基于 TorchDynamo 的 ONNX Exporter¶
警告
TorchDynamo 的 ONNX exporter 是一项快速发展的 beta 技术。
概览¶
ONNX exporter 利用 TorchDynamo 引擎 Hook 进入 Python 的帧评估 API,并将其字节码动态重写为 FX Graph。然后对生成的 FX Graph 进行精炼,最后将其转换为 ONNX 图。
这种方法的主要优点是 FX 图 是通过字节码分析捕获的,它保留了模型的动态特性,而不是使用传统的静态追踪技术。
此外,在导出过程中,与启用 TorchScript 的 exporter 相比,内存使用量显著降低。更多信息请参阅内存使用文档。
依赖项¶
ONNX exporter 依赖于额外的 Python 包
它们可以通过 pip 安装
pip install --upgrade onnx onnxscript
然后可以使用 onnxruntime 在各种处理器上执行模型。
一个简单的例子¶
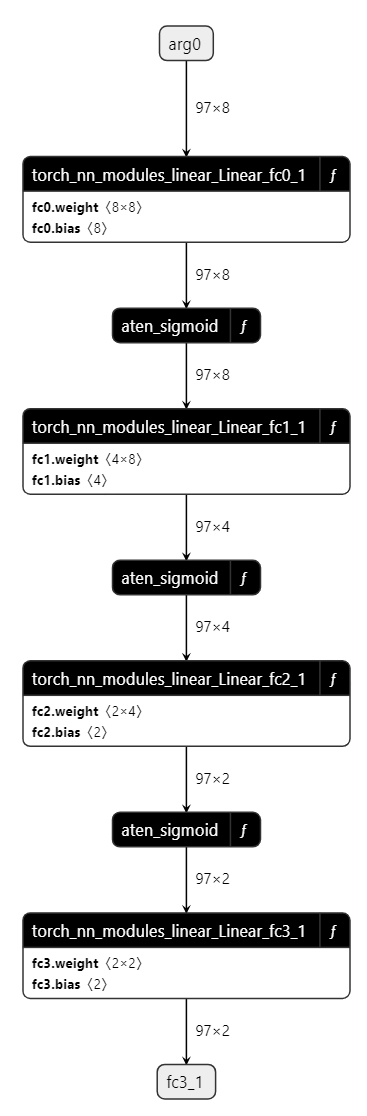
下面是一个使用简单的多层感知机 (MLP) 作为示例来演示 exporter API 的实际应用
import torch
import torch.nn as nn
class MLPModel(nn.Module):
def __init__(self):
super().__init__()
self.fc0 = nn.Linear(8, 8, bias=True)
self.fc1 = nn.Linear(8, 4, bias=True)
self.fc2 = nn.Linear(4, 2, bias=True)
self.fc3 = nn.Linear(2, 2, bias=True)
def forward(self, tensor_x: torch.Tensor):
tensor_x = self.fc0(tensor_x)
tensor_x = torch.sigmoid(tensor_x)
tensor_x = self.fc1(tensor_x)
tensor_x = torch.sigmoid(tensor_x)
tensor_x = self.fc2(tensor_x)
tensor_x = torch.sigmoid(tensor_x)
output = self.fc3(tensor_x)
return output
model = MLPModel()
tensor_x = torch.rand((97, 8), dtype=torch.float32)
onnx_program = torch.onnx.export(model, (tensor_x,), dynamo=True)
如上面的代码所示,您只需向 torch.onnx.export() 提供模型实例及其输入。Exporter 将返回一个 torch.onnx.ONNXProgram 实例,其中包含导出的 ONNX 图以及额外信息。
onnx_program.optimize() 可以用来优化 ONNX 图,执行常量折叠和冗余操作符消除。优化是就地完成的。
onnx_program.optimize()
通过 onnx_program.model_proto 获得的内存中的模型是一个符合 ONNX IR 规范的 onnx.ModelProto 对象。然后可以使用 torch.onnx.ONNXProgram.save() API 将 ONNX 模型序列化为 Protobuf 文件。
onnx_program.save("mlp.onnx")
存在两个基于 TorchDynamo 引擎将模型导出为 ONNX 的函数。它们在生成 torch.export.ExportedProgram 的方式上略有不同。torch.onnx.dynamo_export() 在 PyTorch 2.1 中引入,而 torch.onnx.export() 在 PyTorch 2.5 中进行了扩展,可以方便地从 TorchScript 切换到 TorchDynamo。要调用前者,可以将上一个示例的最后一行替换为以下代码。
注意
torch.onnx.dynamo_export() 将在未来弃用。请改用带有参数 dynamo=True 的 torch.onnx.export()。
onnx_program = torch.onnx.dynamo_export(model, tensor_x)
API 参考¶
- torch.onnx.dynamo_export(model, /, *model_args, export_options=None, **model_kwargs)[source][source]¶
将 torch.nn.Module 导出为 ONNX 图。
自版本 2.7 起已弃用: 请改用
torch.onnx.export(..., dynamo=True)。- 参数
model (torch.nn.Module | Callable | torch.export.ExportedProgram) – 要导出到 ONNX 的 PyTorch 模型。
model_args –
model的位置输入。model_kwargs –
model的关键字输入。export_options (ExportOptions | None) – 影响导出到 ONNX 的选项。
- 返回值
导出的 ONNX 模型的内存中表示。
- 返回类型
- class torch.onnx.ONNXProgram(model, exported_program)¶
一个类,表示可使用 torch 张量调用的 ONNX 程序。
- apply_weights(state_dict)[source][source]¶
将指定 state dict 中的权重应用于 ONNX 模型。
使用此方法替换 FakeTensors 或其他权重。
- 参数
state_dict (dict[str, torch.Tensor]) – 包含要应用于 ONNX 模型的权重的 state dict。
- compute_values(value_names, args=(), kwargs=None)[source][source]¶
计算 ONNX 模型中指定名称的值。
此方法用于计算 ONNX 模型中指定名称的值。值将作为名称到张量的字典返回。
- 参数
value_names (Sequence[str]) – 要计算的值的名称。
- 返回值
一个将名称映射到张量的字典。
- 返回类型
Sequence[torch.Tensor]
- initialize_inference_session(initializer=<function _ort_session_initializer>)[source][source]¶
初始化 ONNX Runtime 推理会话。
- property model_proto: ModelProto¶
返回 ONNX
ModelProto对象。
- save(destination, *, include_initializers=True, keep_initializers_as_inputs=False, external_data=None)[source][source]¶
将 ONNX 模型保存到指定的目标位置。
当
external_data为True或模型大于 2GB 时,权重将作为外部数据保存到单独的文件中。初始化器(模型权重)序列化行为:*
include_initializers=True,keep_initializers_as_inputs=False(默认):初始化器包含在保存的模型中。*include_initializers=True,keep_initializers_as_inputs=True:初始化器包含在保存的模型中,并保留为模型输入。如果您希望在推理期间能够覆盖模型权重,请选择此选项。*include_initializers=False,keep_initializers_as_inputs=False:初始化器不包含在保存的模型中,也不列为模型输入。如果您希望在单独的后处理步骤中将初始化器附加到 ONNX 模型,请选择此选项。*include_initializers=False,keep_initializers_as_inputs=True:初始化器不包含在保存的模型中,但列为模型输入。如果您希望在推理期间提供初始化器并最大程度地减小保存模型的大小,请选择此选项。- 参数
destination (str | os.PathLike) – 保存 ONNX 模型的路径。
include_initializers (bool) – 是否在保存的模型中包含初始化器。
keep_initializers_as_inputs (bool) – 是否在保存的模型中将初始化器保留为输入。如果为 True,初始化器将作为输入添加到模型中,这意味着可以通过提供初始化器作为模型输入来覆盖它们。
external_data (bool | None) – 是否将权重保存为单独文件中的外部数据。
- 引发
TypeError – 如果
external_data为True且destination不是文件路径。
- class torch.onnx.ExportOptions(*, dynamic_shapes=None, fake_context=None, onnx_registry=None, diagnostic_options=None)¶
影响 TorchDynamo ONNX exporter 的选项。
自版本 2.7 起已弃用: 请改用
torch.onnx.export(..., dynamo=True)。- 变量
dynamic_shapes (bool | None) – 输入/输出张量的形状信息提示。当为
None时,exporter 会确定最兼容的设置。当为True时,所有输入形状都被视为动态。当为False时,所有输入形状都被视为静态。diagnostic_options (DiagnosticOptions) – exporter 的诊断选项。
fake_context (ONNXFakeContext | None) – 用于符号追踪的 fake 上下文。
onnx_registry (OnnxRegistry | None) – 用于将 ATen 操作符注册到 ONNX 函数的 ONNX 注册表。
- torch.onnx.enable_fake_mode()[source]¶
在上下文期间启用 fake 模式。
它内部实例化一个
torch._subclasses.fake_tensor.FakeTensorMode上下文管理器,将用户输入和模型参数转换为torch._subclasses.fake_tensor.FakeTensor。一个
torch._subclasses.fake_tensor.FakeTensor是一个torch.Tensor,它能够在无需实际通过meta设备上分配的张量进行计算的情况下运行 PyTorch 代码。由于设备上没有分配实际数据,此 API 允许初始化和导出大型模型,而无需执行它所需的实际内存占用。强烈建议在导出过大而无法完全加载到内存中的模型时,在 fake 模式下初始化模型。
注意
此函数不支持 torch.onnx.export(…, dynamo=True, optimize=True)。请在模型导出后在函数外部调用 ONNXProgram.optimize()。
示例
# xdoctest: +REQUIRES(env:TORCH_DOCTEST_ONNX) >>> import torch >>> class MyModel(torch.nn.Module): # Model with a parameter ... def __init__(self) -> None: ... super().__init__() ... self.weight = torch.nn.Parameter(torch.tensor(42.0)) ... def forward(self, x): ... return self.weight + x >>> with torch.onnx.enable_fake_mode(): ... # When initialized in fake mode, the model's parameters are fake tensors ... # They do not take up memory so we can initialize large models ... my_nn_module = MyModel() ... arg1 = torch.randn(2, 2, 2) >>> onnx_program = torch.onnx.export(my_nn_module, (arg1,), dynamo=True, optimize=False) >>> # Saving model WITHOUT initializers (only the architecture) >>> onnx_program.save( ... "my_model_without_initializers.onnx", ... include_initializers=False, ... keep_initializers_as_inputs=True, ... ) >>> # Saving model WITH initializers after applying concrete weights >>> onnx_program.apply_weights({"weight": torch.tensor(42.0)}) >>> onnx_program.save("my_model_with_initializers.onnx")
警告
此 API 是实验性的,且不向后兼容。
- class torch.onnx.ONNXRuntimeOptions(*, session_options=None, execution_providers=None, execution_provider_options=None)¶
通过 ONNX Runtime 影响 ONNX 模型执行的选项。
自版本 2.7 起已弃用: 请改用
torch.onnx.export(..., dynamo=True)。
- class torch.onnx.OnnxExporterError¶
ONNX 导出器引发的错误。这是所有导出器错误的基类。
- class torch.onnx.OnnxRegistry¶
ONNX 函数的注册表。
自版本 2.7 起已弃用: 请改用
torch.onnx.export(..., dynamo=True)。该注册表维护了在固定 opset 版本下,从限定名称到符号函数的映射。它支持注册自定义 onnx-script 函数,并支持调度器将调用分派到适当的函数。
- get_op_functions(namespace, op_name, overload=None)[source][source]¶
返回给定操作 torch.ops.<namespace>.<op_name>.<overload> 的 ONNXFunction 列表。
该列表按注册时间排序。自定义操作应位于列表的后半部分。
- is_registered_op(namespace, op_name, overload=None)[source][source]¶
返回给定操作是否已注册:torch.ops.<namespace>.<op_name>.<overload>。
- register_op(function, namespace, op_name, overload=None, is_complex=False)[source][source]¶
注册自定义操作:torch.ops.<namespace>.<op_name>.<overload>。
- 参数
- 引发
ValueError – 如果名称格式不是 'namespace::op'。
