常见问题¶
作者: Mark Saroufim
torch.compile 支持训练吗?¶
torch.compile 支持训练,它使用 AOTAutograd 捕获反向传播
TorchDynamo 的 Python
evalframe前端捕获.forward()图和optimizer.step()。对于 TorchDynamo 捕获的每个
.forward()段,它都使用 AOTAutograd 生成一个反向传播图段。每对前向和反向传播图都可以(可选地)进行最小割分区,以在前向和反向传播之间保存最少的状态。
前向和反向传播对被封装在
autograd.function模块中。用户代码调用
.backward()时仍会触发 eager 模式的 autograd 引擎,该引擎将每个 编译后的反向传播 图作为一个 op 运行,同时也会运行任何未编译的 eager ops 的.backward()函数。
你们支持分布式代码吗?¶
torch.compile 支持 DistributedDataParallel (DDP)。对其他分布式训练库的支持正在考虑中。
分布式代码在使用 dynamo 时面临挑战的主要原因是 AOTAutograd 会展开前向和反向传播过程,并为后端提供两个图用于优化。这对于分布式代码来说是个问题,因为理想情况下我们希望将通信操作与计算重叠。Eager PyTorch 通过不同的方式为 DDP/FSDP 实现这一点,例如使用 autograd 钩子、模块钩子以及修改/改变模块状态。在 dynamo 的简单应用中,由于 AOTAutograd 编译函数与调度器钩子的交互方式,本应在反向传播操作后立即运行的钩子可能会延迟到整个反向传播操作的编译区域之后再运行。
使用 Dynamo 优化 DDP 的基本策略在 distributed.py 中进行了概述,其主要思想是在 DDP 分桶边界处进行图断点。
当 DDP 中的每个节点需要与其他节点同步其权重时,它会将梯度和参数组织成桶,这可以减少通信时间,并允许节点将其部分梯度广播到其他等待的节点。
分布式代码中的图断点意味着你可以期望 dynamo 及其后端优化分布式程序的计算开销,但无法优化其通信开销。如果图尺寸减小导致编译器失去融合机会,图断点可能会影响编译加速效果。然而,随着图尺寸的增加,收益会递减,因为当前大多数计算优化都是局部融合。因此,在实践中,这种方法可能就足够了。
我还需要导出整个图吗?¶
对于绝大多数模型,你可能不需要这样做,并且可以直接使用 torch.compile(),但在少数情况下需要完整的图,你可以通过简单地运行 torch.compile(..., fullgraph=True) 来确保获得完整的图。这些情况包括:
需要流水线并行和其他高级分片策略的大规模训练运行,例如超过 25 万美元的训练。
推理优化器,例如 TensorRT 或 AITemplate,它们比训练优化器更积极地进行融合。
移动端训练或推理。
未来的工作将包括将通信操作跟踪到图中,协调这些操作与计算优化,并优化通信操作。
为什么我的代码崩溃了?¶
如果你的代码在没有 torch.compile 的情况下运行良好,但在启用它后开始崩溃,那么最重要的一步是弄清楚故障发生在堆栈的哪个部分。为了解决这个问题,请按照以下步骤操作,并且只有在前一步骤成功后才尝试下一步。
torch.compile(..., backend="eager")只运行 TorchDynamo 前向图捕获,然后使用 PyTorch 运行捕获的图。如果此步骤失败,则说明 TorchDynamo 存在问题。torch.compile(..., backend="aot_eager")运行 TorchDynamo 捕获前向图,然后使用 AOTAutograd 跟踪反向传播图,不执行任何额外的后端编译器步骤。PyTorch eager 模式随后将用于运行前向和反向传播图。如果此步骤失败,则说明 AOTAutograd 存在问题。torch.compile(..., backend="inductor")运行 TorchDynamo 捕获前向图,然后使用 AOTAutograd 和 TorchInductor 编译器跟踪反向传播图。如果此步骤失败,则说明 TorchInductor 存在问题。
为什么编译很慢?¶
Dynamo 编译 – TorchDynamo 有一个内置的统计函数,用于收集和显示每个编译阶段花费的时间。在执行
torch._dynamo后,可以通过调用torch._dynamo.utils.compile_times()来访问这些统计信息。默认情况下,这会返回一个字符串表示,显示每个 TorchDynamo 函数按名称计算的编译时间。Inductor 编译 – TorchInductor 有一个内置的统计和跟踪函数,用于显示每个编译阶段花费的时间、输出代码、输出图可视化和 IR 转储。
env TORCH_COMPILE_DEBUG=1 python repro.py。这是一个调试工具,旨在更容易地调试/理解 TorchInductor 的内部机制,其输出类似于 此处 的内容。调试跟踪中的每个文件都可以通过torch._inductor.config.trace.*启用/禁用。默认情况下,性能分析和图表都处于禁用状态,因为生成它们成本很高。有关更多示例,请参见 示例调试目录输出。过度重新编译 当 TorchDynamo 编译一个函数(或一部分)时,它会对局部变量和全局变量做出某些假设,以便进行编译器优化,并将这些假设表示为在运行时检查特定值的守卫(guard)。如果任何守卫失败,Dynamo 将对该函数(或部分)进行重新编译,最多可达
torch._dynamo.config.recompile_limit次。如果你的程序达到了缓存限制,你首先需要确定是哪个守卫失败了,以及是程序的哪个部分触发了它。重新编译性能分析器 会自动化设置 TorchDynamo 缓存限制为 1 并在一个只进行观察的“编译器”下运行你的程序,该“编译器”会记录任何守卫失败的原因。你应该确保运行你的程序至少达到你遇到问题时的时长(迭代次数),并且性能分析器将在此期间累积统计信息。
为什么在生产环境中会进行重新编译?¶
在某些情况下,你可能不希望程序预热后出现意外的编译。例如,如果你在对延迟敏感的生产应用中提供服务。为此,TorchDynamo 提供了一种替代模式,其中使用之前编译的图,但不会生成新的图。
frozen_toy_example = dynamo.run(toy_example)
frozen_toy_example(torch.randn(10), torch.randn(10))
我的代码是如何被加速的?¶
加速 PyTorch 代码主要有 3 种方式:
通过垂直融合进行核融合(Kernel Fusion),将顺序操作融合以避免过多的读写。例如,融合两个连续的余弦操作意味着你可以进行 1 次读写,而不是 2 次读写。水平融合(Horizontal Fusion):最简单的例子是批量处理,其中单个矩阵与一批样本相乘,但更一般的场景是分组 GEMM,其中一组矩阵乘法被调度在一起执行。
乱序执行(Out of Order Execution):编译器的一项通用优化,通过提前查看图中的精确数据依赖关系,我们可以决定执行节点的最佳时机以及哪些缓冲区可以被重用。
自动工作放置(Automatic Work Placement):类似于乱序执行,但通过将图中的节点与物理硬件或内存等资源匹配,我们可以设计合适的调度方案。
上述是加速 PyTorch 代码的一般原则,但不同的后端会在优化内容上做出不同的权衡。例如,Inductor 首先会尽可能进行融合,然后才生成 Triton 核(kernels)。
此外,Triton 还通过每个 Streaming Multiprocessor 内的自动内存合并、内存管理和调度提供加速,并且被设计用于处理平铺计算(tiled computations)。
然而,无论你使用哪种后端,最好的方法是进行基准测试并观察,所以请尝试使用 PyTorch 性能分析器,可视化检查生成的核,并尝试自己看看发生了什么。
为什么我没有看到加速?¶
图断点¶
使用 dynamo 时,你可能没有看到期望加速的主要原因是过多的图断点。那么什么是图断点?
例如,给定如下程序:
def some_fun(x):
...
torch.compile(some_fun)(x)
...
Torchdynamo 会尝试将 some_fun() 中的所有 torch/tensor 操作编译成一个单一的 FX 图,但可能无法将所有内容都捕获到一个图中。
一些图断点的原因是 TorchDynamo 无法克服的,例如调用 PyTorch 之外的 C 扩展对 TorchDynamo 是不可见的,并且可以执行任意操作,而 TorchDynamo 无法引入必要的守卫来确保编译后的程序可以安全地重用。
为了最大限度地提高性能,尽量减少图断点非常重要。
识别图断点的原因¶
要识别程序中的所有图断点及其相关原因,可以使用 torch._dynamo.explain。该工具会在提供的函数上运行 TorchDynamo 并汇总遇到的图断点。以下是一个使用示例:
import torch
import torch._dynamo as dynamo
def toy_example(a, b):
x = a / (torch.abs(a) + 1)
print("woo")
if b.sum() < 0:
b = b * -1
return x * b
explanation = dynamo.explain(toy_example)(torch.randn(10), torch.randn(10))
print(explanation)
"""
Graph Count: 3
Graph Break Count: 2
Op Count: 5
Break Reasons:
Break Reason 1:
Reason: builtin: print [<class 'torch._dynamo.variables.constant.ConstantVariable'>] False
User Stack:
<FrameSummary file foo.py, line 5 in toy_example>
Break Reason 2:
Reason: generic_jump TensorVariable()
User Stack:
<FrameSummary file foo.py, line 6 in torch_dynamo_resume_in_toy_example_at_5>
Ops per Graph:
...
Out Guards:
...
"""
要在遇到第一个图断点时抛出错误,你可以使用 fullgraph=True 禁用 Python 回退,如果你使用过基于导出的编译器,应该对此很熟悉。
def toy_example(a, b):
...
torch.compile(toy_example, fullgraph=True, backend=<compiler>)(a, b)
为什么我的代码修改后没有重新编译?¶
如果你通过设置 env TORCHDYNAMO_DYNAMIC_SHAPES=1 python model.py 启用了动态形状,那么你的代码在形状变化时不会重新编译。我们添加了对动态形状的支持,这可以避免在形状变化小于两倍的情况下进行重新编译。这在 CV 中图像尺寸变化或 NLP 中序列长度变化等场景中特别有用。在推理场景中,通常无法预先知道批量大小,因为你会接收来自不同客户端应用的任何数据。
总的来说,TorchDynamo 会非常努力地避免不必要的重新编译,因此如果 TorchDynamo 找到了 3 个图,而你的更改只修改了一个图,那么只有该图会重新编译。因此,另一个避免潜在慢编译时间的方法是先对模型进行一次预热编译,之后的后续编译会快得多。冷启动编译时间仍然是我们明确跟踪的一个指标。
为什么我得到了错误的结果?¶
如果设置环境变量 TORCHDYNAMO_REPRO_LEVEL=4,也可以最小化精度问题,它的工作方式类似于 git bisect 模型,完整的复现可能类似于 TORCHDYNAMO_REPRO_AFTER="aot" TORCHDYNAMO_REPRO_LEVEL=4 之类的。我们需要这个是因为下游编译器会生成代码,无论是 Triton 代码还是 C++ 后端,这些下游编译器的数值可能存在细微差异,但却会对你的训练稳定性产生巨大影响。因此,精度调试器对于我们检测代码生成器或后端编译器中的错误非常有用。
如果你想确保 torch 和 triton 之间的随机数生成是相同的,你可以启用 torch._inductor.config.fallback_random = True
为什么我会遇到 OOM(内存不足)?¶
Dynamo 仍处于 Alpha 阶段,因此存在一些 OOM 的来源,如果你遇到了 OOM,请尝试按以下顺序禁用这些配置,然后在 GitHub 上提交 issue,以便我们解决根本问题。1. 如果你正在使用动态形状,请尝试禁用它,我们默认是禁用的:env TORCHDYNAMO_DYNAMIC_SHAPES=0 python model.py 2. 在 Inductor 中,默认启用带 Triton 的 CUDA Graphs,但移除它们可能会缓解一些 OOM 问题:torch._inductor.config.triton.cudagraphs = False。
torch.func(用于 grad 和 vmap 转换)是否与 torch.compile 一起使用?¶
对使用 torch.compile 的函数应用 torch.func 转换是可行的
import torch
@torch.compile
def f(x):
return torch.sin(x)
def g(x):
return torch.grad(f)(x)
x = torch.randn(2, 3)
g(x)
在用 torch.compile 处理的函数内部调用 torch.func 转换¶
使用 torch.compile 编译 torch.func.grad¶
import torch
def wrapper_fn(x):
return torch.func.grad(lambda x: x.sin().sum())(x)
x = torch.randn(3, 3, 3)
grad_x = torch.compile(wrapper_fn)(x)
使用 torch.compile 编译 torch.vmap¶
import torch
def my_fn(x):
return torch.vmap(lambda x: x.sum(1))(x)
x = torch.randn(3, 3, 3)
output = torch.compile(my_fn)(x)
编译不受支持的函数(逃生舱)¶
对于其他转换,作为一种变通方法,请使用 torch._dynamo.allow_in_graph
allow_in_graph 是一个逃生舱。如果你的代码无法与内省 Python 字节码的 torch.compile 配合使用,但你认为它可以通过符号跟踪方法(如 jax.jit)工作,那么请使用 allow_in_graph。
通过使用 allow_in_graph 注解函数,你必须确保你的代码满足以下要求:
函数中的所有输出仅依赖于输入,不依赖于任何捕获的张量(Tensor)。
你的函数是纯函数(functional)。也就是说,它不改变任何状态。这一点可能会放宽;我们实际上支持那些从外部看来是纯函数的函数:它们可能包含原地(in-place)的 PyTorch 操作,但不能改变全局状态或函数的输入。
你的函数不会引发数据相关的错误。
import torch
@torch.compile
def f(x):
return torch._dynamo.allow_in_graph(torch.vmap(torch.sum))(x)
x = torch.randn(2, 3)
f(x)
一个常见的陷阱是使用 allow_in_graph 注解一个调用 nn.Module 的函数。这是因为输出现在依赖于 nn.Module 的参数。要使其工作,请使用 torch.func.functional_call 来提取模块状态。
NumPy 是否与 torch.compile 配合使用?¶
从 2.1 版本开始,torch.compile 支持直接操作 NumPy 数组的原生 NumPy 程序,以及通过 x.numpy()、torch.from_numpy 及相关函数在 PyTorch 和 NumPy 之间进行转换的混合 PyTorch-NumPy 程序。
torch.compile 支持哪些 NumPy 功能?¶
torch.compile 中的 NumPy 遵循 NumPy 2.0 预发布版本。
通常,torch.compile 能够跟踪大多数 NumPy 结构,当无法跟踪时,它会回退到 eager 模式并让 NumPy 执行该段代码。即便如此,在某些功能上,torch.compile 的语义与 NumPy 的语义略有不同:
NumPy 标量(scalars):我们将它们建模为 0 维数组。也就是说,在
torch.compile下,np.float32(3)返回一个 0 维数组。为了避免图断点,最好使用此 0 维数组。如果这导致你的代码中断,你可以通过将 NumPy 标量转换为相应的 Python 标量类型bool/int/float来解决。负步长(Negative strides):
np.flip和带有负步长的切片返回一个副本。类型提升(Type promotion):NumPy 的类型提升将在 NumPy 2.0 中发生变化。新规则在 NEP 50 中描述。
torch.compile实现的是 NEP 50,而不是当前即将弃用的规则。{tril,triu}_indices_from/{tril,triu}_indices返回数组而不是数组元组。
还有一些其他功能我们不支持跟踪,并且会优雅地回退到 NumPy 进行执行:
非数值数据类型(dtypes),例如日期时间、字符串、字符、void、结构化数据类型和记录数组(recarrays)。
长数据类型(long dtypes)
np.float128/np.complex256以及一些无符号数据类型(unsigned dtypes)np.uint16/np.uint32/np.uint64。ndarray子类。掩码数组(Masked arrays)。
深奥的 ufunc 机制,例如
axes=[(n,k),(k,m)->(n,m)]以及 ufunc 方法(例如np.add.reduce)。排序/排序
complex64/complex128数组。NumPy
np.poly1d和np.polynomial。返回 2 个或更多值的函数中的位置参数
out1, out2(out=tuple是可行的)。__array_function__,__array_interface__和__array_wrap__。ndarray.ctypes属性。
我可以使用 torch.compile 编译 NumPy 代码吗?¶
当然可以!torch.compile 原生支持理解 NumPy 代码,并将其视为 PyTorch 代码处理。只需使用 torch.compile 装饰器封装 NumPy 代码即可。
import torch
import numpy as np
@torch.compile
def numpy_fn(X: np.ndarray, Y: np.ndarray) -> np.ndarray:
return np.sum(X[:, :, None] * Y[:, None, :], axis=(-2, -1))
X = np.random.randn(1024, 64)
Y = np.random.randn(1024, 64)
Z = numpy_fn(X, Y)
assert isinstance(Z, np.ndarray)
通过设置环境变量 TORCH_LOGS=output_code 执行此示例,我们可以看到 torch.compile 能够将乘法和求和融合成一个 C++ 内核。它还能使用 OpenMP 并行执行这些操作(原生 NumPy 是单线程的)。这可以轻松让您的 NumPy 代码加速 n 倍,其中 n 是您处理器中的核心数量!
以这种方式跟踪 NumPy 代码也支持在编译代码中进行图中断。
我可以在 CUDA 上执行 NumPy 代码并通过 torch.compile 计算梯度吗?¶
是的,可以!为此,您只需在 torch.device("cuda") 上下文管理器中执行代码即可。请考虑以下示例:
import torch
import numpy as np
@torch.compile
def numpy_fn(X: np.ndarray, Y: np.ndarray) -> np.ndarray:
return np.sum(X[:, :, None] * Y[:, None, :], axis=(-2, -1))
X = np.random.randn(1024, 64)
Y = np.random.randn(1024, 64)
with torch.device("cuda"):
Z = numpy_fn(X, Y)
assert isinstance(Z, np.ndarray)
在此示例中,numpy_fn 将在 CUDA 中执行。为了实现这一点,torch.compile 会自动将 X 和 Y 从 CPU 移动到 CUDA,然后再将结果 Z 从 CUDA 移动到 CPU。如果我们在同一个程序运行中多次执行此函数,我们可能希望避免这些相当昂贵的内存复制。为此,我们只需要调整 numpy_fn,使其接受 CUDA 张量并返回张量即可。我们可以通过使用 torch.compiler.wrap_numpy 来实现这一点:
@torch.compile(fullgraph=True)
@torch.compiler.wrap_numpy
def numpy_fn(X, Y):
return np.sum(X[:, :, None] * Y[:, None, :], axis=(-2, -1))
X = torch.randn(1024, 64, device="cuda")
Y = torch.randn(1024, 64, device="cuda")
Z = numpy_fn(X, Y)
assert isinstance(Z, torch.Tensor)
assert Z.device.type == "cuda"
在这里,我们在 CUDA 内存中显式创建张量,并将它们传递给函数,函数在 CUDA 设备上执行所有计算。wrap_numpy 负责在 torch.compile 级别标记任何 torch.Tensor 输入,使其具有 np.ndarray 语义。在编译器内部标记张量是一个非常廉价的操作,因此在运行时不会发生数据复制或数据移动。
使用此装饰器,我们还可以通过 NumPy 代码进行微分!
@torch.compile(fullgraph=True)
@torch.compiler.wrap_numpy
def numpy_fn(X, Y):
return np.mean(np.sum(X[:, :, None] * Y[:, None, :], axis=(-2, -1)))
X = torch.randn(1024, 64, device="cuda", requires_grad=True)
Y = torch.randn(1024, 64, device="cuda")
Z = numpy_fn(X, Y)
assert isinstance(Z, torch.Tensor)
Z.backward()
# X.grad now holds the gradient of the computation
print(X.grad)
我们一直在使用 fullgraph=True,因为在这种情况下图中断是有问题的。当发生图中断时,我们需要具体化 NumPy 数组。由于 NumPy 数组没有 device 或 requires_grad 的概念,因此在图中断期间会丢失此信息。
我们无法通过图中断传播梯度,因为图中断代码可能执行任意代码,而这些代码不知道如何微分。另一方面,在 CUDA 执行的情况下,我们可以像第一个示例那样,通过使用 torch.device("cuda") 上下文管理器来解决这个问题:
@torch.compile
@torch.compiler.wrap_numpy
def numpy_fn(X, Y):
prod = X[:, :, None] * Y[:, None, :]
print("oops, a graph break!")
return np.sum(prod, axis=(-2, -1))
X = torch.randn(1024, 64, device="cuda")
Y = torch.randn(1024, 64, device="cuda")
with torch.device("cuda"):
Z = numpy_fn(X, Y)
assert isinstance(Z, torch.Tensor)
assert Z.device.type == "cuda"
在图中断期间,中间张量仍然需要移动到 CPU,但当图中断后跟踪恢复时,图的其余部分仍会在 CUDA 上被跟踪。考虑到这种 CUDA <> CPU 和 CPU <> CUDA 移动,在 NumPy 上下文中图中断的代价相当高,应该避免,但至少它们允许跟踪复杂代码片段。
如何在 torch.compile 下调试 NumPy 代码?¶
调试 JIT 编译的代码具有挑战性,因为现代编译器非常复杂且会引发令人沮丧的错误。torch.compile 故障排除文档包含一些关于如何解决此任务的技巧和窍门。
如果上述方法不足以确定问题的根源,我们仍然可以使用一些其他的 NumPy 特定工具。通过禁用对 NumPy 函数的跟踪,我们可以判断 bug 是否完全在 PyTorch 代码中:
from torch._dynamo import config
config.trace_numpy = False
如果 bug 存在于被跟踪的 NumPy 代码中,我们可以通过导入 import torch._numpy as np,使用 PyTorch 作为后端以 eager 模式执行 NumPy 代码(不使用 torch.compile)。此方法应仅用于调试目的,绝不能替代 PyTorch API,因为它性能差得多,并且作为私有 API,可能随时更改而恕不另行通知。无论如何,torch._numpy 是 NumPy 在 PyTorch 上的 Python 实现,torch.compile 在内部使用它将 NumPy 代码转换为 Pytorch 代码。它很容易阅读和修改,因此如果您在其中发现任何 bug,请随时提交 PR 修复它或直接开一个 issue。
如果导入 torch._numpy as np 后程序能够正常工作,那么 bug 很可能在 TorchDynamo 中。如果是这种情况,请随时使用 最小复现示例 提交 issue。
我对一些 NumPy 代码进行了 torch.compile,但没有看到任何加速。¶
最好的起点是提供调试此类 torch.compile 问题通用建议的教程。
一些图中断可能由于使用了不受支持的功能而发生。请参阅 torch.compile 支持哪些 NumPy 功能?。更普遍的是,记住一些广泛使用的 NumPy 功能与编译器配合不佳是很有用的。例如,就地修改使编译器中的推理变得困难,并且通常比非就地修改的性能更差。因此,最好避免它们。使用 out= 参数也是如此。相反,优先使用非就地操作,并让 torch.compile 优化内存使用。数据依赖操作(如通过布尔掩码进行掩码索引)或数据依赖控制流(如 if 或 while 结构)也是如此。
如何使用细粒度跟踪的 API?¶
在某些情况下,您可能需要从 torch.compile 编译中排除代码的小部分。本节提供了一些答案,您可以在 用于细粒度跟踪的 TorchDynamo API 中找到更多信息。
如何在函数上进行图中断?¶
在函数上进行图中断不足以充分表达您希望 PyTorch 执行的操作。您需要更具体地说明您的用例。以下是一些您可能想要考虑的最常见用例:
如果您想在此函数帧和递归调用的帧上禁用编译,请使用
torch._dynamo.disable。如果您想让特定操作符(例如
fbgemm)使用 eager 模式,请使用torch._dynamo.disallow_in_graph。
一些不常见用例包括:
如果您想在函数帧上禁用 TorchDynamo,但在递归调用的帧上重新启用它,请使用
torch._dynamo.disable(recursive=False)。如果您想阻止函数帧的内联,请在您想阻止内联的函数开头使用
torch._dynamo.graph_break。
torch._dynamo.disable 和 torch._dynamo.disallow_in_graph 之间有什么区别?¶
Disallow-in-graph 在操作符级别工作,更具体地说,是在您在 TorchDynamo 提取的图中看到的操作符级别工作。
Disable 在函数帧级别工作,并决定 TorchDynamo 是否应该查看该函数帧。
torch._dynamo.disable 和 torch._dynamo_skip 之间有什么区别?¶
注意
torch._dynamo_skip 已弃用。
您很可能需要 torch._dynamo.disable。但在极少数情况下,您可能需要更精细的控制。假设您只想在 a_fn 函数上禁用跟踪,但想在 aa_fn 和 ab_fn 中继续跟踪。下图展示了此用例:
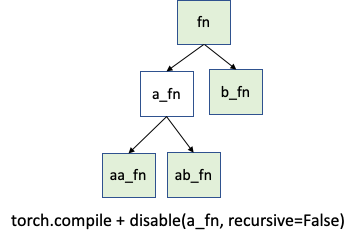
在这种情况下,您可以使用 torch._dynamo.disable(recursive=False)。在以前的版本中,此功能由 torch._dynamo.skip 提供。现在,torch._dynamo.disable 中的 recursive 标志支持此功能。
