理解基于 TorchDynamo 的 ONNX 导出器内存使用¶
之前的基于 TorchScript 的 ONNX 导出器会执行一次模型来跟踪其执行过程,如果模型的内存需求超过可用的 GPU 内存,可能会导致 GPU 内存不足。这个问题已通过新的基于 TorchDynamo 的 ONNX 导出器得到解决。
基于 TorchDynamo 的 ONNX 导出器利用 torch.export.export() 函数来利用 FakeTensorMode,从而避免在导出过程中执行实际的张量计算。与基于 TorchScript 的 ONNX 导出器相比,这种方法显著降低了内存使用量。
下面是一个示例,展示了基于 TorchScript 和基于 TorchDynamo 的 ONNX 导出器之间的内存使用差异。在此示例中,我们使用了 MONAI 中的 HighResNet 模型。在继续之前,请从 PyPI 安装它
pip install monai
PyTorch 提供了一个用于捕获和可视化内存使用跟踪的工具。我们将使用此工具记录两种导出器在导出过程中的内存使用情况并比较结果。您可以在理解 CUDA 内存使用上找到有关此工具的更多详细信息。
基于 TorchScript 的导出器¶
可以运行以下代码生成一个快照文件,该文件记录导出过程中已分配 CUDA 内存的状态。
import torch
from monai.networks.nets import (
HighResNet,
)
torch.cuda.memory._record_memory_history()
model = HighResNet(
spatial_dims=3, in_channels=1, out_channels=3, norm_type="batch"
).eval()
model = model.to("cuda")
data = torch.randn(30, 1, 48, 48, 48, dtype=torch.float32).to("cuda")
with torch.no_grad():
onnx_program = torch.onnx.export(
model,
data,
"torchscript_exporter_highresnet.onnx",
dynamo=False,
)
snapshot_name = "torchscript_exporter_example.pickle"
print(f"generate {snapshot_name}")
torch.cuda.memory._dump_snapshot(snapshot_name)
print("Export is done.")
打开 pytorch.org/memory_viz 并将生成的 pickled 快照文件拖放到可视化工具中。内存使用情况如下所示
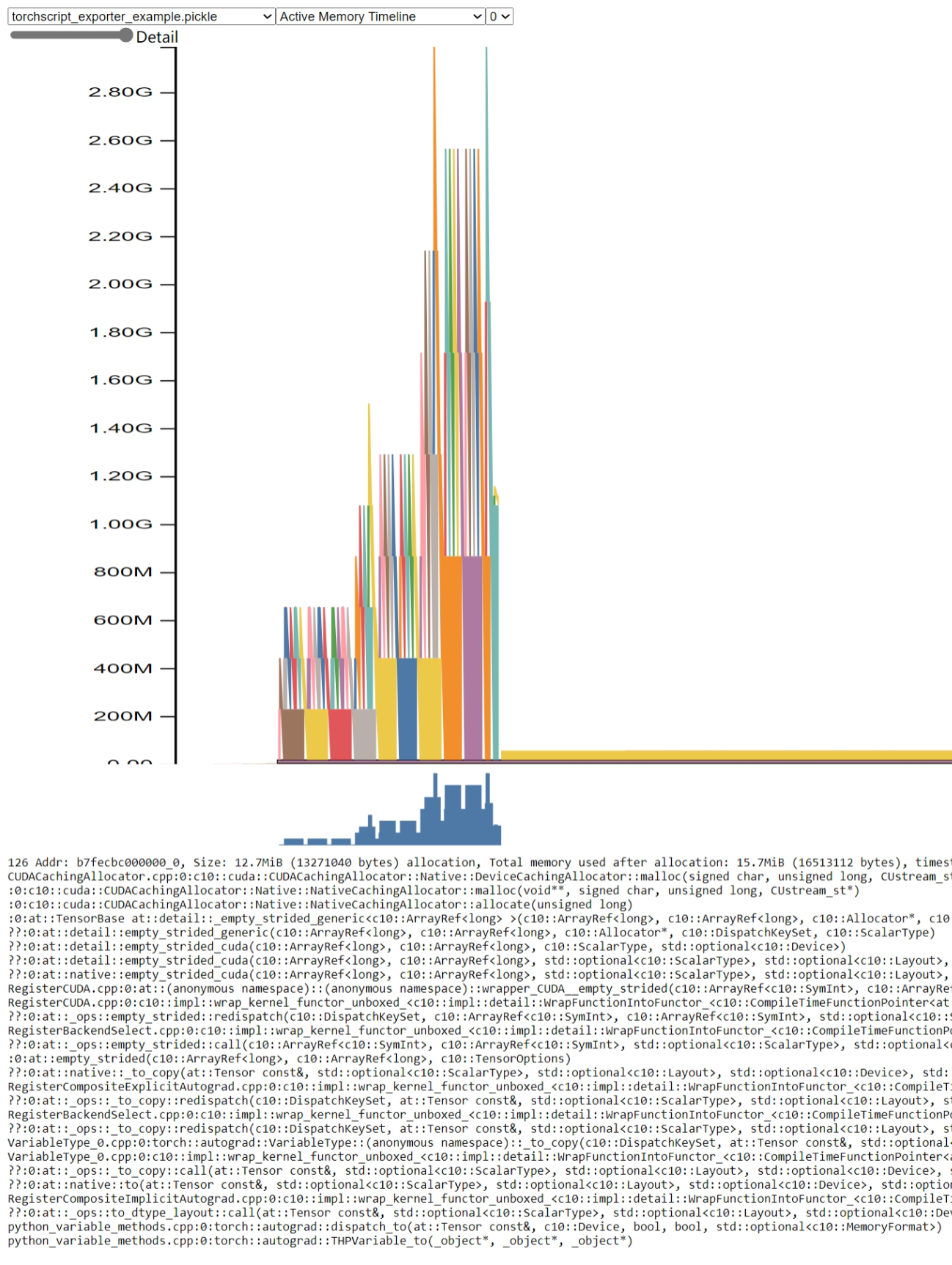
通过此图,我们可以看到内存使用峰值高于 2.8GB。
基于 TorchDynamo 的导出器¶
可以运行以下代码生成一个快照文件,该文件记录导出过程中已分配 CUDA 内存的状态。
import torch
from monai.networks.nets import (
HighResNet,
)
torch.cuda.memory._record_memory_history()
model = HighResNet(
spatial_dims=3, in_channels=1, out_channels=3, norm_type="batch"
).eval()
model = model.to("cuda")
data = torch.randn(30, 1, 48, 48, 48, dtype=torch.float32).to("cuda")
with torch.no_grad():
onnx_program = torch.onnx.export(
model,
data,
"test_faketensor.onnx",
dynamo=True,
)
snapshot_name = f"torchdynamo_exporter_example.pickle"
print(f"generate {snapshot_name}")
torch.cuda.memory._dump_snapshot(snapshot_name)
print(f"Export is done.")
打开 pytorch.org/memory_viz 并将生成的 pickled 快照文件拖放到可视化工具中。内存使用情况如下所示
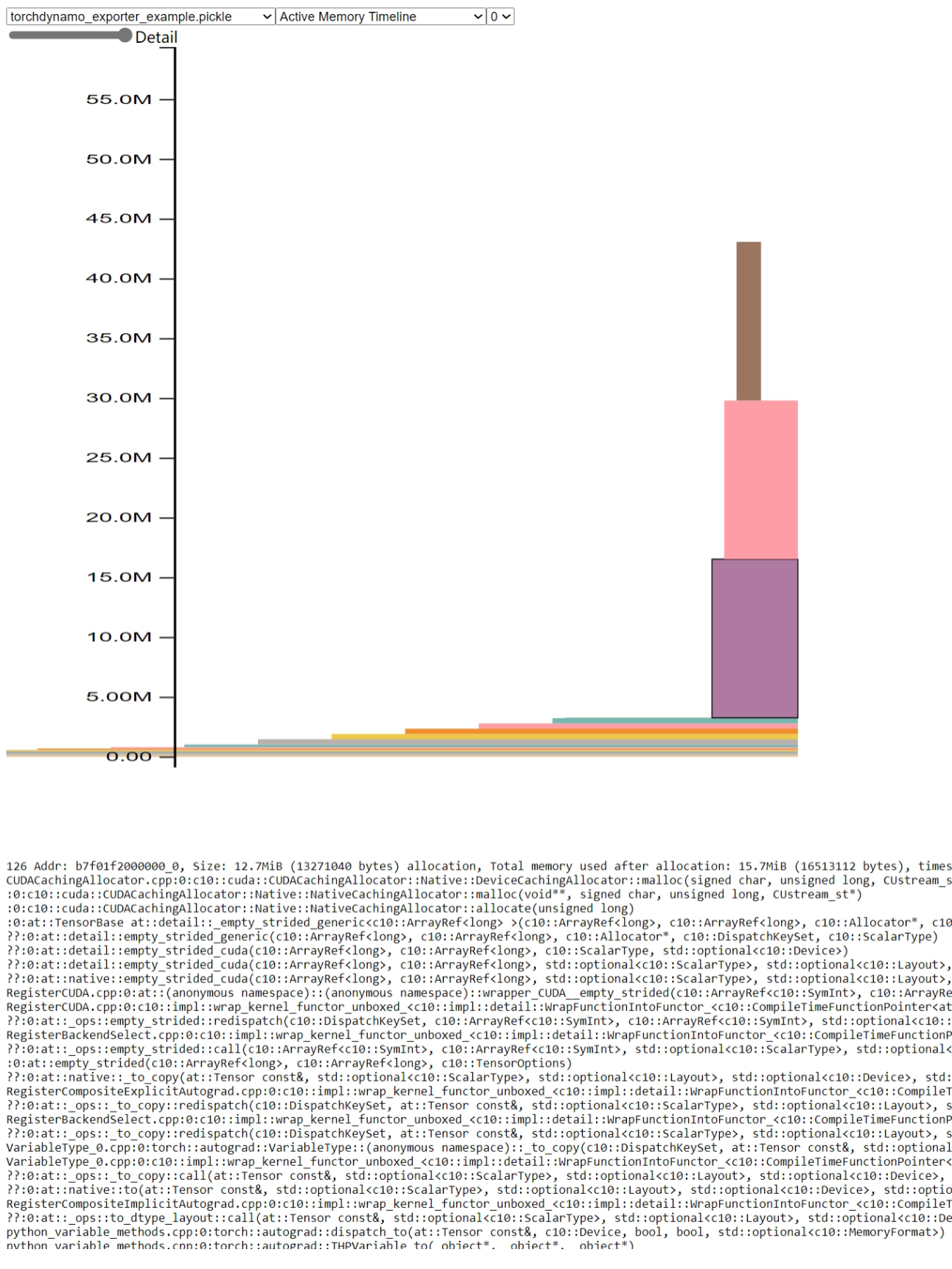
通过此图,我们可以看到内存使用峰值仅为约 45MB。与基于 TorchScript 的导出器内存使用峰值相比,它降低了 98% 的内存使用量。
