


注意
跳转至末尾 下载完整的示例代码。
TorchRL 目标: 编写 DDPG 损失函数¶
作者: Vincent Moens
概述¶
TorchRL 将强化学习算法的训练分解为各种组件,这些组件将组装到你的训练脚本中:环境、数据收集和存储、模型以及最后的损失函数。
TorchRL 损失函数(或“目标函数”)是包含可训练参数(策略模型和价值模型)的状态对象。本教程将指导你从头开始使用 TorchRL 编写损失函数的步骤。
为此,我们将重点关注 DDPG,它是一种相对简单易于编写的算法。深度确定性策略梯度 (DDPG) 是一种简单的连续控制算法。它包含学习一个动作-观察对的参数化价值函数,然后学习一个策略,该策略在给定特定观察时输出最大化此价值函数的动作。
你将学到什么
如何编写损失模块并自定义其价值估计器;
如何在 TorchRL 中构建环境,包括 transforms(例如数据归一化)和并行执行;
如何设计策略网络和价值网络;
如何高效地从环境中收集数据并将其存储在经验回放缓冲区中;
如何将轨迹(而非单一转换)存储在经验回放缓冲区中;
如何评估你的模型。
先决条件¶
本教程假设你已完成PPO 教程,该教程概述了 TorchRL 组件和依赖项,例如 tensordict.TensorDict 和 tensordict.nn.TensorDictModules,尽管它应该足够透明,即使不深入理解这些类也能理解。
注意
我们并非旨在提供该算法的最先进 (SOTA) 实现,而是旨在提供 TorchRL 损失实现的高级示例,以及在该算法上下文中使用的库功能。
导入与设置¶
%%bash pip3 install torchrl mujoco glfw
import torch
import tqdm
如果可用,我们将在 CUDA 上执行策略
is_fork = multiprocessing.get_start_method() == "fork"
device = (
torch.device(0)
if torch.cuda.is_available() and not is_fork
else torch.device("cpu")
)
collector_device = torch.device("cpu") # Change the device to ``cuda`` to use CUDA
TorchRL LossModule¶
TorchRL 提供了一系列损失函数供你在训练脚本中使用。目的是使损失函数易于重用/替换,并具有简单的签名。
TorchRL 损失函数的主要特点是
它们是状态对象(stateful objects):包含可训练参数的副本,因此
loss_module.parameters()会提供训练算法所需的一切。它们遵循
TensorDict约定:torch.nn.Module.forward()方法将接收一个从经验回放缓冲区或任何类似数据结构中采样的 TensorDict 作为输入,其中包含返回损失值所需的所有必要信息。它们输出一个
tensordict.TensorDict实例,其中损失值存储在"loss_<smth>"键下,其中smth是描述损失的字符串。TensorDict 中的附加键可能是训练期间有用的度量。注意
我们返回独立损失的原因是允许用户对不同的参数集使用不同的优化器。可以通过以下方式简单地对损失进行求和
..code - block::Python
>>> loss_val = sum(loss for key, loss in loss_dict.items() if key.startswith("loss_"))
__init__ 方法¶
所有损失函数的父类是 LossModule。与库中的许多其他组件一样,其 forward() 方法期望从经验回放缓冲区或任何类似数据结构中采样的 tensordict.TensorDict 实例作为输入。使用这种格式可以在不同的模态或模型需要读取多个条目的复杂设置中重用该模块。换句话说,它允许我们编写一个损失模块,该模块不关心提供给它的数据类型,而专注于运行损失函数的基本步骤,仅此而已。
为了使本教程尽可能具有启发性,我们将独立展示类中的每个方法,并稍后填充类。
让我们从 __init__() 方法开始。DDPG 旨在通过一个简单的策略解决控制任务:训练一个策略来输出最大化价值网络预测的价值的动作。因此,我们的损失模块需要在其构造函数中接收两个网络:一个 actor 网络和一个价值网络。我们期望这两个网络都是 TensorDict 兼容的对象,例如 tensordict.nn.TensorDictModule。我们的损失函数需要计算目标价值并将价值网络拟合到该目标值,并生成一个动作并拟合策略,以便其价值估计最大化。
LossModule.__init__() 方法中的关键步骤是调用 convert_to_functional()。此方法将从模块中提取参数并将其转换为函数式模块。严格来说,这不是必需的,完全可以在不使用它的情况下编写所有损失函数。但是,我们鼓励使用它,原因如下。
TorchRL 这样做是因为强化学习算法通常使用不同的参数集执行相同的模型,这些参数集称为“可训练”参数和“目标”参数。“可训练”参数是优化器需要拟合的参数。“目标”参数通常是前者的副本,但存在一些时间延迟(绝对或通过移动平均稀释)。这些目标参数用于计算与下一个观察值相关联的价值。使用一组与当前配置不完全匹配的价值模型目标参数的优点之一是它们为正在计算的价值函数提供了悲观的界限。请注意下面的 create_target_params 关键字参数:此参数告诉 convert_to_functional() 方法在损失模块中创建一组目标参数,用于计算目标价值。如果此参数设置为 False(例如 actor 网络),则 target_actor_network_params 属性仍然可访问,但这只会返回 actor 参数的分离版本。
稍后,我们将看到如何在 TorchRL 中更新目标参数。
from tensordict.nn import TensorDictModule, TensorDictSequential
def _init(
self,
actor_network: TensorDictModule,
value_network: TensorDictModule,
) -> None:
super(type(self), self).__init__()
self.convert_to_functional(
actor_network,
"actor_network",
create_target_params=True,
)
self.convert_to_functional(
value_network,
"value_network",
create_target_params=True,
compare_against=list(actor_network.parameters()),
)
self.actor_in_keys = actor_network.in_keys
# Since the value we'll be using is based on the actor and value network,
# we put them together in a single actor-critic container.
actor_critic = ActorCriticWrapper(actor_network, value_network)
self.actor_critic = actor_critic
self.loss_function = "l2"
价值估计器损失方法¶
在许多强化学习算法中,价值网络(或 Q 值网络)基于经验价值估计进行训练。这可以是自举的(TD(0),低方差,高偏差),这意味着目标价值是通过下一个奖励获得的,别无其他;或者可以获得蒙特卡罗估计(TD(1)),在这种情况下将使用即将到来的整个奖励序列(高方差,低偏差)。也可以使用中间估计器 (TD(\(\lambda\))) 来折衷偏差和方差。TorchRL 通过 ValueEstimators 枚举类使其易于使用其中一个估计器,该类包含指向所有已实现的价值估计器的指针。让我们在此处定义默认价值函数。我们将采用最简单的版本 (TD(0)),并在稍后展示如何更改它。
from torchrl.objectives.utils import ValueEstimators
default_value_estimator = ValueEstimators.TD0
我们还需要向 DDPG 提供一些关于如何根据用户查询构建价值估计器的说明。根据提供的估计器,我们将构建在训练时要使用的相应模块
from torchrl.objectives.utils import default_value_kwargs
from torchrl.objectives.value import TD0Estimator, TD1Estimator, TDLambdaEstimator
def make_value_estimator(self, value_type: ValueEstimators, **hyperparams):
hp = dict(default_value_kwargs(value_type))
if hasattr(self, "gamma"):
hp["gamma"] = self.gamma
hp.update(hyperparams)
value_key = "state_action_value"
if value_type == ValueEstimators.TD1:
self._value_estimator = TD1Estimator(value_network=self.actor_critic, **hp)
elif value_type == ValueEstimators.TD0:
self._value_estimator = TD0Estimator(value_network=self.actor_critic, **hp)
elif value_type == ValueEstimators.GAE:
raise NotImplementedError(
f"Value type {value_type} it not implemented for loss {type(self)}."
)
elif value_type == ValueEstimators.TDLambda:
self._value_estimator = TDLambdaEstimator(value_network=self.actor_critic, **hp)
else:
raise NotImplementedError(f"Unknown value type {value_type}")
self._value_estimator.set_keys(value=value_key)
make_value_estimator 方法可以调用,但非必需:如果未调用,则 LossModule 将使用其默认估计器查询此方法。
Actor 损失方法¶
强化学习算法的核心部分是 actor 的训练损失函数。在 DDPG 的情况下,此函数相当简单:我们只需要计算使用策略计算的动作的价值,并优化 actor 权重以最大化此价值。
计算此价值时,我们必须确保将价值参数从计算图中移除,否则 actor 和价值损失将混淆。为此,可以使用 hold_out_params() 函数。
def _loss_actor(
self,
tensordict,
) -> torch.Tensor:
td_copy = tensordict.select(*self.actor_in_keys)
# Get an action from the actor network: since we made it functional, we need to pass the params
with self.actor_network_params.to_module(self.actor_network):
td_copy = self.actor_network(td_copy)
# get the value associated with that action
with self.value_network_params.detach().to_module(self.value_network):
td_copy = self.value_network(td_copy)
return -td_copy.get("state_action_value")
价值损失方法¶
现在我们需要优化价值网络参数。为此,我们将依赖于类的价值估计器
from torchrl.objectives.utils import distance_loss
def _loss_value(
self,
tensordict,
):
td_copy = tensordict.clone()
# V(s, a)
with self.value_network_params.to_module(self.value_network):
self.value_network(td_copy)
pred_val = td_copy.get("state_action_value").squeeze(-1)
# we manually reconstruct the parameters of the actor-critic, where the first
# set of parameters belongs to the actor and the second to the value function.
target_params = TensorDict(
{
"module": {
"0": self.target_actor_network_params,
"1": self.target_value_network_params,
}
},
batch_size=self.target_actor_network_params.batch_size,
device=self.target_actor_network_params.device,
)
with target_params.to_module(self.actor_critic):
target_value = self.value_estimator.value_estimate(tensordict).squeeze(-1)
# Computes the value loss: L2, L1 or smooth L1 depending on `self.loss_function`
loss_value = distance_loss(pred_val, target_value, loss_function=self.loss_function)
td_error = (pred_val - target_value).pow(2)
return loss_value, td_error, pred_val, target_value
在 forward 调用中将各部分组合起来¶
唯一缺少的部分是 forward 方法,它将价值损失和 actor 损失粘合在一起,收集成本值并将它们写入提供给用户的 TensorDict 中。
from tensordict import TensorDict, TensorDictBase
def _forward(self, input_tensordict: TensorDictBase) -> TensorDict:
loss_value, td_error, pred_val, target_value = self.loss_value(
input_tensordict,
)
td_error = td_error.detach()
td_error = td_error.unsqueeze(input_tensordict.ndimension())
if input_tensordict.device is not None:
td_error = td_error.to(input_tensordict.device)
input_tensordict.set(
"td_error",
td_error,
inplace=True,
)
loss_actor = self.loss_actor(input_tensordict)
return TensorDict(
source={
"loss_actor": loss_actor.mean(),
"loss_value": loss_value.mean(),
"pred_value": pred_val.mean().detach(),
"target_value": target_value.mean().detach(),
"pred_value_max": pred_val.max().detach(),
"target_value_max": target_value.max().detach(),
},
batch_size=[],
)
from torchrl.objectives import LossModule
class DDPGLoss(LossModule):
default_value_estimator = default_value_estimator
make_value_estimator = make_value_estimator
__init__ = _init
forward = _forward
loss_value = _loss_value
loss_actor = _loss_actor
现在我们有了损失函数,我们可以用它来训练策略来解决控制任务。
环境¶
在大多数算法中,首先需要处理的是环境的构建,因为它决定了训练脚本的其余部分。
对于此示例,我们将使用 "cheetah" 任务。目标是让一只半机械豹尽可能快地奔跑。
在 TorchRL 中,可以通过依赖 dm_control 或 gym 创建此类任务
env = GymEnv("HalfCheetah-v4")
或
env = DMControlEnv("cheetah", "run")
默认情况下,这些环境禁用渲染。从状态进行训练通常比从图像进行训练更容易。为了简单起见,我们只关注从状态学习。要将像素传递给 env.step() 收集的 tensordicts,只需将 from_pixels=True 参数传递给构造函数即可
env = GymEnv("HalfCheetah-v4", from_pixels=True, pixels_only=True)
我们编写一个 make_env() 辅助函数,该函数将使用上面考虑的两种后端之一(dm-control 或 gym)创建一个环境。
from torchrl.envs.libs.dm_control import DMControlEnv
from torchrl.envs.libs.gym import GymEnv
env_library = None
env_name = None
def make_env(from_pixels=False):
"""Create a base ``env``."""
global env_library
global env_name
if backend == "dm_control":
env_name = "cheetah"
env_task = "run"
env_args = (env_name, env_task)
env_library = DMControlEnv
elif backend == "gym":
env_name = "HalfCheetah-v4"
env_args = (env_name,)
env_library = GymEnv
else:
raise NotImplementedError
env_kwargs = {
"device": device,
"from_pixels": from_pixels,
"pixels_only": from_pixels,
"frame_skip": 2,
}
env = env_library(*env_args, **env_kwargs)
return env
Transforms¶
现在我们有了基本环境,我们可能希望修改其表示形式以使其对策略更友好。在 TorchRL 中,transforms 被附加到基本环境中,放在专门的 torchr.envs.TransformedEnv 类中。
在 DDPG 中,使用一些启发式价值来重新缩放奖励是很常见的。在此示例中,我们将奖励乘以 5。
如果我们使用
dm_control,构建一个在模拟器(使用双精度数字)与我们的脚本(可能使用单精度数字)之间的接口也很重要。这种转换是双向的:调用env.step()时,我们的动作需要表示为双精度,并且输出需要转换为单精度。DoubleToFloattransform 正好做了这件事:in_keys列表指的是需要从双精度转换为单精度的键,而in_keys_inv指的是在传递给环境之前需要转换为双精度的键。我们使用
CatTensorstransform 将状态键连接在一起。最后,我们也保留了归一化状态的可能性:我们将稍后计算归一化常数。
from torchrl.envs import (
CatTensors,
DoubleToFloat,
EnvCreator,
InitTracker,
ObservationNorm,
ParallelEnv,
RewardScaling,
StepCounter,
TransformedEnv,
)
def make_transformed_env(
env,
):
"""Apply transforms to the ``env`` (such as reward scaling and state normalization)."""
env = TransformedEnv(env)
# we append transforms one by one, although we might as well create the
# transformed environment using the `env = TransformedEnv(base_env, transforms)`
# syntax.
env.append_transform(RewardScaling(loc=0.0, scale=reward_scaling))
# We concatenate all states into a single "observation_vector"
# even if there is a single tensor, it'll be renamed in "observation_vector".
# This facilitates the downstream operations as we know the name of the
# output tensor.
# In some environments (not half-cheetah), there may be more than one
# observation vector: in this case this code snippet will concatenate them
# all.
selected_keys = list(env.observation_spec.keys())
out_key = "observation_vector"
env.append_transform(CatTensors(in_keys=selected_keys, out_key=out_key))
# we normalize the states, but for now let's just instantiate a stateless
# version of the transform
env.append_transform(ObservationNorm(in_keys=[out_key], standard_normal=True))
env.append_transform(DoubleToFloat())
env.append_transform(StepCounter(max_frames_per_traj))
# We need a marker for the start of trajectories for our Ornstein-Uhlenbeck (OU)
# exploration:
env.append_transform(InitTracker())
return env
并行执行¶
以下辅助函数允许我们并行运行环境。并行运行环境可以显著加快收集吞吐量。使用 transformed 环境时,我们需要选择是为每个环境单独执行 transform,还是集中数据并以批处理方式转换。这两种方法都很容易编码
env = ParallelEnv(
lambda: TransformedEnv(GymEnv("HalfCheetah-v4"), transforms),
num_workers=4
)
env = TransformedEnv(
ParallelEnv(lambda: GymEnv("HalfCheetah-v4"), num_workers=4),
transforms
)
为了利用 PyTorch 的向量化能力,我们采用第一种方法
def parallel_env_constructor(
env_per_collector,
transform_state_dict,
):
if env_per_collector == 1:
def make_t_env():
env = make_transformed_env(make_env())
env.transform[2].init_stats(3)
env.transform[2].loc.copy_(transform_state_dict["loc"])
env.transform[2].scale.copy_(transform_state_dict["scale"])
return env
env_creator = EnvCreator(make_t_env)
return env_creator
parallel_env = ParallelEnv(
num_workers=env_per_collector,
create_env_fn=EnvCreator(lambda: make_env()),
create_env_kwargs=None,
pin_memory=False,
)
env = make_transformed_env(parallel_env)
# we call `init_stats` for a limited number of steps, just to instantiate
# the lazy buffers.
env.transform[2].init_stats(3, cat_dim=1, reduce_dim=[0, 1])
env.transform[2].load_state_dict(transform_state_dict)
return env
# The backend can be ``gym`` or ``dm_control``
backend = "gym"
注意
frame_skip 将多个步骤与单个动作批处理在一起 如果 > 1,则其他帧计数(例如 frames_per_batch, total_frames)需要调整,以确保在不同实验中收集到的总帧数一致。这一点很重要,因为提高 frame-skip 但保持总帧数不变可能看起来像作弊:相比之下,一个使用 frame-skip 2 收集的 10M 元素数据集和另一个使用 frame-skip 1 的数据集,其与环境交互的比率实际上是 2:1!简而言之,在处理帧跳过时,应该谨慎对待训练脚本的帧计数,因为这可能导致训练策略之间的比较产生偏差。
缩放奖励有助于我们控制信号幅度,从而实现更高效的学习。
reward_scaling = 5.0
我们还定义了轨迹何时会被截断。一千步(如果 frame-skip = 2,则为 500)对于 cheetah 任务来说是个不错的数值
max_frames_per_traj = 500
观察值归一化¶
为了计算归一化统计数据,我们在环境中运行任意数量的随机步骤,并计算收集到的观察值的均值和标准差。ObservationNorm.init_stats() 方法可用于此目的。为了获得汇总统计数据,我们创建一个 dummy 环境,运行特定数量的步骤,收集特定数量步骤的数据,并计算其汇总统计数据。
def get_env_stats():
"""Gets the stats of an environment."""
proof_env = make_transformed_env(make_env())
t = proof_env.transform[2]
t.init_stats(init_env_steps)
transform_state_dict = t.state_dict()
proof_env.close()
return transform_state_dict
归一化统计数据¶
使用 ObservationNorm 计算统计数据所使用的随机步骤数
init_env_steps = 5000
transform_state_dict = get_env_stats()
每个数据收集器中的环境数量
env_per_collector = 4
我们将之前计算的统计数据传递给环境以归一化其输出
parallel_env = parallel_env_constructor(
env_per_collector=env_per_collector,
transform_state_dict=transform_state_dict,
)
from torchrl.data import Composite
构建模型¶
现在我们来设置模型。正如我们所见,DDPG 需要一个价值网络,用于估计状态-动作对的价值,以及一个参数化 actor,用于学习如何选择最大化此价值的动作。
回想一下,构建 TorchRL 模块需要两个步骤
编写将用作网络的
torch.nn.Module,将网络包装到
tensordict.nn.TensorDictModule中,其中通过指定输入和输出键来处理数据流。
在更复杂的场景中,也可以使用 tensordict.nn.TensorDictSequential。
Q 值网络被包装在一个 ValueOperator 中,该操作符会自动将 Q 值网络的 out_keys 设置为 "state_action_value,将其他价值网络的 out_keys 设置为 state_value。
TorchRL 提供了原论文中介绍的内置 DDPG 网络版本。可以在 DdpgMlpActor 和 DdpgMlpQNet 中找到它们。
由于我们使用 lazy 模块,因此必须在能够将策略从一个设备移动到另一个设备以及执行其他操作之前实例化这些 lazy 模块。因此,使用少量数据样本运行模块是良好的实践。为此,我们根据环境规格生成假数据。
from torchrl.modules import (
ActorCriticWrapper,
DdpgMlpActor,
DdpgMlpQNet,
OrnsteinUhlenbeckProcessModule,
ProbabilisticActor,
TanhDelta,
ValueOperator,
)
def make_ddpg_actor(
transform_state_dict,
device="cpu",
):
proof_environment = make_transformed_env(make_env())
proof_environment.transform[2].init_stats(3)
proof_environment.transform[2].load_state_dict(transform_state_dict)
out_features = proof_environment.action_spec.shape[-1]
actor_net = DdpgMlpActor(
action_dim=out_features,
)
in_keys = ["observation_vector"]
out_keys = ["param"]
actor = TensorDictModule(
actor_net,
in_keys=in_keys,
out_keys=out_keys,
)
actor = ProbabilisticActor(
actor,
distribution_class=TanhDelta,
in_keys=["param"],
spec=Composite(action=proof_environment.action_spec),
).to(device)
q_net = DdpgMlpQNet()
in_keys = in_keys + ["action"]
qnet = ValueOperator(
in_keys=in_keys,
module=q_net,
).to(device)
# initialize lazy modules
qnet(actor(proof_environment.reset().to(device)))
return actor, qnet
actor, qnet = make_ddpg_actor(
transform_state_dict=transform_state_dict,
device=device,
)
探索¶
策略被传递到一个 OrnsteinUhlenbeckProcessModule 探索模块中,正如原论文建议的那样。让我们定义 OU 噪声达到最小值之前的帧数
annealing_frames = 1_000_000
actor_model_explore = TensorDictSequential(
actor,
OrnsteinUhlenbeckProcessModule(
spec=actor.spec.clone(),
annealing_num_steps=annealing_frames,
).to(device),
)
if device == torch.device("cpu"):
actor_model_explore.share_memory()
数据收集器¶
TorchRL 提供了专门的类,帮助你通过在环境中执行策略来收集数据。这些“数据收集器”会迭代计算给定时间要执行的动作,然后在环境中执行一个步骤,并在需要时重置环境。数据收集器旨在帮助开发者严格控制每批数据中的帧数、收集的同步/异步性质以及分配给数据收集的资源(例如 GPU、worker 数量等)。
这里我们将使用 SyncDataCollector,一个简单的单进程数据收集器。TorchRL 还提供其他收集器,例如 MultiaSyncDataCollector,它以异步方式执行 rollouts(例如,在策略优化时收集数据,从而解耦训练和数据收集)。
需要指定的参数有
一个环境工厂或一个环境,
策略,
收集器被视为空之前的总帧数,
每条轨迹的最大帧数(对于非终止环境,例如
dm_control环境很有用)。注意
传递给收集器的
max_frames_per_traj参数将注册一个新的StepCountertransform 到用于推理的环境中。我们也可以手动实现相同的结果,正如我们在脚本中所做的那样。
还应该传递
每个收集到的批次中的帧数,
独立于策略执行的随机步数,
用于策略执行的设备
在数据传递给主进程之前用于存储数据的设备。
训练期间使用的总帧数应在 1M 左右。
total_frames = 10_000 # 1_000_000
收集器在外部循环每次迭代中返回的帧数等于每个子轨迹的长度乘以每个收集器中并行运行的环境数量。
换句话说,我们期望收集器返回的批次具有 [env_per_collector, traj_len] 的形状,其中 traj_len=frames_per_batch/env_per_collector
traj_len = 200
frames_per_batch = env_per_collector * traj_len
init_random_frames = 5000
num_collectors = 2
from torchrl.collectors import SyncDataCollector
from torchrl.envs import ExplorationType
collector = SyncDataCollector(
parallel_env,
policy=actor_model_explore,
total_frames=total_frames,
frames_per_batch=frames_per_batch,
init_random_frames=init_random_frames,
reset_at_each_iter=False,
split_trajs=False,
device=collector_device,
exploration_type=ExplorationType.RANDOM,
)
评估器:构建你的记录器对象¶
由于训练数据是使用某种探索策略获得的,因此算法的真实性能需要在确定性模式下评估。我们使用一个专门的类 LogValidationReward 来实现此目的,它会以给定的频率在环境中执行策略,并返回从这些模拟中获得的统计数据。
以下辅助函数构建此对象
from torchrl.trainers import LogValidationReward
def make_recorder(actor_model_explore, transform_state_dict, record_interval):
base_env = make_env()
environment = make_transformed_env(base_env)
environment.transform[2].init_stats(
3
) # must be instantiated to load the state dict
environment.transform[2].load_state_dict(transform_state_dict)
recorder_obj = LogValidationReward(
record_frames=1000,
policy_exploration=actor_model_explore,
environment=environment,
exploration_type=ExplorationType.DETERMINISTIC,
record_interval=record_interval,
)
return recorder_obj
我们将每收集 10 个批次记录一次性能
record_interval = 10
recorder = make_recorder(
actor_model_explore, transform_state_dict, record_interval=record_interval
)
from torchrl.data.replay_buffers import (
LazyMemmapStorage,
PrioritizedSampler,
RandomSampler,
TensorDictReplayBuffer,
)
经验回放缓冲区¶
经验回放缓冲区有两种类型:优先回放(其中使用某种误差信号为某些项提供比其他项更高的采样概率)和常规的循环经验回放。
TorchRL 经验回放缓冲区是可组合的:可以选择存储、采样和写入策略。也可以使用内存映射数组将张量存储在物理内存中。以下函数负责使用所需的超参数创建经验回放缓冲区
from torchrl.envs import RandomCropTensorDict
def make_replay_buffer(buffer_size, batch_size, random_crop_len, prefetch=3, prb=False):
if prb:
sampler = PrioritizedSampler(
max_capacity=buffer_size,
alpha=0.7,
beta=0.5,
)
else:
sampler = RandomSampler()
replay_buffer = TensorDictReplayBuffer(
storage=LazyMemmapStorage(
buffer_size,
scratch_dir=buffer_scratch_dir,
),
batch_size=batch_size,
sampler=sampler,
pin_memory=False,
prefetch=prefetch,
transform=RandomCropTensorDict(random_crop_len, sample_dim=1),
)
return replay_buffer
我们将经验回放缓冲区存储在磁盘上的一个临时目录中
import tempfile
tmpdir = tempfile.TemporaryDirectory()
buffer_scratch_dir = tmpdir.name
经验回放缓冲区存储和批次大小¶
TorchRL 经验回放缓冲区沿第一个维度计算元素数量。由于我们将轨迹馈送到缓冲区,因此需要将缓冲区大小除以数据收集器产生的子轨迹长度进行调整。关于批次大小,我们的采样策略将包括采样长度为 traj_len=200 的轨迹,然后选择长度为 random_crop_len=25 的子轨迹,并在此子轨迹上计算损失。此策略平衡了存储特定长度的完整轨迹与为损失提供足够异构样本的需求。下图显示了一个收集器的数据流,该收集器在每个批次中获取 8 帧,并并行运行 2 个环境,将这些数据馈送到包含 1000 条轨迹的经验回放缓冲区,并采样每条长度为 2 个时间步的子轨迹。
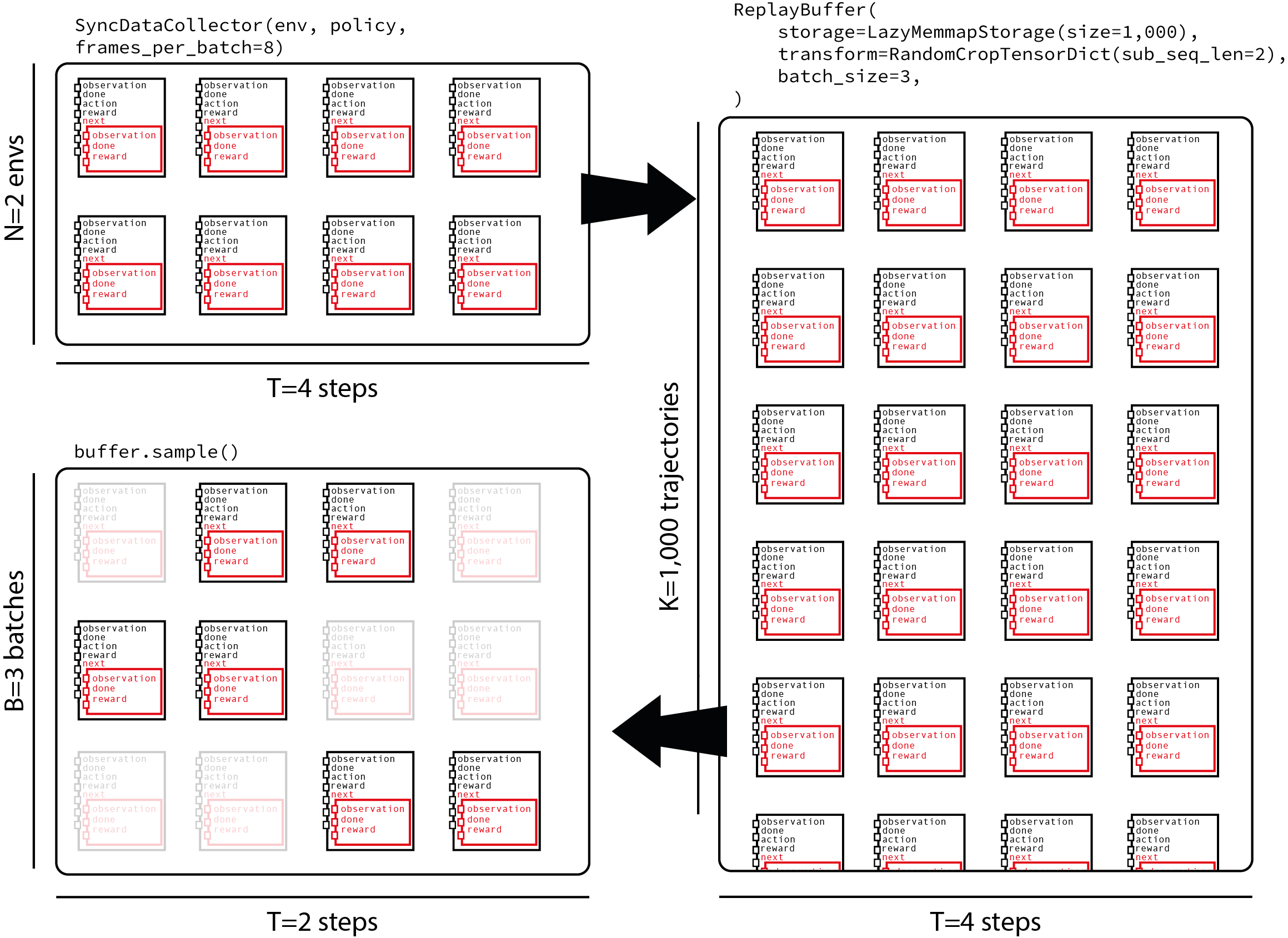
让我们从存储在缓冲区中的帧数开始
def ceil_div(x, y):
return -x // (-y)
buffer_size = 1_000_000
buffer_size = ceil_div(buffer_size, traj_len)
默认情况下禁用优先回放缓冲区
prb = False
我们还需要定义每个收集到的数据批次要执行多少次更新。这被称为更新-数据比率或 UTD 比率
update_to_data = 64
我们将使用长度为 25 的轨迹来训练损失函数
random_crop_len = 25
在原论文中,作者为收集到的每一帧执行一次批量大小为 64 的更新。在这里,我们重复相同的比率,但在每次收集批次时执行多次更新。我们调整批量大小以达到相同的每帧更新次数比率
batch_size = ceil_div(64 * frames_per_batch, update_to_data * random_crop_len)
replay_buffer = make_replay_buffer(
buffer_size=buffer_size,
batch_size=batch_size,
random_crop_len=random_crop_len,
prefetch=3,
prb=prb,
)
损失模块构建¶
我们使用刚刚创建的 actor 和 qnet 构建我们的损失模块。因为我们有目标参数需要更新,所以必须创建一个目标网络更新器。
gamma = 0.99
lmbda = 0.9
tau = 0.001 # Decay factor for the target network
loss_module = DDPGLoss(actor, qnet)
让我们使用 TD(lambda) 估计器!
loss_module.make_value_estimator(ValueEstimators.TDLambda, gamma=gamma, lmbda=lmbda)
注意
离策略通常需要一个 TD(0) 估计器。在这里,我们使用 TD(\(\lambda\)) 估计器,这会引入一些偏差,因为某个状态后的轨迹是使用过时的策略收集的。这个技巧,就像数据收集期间可以使用的多步技巧一样,是“黑客技巧”的另一种版本,我们通常发现在实践中它们效果很好,尽管它们在回报估计中引入了一些偏差。
目标网络更新器¶
目标网络是离策略强化学习算法的关键部分。得益于 HardUpdate 和 SoftUpdate 类,更新目标网络参数变得容易。它们以损失模块作为参数构建,更新通过在训练循环的适当位置调用 updater.step() 来实现。
from torchrl.objectives.utils import SoftUpdate
target_net_updater = SoftUpdate(loss_module, eps=1 - tau)
优化器¶
最后,我们将对策略网络和价值网络使用 Adam 优化器
from torch import optim
optimizer_actor = optim.Adam(
loss_module.actor_network_params.values(True, True), lr=1e-4, weight_decay=0.0
)
optimizer_value = optim.Adam(
loss_module.value_network_params.values(True, True), lr=1e-3, weight_decay=1e-2
)
total_collection_steps = total_frames // frames_per_batch
训练策略的时间¶
现在我们已经构建了所有需要的模块,训练循环变得相当简单。
rewards = []
rewards_eval = []
# Main loop
collected_frames = 0
pbar = tqdm.tqdm(total=total_frames)
r0 = None
for i, tensordict in enumerate(collector):
# update weights of the inference policy
collector.update_policy_weights_()
if r0 is None:
r0 = tensordict["next", "reward"].mean().item()
pbar.update(tensordict.numel())
# extend the replay buffer with the new data
current_frames = tensordict.numel()
collected_frames += current_frames
replay_buffer.extend(tensordict.cpu())
# optimization steps
if collected_frames >= init_random_frames:
for _ in range(update_to_data):
# sample from replay buffer
sampled_tensordict = replay_buffer.sample().to(device)
# Compute loss
loss_dict = loss_module(sampled_tensordict)
# optimize
loss_dict["loss_actor"].backward()
gn1 = torch.nn.utils.clip_grad_norm_(
loss_module.actor_network_params.values(True, True), 10.0
)
optimizer_actor.step()
optimizer_actor.zero_grad()
loss_dict["loss_value"].backward()
gn2 = torch.nn.utils.clip_grad_norm_(
loss_module.value_network_params.values(True, True), 10.0
)
optimizer_value.step()
optimizer_value.zero_grad()
gn = (gn1**2 + gn2**2) ** 0.5
# update priority
if prb:
replay_buffer.update_tensordict_priority(sampled_tensordict)
# update target network
target_net_updater.step()
rewards.append(
(
i,
tensordict["next", "reward"].mean().item(),
)
)
td_record = recorder(None)
if td_record is not None:
rewards_eval.append((i, td_record["r_evaluation"].item()))
if len(rewards_eval) and collected_frames >= init_random_frames:
target_value = loss_dict["target_value"].item()
loss_value = loss_dict["loss_value"].item()
loss_actor = loss_dict["loss_actor"].item()
rn = sampled_tensordict["next", "reward"].mean().item()
rs = sampled_tensordict["next", "reward"].std().item()
pbar.set_description(
f"reward: {rewards[-1][1]: 4.2f} (r0 = {r0: 4.2f}), "
f"reward eval: reward: {rewards_eval[-1][1]: 4.2f}, "
f"reward normalized={rn :4.2f}/{rs :4.2f}, "
f"grad norm={gn: 4.2f}, "
f"loss_value={loss_value: 4.2f}, "
f"loss_actor={loss_actor: 4.2f}, "
f"target value: {target_value: 4.2f}"
)
# update the exploration strategy
actor_model_explore[1].step(current_frames)
collector.shutdown()
del collector
try:
parallel_env.close()
del parallel_env
except Exception:
pass
实验结果¶
我们绘制了一个简单的训练期间平均奖励图。我们可以观察到,我们的策略很好地学会了解决任务。
注意
如上所述,为了获得更合理的性能,请为 total_frames 使用更大的值,例如 1M。
from matplotlib import pyplot as plt
plt.figure()
plt.plot(*zip(*rewards), label="training")
plt.plot(*zip(*rewards_eval), label="eval")
plt.legend()
plt.xlabel("iter")
plt.ylabel("reward")
plt.tight_layout()
结论¶
在本教程中,我们学习了如何使用具体的 DDPG 示例在 TorchRL 中编写损失模块的代码。
主要要点是
如何使用
LossModule类来编写新的损失组件的代码;如何使用(或不使用)目标网络,以及如何更新其参数;
如何创建与损失模块关联的优化器。
下一步¶
为了进一步迭代此损失模块,我们可以考虑
使用 @dispatch(参见 [Feature] Distpatch IQL loss module。)
允许灵活的 TensorDict 键。
