100, 5), metadata=meta)
注意
分类(即非数字)元数据如果用于嵌入投影仪中的着色,则唯一值不能超过 50 个。
- add_pr_curve(tag, labels, predictions, global_step=None, num_thresholds=127, weights=None, walltime=None)[source][source]¶
添加精确率-召回率曲线。
绘制精确率-召回率曲线可以帮助您了解模型在不同阈值设置下的性能。使用此函数,您可以为每个目标提供真实标签(真/假)和预测置信度(通常是模型的输出)。TensorBoard UI 将允许您交互式地选择阈值。
- 参数
tag (str) – 数据标识符
labels (torch.Tensor, numpy.ndarray, or string/blobname) – 真实数据。每个元素的二元标签。
predictions (torch.Tensor, numpy.ndarray, or string/blobname) – 元素被归类为真的概率。值应在 [0, 1] 之间。
global_step (int) – 要记录的全局步骤值
num_thresholds (int) – 用于绘制曲线的阈值数量。
walltime (float) – 可选地覆盖默认 walltime (time.time()),使用事件的 epoch 后秒数
示例
from torch.utils.tensorboard import SummaryWriter import numpy as np labels = np.random.randint(2, size=100) # binary label predictions = np.random.rand(100) writer = SummaryWriter() writer.add_pr_curve('pr_curve', labels, predictions, 0) writer.close()
- add_custom_scalars(layout)[source][source]¶
通过收集“标量”中的图表标签来创建特殊图表。
注意:此函数对于每个 SummaryWriter() 对象只能调用一次。
由于此函数只向 TensorBoard 提供元数据,因此可以在训练循环之前或之后调用。
- 参数
layout (dict) – {类别名称: 图表集},其中图表集也是一个字典 {图表名称: 属性列表}。属性列表中的第一个元素是图表类型(可以是 Multiline 或 Margin),第二个元素应是一个列表,包含您在 add_scalar 函数中使用的标签,这些标签将被收集到新图表中。
示例
layout = {'Taiwan':{'twse':['Multiline',['twse/0050', 'twse/2330']]}, 'USA':{ 'dow':['Margin', ['dow/aaa', 'dow/bbb', 'dow/ccc']], 'nasdaq':['Margin', ['nasdaq/aaa', 'nasdaq/bbb', 'nasdaq/ccc']]}} writer.add_custom_scalars(layout)
- add_mesh(tag, vertices, colors=None, faces=None, config_dict=None, global_step=None, walltime=None)[source][source]¶
将网格或 3D 点云添加到 TensorBoard。
可视化基于 Three.js,因此允许用户与渲染的对象进行交互。除了顶点、面等基本定义外,用户还可以提供相机参数、光照条件等。请查看 https://threejs.org/docs/index.html#manual/en/introduction/Creating-a-scene 获取高级用法。
- 参数
tag (str) – 数据标识符
vertices (torch.Tensor) – 顶点的 3D 坐标列表。
colors (torch.Tensor) – 每个顶点的颜色
faces (torch.Tensor) – 每个三角形内顶点的索引。(可选)
config_dict – 包含 ThreeJS 类名和配置的字典。
global_step (int) – 要记录的全局步骤值
walltime (float) – 可选地覆盖默认 walltime (time.time()),使用事件的 epoch 后秒数
- 形状
vertices: 。(批次大小,顶点数量,通道)
colors: 。对于 uint8 类型,值应在 [0, 255] 之间;对于 float 类型,值应在 [0, 1] 之间。
faces: 。对于 uint8 类型,值应在 [0, number_of_vertices] 之间。
示例
from torch.utils.tensorboard import SummaryWriter vertices_tensor = torch.as_tensor([ [1, 1, 1], [-1, -1, 1], [1, -1, -1], [-1, 1, -1], ], dtype=torch.float).unsqueeze(0) colors_tensor = torch.as_tensor([ [255, 0, 0], [0, 255, 0], [0, 0, 255], [255, 0, 255], ], dtype=torch.int).unsqueeze(0) faces_tensor = torch.as_tensor([ [0, 2, 3], [0, 3, 1], [0, 1, 2], [1, 3, 2], ], dtype=torch.int).unsqueeze(0) writer = SummaryWriter() writer.add_mesh('my_mesh', vertices=vertices_tensor, colors=colors_tensor, faces=faces_tensor) writer.close()
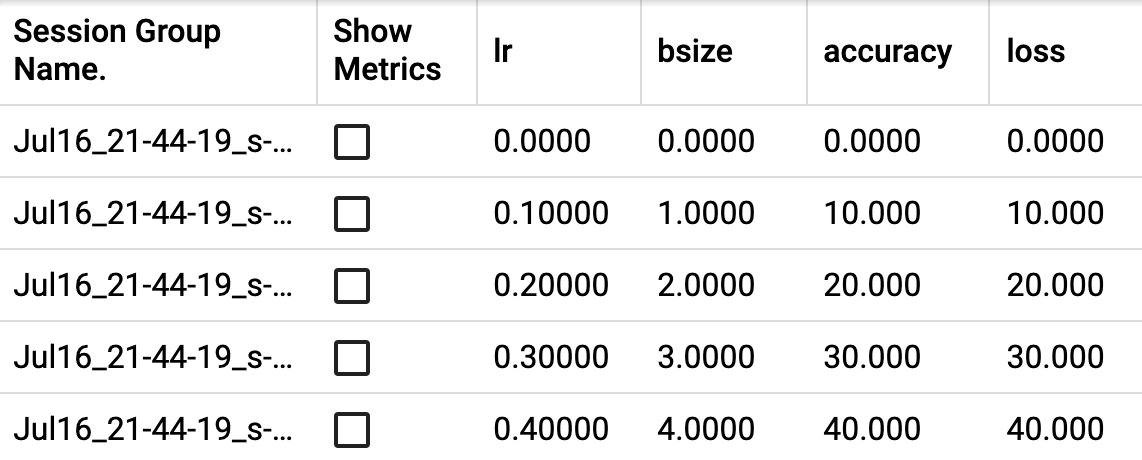
- add_hparams(hparam_dict, metric_dict, hparam_domain_discrete=None, run_name=None, global_step=None)[source][source]¶
将一组超参数添加到 TensorBoard 中进行比较。
- 参数
hparam_dict (dict) – 字典中的每个键值对是超参数的名称及其对应的值。值的类型可以是 bool、string、float、int 或 None 之一。
metric_dict (dict) – 字典中的每个键值对是度量的名称及其对应的值。请注意,此处使用的键在 TensorBoard 记录中应是唯一的。否则,您通过
add_scalar添加的值将显示在 hparam 插件中。在大多数情况下,这是不希望的。hparam_domain_discrete – (Optional[Dict[str, List[Any]]]) 一个字典,包含超参数的名称及其可以持有的所有离散值
run_name (str) – 运行的名称,将包含在 logdir 中。如果未指定,将使用当前时间戳。
global_step (int) – 要记录的全局步骤值
示例
from torch.utils.tensorboard import SummaryWriter with SummaryWriter() as w: for i in range(5): w.add_hparams({'lr': 0.1*i, 'bsize': i}, {'hparam/accuracy': 10*i, 'hparam/loss': 10*i})
预期结果