Rendezvous¶
在 Torch Distributed Elastic 的上下文中,我们使用术语 rendezvous 指代一种特定的功能,该功能结合了分布式同步原语和对等节点发现。
Torch Distributed Elastic 使用它来聚集训练作业的参与者(即节点),使它们都能就相同的参与者列表和每个参与者的角色达成一致,并在训练何时可以开始/恢复的问题上做出一致的集体决定。
Torch Distributed Elastic rendezvous 提供以下关键功能:
屏障 (Barrier):
执行 rendezvous 的节点都将阻塞,直到 rendezvous 被认为是完成的 - 这发生在至少有总数达到 min 个节点加入 rendezvous 屏障(针对同一个作业)时。这也意味着屏障的大小不一定是固定的。
达到 min 个节点后会有一个额外的短暂等待时间 - 这用于确保 rendezvous 不会“过快”完成(这可能会将同时尝试加入的其他节点排除在外)。
如果在屏障处聚集了 max 个节点,则 rendezvous 立即完成。
还有一个总体超时,如果 min 个节点始终未达到,则会导致 rendezvous 失败 - 这旨在作为一个简单的故障保护,以帮助释放部分分配的作业资源,以防资源管理器出现问题,并且应解释为不可重试。
排他性 (Exclusivity):
一个简单的分布式屏障是不够的,因为我们还需要确保在任何给定时间(对于给定作业)只存在一个节点组。换句话说,新节点(即延迟加入的节点)不应该能够为同一个作业形成一个并行独立的 worker 组。
Torch Distributed Elastic rendezvous 确保如果一个节点组已经完成了 rendezvous(因此可能已经在训练中),那么尝试进行 rendezvous 的其他“延迟”节点只会声明自己正在等待,并且必须等到(之前完成的)现有 rendezvous 首先被销毁。
一致性 (Consistency):
当 rendezvous 完成时,其所有成员将就作业成员资格以及每个成员在其中的角色达成一致。此角色由一个整数表示,称为 rank,其值介于 0 到 world size 之间。
请注意,rank 是不稳定的,这意味着同一个节点在下一次(重新)rendezvous 中可能会被分配不同的 rank。
容错性 (Fault-tolerance):
Torch Distributed Elastic rendezvous 设计用于在 rendezvous 过程中容忍节点故障。如果在加入 rendezvous 和 rendezvous 完成之间,一个进程崩溃(或丢失网络连接等),则会与剩余的健康节点自动重新进行 rendezvous。
一个节点也可能在完成 rendezvous 之后(或被其他节点观察到已经完成 rendezvous)失败 - 这种情况将由 Torch Distributed Elastic 的 train_loop 处理(其中也会触发重新 rendezvous)。
共享键值存储 (Shared key-value store):
当 rendezvous 完成时,会创建一个共享的键值存储并返回。该存储实现了 torch.distributed.Store API(请参阅分布式通信文档)。
此存储仅由已完成 rendezvous 的成员共享。它旨在由 Torch Distributed Elastic 用于交换初始化作业控制和数据平面所需的信息。
等待中的 worker 和 rendezvous 关闭:
Torch Distributed Elastic rendezvous handler 对象提供了附加功能,这些功能技术上不是 rendezvous 过程的一部分:
查询有多少 worker 延迟到达了屏障,他们可以参与下一次 rendezvous。
将 rendezvous 设置为closed,以向所有节点发出信号,表明不参与下一次 rendezvous。
DynamicRendezvousHandler:
Torch Distributed Elastic 提供 DynamicRendezvousHandler 类,该类实现了上述 rendezvous 机制。它是一个与后端无关的类型,期望在构建时指定一个特定的 RendezvousBackend 实例。
Torch 分布式用户可以实现自己的后端类型,也可以使用 PyTorch 提供的以下实现之一:
C10dRendezvousBackend: 使用 C10d store(默认为TCPStore)作为 rendezvous 后端。使用 C10d store 的主要优势是它无需第三方依赖(如 etcd)即可建立 rendezvous。EtcdRendezvousBackend: 取代了旧的EtcdRendezvousHandler类。将EtcdRendezvousBackend实例传递给DynamicRendezvousHandler功能上等同于实例化一个EtcdRendezvousHandler。store = TCPStore("localhost") backend = C10dRendezvousBackend(store, "my_run_id") rdzv_handler = DynamicRendezvousHandler.from_backend( run_id="my_run_id", store=store, backend=backend, min_nodes=2, max_nodes=4 )
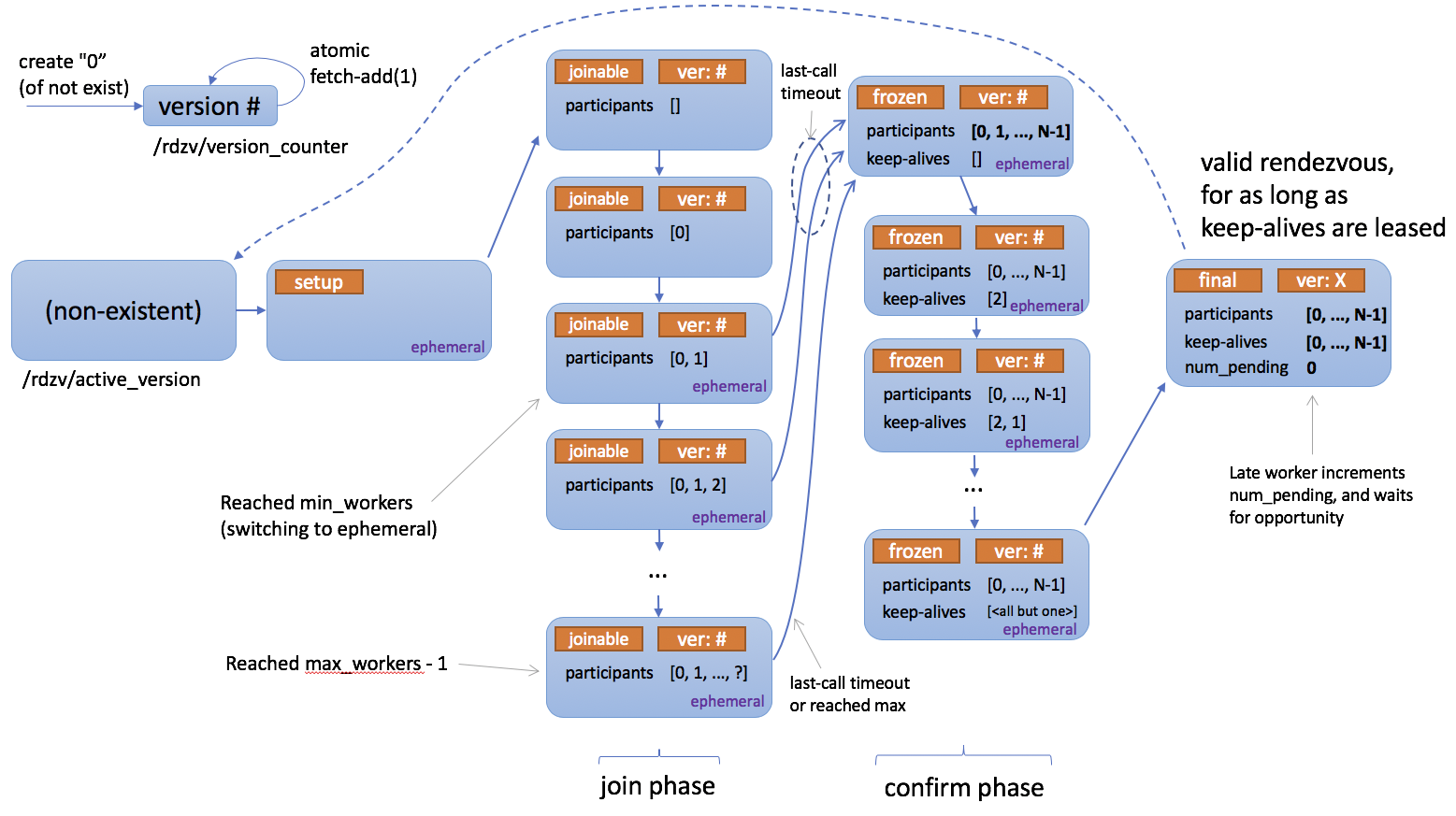
下面是描述 rendezvous 工作原理的状态图。
注册表 (Registry)¶
- class torch.distributed.elastic.rendezvous.RendezvousParameters(backend, endpoint, run_id, min_nodes, max_nodes, local_addr=None, **kwargs)[源代码][源代码]¶
保存构建
RendezvousHandler的参数。- 参数
- class torch.distributed.elastic.rendezvous.RendezvousHandlerRegistry[源代码][源代码]¶
表示
RendezvousHandler后端的注册表。
处理程序 (Handler)¶
- class torch.distributed.elastic.rendezvous.RendezvousHandler[源代码][源代码]¶
主要 rendezvous 接口。
注意
分布式 Torch 用户通常不需要实现自己的
RendezvousHandler。基于 C10d Store 的实现已经提供,建议大多数用户使用。- abstract get_run_id()[源代码][源代码]¶
返回 rendezvous 的运行 ID。
运行 ID 是一个用户定义的 ID,用于唯一标识分布式应用程序的实例。它通常映射到作业 ID,并用于允许节点加入正确的分布式应用程序。
- 返回类型
- abstract is_closed()[源代码][源代码]¶
检查 rendezvous 是否已关闭。
关闭的 rendezvous 意味着所有将来在同一作业中重新进行 rendezvous 的尝试都将失败。
is_closed()和set_closed()具有最终传播的语义,不应用于同步。其意图是,如果至少有一个节点决定作业完成,它将关闭 rendezvous,其他节点很快就会观察到这一点并停止运行。- 返回类型
- abstract next_rendezvous()[源代码][源代码]¶
rendezvous 屏障的主要入口点。
阻塞直到 rendezvous 完成并且当前进程包含在形成的 worker 组中,或者发生超时,或者 rendezvous 被标记为关闭。
- 返回
RendezvousInfo的实例。- 引发
RendezvousClosedError – Rendezvous 已关闭。
RendezvousConnectionError – 连接到 rendezvous 后端失败。
RendezvousStateError – Rendezvous 状态损坏。
RendezvousTimeoutError – Rendezvous 未按时完成。
- 返回类型
- abstract num_nodes_waiting()[源代码][源代码]¶
返回延迟到达 rendezvous 屏障因而未包含在当前 worker 组中的节点数量。
调用者应定期调用此方法检查是否有新节点正在等待加入作业,如果是,则通过调用
next_rendezvous()(重新 rendezvous) 允许它们加入。- 返回类型
- abstract shutdown()[源代码][源代码]¶
关闭为 rendezvous 打开的所有资源。
示例
rdzv_handler = ... try: store, rank, world_size = rdzv_handler.next_rendezvous() finally: rdzv_handler.shutdown()
- 返回类型
- property use_agent_store: bool¶
指示
next_rendezvous()返回的 store 引用可以与用户应用程序共享,并在应用程序生命周期中可用。Rendezvous handler 实现将以
RendezvousStoreInfo实例的形式共享 store 详细信息。应用程序习惯上使用 MASTER_ADDR/MASTER_PORT 环境变量来查找 store。
数据类 (Dataclasses)¶
- class torch.distributed.elastic.rendezvous.RendezvousInfo(store, rank, world_size, bootstrap_store_info)[源代码][源代码]¶
保存 rendezvous 相关信息。
异常 (Exceptions)¶
- class torch.distributed.elastic.rendezvous.api.RendezvousClosedError[源代码][源代码]¶
在 rendezvous 已关闭时引发。
- class torch.distributed.elastic.rendezvous.api.RendezvousTimeoutError[source][source]¶
当 rendezvous 未按时完成时引发此错误。
- class torch.distributed.elastic.rendezvous.api.RendezvousConnectionError[source][source]¶
当连接到 rendezvous 后端失败时引发此错误。
实现¶
动态 Rendezvous¶
- torch.distributed.elastic.rendezvous.dynamic_rendezvous.create_handler(store, backend, params)[source][source]¶
根据指定参数创建一个新的
DynamicRendezvousHandler实例。- 参数
store (Store) – 作为 rendezvous 的一部分返回的 C10d 存储实例。
backend (RendezvousBackend) – 用于存储 rendezvous 状态的后端实例。
- 返回类型
参数
描述
join_timeout
rendezvous 预期完成的总时间(以秒为单位)。默认为 600 秒。
last_call_timeout
达到最小节点数后,在完成 rendezvous 之前额外等待的时间(以秒为单位)。默认为 30 秒。
close_timeout
在调用
RendezvousHandler.set_closed()或RendezvousHandler.shutdown()后,rendezvous 预期在其中关闭的时间(以秒为单位)。默认为 30 秒。heartbeat
预期完成保活心跳的时间(以秒为单位)
- class torch.distributed.elastic.rendezvous.dynamic_rendezvous.DynamicRendezvousHandler[source][source]¶
表示一个负责在节点集合之间建立 rendezvous 的处理程序。
- classmethod from_backend(run_id, store, backend, min_nodes, max_nodes, local_addr=None, timeout=None, keep_alive_interval=5, keep_alive_max_attempt=3)[source][source]¶
创建一个新的
DynamicRendezvousHandler实例。- 参数
run_id (str) – rendezvous 的运行 ID。
store (Store) – 作为 rendezvous 的一部分返回的 C10d 存储实例。
backend (RendezvousBackend) – 用于存储 rendezvous 状态的后端实例。
min_nodes (int) – 允许加入 rendezvous 的最小节点数。
max_nodes (int) – 允许加入 rendezvous 的最大节点数。
timeout (Optional[RendezvousTimeout]) – rendezvous 的超时配置。
keep_alive_interval (int) – 节点在发送心跳以在 rendezvous 中保持活动状态之前等待的时间量。
keep_alive_max_attempt (int) – 节点在经历最大失败心跳尝试次数后被视为死亡。
- class torch.distributed.elastic.rendezvous.dynamic_rendezvous.RendezvousBackend[source][source]¶
表示一个存储 rendezvous 状态的后端实例。
- abstract get_state()[source][source]¶
获取 rendezvous 状态。
- 返回
一个元组,包含编码的 rendezvous 状态及其 fence token;如果后端中未找到状态,则为
None。- 引发
RendezvousConnectionError – 连接到后端失败。
RendezvousStateError – Rendezvous 状态损坏。
- 返回类型
- abstract set_state(state, token=None)[source][source]¶
设置 rendezvous 状态。
新 rendezvous 状态是条件性设置的
如果指定的
token与后端存储的 fence token 匹配,则状态将被更新。新状态将连同其 fence token 一起返回给调用者。如果指定的
token与后端存储的 fence token 不匹配,则状态将不会更新;取而代之的是,现有状态将连同其 fence token 一起返回给调用者。如果指定的
token是None,则仅在后端没有现有状态的情况下才会设置新状态。新状态或现有状态(连同其 fence token)将被返回给调用者。
- 参数
state (bytes) – 编码后的 rendezvous 状态。
token (Optional[Any]) – 通过之前调用
get_state()或set_state()获取的可选 fence token。
- 返回
一个元组,包含序列化的 rendezvous 状态、其 fence token 以及一个布尔值,指示我们的设置尝试是否成功。
- 引发
RendezvousConnectionError – 连接到后端失败。
RendezvousStateError – Rendezvous 状态损坏。
- 返回类型
- class torch.distributed.elastic.rendezvous.dynamic_rendezvous.RendezvousTimeout(join=None, last_call=None, close=None, heartbeat=None)[source][source]¶
保存 rendezvous 的超时配置。
C10d 后端¶
- torch.distributed.elastic.rendezvous.c10d_rendezvous_backend.create_backend(params)[source][source]¶
根据指定参数创建一个新的
C10dRendezvousBackend实例。参数
描述
store_type
C10d 存储的类型。目前支持的类型有 “tcp” 和 “file”,分别对应于
torch.distributed.TCPStore和torch.distributed.FileStore。默认为 “tcp”。read_timeout
存储操作的读取超时时间(以秒为单位)。默认为 60 秒。
注意:这仅适用于
torch.distributed.TCPStore。对于不接受 timeout 作为参数的torch.distributed.FileStore,它不相关。is_host
一个布尔值,指示此后端实例是否将托管 C10d 存储。如果未指定,将通过将本机的 hostname 或 IP 地址与指定的 rendezvous endpoint 进行匹配来启发式推断。默认为
None。请注意,此配置选项仅适用于
torch.distributed.TCPStore。在正常情况下可以安全地跳过它;仅当其值无法正确确定时才需要它(例如,rendezvous endpoint 的 hostname 是 CNAME 或与机器的 FQDN 不匹配)。
Etcd 后端¶
- torch.distributed.elastic.rendezvous.etcd_rendezvous_backend.create_backend(params)[source][source]¶
根据指定参数创建一个新的
EtcdRendezvousBackend实例。参数
描述
read_timeout
etcd 操作的读取超时时间(以秒为单位)。默认为 60 秒。
protocol
用于与 etcd 通信的协议。有效值为 “http” 和 “https”。默认为 “http”。
ssl_cert
与 HTTPS 一起使用的 SSL 客户端证书路径。默认为
None。ssl_cert_key
与 HTTPS 一起使用的 SSL 客户端证书私钥路径。默认为
None。ca_cert
根 SSL 颁发机构证书路径。默认为
None。
Etcd 会合(旧版)¶
警告
DynamicRendezvousHandler 类已取代 EtcdRendezvousHandler 类,推荐大多数用户使用前者。EtcdRendezvousHandler 已处于维护模式,将来会被弃用。
- class torch.distributed.elastic.rendezvous.etcd_rendezvous.EtcdRendezvousHandler(rdzv_impl, local_addr)[source][source]¶
实现了由
torch.distributed.elastic.rendezvous.etcd_rendezvous.EtcdRendezvous支持的torch.distributed.elastic.rendezvous.RendezvousHandler接口。EtcdRendezvousHandler使用 URL 来配置要使用的会合类型,并将特定于实现的配置传递给会合模块。基本的 etcd 会合配置 URL 如下所示:etcd://<etcd_address>:<port>/<job_id>?min_workers=<min_workers>&max_workers=<max_workers> # noqa: W605 -- example -- etcd://:2379/1234?min_workers=1&max_workers=3
上述 URL 的解释如下:
使用注册了
etcd方案的会合处理器要使用的
etcd端点是localhost:2379job_id == 1234在 etcd 中用作前缀(这允许多个作业共享一个共同的 etcd 服务器,只要job_ids保证唯一)。请注意,作业 ID 可以是任何字符串(例如,不一定是数字),只要它是唯一的。min_workers=1和max_workers=3指定了成员规模的范围 - Torch Distributed Elastic 只要集群规模大于或等于min_workers就会开始运行作业,并允许最多max_workers加入集群。
下面是可传递给 etcd 会合的完整参数列表:
参数
描述
min_workers
会合有效的最小工作进程数
max_workers
允许加入的最大工作进程数
timeout
next_rendezvous 预计成功的总超时时间(默认为 600 秒)
last_call_timeout
达到最小工作进程数后的额外等待时间(“最后召集”)(默认为 30 秒)
etcd_prefix
路径前缀(从 etcd 根目录开始),所有 etcd 节点都将在此路径下创建(默认为
/torchelastic/p2p)
Etcd 存储¶
EtcdStore 是当 etcd 用作会合后端时,由 next_rendezvous() 返回的 C10d Store 实例类型。
- class torch.distributed.elastic.rendezvous.etcd_store.EtcdStore(etcd_client, etcd_store_prefix, timeout=None)[source][source]¶
通过借用会合 etcd 实例来实现 c10 Store 接口。
这是由
EtcdRendezvous返回的存储对象。
Etcd 服务器¶
EtcdServer 是一个便捷类,使您能够轻松地在子进程中启动和停止 etcd 服务器。这对于测试或单节点(多工作进程)部署非常有用,在这种情况下,手动设置 etcd 服务器会很麻烦。
警告
对于生产环境和多节点部署,请考虑正确部署高可用的 etcd 服务器,因为这是您的分布式作业的单点故障。
- class torch.distributed.elastic.rendezvous.etcd_server.EtcdServer(data_dir=None)[source][source]¶
注意
在 etcd server v3.4.3 上测试通过。
在随机可用端口上启动和停止本地独立 etcd 服务器。对于单节点、多工作进程启动或测试很有用,在这种情况下,sidecar etcd 服务器比单独设置 etcd 服务器更方便。
此类注册了一个终止处理程序,用于在退出时关闭 etcd 子进程。此终止处理程序不能替代调用
stop()方法。使用以下回退机制来查找 etcd 二进制文件:
使用环境变量 TORCHELASTIC_ETCD_BINARY_PATH
如果存在,使用
<此文件根目录>/bin/etcd使用
PATH中的etcd
用法
server = EtcdServer("/usr/bin/etcd", 2379, "/tmp/default.etcd") server.start() client = server.get_client() # use client server.stop()
- 参数
etcd_binary_path – etcd 服务器二进制文件路径(有关回退路径,请参见上文)
