量化¶
警告
量化功能目前处于 Beta 阶段,可能会发生变化。
量化简介¶
量化指的是用于以低于浮点精度的位宽执行计算和存储张量的技术。量化模型对张量执行部分或全部操作时,使用较低精度而不是全精度(浮点)值。这使得模型表示更紧凑,并在许多硬件平台上可以使用高性能向量化操作。与典型的 FP32 模型相比,PyTorch 支持 INT8 量化,可将模型大小减少 4 倍,内存带宽需求减少 4 倍。硬件对 INT8 计算的支持通常比 FP32 计算快 2 到 4 倍。量化主要是为了加速推理,并且量化运算符仅支持前向传播。
PyTorch 支持多种对深度学习模型进行量化的方法。在大多数情况下,模型在 FP32 中训练,然后转换为 INT8。此外,PyTorch 还支持量化感知训练 (quantization aware training),它使用伪量化模块对前向和后向传播中的量化误差进行建模。请注意,整个计算都在浮点数中进行。量化感知训练结束后,PyTorch 提供转换函数将训练好的模型转换为较低精度。
在较低级别,PyTorch 提供了一种表示量化张量并对其进行操作的方式。它们可以直接用于构建在较低精度下执行全部或部分计算的模型。更高层次的 API 则提供典型的工作流程,以最小的精度损失将 FP32 模型转换为较低精度。
量化 API 概述¶
PyTorch 提供三种不同的量化模式:Eager 模式量化、FX 图模式量化(维护中)和 PyTorch 2 Export 量化。
Eager 模式量化是 Beta 功能。用户需要手动进行融合并指定量化和反量化发生的位置,并且它只支持模块而不支持函数式操作 (functionals)。
FX 图模式量化是 PyTorch 中的自动化量化工作流程,目前是原型功能,并且由于有了 PyTorch 2 Export 量化而处于维护模式。它通过增加对函数式操作的支持和自动化量化过程来改进 Eager 模式量化,尽管用户可能需要重构模型以使其与 FX 图模式量化兼容(即可使用 torch.fx 进行符号跟踪)。请注意,FX 图模式量化预计不适用于任意模型,因为模型可能无法进行符号跟踪。我们将其集成到 torchvision 等领域库中,用户将能够使用 FX 图模式量化对支持的领域库中的模型进行量化。对于任意模型,我们将提供通用指南,但要实际使其工作,用户可能需要熟悉 torch.fx,特别是如何使模型可符号跟踪。
PyTorch 2 Export 量化是新的完整图模式量化工作流程,在 PyTorch 2.1 中作为原型功能发布。随着 PyTorch 2 的推出,我们正在转向一个更好的完整程序捕获解决方案 (torch.export),因为它比 FX 图模式量化使用的程序捕获解决方案 torch.fx.symbolic_trace(在 14K 模型上为 72.7%)能捕获更高比例的模型(在 14K 模型上为 88.8%)。torch.export 在某些 Python 构造方面仍然存在限制,并且需要用户参与以支持导出模型中的动态性,但总的来说,它是对先前程序捕获解决方案的改进。PyTorch 2 Export 量化是为 torch.export 捕获的模型而构建的,同时考虑了建模用户和后端开发人员的灵活性和生产力。主要特点是 (1). 可编程 API,用于配置模型量化方式,可扩展到更多用例 (2). 简化的用户体验,建模用户和后端开发人员只需与单个对象 (Quantizer) 交互,即可表达用户关于如何量化模型以及后端支持哪些功能。 (3). 可选的参考量化模型表示,可以使用整数操作表示量化计算,更接近实际硬件中发生的量化计算。
鼓励量化新用户首先尝试 PyTorch 2 Export 量化,如果效果不佳,可以尝试 eager 模式量化。
下表比较了 Eager 模式量化、FX 图模式量化和 PyTorch 2 Export 量化之间的差异
Eager 模式量化 |
FX 图模式量化 |
PyTorch 2 Export 量化 |
|
发布状态 |
Beta |
原型 (维护中) |
原型 |
运算符融合 |
手动 |
自动 |
自动 |
量化/反量化放置 |
手动 |
自动 |
自动 |
量化模块 |
支持 |
支持 |
支持 |
量化函数式操作/Torch 运算符 |
手动 |
自动 |
支持 |
支持自定义 |
有限支持 |
完全支持 |
完全支持 |
量化模式支持 |
训练后量化:静态、动态、仅权重 量化感知训练:静态 |
训练后量化:静态、动态、仅权重 量化感知训练:静态 |
由后端特定的 Quantizer 定义 |
输入/输出模型类型 |
|
|
|
支持三种类型的量化
动态量化(权重被量化,而激活值以浮点形式读取/存储,并在计算时进行量化)
静态量化(权重被量化,激活值被量化,训练后需要校准)
静态量化感知训练(权重被量化,激活值被量化,量化数值在训练期间建模)
请参阅我们的 PyTorch 量化简介 博客文章,以更全面地了解这些量化类型之间的权衡。
运算符支持范围在动态量化和静态量化之间有所不同,如下表所示。
静态量化 |
动态量化 |
|
nn.Linear
nn.Conv1d/2d/3d
|
是
是
|
是
否
|
nn.LSTM
nn.GRU
|
是(通过
自定义模块)
否
|
是
是
|
nn.RNNCell
nn.GRUCell
nn.LSTMCell
|
否
否
否
|
是
是
是
|
nn.EmbeddingBag |
是(激活值为 fp32) |
是 |
nn.Embedding |
是 |
是 |
nn.MultiheadAttention |
是(通过自定义模块) |
不支持 |
激活值 |
广泛支持 |
未改变,计算仍为 fp32 |
Eager 模式量化¶
关于量化流程的总体介绍,包括不同类型的量化,请参阅量化总体流程。
训练后动态量化¶
这是最简单的量化应用形式,其中权重预先量化,而激活值在推理期间动态量化。这适用于模型执行时间主要由从内存加载权重而非计算矩阵乘法主导的情况。对于批量大小较小的 LSTM 和 Transformer 类型模型而言,情况正是如此。
图示
# original model
# all tensors and computations are in floating point
previous_layer_fp32 -- linear_fp32 -- activation_fp32 -- next_layer_fp32
/
linear_weight_fp32
# dynamically quantized model
# linear and LSTM weights are in int8
previous_layer_fp32 -- linear_int8_w_fp32_inp -- activation_fp32 -- next_layer_fp32
/
linear_weight_int8
PTDQ API 示例
import torch
# define a floating point model
class M(torch.nn.Module):
def __init__(self):
super().__init__()
self.fc = torch.nn.Linear(4, 4)
def forward(self, x):
x = self.fc(x)
return x
# create a model instance
model_fp32 = M()
# create a quantized model instance
model_int8 = torch.ao.quantization.quantize_dynamic(
model_fp32, # the original model
{torch.nn.Linear}, # a set of layers to dynamically quantize
dtype=torch.qint8) # the target dtype for quantized weights
# run the model
input_fp32 = torch.randn(4, 4, 4, 4)
res = model_int8(input_fp32)
要了解更多关于动态量化的信息,请参阅我们的动态量化教程。
训练后静态量化¶
训练后静态量化(PTQ 静态)量化模型的权重和激活值。它在可能的情况下将激活值融合到前一层。它需要使用代表性数据集进行校准,以确定激活值的最佳量化参数。训练后静态量化通常用于内存带宽和计算节省都很重要的情况,CNN 是典型的用例。
在应用训练后静态量化之前,我们可能需要修改模型。请参阅Eager 模式静态量化模型准备。
图示
# original model
# all tensors and computations are in floating point
previous_layer_fp32 -- linear_fp32 -- activation_fp32 -- next_layer_fp32
/
linear_weight_fp32
# statically quantized model
# weights and activations are in int8
previous_layer_int8 -- linear_with_activation_int8 -- next_layer_int8
/
linear_weight_int8
PTSQ API 示例
import torch
# define a floating point model where some layers could be statically quantized
class M(torch.nn.Module):
def __init__(self):
super().__init__()
# QuantStub converts tensors from floating point to quantized
self.quant = torch.ao.quantization.QuantStub()
self.conv = torch.nn.Conv2d(1, 1, 1)
self.relu = torch.nn.ReLU()
# DeQuantStub converts tensors from quantized to floating point
self.dequant = torch.ao.quantization.DeQuantStub()
def forward(self, x):
# manually specify where tensors will be converted from floating
# point to quantized in the quantized model
x = self.quant(x)
x = self.conv(x)
x = self.relu(x)
# manually specify where tensors will be converted from quantized
# to floating point in the quantized model
x = self.dequant(x)
return x
# create a model instance
model_fp32 = M()
# model must be set to eval mode for static quantization logic to work
model_fp32.eval()
# attach a global qconfig, which contains information about what kind
# of observers to attach. Use 'x86' for server inference and 'qnnpack'
# for mobile inference. Other quantization configurations such as selecting
# symmetric or asymmetric quantization and MinMax or L2Norm calibration techniques
# can be specified here.
# Note: the old 'fbgemm' is still available but 'x86' is the recommended default
# for server inference.
# model_fp32.qconfig = torch.ao.quantization.get_default_qconfig('fbgemm')
model_fp32.qconfig = torch.ao.quantization.get_default_qconfig('x86')
# Fuse the activations to preceding layers, where applicable.
# This needs to be done manually depending on the model architecture.
# Common fusions include `conv + relu` and `conv + batchnorm + relu`
model_fp32_fused = torch.ao.quantization.fuse_modules(model_fp32, [['conv', 'relu']])
# Prepare the model for static quantization. This inserts observers in
# the model that will observe activation tensors during calibration.
model_fp32_prepared = torch.ao.quantization.prepare(model_fp32_fused)
# calibrate the prepared model to determine quantization parameters for activations
# in a real world setting, the calibration would be done with a representative dataset
input_fp32 = torch.randn(4, 1, 4, 4)
model_fp32_prepared(input_fp32)
# Convert the observed model to a quantized model. This does several things:
# quantizes the weights, computes and stores the scale and bias value to be
# used with each activation tensor, and replaces key operators with quantized
# implementations.
model_int8 = torch.ao.quantization.convert(model_fp32_prepared)
# run the model, relevant calculations will happen in int8
res = model_int8(input_fp32)
要了解更多关于静态量化的信息,请参阅静态量化教程。
静态量化的量化感知训练¶
量化感知训练(QAT)在训练期间对量化效果进行建模,与其它量化方法相比可以获得更高的精度。我们可以对静态、动态或仅权重量化进行 QAT。在训练期间,所有计算都在浮点数中完成,使用 fake_quant 模块通过钳位和四舍五入来模拟 INT8 的效果,从而模拟量化效果。模型转换后,权重和激活值被量化,并在可能的情况下将激活值融合到前一层。它常用于 CNN,与静态量化相比可获得更高的精度。
在应用训练后静态量化之前,我们可能需要修改模型。请参阅Eager 模式静态量化模型准备。
图示
# original model
# all tensors and computations are in floating point
previous_layer_fp32 -- linear_fp32 -- activation_fp32 -- next_layer_fp32
/
linear_weight_fp32
# model with fake_quants for modeling quantization numerics during training
previous_layer_fp32 -- fq -- linear_fp32 -- activation_fp32 -- fq -- next_layer_fp32
/
linear_weight_fp32 -- fq
# quantized model
# weights and activations are in int8
previous_layer_int8 -- linear_with_activation_int8 -- next_layer_int8
/
linear_weight_int8
QAT API 示例
import torch
# define a floating point model where some layers could benefit from QAT
class M(torch.nn.Module):
def __init__(self):
super().__init__()
# QuantStub converts tensors from floating point to quantized
self.quant = torch.ao.quantization.QuantStub()
self.conv = torch.nn.Conv2d(1, 1, 1)
self.bn = torch.nn.BatchNorm2d(1)
self.relu = torch.nn.ReLU()
# DeQuantStub converts tensors from quantized to floating point
self.dequant = torch.ao.quantization.DeQuantStub()
def forward(self, x):
x = self.quant(x)
x = self.conv(x)
x = self.bn(x)
x = self.relu(x)
x = self.dequant(x)
return x
# create a model instance
model_fp32 = M()
# model must be set to eval for fusion to work
model_fp32.eval()
# attach a global qconfig, which contains information about what kind
# of observers to attach. Use 'x86' for server inference and 'qnnpack'
# for mobile inference. Other quantization configurations such as selecting
# symmetric or asymmetric quantization and MinMax or L2Norm calibration techniques
# can be specified here.
# Note: the old 'fbgemm' is still available but 'x86' is the recommended default
# for server inference.
# model_fp32.qconfig = torch.ao.quantization.get_default_qconfig('fbgemm')
model_fp32.qconfig = torch.ao.quantization.get_default_qat_qconfig('x86')
# fuse the activations to preceding layers, where applicable
# this needs to be done manually depending on the model architecture
model_fp32_fused = torch.ao.quantization.fuse_modules(model_fp32,
[['conv', 'bn', 'relu']])
# Prepare the model for QAT. This inserts observers and fake_quants in
# the model needs to be set to train for QAT logic to work
# the model that will observe weight and activation tensors during calibration.
model_fp32_prepared = torch.ao.quantization.prepare_qat(model_fp32_fused.train())
# run the training loop (not shown)
training_loop(model_fp32_prepared)
# Convert the observed model to a quantized model. This does several things:
# quantizes the weights, computes and stores the scale and bias value to be
# used with each activation tensor, fuses modules where appropriate,
# and replaces key operators with quantized implementations.
model_fp32_prepared.eval()
model_int8 = torch.ao.quantization.convert(model_fp32_prepared)
# run the model, relevant calculations will happen in int8
res = model_int8(input_fp32)
要了解更多关于量化感知训练的信息,请参阅QAT 教程。
Eager 模式静态量化模型准备¶
目前需要对 Eager 模式量化之前的模型定义进行一些修改。这是因为当前量化是基于模块进行的。具体来说,对于所有量化技术,用户需要:
将任何需要输出重新量化(因此有额外参数)的操作从函数式形式转换为模块形式(例如,使用
torch.nn.ReLU而不是torch.nn.functional.relu)。通过在子模块上分配
.qconfig属性或指定qconfig_mapping来指定模型需要量化的部分。例如,设置model.conv1.qconfig = None意味着model.conv层将不会被量化,设置model.linear1.qconfig = custom_qconfig意味着model.linear1的量化设置将使用custom_qconfig而不是全局 qconfig。
对于量化激活值的静态量化技术,用户还需要执行以下操作:
指定激活值在哪里进行量化和反量化。这通过使用
QuantStub和DeQuantStub模块完成。使用
FloatFunctional将需要特殊量化处理的张量操作包装成模块。例如,像add和cat这样的操作,它们需要特殊处理来确定输出量化参数。融合模块:将操作/模块组合成一个模块,以获得更高的精度和性能。这通过使用
fuse_modules()API 完成,该 API 接收要融合的模块列表。我们目前支持以下融合:[Conv, Relu], [Conv, BatchNorm], [Conv, BatchNorm, Relu], [Linear, Relu]。
(原型 - 维护模式)FX 图模式量化¶
训练后量化(仅权重、动态和静态)中有多种量化类型,配置通过 qconfig_mapping(prepare_fx 函数的一个参数)完成。
FXPTQ API 示例
import torch
from torch.ao.quantization import (
get_default_qconfig_mapping,
get_default_qat_qconfig_mapping,
QConfigMapping,
)
import torch.ao.quantization.quantize_fx as quantize_fx
import copy
model_fp = UserModel()
#
# post training dynamic/weight_only quantization
#
# we need to deepcopy if we still want to keep model_fp unchanged after quantization since quantization apis change the input model
model_to_quantize = copy.deepcopy(model_fp)
model_to_quantize.eval()
qconfig_mapping = QConfigMapping().set_global(torch.ao.quantization.default_dynamic_qconfig)
# a tuple of one or more example inputs are needed to trace the model
example_inputs = (input_fp32)
# prepare
model_prepared = quantize_fx.prepare_fx(model_to_quantize, qconfig_mapping, example_inputs)
# no calibration needed when we only have dynamic/weight_only quantization
# quantize
model_quantized = quantize_fx.convert_fx(model_prepared)
#
# post training static quantization
#
model_to_quantize = copy.deepcopy(model_fp)
qconfig_mapping = get_default_qconfig_mapping("qnnpack")
model_to_quantize.eval()
# prepare
model_prepared = quantize_fx.prepare_fx(model_to_quantize, qconfig_mapping, example_inputs)
# calibrate (not shown)
# quantize
model_quantized = quantize_fx.convert_fx(model_prepared)
#
# quantization aware training for static quantization
#
model_to_quantize = copy.deepcopy(model_fp)
qconfig_mapping = get_default_qat_qconfig_mapping("qnnpack")
model_to_quantize.train()
# prepare
model_prepared = quantize_fx.prepare_qat_fx(model_to_quantize, qconfig_mapping, example_inputs)
# training loop (not shown)
# quantize
model_quantized = quantize_fx.convert_fx(model_prepared)
#
# fusion
#
model_to_quantize = copy.deepcopy(model_fp)
model_fused = quantize_fx.fuse_fx(model_to_quantize)
请按照以下教程了解更多关于 FX 图模式量化的信息
(原型)PyTorch 2 Export 量化¶
API 示例
import torch
from torch.ao.quantization.quantize_pt2e import prepare_pt2e
from torch.export import export_for_training
from torch.ao.quantization.quantizer import (
XNNPACKQuantizer,
get_symmetric_quantization_config,
)
class M(torch.nn.Module):
def __init__(self):
super().__init__()
self.linear = torch.nn.Linear(5, 10)
def forward(self, x):
return self.linear(x)
# initialize a floating point model
float_model = M().eval()
# define calibration function
def calibrate(model, data_loader):
model.eval()
with torch.no_grad():
for image, target in data_loader:
model(image)
# Step 1. program capture
# NOTE: this API will be updated to torch.export API in the future, but the captured
# result should mostly stay the same
m = export_for_training(m, *example_inputs).module()
# we get a model with aten ops
# Step 2. quantization
# backend developer will write their own Quantizer and expose methods to allow
# users to express how they
# want the model to be quantized
quantizer = XNNPACKQuantizer().set_global(get_symmetric_quantization_config())
# or prepare_qat_pt2e for Quantization Aware Training
m = prepare_pt2e(m, quantizer)
# run calibration
# calibrate(m, sample_inference_data)
m = convert_pt2e(m)
# Step 3. lowering
# lower to target backend
请按照这些教程开始使用 PyTorch 2 Export 量化
模型用户
后端开发人员(请也查看所有模型用户文档)
量化堆栈¶
量化是将浮点模型转换为量化模型的过程。因此,从高层次来看,量化堆栈可以分为两部分:1). 量化模型的构建块或抽象 2). 将浮点模型转换为量化模型的量化流程的构建块或抽象。
量化模型¶
量化张量¶
为了在 PyTorch 中进行量化,我们需要能够表示量化数据在张量中。量化张量允许存储量化数据(表示为 int8/uint8/int32)以及量化参数,如 scale 和 zero_point。量化张量允许许多有用的操作,使量化算术变得容易,此外还允许以量化格式序列化数据。
PyTorch 支持逐张量(per tensor)和逐通道(per channel)的对称(symmetric)和非对称(asymmetric)量化。逐张量意味着张量内的所有值都以相同的方式使用相同的量化参数进行量化。逐通道意味着对于每个维度(通常是张量的通道维度),张量中的值使用不同的量化参数进行量化。这减少了将张量转换为量化值时的误差,因为异常值只会影响其所在的通道,而不是整个张量。
映射通过以下方式使用浮点张量进行转换:
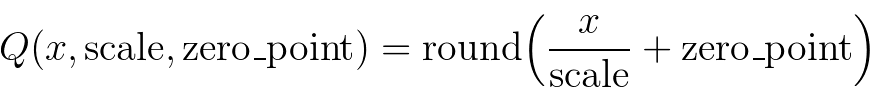
注意,我们确保浮点数中的零在量化后能无误差地表示,从而确保像 padding 这样的操作不会引起额外的量化误差。
以下是量化张量的几个关键属性
QScheme (torch.qscheme):一个枚举,指定量化张量的方式
torch.per_tensor_affine
torch.per_tensor_symmetric
torch.per_channel_affine
torch.per_channel_symmetric
dtype (torch.dtype):量化张量的数据类型
torch.quint8
torch.qint8
torch.qint32
torch.float16
量化参数(根据 QScheme 不同而异):选定量化方式的参数
torch.per_tensor_affine 将具有以下量化参数
scale (浮点数)
zero_point (整数)
torch.per_channel_affine 将具有以下量化参数
per_channel_scales (浮点数列表)
per_channel_zero_points (整数列表)
axis (整数)
量化与反量化¶
模型的输入和输出是浮点张量,但量化模型中的激活值是量化的,因此我们需要运算符在浮点张量和量化张量之间进行转换。
量化 (浮点 -> 量化)
torch.quantize_per_tensor(x, scale, zero_point, dtype)
torch.quantize_per_channel(x, scales, zero_points, axis, dtype)
torch.quantize_per_tensor_dynamic(x, dtype, reduce_range)
to(torch.float16)
反量化 (量化 -> 浮点)
quantized_tensor.dequantize() - 在 torch.float16 张量上调用 dequantize 将把张量转换回 torch.float
torch.dequantize(x)
量化运算符/模块¶
量化运算符是接受量化张量作为输入并输出量化张量的运算符。
量化模块是执行量化操作的 PyTorch 模块。它们通常为加权操作(如 linear 和 conv)定义。
量化引擎¶
执行量化模型时,qengine (torch.backends.quantized.engine) 指定用于执行的后端。重要的是确保 qengine 与量化模型在量化激活值和权重的取值范围方面兼容。
量化流程¶
Observer 和 FakeQuantize¶
Observer 是用于以下目的的 PyTorch 模块:
收集通过 Observer 的张量统计信息,例如最小值和最大值
并根据收集到的张量统计信息计算量化参数
FakeQuantize 是用于以下目的的 PyTorch 模块:
模拟网络中张量的量化(执行量化/反量化)
它可以根据从 Observer 收集的统计信息计算量化参数,也可以学习量化参数
QConfig¶
QConfig 是 Observer 或 FakeQuantize 模块类的命名元组,可以使用 qscheme、dtype 等进行配置。它用于配置如何对运算符进行观察。
运算符/模块的量化配置
不同类型的 Observer/FakeQuantize
dtype
qscheme
quant_min/quant_max:可用于模拟较低精度张量
当前支持激活值和权重的配置
我们根据为给定运算符或模块配置的 qconfig 插入输入/权重/输出 Observer
量化总体流程¶
通常,流程如下:
准备 (prepare)
根据用户指定的 qconfig 插入 Observer/FakeQuantize 模块
校准/训练(取决于训练后量化还是量化感知训练)
允许 Observer 收集统计信息或 FakeQuantize 模块学习量化参数
转换 (convert)
将校准/训练后的模型转换为量化模型
量化有不同的模式,可以从两个方面分类
根据应用量化流程的位置,我们有
训练后量化(在训练后应用量化,量化参数基于样本校准数据计算)
量化感知训练(在训练期间模拟量化,以便使用训练数据学习量化参数和模型)
根据我们如何量化运算符,我们可以有
仅权重量化(只有权重是静态量化的)
动态量化(权重是静态量化的,激活值是动态量化的)
静态量化(权重和激活值都是静态量化的)
我们可以在同一个量化流程中混合不同的运算符量化方式。例如,我们可以在训练后量化中同时包含静态量化和动态量化运算符。
量化支持矩阵¶
量化模式支持¶
量化模式 |
数据集需求 |
最适用于 |
精度 |
注释 |
||
训练后量化 |
动态/仅权重量化 |
激活值动态量化(fp16, int8)或不量化,权重静态量化(fp16, int8, in4) |
无 |
LSTM, MLP, Embedding, Transformer |
良好 |
易于使用,当性能受权重计算或内存限制时,接近静态量化 |
静态量化 |
静态量化 |
激活值和权重静态量化 (int8) |
校准数据集 |
良好 |
CNN |
|
提供最佳性能,可能对精度影响较大,适用于仅支持 int8 计算的硬件 |
动态量化 |
量化感知训练 |
激活值和权重是伪量化的 |
微调数据集 |
MLP, Embedding |
最佳 |
静态量化 |
量化感知训练 |
激活值和权重是伪量化的 |
CNN, MLP, Embedding |
MLP, Embedding |
通常在静态量化导致精度不佳时使用,用于弥补精度差距 |
|
请参阅我们的PyTorch 量化简介 博客文章,以更全面地了解这些量化类型之间的权衡。
量化流程支持¶
PyTorch 提供两种量化模式:Eager 模式量化和 FX 图模式量化。
Eager 模式量化是 Beta 功能。用户需要手动进行融合并指定量化和反量化发生的位置,并且它只支持模块而不支持函数式操作 (functionals)。
FX Graph Mode Quantization 是 PyTorch 中的一种自动化量化框架,目前是一个原型功能。它在 Eager Mode Quantization 的基础上进行了改进,增加了对函数(functionals)的支持并自动化了量化过程,不过用户可能需要重构模型以使其与 FX Graph Mode Quantization 兼容(即可以使用 torch.fx 进行符号追踪)。请注意,FX Graph Mode Quantization 并非预期适用于任意模型,因为模型可能无法进行符号追踪。我们将把此功能集成到 torchvision 等领域库中,用户将能够使用 FX Graph Mode Quantization 量化与支持的领域库中类似的模型。对于任意模型,我们将提供一般性指导,但要使其真正工作,用户可能需要熟悉 torch.fx,尤其是如何使模型可进行符号追踪。
鼓励量化的新用户首先尝试 FX Graph Mode Quantization,如果不行,用户可以尝试按照使用 FX Graph Mode Quantization的指南操作,或回退到 eager mode quantization。
下表比较了 Eager Mode Quantization 和 FX Graph Mode Quantization 的区别
Eager 模式量化 |
FX 图模式量化 |
|
发布状态 |
Beta |
原型 |
运算符融合 |
手动 |
自动 |
量化/反量化放置 |
手动 |
自动 |
量化模块 |
支持 |
支持 |
量化函数式操作/Torch 运算符 |
手动 |
自动 |
支持自定义 |
有限支持 |
完全支持 |
量化模式支持 |
训练后量化:静态、动态、仅权重 量化感知训练:静态 |
训练后量化:静态、动态、仅权重 量化感知训练:静态 |
输入/输出模型类型 |
|
|
后端/硬件支持¶
硬件 |
核函数库 |
Eager 模式量化 |
FX 图模式量化 |
量化模式支持 |
服务器 CPU |
fbgemm/onednn |
支持 |
全部支持 |
|
移动 CPU |
qnnpack/xnnpack |
|||
服务器 GPU |
TensorRT (早期原型) |
不支持,因为它需要一个图 |
支持 |
静态量化 |
目前,PyTorch 支持以下后端高效运行量化算子
具有 AVX2 或更高版本支持的 x86 CPU(没有 AVX2 时,一些操作的实现效率较低),通过由 fbgemm 和 onednn 优化的 x86(详情请参阅 RFC)
ARM CPU(通常用于移动/嵌入式设备),通过 qnnpack
通过 TensorRT (通过 fx2trt,即将开源) 对 NVidia GPU 的支持(早期原型)
原生 CPU 后端注意事项¶
我们通过相同的原生 PyTorch 量化算子暴露了 x86 和 qnnpack,因此我们需要额外的标志来区分它们。选择 x86 和 qnnpack 对应的实现是根据 PyTorch 构建模式自动进行的,不过用户可以选择设置 torch.backends.quantization.engine 为 x86 或 qnnpack 来覆盖此设置。
准备量化模型时,需要确保 qconfig 和用于量化计算的 engine 与模型将在其上执行的后端匹配。qconfig 控制量化过程中使用的 observer 类型。qengine 控制在为 linear 和 convolution 函数和模块打包权重时是否使用 x86 或 qnnpack 特定的打包函数。例如:
x86 的默认设置
# set the qconfig for PTQ
# Note: the old 'fbgemm' is still available but 'x86' is the recommended default on x86 CPUs
qconfig = torch.ao.quantization.get_default_qconfig('x86')
# or, set the qconfig for QAT
qconfig = torch.ao.quantization.get_default_qat_qconfig('x86')
# set the qengine to control weight packing
torch.backends.quantized.engine = 'x86'
qnnpack 的默认设置
# set the qconfig for PTQ
qconfig = torch.ao.quantization.get_default_qconfig('qnnpack')
# or, set the qconfig for QAT
qconfig = torch.ao.quantization.get_default_qat_qconfig('qnnpack')
# set the qengine to control weight packing
torch.backends.quantized.engine = 'qnnpack'
算子支持¶
算子覆盖率在动态量化和静态量化之间有所不同,如下表所示。请注意,对于 FX Graph Mode Quantization,也支持相应的函数(functionals)。
静态量化 |
动态量化 |
|
nn.Linear
nn.Conv1d/2d/3d
|
是
是
|
是
否
|
nn.LSTM
nn.GRU
|
否
否
|
是
是
|
nn.RNNCell
nn.GRUCell
nn.LSTMCell
|
否
否
否
|
是
是
是
|
nn.EmbeddingBag |
是(激活值为 fp32) |
是 |
nn.Embedding |
是 |
是 |
nn.MultiheadAttention |
不支持 |
不支持 |
激活值 |
广泛支持 |
未改变,计算仍为 fp32 |
注意:这将很快更新一些从原生 backend_config_dict 生成的信息。
量化定制¶
虽然提供了基于观测到的 tensor 数据选择尺度因子和偏差的默认 observer 实现,但开发者可以提供自己的量化函数。量化可以有选择地应用于模型的不同部分,或者为模型的不同部分进行不同的配置。
我们还支持对 conv1d()、conv2d()、conv3d() 和 linear() 进行逐通道量化。
量化工作流通过添加(例如,将 observer 作为 .observer 子模块添加)或替换(例如,将 nn.Conv2d 转换为 nn.quantized.Conv2d)模型模块层次结构中的子模块来实现。这意味着模型在整个过程中保持一个常规的 nn.Module 实例,因此可以与 PyTorch 的其余 API 协同工作。
量化自定义模块 API¶
Eager mode 和 FX graph mode 量化 API 都提供了一个 hook,供用户以自定义方式指定量化模块,并使用用户定义的观测和量化逻辑。用户需要指定:
源 fp32 模块(存在于模型中)的 Python 类型
观测模块(由用户提供)的 Python 类型。此模块需要定义一个 from_float 函数,该函数定义如何从原始 fp32 模块创建观测模块。
量化模块(由用户提供)的 Python 类型。此模块需要定义一个 from_observed 函数,该函数定义如何从观测模块创建量化模块。
描述上述 (1)、(2)、(3) 的配置,传递给量化 API。
框架随后将执行以下操作:
在 prepare 模块交换期间,它将使用 (2) 中类的 from_float 函数,将指定类型在 (1) 中的每个模块转换为指定类型在 (2) 中的模块。
在 convert 模块交换期间,它将使用 (3) 中类的 from_observed 函数,将指定类型在 (2) 中的每个模块转换为指定类型在 (3) 中的模块。
目前,要求 ObservedCustomModule 只有一个 Tensor 输出,并且框架(而不是用户)将在此输出上添加一个 observer。observer 将作为自定义模块实例的属性存储在 activation_post_process 键下。将来可能会放宽这些限制。
自定义 API 示例
import torch
import torch.ao.nn.quantized as nnq
from torch.ao.quantization import QConfigMapping
import torch.ao.quantization.quantize_fx
# original fp32 module to replace
class CustomModule(torch.nn.Module):
def __init__(self):
super().__init__()
self.linear = torch.nn.Linear(3, 3)
def forward(self, x):
return self.linear(x)
# custom observed module, provided by user
class ObservedCustomModule(torch.nn.Module):
def __init__(self, linear):
super().__init__()
self.linear = linear
def forward(self, x):
return self.linear(x)
@classmethod
def from_float(cls, float_module):
assert hasattr(float_module, 'qconfig')
observed = cls(float_module.linear)
observed.qconfig = float_module.qconfig
return observed
# custom quantized module, provided by user
class StaticQuantCustomModule(torch.nn.Module):
def __init__(self, linear):
super().__init__()
self.linear = linear
def forward(self, x):
return self.linear(x)
@classmethod
def from_observed(cls, observed_module):
assert hasattr(observed_module, 'qconfig')
assert hasattr(observed_module, 'activation_post_process')
observed_module.linear.activation_post_process = \
observed_module.activation_post_process
quantized = cls(nnq.Linear.from_float(observed_module.linear))
return quantized
#
# example API call (Eager mode quantization)
#
m = torch.nn.Sequential(CustomModule()).eval()
prepare_custom_config_dict = {
"float_to_observed_custom_module_class": {
CustomModule: ObservedCustomModule
}
}
convert_custom_config_dict = {
"observed_to_quantized_custom_module_class": {
ObservedCustomModule: StaticQuantCustomModule
}
}
m.qconfig = torch.ao.quantization.default_qconfig
mp = torch.ao.quantization.prepare(
m, prepare_custom_config_dict=prepare_custom_config_dict)
# calibration (not shown)
mq = torch.ao.quantization.convert(
mp, convert_custom_config_dict=convert_custom_config_dict)
#
# example API call (FX graph mode quantization)
#
m = torch.nn.Sequential(CustomModule()).eval()
qconfig_mapping = QConfigMapping().set_global(torch.ao.quantization.default_qconfig)
prepare_custom_config_dict = {
"float_to_observed_custom_module_class": {
"static": {
CustomModule: ObservedCustomModule,
}
}
}
convert_custom_config_dict = {
"observed_to_quantized_custom_module_class": {
"static": {
ObservedCustomModule: StaticQuantCustomModule,
}
}
}
mp = torch.ao.quantization.quantize_fx.prepare_fx(
m, qconfig_mapping, torch.randn(3,3), prepare_custom_config=prepare_custom_config_dict)
# calibration (not shown)
mq = torch.ao.quantization.quantize_fx.convert_fx(
mp, convert_custom_config=convert_custom_config_dict)
最佳实践¶
1. 如果您正在使用 x86 后端,我们需要使用 7 位而不是 8 位。请确保减小 quant\_min 和 quant\_max 的范围,例如:如果 dtype 是 torch.quint8,请确保设置自定义 quant_min 为 0,quant_max 为 127 (255 / 2);如果 dtype 是 torch.qint8,请确保设置自定义 quant_min 为 -64 (-128 / 2),quant_max 为 63 (127 / 2)。如果您调用 torch.ao.quantization.get_default_qconfig(backend) 或 torch.ao.quantization.get_default_qat_qconfig(backend) 函数来获取 x86 或 qnnpack 后端的默认 qconfig,我们已经正确设置了这些值。
2. 如果选择了 onednn 后端,在默认 qconfig 映射 torch.ao.quantization.get_default_qconfig_mapping('onednn') 和默认 qconfig torch.ao.quantization.get_default_qconfig('onednn') 中,激活将使用 8 位。建议在支持矢量神经网络指令 (VNNI) 的 CPU 上使用。否则,设置激活的 observer 的 reduce_range 为 True,以在没有 VNNI 支持的 CPU 上获得更好的精度。
常见问题解答¶
我如何在 GPU 上进行量化推理?
我们目前还没有官方的 GPU 支持,但这正在积极开发中。您可以在此处找到更多信息。
我的量化模型在哪里可以获得 ONNX 支持?
如果您在导出模型时(使用
torch.onnx下的 API)遇到错误,您可以在 PyTorch 仓库中提出问题。在问题标题前加上[ONNX]并标记问题为module: onnx。如果您在使用 ONNX Runtime 时遇到问题,请在GitHub - microsoft/onnxruntime上提出问题。
我如何将量化与 LSTM 一起使用?
LSTM 在 eager mode 和 fx graph mode 量化中都通过我们的自定义模块 API 得到支持。示例可以在 Eager Mode: pytorch/test_quantized_op.py TestQuantizedOps.test_custom_module_lstm FX Graph Mode: pytorch/test_quantize_fx.py TestQuantizeFx.test_static_lstm 中找到。
常见错误¶
将非量化 Tensor 传递给量化核函数¶
如果您看到类似于以下内容的错误:
RuntimeError: Could not run 'quantized::some_operator' with arguments from the 'CPU' backend...
这意味着您尝试将非量化 Tensor 传递给量化核函数。一个常见的解决方法是使用 torch.ao.quantization.QuantStub 对 Tensor 进行量化。在 Eager mode 量化中,这需要手动完成。一个端到端示例:
class M(torch.nn.Module):
def __init__(self):
super().__init__()
self.quant = torch.ao.quantization.QuantStub()
self.conv = torch.nn.Conv2d(1, 1, 1)
def forward(self, x):
# during the convert step, this will be replaced with a
# `quantize_per_tensor` call
x = self.quant(x)
x = self.conv(x)
return x
将量化 Tensor 传递给非量化核函数¶
如果您看到类似于以下内容的错误:
RuntimeError: Could not run 'aten::thnn_conv2d_forward' with arguments from the 'QuantizedCPU' backend.
这意味着您尝试将量化 Tensor 传递给非量化核函数。一个常见的解决方法是使用 torch.ao.quantization.DeQuantStub 对 Tensor 进行反量化。在 Eager mode 量化中,这需要手动完成。一个端到端示例:
class M(torch.nn.Module):
def __init__(self):
super().__init__()
self.quant = torch.ao.quantization.QuantStub()
self.conv1 = torch.nn.Conv2d(1, 1, 1)
# this module will not be quantized (see `qconfig = None` logic below)
self.conv2 = torch.nn.Conv2d(1, 1, 1)
self.dequant = torch.ao.quantization.DeQuantStub()
def forward(self, x):
# during the convert step, this will be replaced with a
# `quantize_per_tensor` call
x = self.quant(x)
x = self.conv1(x)
# during the convert step, this will be replaced with a
# `dequantize` call
x = self.dequant(x)
x = self.conv2(x)
return x
m = M()
m.qconfig = some_qconfig
# turn off quantization for conv2
m.conv2.qconfig = None
保存和加载量化模型¶
当对量化模型调用 torch.load 时,如果您看到类似于以下内容的错误:
AttributeError: 'LinearPackedParams' object has no attribute '_modules'
这是因为直接使用 torch.save 和 torch.load 保存和加载量化模型不受支持。要保存/加载量化模型,可以使用以下方法:
保存/加载量化模型的 state_dict
一个示例:
class M(torch.nn.Module):
def __init__(self):
super().__init__()
self.linear = nn.Linear(5, 5)
self.relu = nn.ReLU()
def forward(self, x):
x = self.linear(x)
x = self.relu(x)
return x
m = M().eval()
prepare_orig = prepare_fx(m, {'' : default_qconfig})
prepare_orig(torch.rand(5, 5))
quantized_orig = convert_fx(prepare_orig)
# Save/load using state_dict
b = io.BytesIO()
torch.save(quantized_orig.state_dict(), b)
m2 = M().eval()
prepared = prepare_fx(m2, {'' : default_qconfig})
quantized = convert_fx(prepared)
b.seek(0)
quantized.load_state_dict(torch.load(b))
使用
torch.jit.save和torch.jit.load保存/加载 scripted 量化模型
一个示例:
# Note: using the same model M from previous example
m = M().eval()
prepare_orig = prepare_fx(m, {'' : default_qconfig})
prepare_orig(torch.rand(5, 5))
quantized_orig = convert_fx(prepare_orig)
# save/load using scripted model
scripted = torch.jit.script(quantized_orig)
b = io.BytesIO()
torch.jit.save(scripted, b)
b.seek(0)
scripted_quantized = torch.jit.load(b)
使用 FX Graph Mode Quantization 时的符号追踪错误¶
符号追踪是(原型 - 维护模式) FX Graph Mode Quantization的要求。因此,如果您将一个无法进行符号追踪的 PyTorch 模型传递给 torch.ao.quantization.prepare_fx 或 torch.ao.quantization.prepare_qat_fx,可能会看到类似以下的错误:
torch.fx.proxy.TraceError: symbolically traced variables cannot be used as inputs to control flow
请参阅符号追踪的限制并使用使用 FX Graph Mode Quantization 的用户指南来解决此问题。
