


注意
请前往末尾下载完整示例代码。
从你的第一个训练循环开始¶
注意
要在 Notebook 中运行此教程,请在开头添加一个包含以下内容的安装单元格
!pip install tensordict !pip install torchrl
是时候总结一下我们在本入门系列中学到的所有知识了!
在本教程中,我们将使用前面课程中介绍过的组件,编写最基本的训练循环。
我们将使用带有 CartPole 环境的 DQN 作为原型示例。
我们将故意将细节保持在最低限度,只将每个部分链接到相关的教程。
构建环境¶
我们将使用一个带有 StepCounter 转换的 gym 环境。如果需要回顾,请查看这些功能在环境教程中的介绍。
import torch
torch.manual_seed(0)
import time
from torchrl.envs import GymEnv, StepCounter, TransformedEnv
env = TransformedEnv(GymEnv("CartPole-v1"), StepCounter())
env.set_seed(0)
from tensordict.nn import TensorDictModule as Mod, TensorDictSequential as Seq
设计策略¶
下一步是构建我们的策略。我们将制作一个常规的、确定性版本的 Actor,用于损失模块内部和评估期间。接下来,我们将为其添加一个探索模块用于推理。
from torchrl.modules import EGreedyModule, MLP, QValueModule
value_mlp = MLP(out_features=env.action_spec.shape[-1], num_cells=[64, 64])
value_net = Mod(value_mlp, in_keys=["observation"], out_keys=["action_value"])
policy = Seq(value_net, QValueModule(spec=env.action_spec))
exploration_module = EGreedyModule(
env.action_spec, annealing_num_steps=100_000, eps_init=0.5
)
policy_explore = Seq(policy, exploration_module)
数据收集器和回放缓冲区¶
接下来是数据部分:我们需要一个数据收集器来轻松获取数据批次,还需要一个回放缓冲区来存储这些数据用于训练。
from torchrl.collectors import SyncDataCollector
from torchrl.data import LazyTensorStorage, ReplayBuffer
init_rand_steps = 5000
frames_per_batch = 100
optim_steps = 10
collector = SyncDataCollector(
env,
policy_explore,
frames_per_batch=frames_per_batch,
total_frames=-1,
init_random_frames=init_rand_steps,
)
rb = ReplayBuffer(storage=LazyTensorStorage(100_000))
from torch.optim import Adam
损失模块和优化器¶
我们按照专用教程中的说明构建损失函数,以及其优化器和目标参数更新器
from torchrl.objectives import DQNLoss, SoftUpdate
loss = DQNLoss(value_network=policy, action_space=env.action_spec, delay_value=True)
optim = Adam(loss.parameters(), lr=0.02)
updater = SoftUpdate(loss, eps=0.99)
日志记录器¶
我们将使用 CSV 日志记录器来记录结果并保存渲染的视频。
from torchrl._utils import logger as torchrl_logger
from torchrl.record import CSVLogger, VideoRecorder
path = "./training_loop"
logger = CSVLogger(exp_name="dqn", log_dir=path, video_format="mp4")
video_recorder = VideoRecorder(logger, tag="video")
record_env = TransformedEnv(
GymEnv("CartPole-v1", from_pixels=True, pixels_only=False), video_recorder
)
训练循环¶
我们将不固定运行的迭代次数,而是持续训练网络,直到它达到一定的性能(任意定义为在环境中达到 200 步 - 对于 CartPole,成功定义为具有更长的轨迹)。
total_count = 0
total_episodes = 0
t0 = time.time()
for i, data in enumerate(collector):
# Write data in replay buffer
rb.extend(data)
max_length = rb[:]["next", "step_count"].max()
if len(rb) > init_rand_steps:
# Optim loop (we do several optim steps
# per batch collected for efficiency)
for _ in range(optim_steps):
sample = rb.sample(128)
loss_vals = loss(sample)
loss_vals["loss"].backward()
optim.step()
optim.zero_grad()
# Update exploration factor
exploration_module.step(data.numel())
# Update target params
updater.step()
if i % 10:
torchrl_logger.info(f"Max num steps: {max_length}, rb length {len(rb)}")
total_count += data.numel()
total_episodes += data["next", "done"].sum()
if max_length > 200:
break
t1 = time.time()
torchrl_logger.info(
f"solved after {total_count} steps, {total_episodes} episodes and in {t1-t0}s."
)
渲染¶
最后,我们让环境运行尽可能多的步数,并在本地保存视频(注意我们此时没有进行探索)。
record_env.rollout(max_steps=1000, policy=policy)
video_recorder.dump()
完整的训练循环结束后,你渲染的 CartPole 视频将看起来像这样
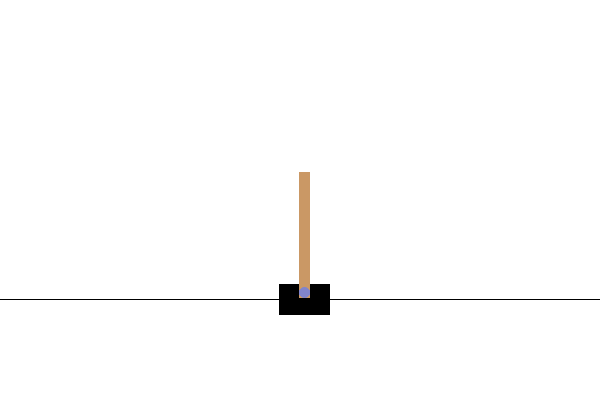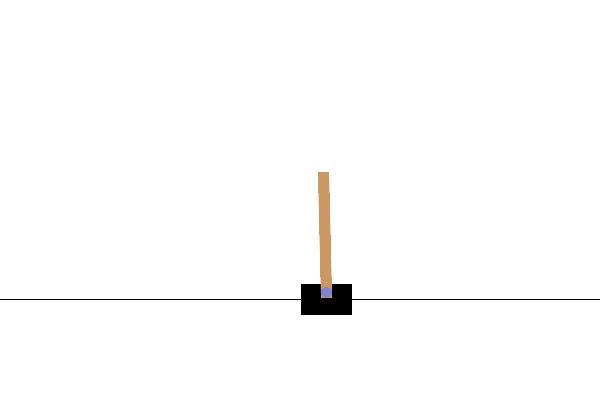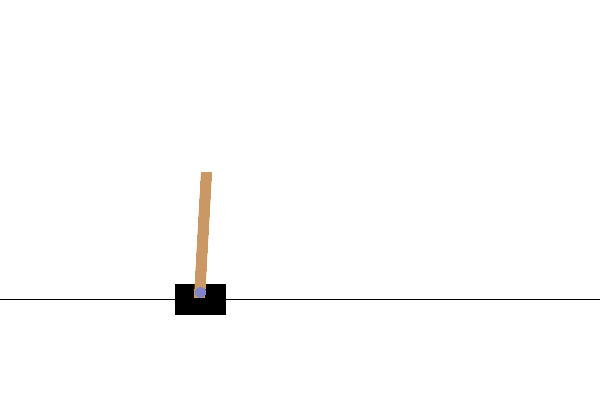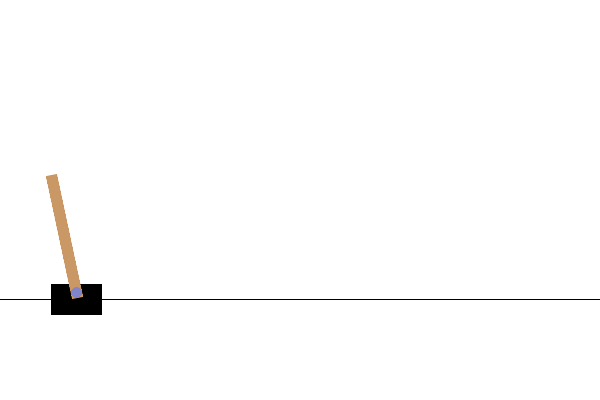
至此,我们的“TorchRL 入门”系列教程就结束了!欢迎在 GitHub 上分享你的反馈。
