LayerNorm¶
- class torch.nn.LayerNorm(normalized_shape, eps=1e-05, elementwise_affine=True, bias=True, device=None, dtype=None)[source][source]¶
对输入 mini-batch 应用 Layer Normalization。
本层实现了论文 Layer Normalization 中描述的操作
均值和标准差是在最后 D 个维度上计算的,其中 D 是
normalized_shape的维度。例如,如果normalized_shape是(3, 5)(一个 2 维形状),则均值和标准差将在输入的最后 2 个维度(即input.mean((-2, -1)))上计算。 和 是normalized_shape的可学习仿射变换参数,如果elementwise_affine为True。方差通过有偏估计量计算,相当于 torch.var(input, unbiased=False)。注意
与 Batch Normalization 和 Instance Normalization 不同,后者使用
affine选项对每个整个通道/平面应用标量缩放和偏置,而 Layer Normalization 使用elementwise_affine应用逐元素的缩放和偏置。此层在训练和评估模式下都使用从输入数据计算出的统计量。
- 参数
normalized_shape (int or list or torch.Size) –
输入形状,期望的输入大小为
如果使用单个整数,则将其视为单元素列表,并且此模块将对最后一个维度进行归一化,该维度的预期大小即为此整数。
eps (float) – 添加到分母上的值,用于数值稳定性。默认值:1e-5
elementwise_affine (bool) – 一个布尔值,设置为
True时,此模块具有可学习的逐元素仿射参数,权重初始化为一,偏置初始化为零。默认值:True。bias (bool) – 如果设置为
False,此层将不学习加性偏置(仅在elementwise_affine为True时相关)。默认值:True。
- 变量
weight – 当
elementwise_affine设置为True时,模块的可学习权重,形状为 。这些值初始化为 1。bias – 当
elementwise_affine设置为True时,模块的可学习偏置,形状为 。这些值初始化为 0。
- 形状
输入:
输出: (与输入形状相同)
示例
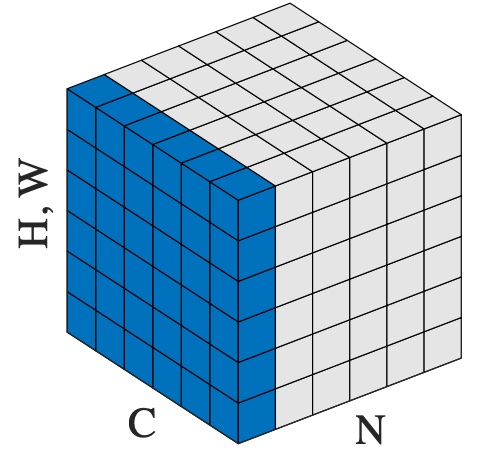
>>> # NLP Example >>> batch, sentence_length, embedding_dim = 20, 5, 10 >>> embedding = torch.randn(batch, sentence_length, embedding_dim) >>> layer_norm = nn.LayerNorm(embedding_dim) >>> # Activate module >>> layer_norm(embedding) >>> >>> # Image Example >>> N, C, H, W = 20, 5, 10, 10 >>> input = torch.randn(N, C, H, W) >>> # Normalize over the last three dimensions (i.e. the channel and spatial dimensions) >>> # as shown in the image below >>> layer_norm = nn.LayerNorm([C, H, W]) >>> output = layer_norm(input)