


注意
点击此处下载完整示例代码
加法合成¶
作者: Moto Hira
本教程是 振荡器和 ADSR 包络 的续篇。
本教程展示了如何使用 TorchAudio 的 DSP 函数执行加法合成和减法合成。
加法合成通过组合多个波形来创建音色。减法合成通过应用滤波器来创建音色。
import torch
import torchaudio
print(torch.__version__)
print(torchaudio.__version__)
2.7.0
2.7.0
概述¶
try:
from torchaudio.prototype.functional import adsr_envelope, extend_pitch, oscillator_bank
except ModuleNotFoundError:
print(
"Failed to import prototype DSP features. "
"Please install torchaudio nightly builds. "
"Please refer to https://pytorch.ac.cn/get-started/locally "
"for instructions to install a nightly build."
)
raise
import matplotlib.pyplot as plt
from IPython.display import Audio
创建多个频率音高¶
加法合成的核心是振荡器。我们通过叠加振荡器生成的多个波形来创建音色。
在 振荡器教程 中,我们使用了 oscillator_bank() 和 adsr_envelope() 来生成各种波形。
在本教程中,我们使用 extend_pitch() 从基频创建音色。
首先,我们定义一些在本教程中使用的常量和辅助函数。
PI = torch.pi
PI2 = 2 * torch.pi
F0 = 344.0 # fundamental frequency
DURATION = 1.1 # [seconds]
SAMPLE_RATE = 16_000 # [Hz]
NUM_FRAMES = int(DURATION * SAMPLE_RATE)
def plot(freq, amp, waveform, sample_rate, zoom=None, vol=0.1):
t = (torch.arange(waveform.size(0)) / sample_rate).numpy()
fig, axes = plt.subplots(4, 1, sharex=True)
axes[0].plot(t, freq.numpy())
axes[0].set(title=f"Oscillator bank (bank size: {amp.size(-1)})", ylabel="Frequency [Hz]", ylim=[-0.03, None])
axes[1].plot(t, amp.numpy())
axes[1].set(ylabel="Amplitude", ylim=[-0.03 if torch.all(amp >= 0.0) else None, None])
axes[2].plot(t, waveform)
axes[2].set(ylabel="Waveform")
axes[3].specgram(waveform, Fs=sample_rate)
axes[3].set(ylabel="Spectrogram", xlabel="Time [s]", xlim=[-0.01, t[-1] + 0.01])
for i in range(4):
axes[i].grid(True)
pos = axes[2].get_position()
fig.tight_layout()
if zoom is not None:
ax = fig.add_axes([pos.x0 + 0.02, pos.y0 + 0.03, pos.width / 2.5, pos.height / 2.0])
ax.plot(t, waveform)
ax.set(xlim=zoom, xticks=[], yticks=[])
waveform /= waveform.abs().max()
return Audio(vol * waveform, rate=sample_rate, normalize=False)
谐波泛音¶
谐波泛音是频率分量,其频率是基频的整数倍。
我们来看看如何生成合成器中常用的波形。即,
锯齿波
方波
三角波
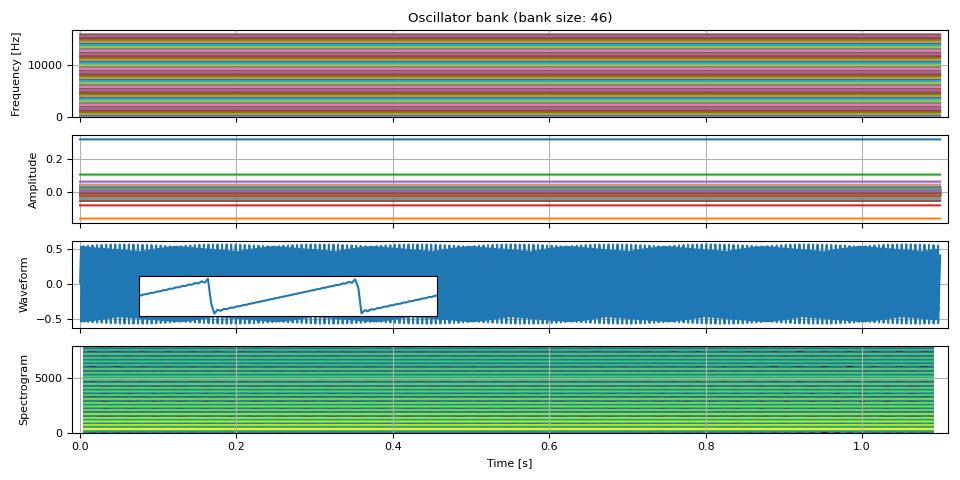
锯齿波¶
锯齿波可以表示如下。它包含所有整数次谐波,因此也常用于减法合成。
\[\begin{align*} y_t &= \sum_{k=1}^{K} A_k \sin ( 2 \pi f_k t ) \\ \text{where} \\ f_k &= k f_0 \\ A_k &= -\frac{ (-1) ^k }{k \pi} \end{align*}\]
以下函数接收基频和幅度,并根据上述公式添加扩展音高。
现在合成波形
freq0 = torch.full((NUM_FRAMES, 1), F0)
amp0 = torch.ones((NUM_FRAMES, 1))
freq, amp, waveform = sawtooth_wave(freq0, amp0, int(SAMPLE_RATE / F0), SAMPLE_RATE)
plot(freq, amp, waveform, SAMPLE_RATE, zoom=(1 / F0, 3 / F0))
/pytorch/audio/src/torchaudio/prototype/functional/_dsp.py:63: UserWarning: Some frequencies are above nyquist frequency. Setting the corresponding amplitude to zero. This might cause numerically unstable gradient.
warnings.warn(
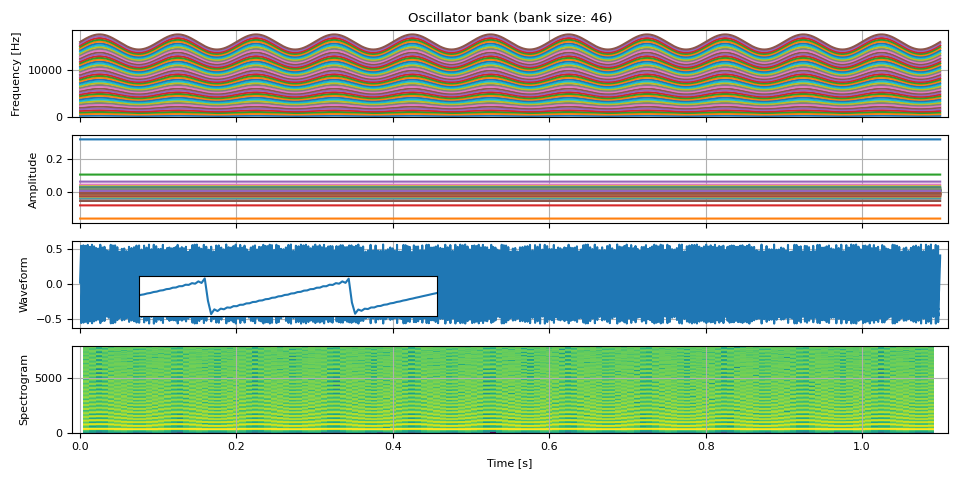
可以通过振荡基频来创建基于锯齿波的时变音调。
fm = 10 # rate at which the frequency oscillates [Hz]
f_dev = 0.1 * F0 # the degree of frequency oscillation [Hz]
phase = torch.linspace(0, fm * PI2 * DURATION, NUM_FRAMES)
freq0 = F0 + f_dev * torch.sin(phase).unsqueeze(-1)
freq, amp, waveform = sawtooth_wave(freq0, amp0, int(SAMPLE_RATE / F0), SAMPLE_RATE)
plot(freq, amp, waveform, SAMPLE_RATE, zoom=(1 / F0, 3 / F0))
/pytorch/audio/src/torchaudio/prototype/functional/_dsp.py:63: UserWarning: Some frequencies are above nyquist frequency. Setting the corresponding amplitude to zero. This might cause numerically unstable gradient.
warnings.warn(
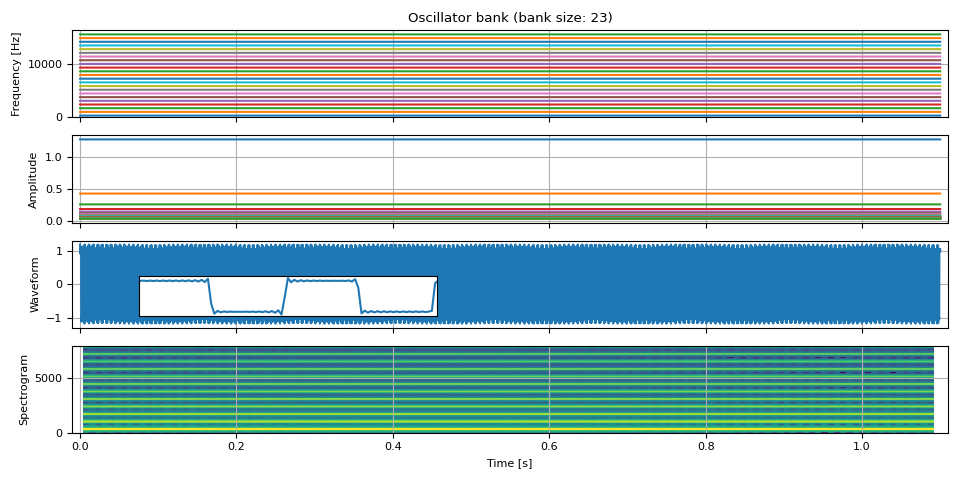
方波¶
方波仅包含奇数次谐波。
\[\begin{align*} y_t &= \sum_{k=0}^{K-1} A_k \sin ( 2 \pi f_k t ) \\ \text{where} \\ f_k &= n f_0 \\ A_k &= \frac{ 4 }{n \pi} \\ n &= 2k + 1 \end{align*}\]
def square_wave(freq0, amp0, num_pitches, sample_rate):
mults = [2.0 * i + 1.0 for i in range(num_pitches)]
freq = extend_pitch(freq0, mults)
mults = [4 / (PI * (2.0 * i + 1.0)) for i in range(num_pitches)]
amp = extend_pitch(amp0, mults)
waveform = oscillator_bank(freq, amp, sample_rate=sample_rate)
return freq, amp, waveform
freq0 = torch.full((NUM_FRAMES, 1), F0)
amp0 = torch.ones((NUM_FRAMES, 1))
freq, amp, waveform = square_wave(freq0, amp0, int(SAMPLE_RATE / F0 / 2), SAMPLE_RATE)
plot(freq, amp, waveform, SAMPLE_RATE, zoom=(1 / F0, 3 / F0))
/pytorch/audio/src/torchaudio/prototype/functional/_dsp.py:63: UserWarning: Some frequencies are above nyquist frequency. Setting the corresponding amplitude to zero. This might cause numerically unstable gradient.
warnings.warn(
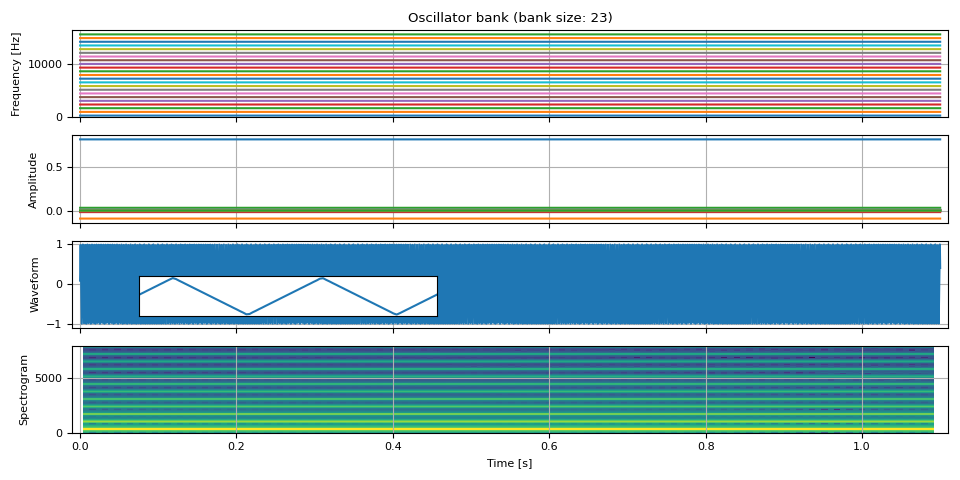
三角波¶
三角波也仅包含奇数次谐波。
\[\begin{align*} y_t &= \sum_{k=0}^{K-1} A_k \sin ( 2 \pi f_k t ) \\ \text{where} \\ f_k &= n f_0 \\ A_k &= (-1) ^ k \frac{8}{(n\pi) ^ 2} \\ n &= 2k + 1 \end{align*}\]
def triangle_wave(freq0, amp0, num_pitches, sample_rate):
mults = [2.0 * i + 1.0 for i in range(num_pitches)]
freq = extend_pitch(freq0, mults)
c = 8 / (PI**2)
mults = [c * ((-1) ** i) / ((2.0 * i + 1.0) ** 2) for i in range(num_pitches)]
amp = extend_pitch(amp0, mults)
waveform = oscillator_bank(freq, amp, sample_rate=sample_rate)
return freq, amp, waveform
freq, amp, waveform = triangle_wave(freq0, amp0, int(SAMPLE_RATE / F0 / 2), SAMPLE_RATE)
plot(freq, amp, waveform, SAMPLE_RATE, zoom=(1 / F0, 3 / F0))
/pytorch/audio/src/torchaudio/prototype/functional/_dsp.py:63: UserWarning: Some frequencies are above nyquist frequency. Setting the corresponding amplitude to zero. This might cause numerically unstable gradient.
warnings.warn(
非谐波分音¶
非谐波分音指频率不是基频整数倍的频率分量。
它们对于重现逼真的声音或使合成结果更有趣至关重要。
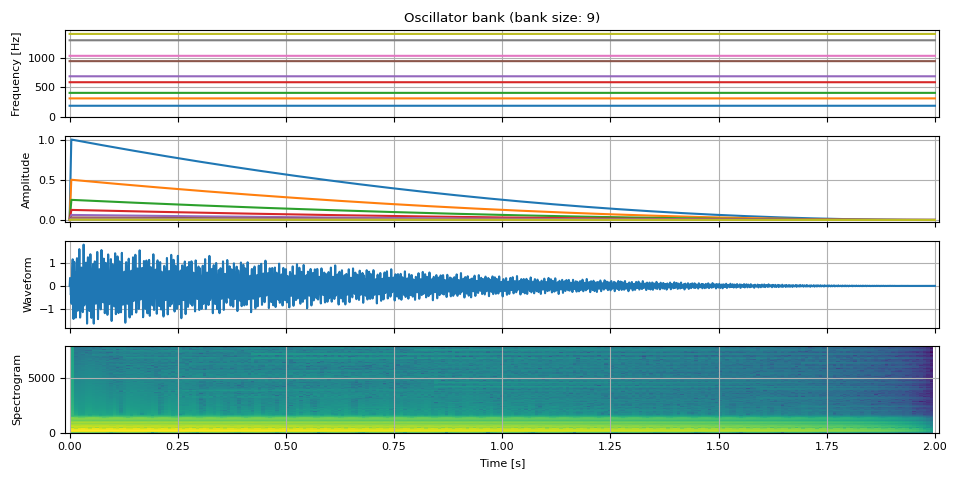
钟声¶
https://computermusicresource.com/Simple.bell.tutorial.html
num_tones = 9
duration = 2.0
num_frames = int(SAMPLE_RATE * duration)
freq0 = torch.full((num_frames, 1), F0)
mults = [0.56, 0.92, 1.19, 1.71, 2, 2.74, 3.0, 3.76, 4.07]
freq = extend_pitch(freq0, mults)
amp = adsr_envelope(
num_frames=num_frames,
attack=0.002,
decay=0.998,
sustain=0.0,
release=0.0,
n_decay=2,
)
amp = torch.stack([amp * (0.5**i) for i in range(num_tones)], dim=-1)
waveform = oscillator_bank(freq, amp, sample_rate=SAMPLE_RATE)
plot(freq, amp, waveform, SAMPLE_RATE, vol=0.4)
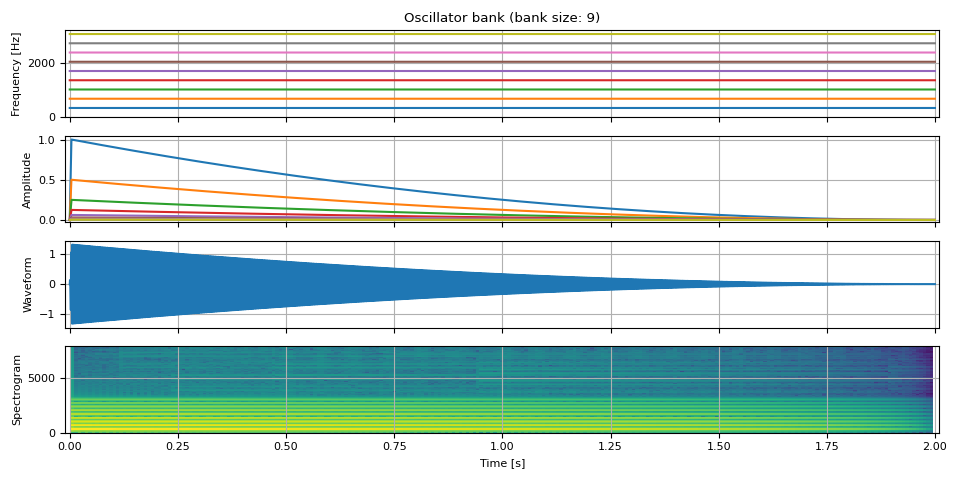
作为比较,以下是上述的谐波版本。只有频率值不同。泛音的数量和幅度相同。
参考¶
脚本总运行时间: ( 0 分 4.900 秒)
