


注意
前往末尾下载完整示例代码。
循环 DQN:训练循环策略¶
作者: Vincent Moens
如何在 TorchRL 的 actor 中集成 RNN
如何将基于内存的策略与回放缓冲区和损失模块一起使用
PyTorch v2.0.0
gym[mujoco]
tqdm
import tempfile
概述¶
基于内存的策略至关重要,不仅在观测值部分可观测时,而且在做出明智决策需要考虑时间维度时也是如此。
循环神经网络长期以来一直是基于内存的策略的流行工具。其思想是在两个连续步骤之间将循环状态保存在内存中,并将其与当前观测值一起作为策略的输入。
本教程展示了如何使用 TorchRL 在策略中集成 RNN。
关键学习点
在 TorchRL 的 actor 中集成 RNN;
将基于内存的策略与回放缓冲区和损失模块一起使用。
在 TorchRL 中使用 RNN 的核心思想是使用 TensorDict 作为数据载体,将隐藏状态从一步传递到另一步。我们将构建一个策略,该策略从当前的 TensorDict 中读取先前的循环状态,并将当前的循环状态写入下一个状态的 TensorDict 中
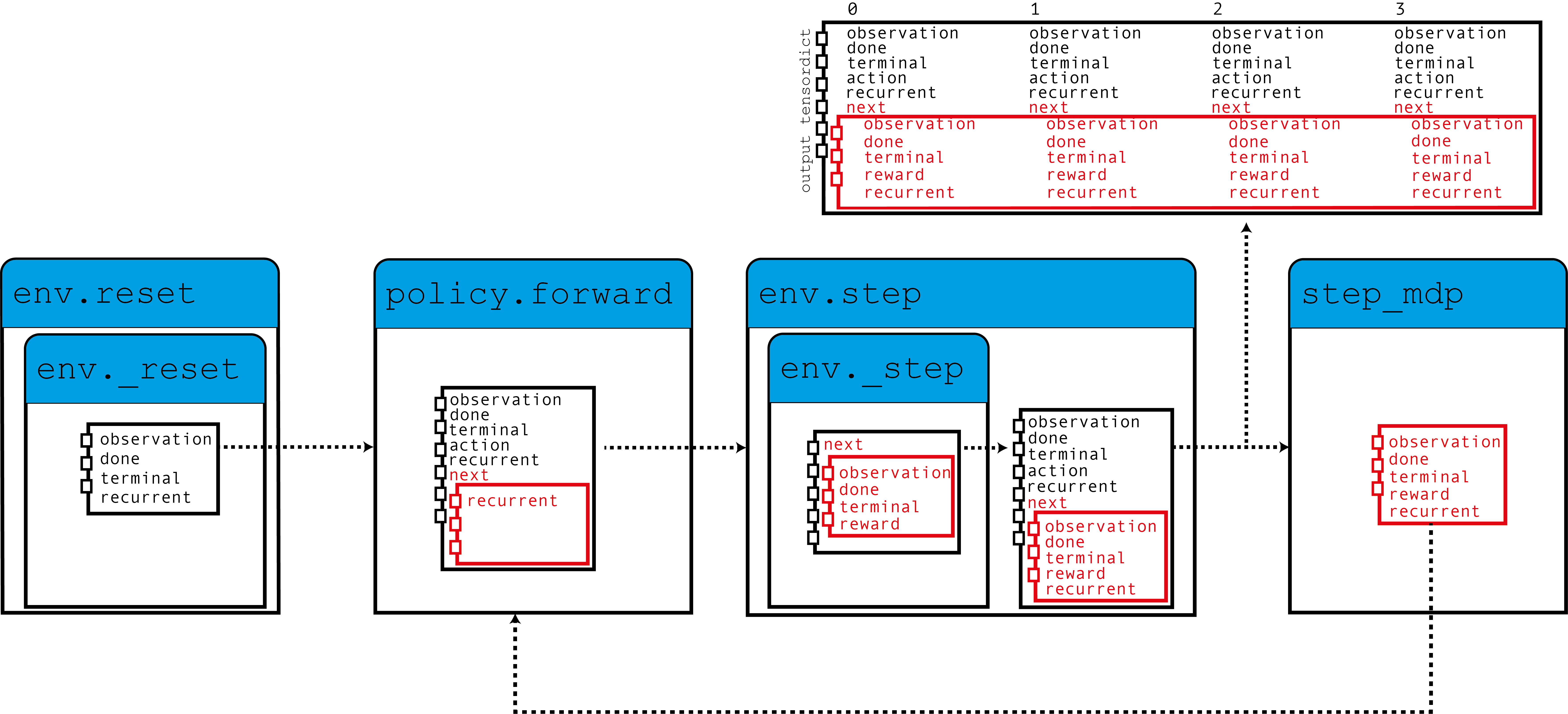
如图所示,我们的环境使用零值循环状态填充 TensorDict,策略读取这些状态以及观测值以生成动作和将在下一步中使用的循环状态。当调用 step_mdp() 函数时,下一个状态的循环状态会被带到当前的 TensorDict 中。让我们看看这在实践中是如何实现的。
如果你在 Google Colab 中运行此代码,请确保安装以下依赖项
!pip3 install torchrl
!pip3 install gym[mujoco]
!pip3 install tqdm
设置¶
import torch
import tqdm
from tensordict.nn import (
TensorDictModule as Mod,
TensorDictSequential,
TensorDictSequential as Seq,
)
from torch import nn
from torchrl.collectors import SyncDataCollector
from torchrl.data import LazyMemmapStorage, TensorDictReplayBuffer
from torchrl.envs import (
Compose,
ExplorationType,
GrayScale,
InitTracker,
ObservationNorm,
Resize,
RewardScaling,
set_exploration_type,
StepCounter,
ToTensorImage,
TransformedEnv,
)
from torchrl.envs.libs.gym import GymEnv
from torchrl.modules import ConvNet, EGreedyModule, LSTMModule, MLP, QValueModule
from torchrl.objectives import DQNLoss, SoftUpdate
is_fork = multiprocessing.get_start_method() == "fork"
device = (
torch.device(0)
if torch.cuda.is_available() and not is_fork
else torch.device("cpu")
)
环境¶
像往常一样,第一步是构建我们的环境:它帮助我们定义问题并相应地构建策略网络。在本教程中,我们将运行一个基于像素的 CartPole gym 环境的单实例,并进行一些自定义 transforms:转换为灰度、调整大小为 84x84、缩小奖励并归一化观测值。
注意
StepCounter transform 是辅助性的。由于 CartPole 任务的目标是使轨迹尽可能长,计数步骤可以帮助我们跟踪策略的性能。
有两个 transforms 对本教程的目的很重要
InitTracker将通过在 TensorDict 中添加一个布尔掩码"is_init"来标记对reset()的调用,该掩码将跟踪哪些步骤需要重置 RNN 隐藏状态。TensorDictPrimertransform 稍微更技术性一些。它不是使用 RNN 策略所必需的。但是,它会通知环境(以及随后的 collector)期望一些额外的键。添加后,调用 env.reset() 将使用零值张量填充 primer 中指定的条目。由于策略期望这些张量,collector 在收集过程中会将其传递下去。最终,我们会将隐藏状态存储在回放缓冲区中,这有助于我们在损失模块中引导 RNN 操作的计算(否则将用 0 初始化)。总而言之:不包含此 transform 不会对我们策略的训练产生巨大影响,但它会使循环键从收集的数据和回放缓冲区中消失,这反过来会导致训练稍不理想。幸运的是,我们提供的LSTMModule配备了一个辅助方法来为我们构建该 transform,所以我们可以等到构建它时再使用!
env = TransformedEnv(
GymEnv("CartPole-v1", from_pixels=True, device=device),
Compose(
ToTensorImage(),
GrayScale(),
Resize(84, 84),
StepCounter(),
InitTracker(),
RewardScaling(loc=0.0, scale=0.1),
ObservationNorm(standard_normal=True, in_keys=["pixels"]),
),
)
一如既往,我们需要手动初始化我们的归一化常数
env.transform[-1].init_stats(1000, reduce_dim=[0, 1, 2], cat_dim=0, keep_dims=[0])
td = env.reset()
策略¶
我们的策略将有 3 个组件:一个 ConvNet 主干网络、一个 LSTMModule 内存层和一个浅层 MLP 块,该块将 LSTM 输出映射到动作值上。
卷积网络¶
我们构建一个卷积网络,并在其两侧添加一个 torch.nn.AdaptiveAvgPool2d,它将输出压缩成大小为 64 的向量。ConvNet 可以帮助我们完成这项工作
feature = Mod(
ConvNet(
num_cells=[32, 32, 64],
squeeze_output=True,
aggregator_class=nn.AdaptiveAvgPool2d,
aggregator_kwargs={"output_size": (1, 1)},
device=device,
),
in_keys=["pixels"],
out_keys=["embed"],
)
我们在一批数据上执行第一个模块,以获取输出向量的大小
n_cells = feature(env.reset())["embed"].shape[-1]
LSTM 模块¶
TorchRL 提供了一个专门的 LSTMModule 类,用于在你的代码库中集成 LSTM。它是一个 TensorDictModuleBase 子类:因此,它有一组 in_keys 和 out_keys,指示在模块执行期间应读取和写入/更新哪些值。该类附带了这些属性的可自定义预定义值,以方便其构建。
注意
使用限制:该类支持几乎所有 LSTM 特性,例如 dropout 或多层 LSTM。然而,为了遵循 TorchRL 的约定,此 LSTM 的 batch_first 属性必须设置为 True,这在 PyTorch 中不是默认值。但是,我们的 LSTMModule 改变了此默认行为,因此我们可以直接调用它。
此外,LSTM 的 bidirectional 属性不能设置为 True因为其在在线设置中无法使用。在这种情况下,默认值是正确的。
lstm = LSTMModule(
input_size=n_cells,
hidden_size=128,
device=device,
in_key="embed",
out_key="embed",
)
让我们看看 LSTM Module 类,特别是它的 in_keys 和 out_keys
print("in_keys", lstm.in_keys)
print("out_keys", lstm.out_keys)
我们可以看到这些值包含我们指定的 in_key (和 out_key) 以及循环键名称。out_keys 前面有一个“next”前缀,表示它们需要写入“next” TensorDict 中。我们使用此约定(可以通过传递 in_keys/out_keys 参数来覆盖)来确保调用 step_mdp() 会将循环状态移动到根 TensorDict,使其在后续调用期间可供 RNN 使用(参见引言中的图)。
如前所述,我们还有一个可选的 transform 需要添加到我们的环境中,以确保循环状态被传递到缓冲区。make_tensordict_primer() 方法正是做这件事的
env.append_transform(lstm.make_tensordict_primer())
就这样!我们可以打印环境来检查一切是否正常,现在我们已经添加了 primer
print(env)
MLP¶
我们使用单层 MLP 来表示我们将用于策略的动作值。
mlp = MLP(
out_features=2,
num_cells=[
64,
],
device=device,
)
并将偏置填充为零
mlp[-1].bias.data.fill_(0.0)
mlp = Mod(mlp, in_keys=["embed"], out_keys=["action_value"])
使用 Q 值选择动作¶
我们策略的最后一部分是 Q 值模块。Q 值模块 QValueModule 将读取我们的 MLP 生成的 "action_values" 键,并从中获取具有最大值的动作。我们唯一需要做的就是指定动作空间,可以通过传递字符串或 action-spec 来完成。这允许我们使用 Categorical(有时称为“稀疏”)编码或其 one-hot 版本。
qval = QValueModule(action_space=None, spec=env.action_spec)
注意
TorchRL 还提供了一个包装类 torchrl.modules.QValueActor,它将一个模块与 QValueModule 一起包装在 Sequential 中,就像我们在此处明确做的一样。这样做的好处不大,过程也不太透明,但最终结果将与我们在此处做的相似。
现在我们可以将这些组件组合到一个 TensorDictSequential 中
policy = Seq(feature, lstm, mlp, qval)
DQN 是一个确定性算法,探索是其关键部分。我们将使用 \(\epsilon\)-greedy 策略,其中 epsilon 从 0.2 逐渐衰减到 0。这种衰减通过调用 step() 实现(参见下面的训练循环)。
exploration_module = EGreedyModule(
annealing_num_steps=1_000_000, spec=env.action_spec, eps_init=0.2
)
stoch_policy = TensorDictSequential(
policy,
exploration_module,
)
将模型用于损失计算¶
我们构建的模型非常适合在序列设置中使用。然而,torch.nn.LSTM 类可以使用 cuDNN 优化的后端在 GPU 设备上更快地运行 RNN 序列。我们不想错过这个加速训练循环的机会!
默认情况下,TorchRL 损失函数在执行任何 LSTMModule 或 GRUModule 的 forward 调用时会使用此功能。如果您需要手动控制,RNN 模块对一个上下文管理器/装饰器 set_recurrent_mode 敏感,它处理底层 RNN 模块的行为。
由于我们还有一些未初始化的参数,因此在创建优化器等之前应该对其进行初始化。
policy(env.reset())
DQN 损失¶
我们的 DQN 损失函数要求我们传入策略,并且再次传入动作空间。虽然这可能看起来是多余的,但很重要,因为我们要确保 DQNLoss 和 QValueModule 类兼容,但彼此之间没有强依赖关系。
为了使用 Double-DQN,我们需要一个 delay_value 参数,它会创建一个不可微分的网络参数副本,用作目标网络。
loss_fn = DQNLoss(policy, action_space=env.action_spec, delay_value=True)
由于我们使用双 DQN,我们需要更新目标参数。我们将使用 SoftUpdate 实例来执行此操作。
updater = SoftUpdate(loss_fn, eps=0.95)
optim = torch.optim.Adam(policy.parameters(), lr=3e-4)
Collector 和回放缓冲区¶
我们构建了最简单的数据 collector。我们将尝试使用一百万帧来训练我们的算法,每次向缓冲区扩展 50 帧。缓冲区将设计为存储 2 万条轨迹,每条轨迹 50 步。在每个优化步骤(每次数据收集 16 次)中,我们将从缓冲区收集 4 个项目,总共 200 个转换。我们将使用 LazyMemmapStorage 存储将数据保存在磁盘上。
注意
为了提高效率,我们在此处只运行了几千次迭代。在实际设置中,总帧数应设置为 100 万。
buffer_scratch_dir = tempfile.TemporaryDirectory().name
collector = SyncDataCollector(env, stoch_policy, frames_per_batch=50, total_frames=200)
rb = TensorDictReplayBuffer(
storage=LazyMemmapStorage(20_000, scratch_dir=buffer_scratch_dir),
batch_size=4,
prefetch=10,
)
训练循环¶
为了跟踪进度,我们每收集 50 次数据,就会在环境中运行一次策略,并在训练后绘制结果。
utd = 16
pbar = tqdm.tqdm(total=collector.total_frames)
longest = 0
traj_lens = []
for i, data in enumerate(collector):
if i == 0:
print(
"Let us print the first batch of data.\nPay attention to the key names "
"which will reflect what can be found in this data structure, in particular: "
"the output of the QValueModule (action_values, action and chosen_action_value),"
"the 'is_init' key that will tell us if a step is initial or not, and the "
"recurrent_state keys.\n",
data,
)
pbar.update(data.numel())
# it is important to pass data that is not flattened
rb.extend(data.unsqueeze(0).to_tensordict().cpu())
for _ in range(utd):
s = rb.sample().to(device, non_blocking=True)
loss_vals = loss_fn(s)
loss_vals["loss"].backward()
optim.step()
optim.zero_grad()
longest = max(longest, data["step_count"].max().item())
pbar.set_description(
f"steps: {longest}, loss_val: {loss_vals['loss'].item(): 4.4f}, action_spread: {data['action'].sum(0)}"
)
exploration_module.step(data.numel())
updater.step()
with set_exploration_type(ExplorationType.DETERMINISTIC), torch.no_grad():
rollout = env.rollout(10000, stoch_policy)
traj_lens.append(rollout.get(("next", "step_count")).max().item())
让我们绘制结果
if traj_lens:
from matplotlib import pyplot as plt
plt.plot(traj_lens)
plt.xlabel("Test collection")
plt.title("Test trajectory lengths")
结论¶
我们已经了解了如何在 TorchRL 的策略中集成 RNN。现在你应该能够
创建一个充当
TensorDictModule的 LSTM 模块通过
InitTrackertransform 指示 LSTM 模块需要重置将此模块集成到策略和损失模块中
确保 collector 知道循环状态条目,以便它们可以与其余数据一起存储在回放缓冲区中
延伸阅读¶
TorchRL 文档可以在这里找到。
