torchrl.data 包¶
重放缓冲区 (Replay Buffers)¶
重放缓冲区是非策略强化学习 (off-policy RL) 算法的核心组成部分。TorchRL 提供了一些常用重放缓冲区的高效实现。
|
一个通用的、可组合的重放缓冲区类。 |
|
优先重放缓冲区。 |
|
围绕 |
|
围绕 |
可组合重放缓冲区¶
我们还为用户提供了组合重放缓冲区的能力。我们提供了广泛的重放缓冲区使用解决方案,包括支持几乎任何数据类型;内存、设备或物理内存中的存储;多种采样策略;transforms 的使用等。
支持的数据类型和存储选择¶
理论上,重放缓冲区支持任何数据类型,但我们无法保证每个组件都支持任何数据类型。最原始的重放缓冲区实现是由一个 ReplayBuffer 基类和一个 ListStorage 存储组成。这种方式效率非常低,但允许你存储包含非 tensor 数据的复杂数据结构。连续内存中的存储包括 TensorStorage、LazyTensorStorage 和 LazyMemmapStorage。这些类将 TensorDict 数据作为一等公民支持,但也支持任何 PyTree 数据结构(例如,元组、列表、字典及其嵌套版本)。TensorStorage 存储要求你在构建时提供存储,而 TensorStorage(RAM,CUDA)和 LazyMemmapStorage(物理内存)在首次扩展后会为你预分配存储。
以下是一些示例,从通用的 ListStorage 开始
>>> from torchrl.data.replay_buffers import ReplayBuffer, ListStorage
>>> rb = ReplayBuffer(storage=ListStorage(10))
>>> rb.add("a string!") # first element will be a string
>>> rb.extend([30, None]) # element [1] is an int, [2] is None
写入缓冲区的主要入口点是 add() 和 extend()。也可以使用 __setitem__(),在这种情况下,数据会按指示写入,而不会更新缓冲区的长度或游标。这在从缓冲区中采样项目并在之后原地更新其值时非常有用。
使用 TensorStorage 时,我们告诉 RB 我们希望存储是连续的,这无疑效率更高,但也更具限制性。
>>> import torch
>>> from torchrl.data.replay_buffers import ReplayBuffer, TensorStorage
>>> container = torch.empty(10, 3, 64, 64, dtype=torch.unit8)
>>> rb = ReplayBuffer(storage=TensorStorage(container))
>>> img = torch.randint(255, (3, 64, 64), dtype=torch.uint8)
>>> rb.add(img)
接下来,我们可以避免创建容器,并让存储自动创建它。这在使用 PyTrees 和 tensordicts 时非常有用!对于 PyTrees 等数据结构,add() 将传递给它的样本视为该类型的单个实例。extend() 则会将数据视为一个可迭代对象。对于 tensors、tensordicts 和列表(见下文),可迭代对象会在根级别查找。对于 PyTrees,我们假设树中所有叶子(tensors)的前导维度是匹配的。如果不匹配,extend 将抛出异常。
>>> import torch
>>> from tensordict import TensorDict
>>> from torchrl.data.replay_buffers import ReplayBuffer, LazyMemmapStorage
>>> rb_td = ReplayBuffer(storage=LazyMemmapStorage(10), batch_size=1) # max 10 elements stored
>>> rb_td.add(TensorDict({"img": torch.randint(255, (3, 64, 64), dtype=torch.unit8),
... "labels": torch.randint(100, ())}, batch_size=[]))
>>> rb_pytree = ReplayBuffer(storage=LazyMemmapStorage(10)) # max 10 elements stored
>>> # extend with a PyTree where all tensors have the same leading dim (3)
>>> rb_pytree.extend({"a": {"b": torch.randn(3), "c": [torch.zeros(3, 2), (torch.ones(3, 10),)]}})
>>> assert len(rb_pytree) == 3 # the replay buffer has 3 elements!
注意
extend() 在处理值列表时可能存在签名模糊,这应该被解释为 PyTree(在这种情况下,列表中的所有元素将被放入存储中保存的 PyTree 的一个切片中),或被解释为需要逐个添加的值列表。为了解决这个问题,TorchRL 在 list 和 tuple 之间做了明确的区分:tuple 将被视为一个 PyTree,而列表(在根级别)将被解释为需要逐个添加到缓冲区的值栈。
采样和索引¶
重放缓冲区可以被索引和采样。索引和采样会在存储中的给定索引处收集数据,然后通过一系列 transforms 和 collate_fn 进行处理,这些可以传递给重放缓冲区的 __init__ 函数。collate_fn 带有默认值,这些默认值在大多数情况下应与用户的预期相符,因此大多数时候你无需为此担心。Transforms 通常是 Transform 的实例,尽管常规函数也可以工作(在后一种情况下,inv() 方法显然会被忽略,而在前一种情况下,它可用于在数据传递到缓冲区之前进行预处理)。最后,可以通过将线程数通过 prefetch 关键字参数传递给构造函数来使用多线程实现采样。我们建议用户在实际设置中对这项技术进行基准测试后再采用,因为不能保证它在实践中一定能带来更快的吞吐量,这取决于使用的机器和设置。
采样时,batch_size 可以在构建时传递(例如,如果在整个训练过程中保持不变),也可以传递给 sample() 方法。
为了进一步细化采样策略,我们建议你查看我们的 samplers!
以下是一些从重放缓冲区获取数据的示例
>>> first_elt = rb_td[0]
>>> storage = rb_td[:] # returns all valid elements from the buffer
>>> sample = rb_td.sample(128)
>>> for data in rb_td: # iterate over the buffer using the sampler -- batch-size was set in the constructor to 1
... print(data)
使用以下组件
|
以紧凑形式保存存储,节省 TED 格式的空间。 |
|
以紧凑形式保存存储,节省 TED 格式的空间,并使用 H5 格式保存数据。 |
|
用于不可变数据集的阻塞写入器。 |
|
用于 tensors 和 tensordicts 的内存映射存储。 |
|
用于 tensors 和 tensordicts 的预分配 tensor 存储。 |
|
存储在列表中的存储。 |
|
返回 LazyStackTensorDict 实例的 ListStorage。 |
用于 ListStorage 的存储检查点。 |
|
|
以紧凑形式保存存储,节省 TED 格式的空间,并使用内存映射嵌套 tensors。 |
|
重放缓冲区的优先采样器。 |
|
根据开始和停止信号,沿第一个维度采样数据切片,使用优先采样。 |
可组合重放缓冲区的均匀随机采样器。 |
|
|
可组合重放缓冲区的 RoundRobin 写入器类。 |
|
可组合重放缓冲区的通用采样器基类。 |
|
一种消耗数据的采样器,确保同一样本不会出现在连续的批次中。 |
|
根据开始和停止信号,沿第一个维度采样数据切片。 |
|
根据开始和停止信号,沿第一个维度进行无放回采样数据切片。 |
|
Storage 是重放缓冲区的容器。 |
存储检查点器的公共基类。 |
|
集合存储的检查点器。 |
|
|
可组合重放缓冲区的写入器类,根据某个排名键保留顶部元素。 |
|
可组合的、基于 tensordict 的重放缓冲区的 RoundRobin 写入器类。 |
|
用于 tensors 和 tensordicts 的存储。 |
用于 TensorStorages 的存储检查点。 |
|
|
重放缓冲区基础写入器类。 |
存储选择对重放缓冲区的采样延迟影响很大,尤其是在数据量较大的分布式强化学习设置中。LazyMemmapStorage 在具有共享存储的分布式设置中非常推荐,因为它具有较低的 MemoryMappedTensors 序列化开销,并且能够指定文件存储位置以改善节点故障恢复。在 https://github.com/pytorch/rl/tree/main/benchmarks/storage 的粗略基准测试中,发现了相对于使用 ListStorage 的以下平均采样延迟改进。
存储类型 |
加速比 |
|---|---|
1倍 |
|
1.83倍 |
|
3.44倍 |
存储轨迹¶
将轨迹存储在重放缓冲区中并不太困难。需要注意的一点是,重放缓冲区的大小默认是存储前导维度的大小:换句话说,当存储多维数据时,创建一个大小为 1M 的存储重放缓冲区并不意味着存储 1M 帧,而是 1M 条轨迹。然而,如果轨迹(或 episode/rollout)在存储前被展平,容量仍将是 1M 步。
有一种方法可以规避这个问题,即告诉存储在保存数据时应该考虑多少个维度。这可以通过 ndim 关键字参数来实现,所有连续存储(如 TensorStorage 等)都接受此参数。当多维存储传递给缓冲区时,缓冲区会自动将最后一个维度视为“时间”维度,这在 TorchRL 中是惯例。这可以通过 ReplayBuffer 中的 dim_extend 关键字参数来覆盖。这是保存通过 ParallelEnv 或其串行对应项获得的轨迹的推荐方法,我们将在下文看到。
采样轨迹时,可能需要采样子轨迹以使学习多样化或提高采样效率。TorchRL 提供了两种独特的方法来实现这一点
通过
SliceSampler可以采样存储在TensorStorage前导维度中,一个接一个排列的轨迹的指定数量的切片。这是 TorchRL 中采样子轨迹的推荐方法,__尤其是在使用离线数据集__(使用该约定存储)时。此策略要求在扩展重放缓冲区之前展平轨迹,并在采样后重塑它们。SliceSampler类的文档字符串提供了关于此存储和采样策略的详细信息。请注意,SliceSampler与多维存储兼容。以下示例展示了如何使用此功能,以及是否对 tensordict 进行展平。在第一个场景中,我们从单个环境收集数据。在这种情况下,我们很高兴使用一个沿第一个维度连接传入数据的存储,因为收集计划不会引入中断。>>> from torchrl.envs import TransformedEnv, StepCounter, GymEnv >>> from torchrl.collectors import SyncDataCollector, RandomPolicy >>> from torchrl.data import ReplayBuffer, LazyTensorStorage, SliceSampler >>> env = TransformedEnv(GymEnv("CartPole-v1"), StepCounter()) >>> collector = SyncDataCollector(env, ... RandomPolicy(env.action_spec), ... frames_per_batch=10, total_frames=-1) >>> rb = ReplayBuffer( ... storage=LazyTensorStorage(100), ... sampler=SliceSampler(num_slices=8, traj_key=("collector", "traj_ids"), ... truncated_key=None, strict_length=False), ... batch_size=64) >>> for i, data in enumerate(collector): ... rb.extend(data) ... if i == 10: ... break >>> assert len(rb) == 100, len(rb) >>> print(rb[:]["next", "step_count"]) tensor([[32], [33], [34], [35], [36], [37], [38], [39], [40], [41], [11], [12], [13], [14], [15], [16], [17], [...
如果在一个批次中运行了多个环境,我们仍然可以通过调用
data.reshape(-1)将大小为[B, T]的数据展平为[B * T],并像之前一样存储在同一个缓冲区中,但这会意味着批次中第一个环境的轨迹将与其他环境的轨迹交错,SliceSampler无法处理这种情况。为了解决这个问题,我们建议在存储构造函数中使用ndim参数。>>> env = TransformedEnv(SerialEnv(2, ... lambda: GymEnv("CartPole-v1")), StepCounter()) >>> collector = SyncDataCollector(env, ... RandomPolicy(env.action_spec), ... frames_per_batch=1, total_frames=-1) >>> rb = ReplayBuffer( ... storage=LazyTensorStorage(100, ndim=2), ... sampler=SliceSampler(num_slices=8, traj_key=("collector", "traj_ids"), ... truncated_key=None, strict_length=False), ... batch_size=64) >>> for i, data in enumerate(collector): ... rb.extend(data) ... if i == 100: ... break >>> assert len(rb) == 100, len(rb) >>> print(rb[:]["next", "step_count"].squeeze()) tensor([[ 6, 5], [ 2, 2], [ 3, 3], [ 4, 4], [ 5, 5], [ 6, 6], [ 7, 7], [ 8, 8], [ 9, 9], [10, 10], [11, 11], [12, 12], [13, 13], [14, 14], [15, 15], [16, 16], [17, 17], [18, 1], [19, 2], [...
轨迹也可以独立存储,前导维度的每个元素指向不同的轨迹。这要求轨迹具有一致的形状(或进行填充)。我们提供了一个名为
RandomCropTensorDict的自定义Transform类,它允许在缓冲区中采样子轨迹。请注意,与基于SliceSampler的策略不同,这里不需要有一个指向开始和停止信号的"episode"或"done"键。以下是此类的使用示例
重放缓冲区检查点¶
重放缓冲区的每个组件可能是有状态的,因此需要一种专门的方法来对其进行序列化。我们的重放缓冲区提供了两个独立的 API 用于将其状态保存到磁盘:dumps() 和 loads() 将使用内存映射 tensors 和 json 文件保存除 transforms 外的每个组件(存储、写入器、采样器)的数据和元数据。
这适用于除 ListStorage 之外的所有类,因为其内容无法预测(因此不符合 tensordict 库中可以找到的内存映射数据结构)。
此 API 保证保存后重新加载的缓冲区将处于完全相同的状态,无论我们查看其采样器(例如,优先树)、写入器(例如,最大写入堆)或存储的状态如何。
在底层,对 dumps() 的简单调用将仅调用其每个组件(transforms 除外,我们通常不假设它们可以使用内存映射 tensors 进行序列化)在特定文件夹中的公共 dumps 方法。
然而,以 TED 格式保存数据可能会消耗比所需更多的内存。如果连续的轨迹存储在缓冲区中,我们可以通过保存根级别所有 observation 以及仅保存“next”子 tensordict 中 observation 的最后一个元素来避免保存重复的 observation,这可以将存储消耗减少多达两倍。为了实现这一点,提供了三种检查点类:FlatStorageCheckpointer 将丢弃重复的 observation 以压缩 TED 格式。在加载时,此类将以正确格式重新写入 observation。如果缓冲区保存到磁盘,此检查点执行的操作将不需要任何额外的 RAM。NestedStorageCheckpointer 将使用嵌套 tensors 保存轨迹,以使数据表示更明显(沿第一个维度的每个项目代表一个不同的轨迹)。最后,H5StorageCheckpointer 将以 H5DB 格式保存缓冲区,使用户能够压缩数据并节省更多空间。
警告
检查点对经验回放缓冲区做了一些限制性假设。首先,假设 done 状态准确表示轨迹的结束(除了正在写入的最后一条轨迹,其写入游标指示截断信号应放置的位置)。对于 MARL 用法,需要注意的是,只允许 done 状态具有与根 Tensordict 相同数量的元素:如果 done 状态具有存储的批量大小中未表示的额外元素,这些检查点将失败。例如,在形状为 torch.Size([3, 4]) 的存储中,不允许形状为 torch.Size([3, 4, 5]) 的 done 状态。
下面是如何在实践中使用 H5DB 检查点的具体示例
>>> from torchrl.data import ReplayBuffer, H5StorageCheckpointer, LazyMemmapStorage
>>> from torchrl.collectors import SyncDataCollector
>>> from torchrl.envs import GymEnv, SerialEnv
>>> import torch
>>> env = SerialEnv(3, lambda: GymEnv("CartPole-v1", device=None))
>>> env.set_seed(0)
>>> torch.manual_seed(0)
>>> collector = SyncDataCollector(
>>> env, policy=env.rand_step, total_frames=200, frames_per_batch=22
>>> )
>>> rb = ReplayBuffer(storage=LazyMemmapStorage(100, ndim=2))
>>> rb_test = ReplayBuffer(storage=LazyMemmapStorage(100, ndim=2))
>>> rb.storage.checkpointer = H5StorageCheckpointer()
>>> rb_test.storage.checkpointer = H5StorageCheckpointer()
>>> for i, data in enumerate(collector):
... rb.extend(data)
... assert rb._storage.max_size == 102
... rb.dumps(path_to_save_dir)
... rb_test.loads(path_to_save_dir)
... assert_allclose_td(rb_test[:], rb[:])
每当无法使用 dumps() 保存数据时,另一种方法是使用 state_dict(),它返回一个可以使用 torch.save() 保存,然后在使用 load_state_dict() 之前使用 torch.load() 加载的数据结构。这种方法的缺点是很难保存大型数据结构,这在使用经验回放缓冲区时是一个常见情况。
TorchRL 幕数据格式 (TED)¶
在 TorchRL 中,序列数据始终以特定格式呈现,称为 TorchRL 幕数据格式 (TED)。这种格式对于 TorchRL 中各种组件的无缝集成和运行至关重要。
某些组件,例如经验回放缓冲区,对数据格式有些不敏感。然而,其他组件,特别是环境,则高度依赖于它以实现平稳运行。
因此,了解 TED、其用途以及如何与其交互至关重要。本指南将清晰解释 TED、为何使用它以及如何有效地与其协作。
TED 背后的原理¶
格式化序列数据可能是一项复杂的任务,尤其是在强化学习 (RL) 领域。作为实践者,我们经常遇到在重置时(尽管并非总是如此)交付数据的情况,有时数据会在轨迹的最后一步提供或丢弃。
这种可变性意味着我们可以在数据集中观察到不同长度的数据,并且并不总是立即清楚如何匹配此数据集各种元素中的每个时间步。考虑以下模糊的数据集结构
>>> observation.shape
[200, 3]
>>> action.shape
[199, 4]
>>> info.shape
[200, 3]
乍一看,似乎 info 和 observation 是同时交付的(重置时各有一次 + 每次 step 调用时各有一次),正如 action 元素少一个所暗示的那样。然而,如果 info 元素少一个,我们必须假设它要么在重置时被省略,要么在轨迹的最后一步未交付或未记录。如果没有适当的数据结构文档,就无法确定哪个 info 对应哪个时间步。
更复杂的是,某些数据集提供的数据格式不一致,其中 observations 或 infos 在 rollout 的开始或结束时缺失,并且这种行为通常没有文档说明。TED 的主要目标是通过提供清晰一致的数据表示来消除这些歧义。
TED 的结构¶
TED 构建在 RL 上下文中马尔可夫决策过程 (MDP) 的规范定义之上。在每一步中,一个 observation 条件化一个 action,该 action 会产生 (1) 一个新的 observation,(2) 一个任务完成指示器(终止、截断、完成),以及 (3) 一个奖励信号。
某些元素可能缺失(例如,奖励在模仿学习上下文中是可选的),或者可以通过状态或信息容器传递附加信息。在某些情况下,为了在调用 step 期间获取 observation,需要附加信息(例如,在无状态环境模拟器中)。此外,在某些场景中,“action”(或任何其他数据)无法表示为单个张量,需要以不同方式组织。例如,在多智能体强化学习设置中,actions、observations、rewards 和完成信号可能是复合的。
TED 以单一、统一、明确的格式适应所有这些场景。我们通过设定 action 执行的时间来区分时间步 t 和 t+1 之间发生的事情。换句话说,在调用 env.step 之前存在的一切都属于 t,而之后的一切都属于 t+1。
一般规则是,属于时间步 t 的所有内容都存储在 Tensordict 的根目录中,而属于 t+1 的所有内容都存储在 Tensordict 的 "next" 条目中。这里有一个例子
>>> data = env.reset()
>>> data = policy(data)
>>> print(env.step(data))
TensorDict(
fields={
action: Tensor(...), # The action taken at time t
done: Tensor(...), # The done state when the action was taken (at reset)
next: TensorDict( # all of this content comes from the call to `step`
fields={
done: Tensor(...), # The done state after the action has been taken
observation: Tensor(...), # The observation resulting from the action
reward: Tensor(...), # The reward resulting from the action
terminated: Tensor(...), # The terminated state after the action has been taken
truncated: Tensor(...), # The truncated state after the action has been taken
batch_size=torch.Size([]),
device=cpu,
is_shared=False),
observation: Tensor(...), # the observation at reset
terminated: Tensor(...), # the terminated at reset
truncated: Tensor(...), # the truncated at reset
batch_size=torch.Size([]),
device=cpu,
is_shared=False)
在 rollout 期间(使用 EnvBase 或 SyncDataCollector),当智能体重置其步数计数时,"next" Tensordict 的内容会通过 step_mdp() 函数被带到根目录:t <- t+1。您可以在这里阅读有关环境 API 的更多信息。
在大多数情况下,根目录没有值为 True 的 "done" 状态,因为任何 done 状态都会触发(部分)重置,这将使 "done" 变为 False。然而,这只有在自动执行重置的情况下才成立。在某些情况下,部分重置不会触发重置,因此我们保留这些数据,这些数据应该比 observations 等具有显着低的内存占用。
这种格式消除了 observation 与其 action、info 或 done 状态匹配的任何歧义。
关于 TED 中单例维度的说明¶
在 TorchRL 中,标准做法是 done 状态(包括 terminated 和 truncated)和奖励应具有一个维度,该维度可以扩展以匹配 observations、states 和 actions 的形状,而无需借助重复以外的任何操作(即,奖励必须与 observation 和/或 action 或它们的嵌入具有相同数量的维度)。
本质上,这种格式是可接受的(尽管并非严格强制执行)
>>> print(rollout[t])
... TensorDict(
... fields={
... action: Tensor(n_action),
... done: Tensor(1), # The done state has a rightmost singleton dimension
... next: TensorDict(
... fields={
... done: Tensor(1),
... observation: Tensor(n_obs),
... reward: Tensor(1), # The reward has a rightmost singleton dimension
... terminated: Tensor(1),
... truncated: Tensor(1),
... batch_size=torch.Size([]),
... device=cpu,
... is_shared=False),
... observation: Tensor(n_obs), # the observation at reset
... terminated: Tensor(1), # the terminated at reset
... truncated: Tensor(1), # the truncated at reset
... batch_size=torch.Size([]),
... device=cpu,
... is_shared=False)
这样做的原因是为了确保对 observations 和/或 actions 进行操作(例如价值估计)的结果与奖励和 done 状态具有相同的维度数量。这种一致性使得后续操作能够顺利进行
>>> state_value = f(observation)
>>> next_state_value = state_value + reward
如果没有奖励末尾的这个单例维度,广播规则(仅当张量可以从左侧扩展时才起作用)会尝试从左侧扩展奖励。这可能导致失败(最好情况)或引入错误(最坏情况)。
展平 TED 以减少内存消耗¶
TED 在内存中复制 observation 两次,这可能会影响在实践中使用此格式的可行性。由于它主要用于方便表示,因此可以以扁平方式存储数据,但在训练期间将其表示为 TED。
这在序列化经验回放缓冲区时特别有用:例如,TED2Flat 类确保在写入磁盘之前将 TED 格式的数据结构展平,而 Flat2TED 加载钩子将在反序列化期间对该结构进行解展平。
Tensordict 的维度¶
在 rollout 期间,所有收集到的 Tensordicts 将沿末尾新增的维度堆叠。收集器和环境都将使用 "time" 名称标记此维度。这里有一个例子
>>> rollout = env.rollout(10, policy)
>>> assert rollout.shape[-1] == 10
>>> assert rollout.names[-1] == "time"
这确保了时间维度在数据结构中被清晰标记且易于识别。
特殊情况和脚注¶
多智能体数据表示¶
多智能体数据格式文档可在多智能体强化学习环境 API 部分访问。
基于记忆的策略(RNNs 和 Transformers)¶
在上面提供的示例中,只有 env.step(data) 生成需要在下一步读取的数据。然而,在某些情况下,策略也会输出需要在下一步使用的信息。这通常是基于 RNN 的策略的情况,它们输出一个 action 以及需要在下一步使用的循环状态。为了适应这种情况,我们建议用户调整其 RNN 策略,将这些数据写入 Tensordict 的 "next" 条目下。这确保了该内容将在下一步被带到根目录。更多信息可在 GRUModule 和 LSTMModule 中找到。
多步¶
收集器允许用户在读取数据时跳过步骤,累积未来 n 个步骤的奖励。这种技术在类似 DQN 的算法(如 Rainbow)中很受欢迎。MultiStep 类对从收集器出来的批次执行此数据转换。在这些情况下,由于下一个 observation 偏移了 n 个步骤,如下所示的检查将失败
>>> assert (data[..., 1:]["observation"] == data[..., :-1]["next", "observation"]).all()
内存需求如何?¶
天真地实现此数据格式会消耗大约扁平表示的两倍内存。在某些内存密集型设置中(例如,在 AtariDQNExperienceReplay 数据集中),我们仅在磁盘上存储 T+1 observation,并在获取时在线执行格式化。在其他情况下,我们假设 2 倍内存成本是一个小代价,以便获得更清晰的表示。然而,推广离线数据集的惰性表示肯定会是一个有益的功能,我们欢迎在这方面的贡献!
数据集¶
TorchRL 提供对离线强化学习数据集的包装器。这些数据表示为 ReplayBuffer 实例,这意味着它们可以使用 transforms、samplers 和 storages 随意自定义。例如,可以使用 SelectTransform 或 ExcludeTransform 从数据集中过滤出或过滤进条目。
默认情况下,数据集存储为内存映射张量,允许它们快速采样,几乎没有内存占用。
这里有一个例子
注意
安装依赖项是用户的责任。对于 D4RL,需要克隆此仓库,因为最新的 wheel 包未发布在 PyPI 上。对于 OpenML,需要 scikit-learn 和 pandas。
转换数据集¶
在许多情况下,原始数据不会原样使用。自然的解决方案可能是将 Transform 实例传递给数据集构造函数,并在运行时即时修改样本。这将起作用,但会产生额外的 transform 运行时开销。如果转换可以(至少一部分)预应用到数据集,则可以节省大量磁盘空间和采样时产生的一些开销。为此,可以使用 preprocess() 方法。此方法将对数据集的每个元素运行一个按样本的预处理管道,并用其转换后的版本替换现有数据集。
一旦转换,重新创建相同的数据集将产生另一个具有相同转换后的存储的对象(除非使用 download="force")
>>> dataset = RobosetExperienceReplay(
... "FK1-v4(expert)/FK1_MicroOpenRandom_v2d-v4", batch_size=32, download="force"
... )
>>>
>>> def func(data):
... return data.set("obs_norm", data.get("observation").norm(dim=-1))
...
>>> dataset.preprocess(
... func,
... num_workers=max(1, os.cpu_count() - 2),
... num_chunks=1000,
... mp_start_method="fork",
... )
>>> sample = dataset.sample()
>>> assert "obs_norm" in sample.keys()
>>> # re-recreating the dataset gives us the transformed version back.
>>> dataset = RobosetExperienceReplay(
... "FK1-v4(expert)/FK1_MicroOpenRandom_v2d-v4", batch_size=32
... )
>>> sample = dataset.sample()
>>> assert "obs_norm" in sample.keys()
|
离线数据集的父类。 |
|
Atari DQN 经验回放类。 |
|
D4RL 的经验回放类。 |
|
Gen-DGRL 经验回放数据集。 |
|
Minari 经验回放数据集。 |
|
OpenML 数据的经验回放。 |
|
Open X-Embodiment 数据集经验回放。 |
|
Roboset 经验回放数据集。 |
|
V-D4RL 经验回放数据集。 |
组合数据集¶
在离线强化学习中,同时使用多个数据集是惯例。此外,TorchRL 通常具有细粒度的数据集命名法,其中每个任务都单独表示,而其他库则以更紧凑的方式表示这些数据集。为了允许用户将多个数据集组合在一起,我们提出了一个 ReplayBufferEnsemble 基本类型,允许用户一次从多个数据集中采样。
如果各个数据集格式不同,可以使用 Transform 实例。在以下示例中,我们创建了两个虚拟数据集,它们的语义相同的条目名称不同(("some", "key") 和 "another_key"),并演示如何重命名它们以使其名称匹配。我们还调整图像大小,以便它们可以在采样期间堆叠在一起。
>>> from torchrl.envs import Comopse, ToTensorImage, Resize, RenameTransform
>>> from torchrl.data import TensorDictReplayBuffer, ReplayBufferEnsemble, LazyMemmapStorage
>>> from tensordict import TensorDict
>>> import torch
>>> rb0 = TensorDictReplayBuffer(
... storage=LazyMemmapStorage(10),
... transform=Compose(
... ToTensorImage(in_keys=["pixels", ("next", "pixels")]),
... Resize(32, in_keys=["pixels", ("next", "pixels")]),
... RenameTransform([("some", "key")], ["renamed"]),
... ),
... )
>>> rb1 = TensorDictReplayBuffer(
... storage=LazyMemmapStorage(10),
... transform=Compose(
... ToTensorImage(in_keys=["pixels", ("next", "pixels")]),
... Resize(32, in_keys=["pixels", ("next", "pixels")]),
... RenameTransform(["another_key"], ["renamed"]),
... ),
... )
>>> rb = ReplayBufferEnsemble(
... rb0,
... rb1,
... p=[0.5, 0.5],
... transform=Resize(33, in_keys=["pixels"], out_keys=["pixels33"]),
... )
>>> data0 = TensorDict(
... {
... "pixels": torch.randint(255, (10, 244, 244, 3)),
... ("next", "pixels"): torch.randint(255, (10, 244, 244, 3)),
... ("some", "key"): torch.randn(10),
... },
... batch_size=[10],
... )
>>> data1 = TensorDict(
... {
... "pixels": torch.randint(255, (10, 64, 64, 3)),
... ("next", "pixels"): torch.randint(255, (10, 64, 64, 3)),
... "another_key": torch.randn(10),
... },
... batch_size=[10],
... )
>>> rb[0].extend(data0)
>>> rb[1].extend(data1)
>>> for _ in range(2):
... sample = rb.sample(10)
... assert sample["next", "pixels"].shape == torch.Size([2, 5, 3, 32, 32])
... assert sample["pixels"].shape == torch.Size([2, 5, 3, 32, 32])
... assert sample["pixels33"].shape == torch.Size([2, 5, 3, 33, 33])
... assert sample["renamed"].shape == torch.Size([2, 5])
|
经验回放缓冲区集合。 |
|
采样器集合。 |
|
存储集合。 |
|
写入器集合。 |
TensorSpec¶
TensorSpec 父类及其子类定义了 TorchRL 中 state、observations action、rewards 和 done status 的基本属性,例如它们的 shape、device、dtype 和 domain。
环境 specs 与其发送和接收的输入输出匹配非常重要,因为 ParallelEnv 将根据这些 specs 创建缓冲区以与 spawn 进程通信。请检查 torchrl.envs.utils.check_env_specs() 方法进行健全性检查。
如果需要,可以使用 make_composite_from_td() 函数从数据自动生成 specs。
Specs 主要分为数值型和类别型两类。
数值型 |
|||
|---|---|---|---|
有界 |
无界 |
||
有界离散 |
有界连续 |
无界离散 |
无界连续 |
每当创建 Bounded 实例时,其域(由其 dtype 隐式定义或由 “domain” 关键字参数显式定义)将决定实例化类的类型是 BoundedContinuous 还是 BoundedDiscrete。同样适用于 Unbounded 类。请参阅这些类以获取更多信息。
类别型 |
||||
|---|---|---|---|---|
独热 |
多独热 |
类别型 |
多类别 |
二元 |
与 gymnasium 不同,TorchRL 没有任意 specs 列表的概念。如果多个 specs 必须组合在一起,TorchRL 假设数据将以字典形式(更具体地说是 TensorDict 或相关格式)呈现。在这些情况下,相应的 TensorSpec 类是 Composite spec。
尽管如此,可以使用 stack() 将 specs 堆叠在一起:如果它们相同,它们的形状将相应扩展。否则,将通过 Stacked 类创建惰性堆叠。
类似地,TensorSpecs 与 Tensor 和 TensorDict 具有一些共同行为:它们可以像常规 Tensor 实例一样被重塑 (reshaped)、索引 (indexed)、压缩 (squeezed)、解压缩 (unsqueezed)、移动到另一个设备 (to) 或解绑 (unbind)。
某些维度为 -1 的 Specs 被称为“动态”Specs,负维度表示相应数据具有不一致的形状。当被优化器或环境(例如,批量环境,如 ParallelEnv)看到时,这些负形状告诉 TorchRL 避免使用缓冲区,因为张量形状不可预测。
|
张量元数据容器的父类。 |
|
二元离散张量 Spec。 |
|
有界张量 Spec。 |
|
离散张量 Spec。 |
|
TensorSpec 的组合。 |
|
离散张量 Spec 的串联。 |
|
独热离散张量 Spec 的串联。 |
|
非张量数据的 Spec。 |
|
一维独热离散张量 Spec。 |
|
张量 Spec 堆叠的惰性表示。 |
|
复合 Spec 堆叠的惰性表示。 |
|
无界张量 Spec。 |
|
|
|
|
以下类已弃用,仅指向上面的类
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
已废弃的 |
|
已废弃的 |
树和森林¶
TorchRL 提供了一套类和函数,可用于高效地表示树和森林,这对于蒙特卡洛树搜索 (MCTS) 算法特别有用。
TensorDictMap¶
MCTS API 的核心是 TensorDictMap,它就像一个存储,其中索引可以是任何数值对象。在传统存储(例如 TensorStorage)中,只允许整数索引。
>>> storage = TensorStorage(...)
>>> data = storage[3]
TensorDictMap 允许我们在存储中进行更高级的查询。典型的例子是当我们有一个包含一组 MDPs 的存储,并且我们想根据其初始观测、动作对来重建轨迹。在张量术语中,这可以用以下伪代码来表示
>>> next_state = storage[observation, action]
(如果与此对关联的下一个状态不止一个,则可以返回一个 next_states 堆栈来代替)。这种 API 有意义,但会受到限制:允许由多个张量组成的观测或动作可能难以实现。因此,我们提供一个包含这些值的 tensordict,并让存储知道要查看哪些 in_keys 来查询下一个状态
>>> td = TensorDict(observation=observation, action=action)
>>> next_td = storage[td]
当然,这个类也允许我们用新数据扩展存储
>>> storage[td] = next_state
这非常方便,因为它允许我们表示复杂的 rollout 结构,其中在给定节点(即给定观测)采取了不同的动作。所有已观测到的 (观测, 动作) 对都可能引导我们获得一组可进一步使用的 rollout。
MCTSForest¶
从初始观测构建一棵树就变成了如何高效组织数据的问题。MCTSForest 的核心有两个存储:第一个存储将观测链接到数据集历史中遇到的动作的哈希和索引
>>> data = TensorDict(observation=observation)
>>> metadata = forest.node_map[data]
>>> index = metadata["_index"]
其中 forest 是一个 MCTSForest 实例。然后,第二个存储记录与该观测关联的动作和结果
>>> next_data = forest.data_map[index]
next_data 条目可以有任何形状,但通常会与 index 的形状匹配(因为每个索引对应一个动作)。一旦获得 next_data,就可以将其与 data 放在一起形成一组节点,并且可以对每个节点扩展树。下图展示了这是如何完成的。
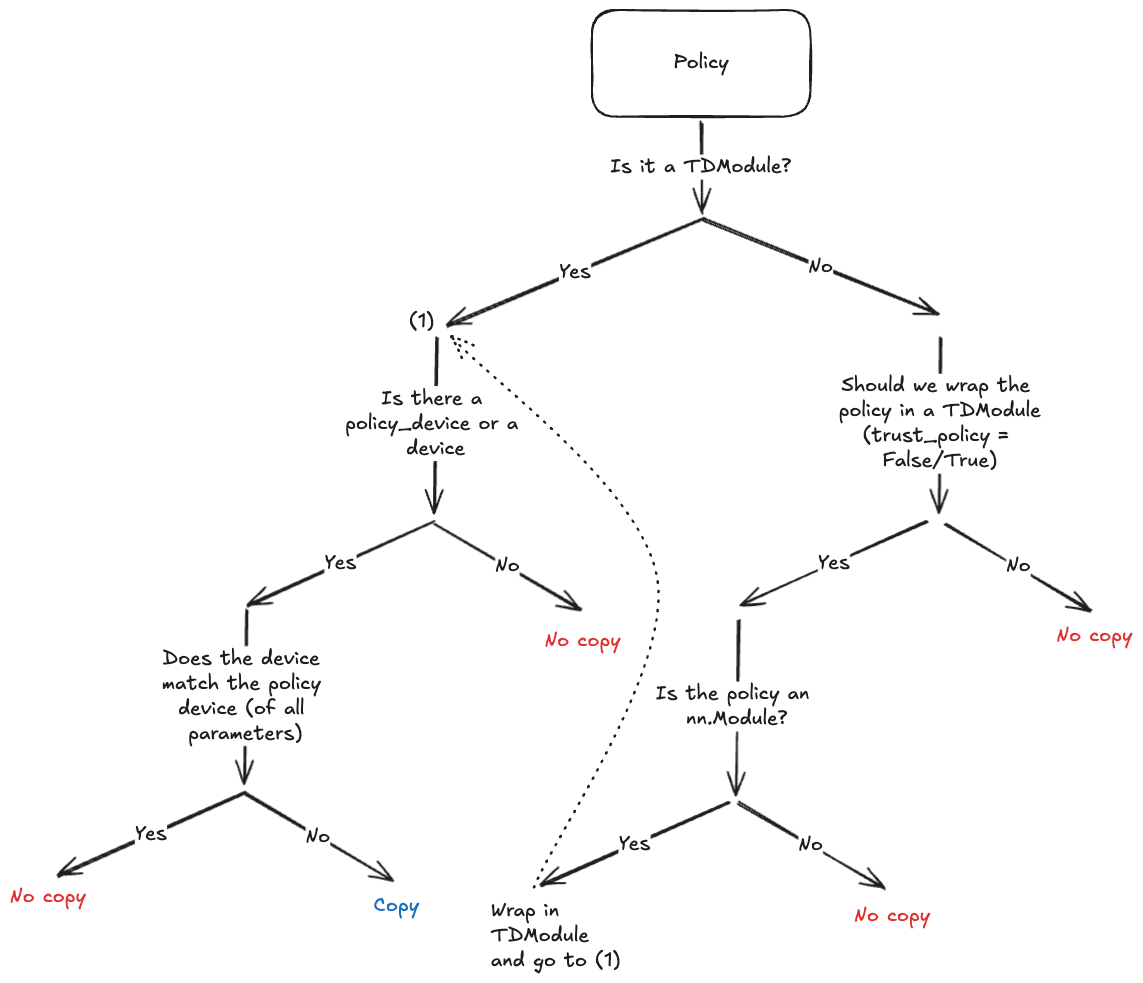
从 MCTSForest 对象构建一棵 Tree。流程图表示从初始观测 o 开始构建一棵树。get_tree 方法将输入数据结构(根节点)传递给 node_map TensorDictMap 实例,该实例返回一组哈希和索引。然后使用这些索引来查询与根节点相关的相应动作、下一个观测、奖励等元组。从中创建每个顶点(如果要求紧凑表示,可能会有更长的 rollout)。然后使用顶点堆栈进一步构建树,这些顶点堆叠在一起构成根节点的分支。这个过程会重复给定的深度或直到树无法再扩展为止。¶
|
一个将二进制编码张量转换为十进制的 Module。 |
将哈希值转换为可用于索引连续存储的整数。 |
|
|
MCTS 树的集合。 |
|
一个用于生成与存储兼容的索引的 Module。 |
|
一个将随机投影与 SipHash 结合以获得低维张量的 module,更容易通过 |
|
一个用于计算给定张量的 SipHash 值的 Module。 |
|
TensorDict 的 Map-Storage。 |
用于实现不同存储的抽象。 |
|
|
人类反馈强化学习 (RLHF)¶
在人类反馈强化学习 (RLHF) 中,数据至关重要。鉴于这些技术常用于语言领域,而该领域在库中的其他 RL 子领域中鲜有涉及,因此我们提供了专门的实用工具来促进与外部库(如数据集)的交互。这些实用工具包括用于对数据进行分词、以适合 TorchRL 模块的方式格式化数据以及优化存储以实现高效采样的工具。
|
|
|
|
|
用于 prompt 数据集的分词配方。 |
|
|
|
一个用于使用因果语言模型执行 rollout 的类。 |
|
一个 Process Function 工厂,用于对文本示例应用 tokenizer。 |
|
加载分词后的数据集,并缓存其内存映射副本。 |
|
无限循环迭代一个 iterator。 |
|
创建一个数据集并从中返回一个 dataloader。 |
|
恒定 KL 控制器。 |
|
如 Ziegler 等人发表的论文 "Fine-Tuning Language Models from Human Preferences" 中所述的自适应 KL 控制器。 |
实用工具¶
|
多步奖励转换。 |
|
给定一个 TensorSpec,通过添加形状为 0 的 spec 来移除专属键。 |
|
给定一个 TensorSpec,如果不存在专属键则返回 true。 |
|
如果 spec 包含延迟堆叠的 spec 则返回 true。 |
|
将嵌套 tensordict(其中每一行都是一个轨迹)转换为 TED 格式。 |
|
一个存储加载钩子,用于将展平的 TED 数据反序列化为 TED 格式。 |
将持久化 tensordict 中的轨迹组合成一个存储在文件系统中的单一 standing tensordict。 |
|
|
将使用 TED2Nested 准备的数据集分割成一个 TensorDict,其中每个轨迹都作为其父嵌套张量的视图存储。 |
|
一个存储保存钩子,用于将 TED 数据序列化为紧凑格式。 |
|
将 TED 格式的数据集转换为填充了嵌套张量的 tensordict,其中每一行都是一个轨迹。 |
|
ReplayBuffer 的 MultiStep 转换。 |
