


注意
点击此处下载完整的示例代码
使用 Hybrid Demucs 进行音乐源分离¶
作者: Sean Kim
本教程展示了如何使用 Hybrid Demucs 模型来执行音乐分离
1. 概述¶
执行音乐分离包含以下步骤
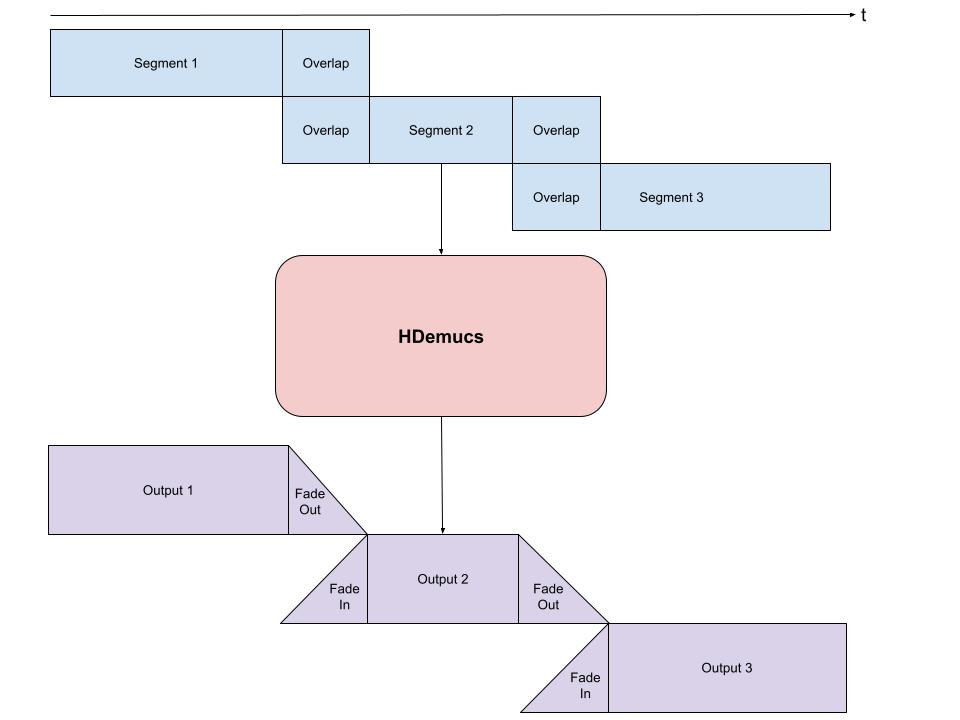
构建 Hybrid Demucs pipeline。
将波形格式化为预期大小的块,并循环处理这些块(有重叠),然后馈送至 pipeline。
收集输出块,并根据它们的重叠方式进行组合。
Hybrid Demucs [Défossez, 2021] 模型是 Demucs 模型的改进版本,Demucs 是一个基于波形的模型,可以将音乐分离成各自的源,例如人声、贝斯和鼓。Hybrid Demucs 有效地利用频谱图通过频域进行学习,并且也使用了时域卷积。
2. 准备工作¶
首先,我们安装必要的依赖项。首要的要求是 torchaudio 和 torch
import torch
import torchaudio
print(torch.__version__)
print(torchaudio.__version__)
import matplotlib.pyplot as plt
2.7.0
2.7.0
除了 torchaudio 外,mir_eval 也是必需的,用于执行信噪失真比 (SDR) 计算。要安装 mir_eval,请使用 pip3 install mir_eval。
from IPython.display import Audio
from mir_eval import separation
from torchaudio.pipelines import HDEMUCS_HIGH_MUSDB_PLUS
from torchaudio.utils import download_asset
3. 构建 pipeline¶
预训练模型权重和相关的 pipeline 组件打包为 torchaudio.pipelines.HDEMUCS_HIGH_MUSDB_PLUS()。这是一个 torchaudio.models.HDemucs 模型,在 MUSDB18-HQ 和额外的内部训练数据上训练得到。这个特定的模型适用于较高的采样率,约 44.1 kHZ,其模型实现中的 nfft 值为 4096,深度为 6。
bundle = HDEMUCS_HIGH_MUSDB_PLUS
model = bundle.get_model()
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model.to(device)
sample_rate = bundle.sample_rate
print(f"Sample rate: {sample_rate}")
0%| | 0.00/319M [00:00<?, ?B/s]
14%|#3 | 44.5M/319M [00:00<00:00, 467MB/s]
28%|##7 | 89.0M/319M [00:00<00:00, 463MB/s]
42%|####1 | 133M/319M [00:00<00:00, 455MB/s]
55%|#####5 | 177M/319M [00:00<00:00, 445MB/s]
69%|######9 | 221M/319M [00:00<00:00, 451MB/s]
83%|########2 | 264M/319M [00:00<00:00, 431MB/s]
97%|#########7| 310M/319M [00:00<00:00, 447MB/s]
100%|##########| 319M/319M [00:00<00:00, 445MB/s]
/pytorch/audio/src/torchaudio/pipelines/_source_separation_pipeline.py:56: FutureWarning: You are using `torch.load` with `weights_only=False` (the current default value), which uses the default pickle module implicitly. It is possible to construct malicious pickle data which will execute arbitrary code during unpickling (See https://github.com/pytorch/pytorch/blob/main/SECURITY.md#untrusted-models for more details). In a future release, the default value for `weights_only` will be flipped to `True`. This limits the functions that could be executed during unpickling. Arbitrary objects will no longer be allowed to be loaded via this mode unless they are explicitly allowlisted by the user via `torch.serialization.add_safe_globals`. We recommend you start setting `weights_only=True` for any use case where you don't have full control of the loaded file. Please open an issue on GitHub for any issues related to this experimental feature.
state_dict = torch.load(path)
Sample rate: 44100
4. 配置应用函数¶
由于 HDemucs 是一个大型且内存消耗大的模型,很难有足够的内存一次性将模型应用于整首歌曲。为了解决这一限制,可以通过将歌曲分块成更小的片段,然后逐块运行模型,再重新组合,从而获得整首歌曲的分离源。
这样做时,重要的是确保每个块之间有一定的重叠,以应对边缘处的伪影。由于模型的特性,有时边缘会包含不准确或不希望出现的声音。
我们在下方提供了一个分块和编排的示例实现。该实现对每一侧取 1 秒的重叠,然后对每一侧进行线性淡入淡出。使用淡化的重叠部分,我将这些片段加在一起,以确保整体音量恒定。这通过较少使用模型输出的边缘来处理伪影。
from torchaudio.transforms import Fade
def separate_sources(
model,
mix,
segment=10.0,
overlap=0.1,
device=None,
):
"""
Apply model to a given mixture. Use fade, and add segments together in order to add model segment by segment.
Args:
segment (int): segment length in seconds
device (torch.device, str, or None): if provided, device on which to
execute the computation, otherwise `mix.device` is assumed.
When `device` is different from `mix.device`, only local computations will
be on `device`, while the entire tracks will be stored on `mix.device`.
"""
if device is None:
device = mix.device
else:
device = torch.device(device)
batch, channels, length = mix.shape
chunk_len = int(sample_rate * segment * (1 + overlap))
start = 0
end = chunk_len
overlap_frames = overlap * sample_rate
fade = Fade(fade_in_len=0, fade_out_len=int(overlap_frames), fade_shape="linear")
final = torch.zeros(batch, len(model.sources), channels, length, device=device)
while start < length - overlap_frames:
chunk = mix[:, :, start:end]
with torch.no_grad():
out = model.forward(chunk)
out = fade(out)
final[:, :, :, start:end] += out
if start == 0:
fade.fade_in_len = int(overlap_frames)
start += int(chunk_len - overlap_frames)
else:
start += chunk_len
end += chunk_len
if end >= length:
fade.fade_out_len = 0
return final
def plot_spectrogram(stft, title="Spectrogram"):
magnitude = stft.abs()
spectrogram = 20 * torch.log10(magnitude + 1e-8).numpy()
_, axis = plt.subplots(1, 1)
axis.imshow(spectrogram, cmap="viridis", vmin=-60, vmax=0, origin="lower", aspect="auto")
axis.set_title(title)
plt.tight_layout()
5. 运行模型¶
最后,我们运行模型并将分离的源文件存储在一个目录中
作为测试歌曲,我们将使用来自 MedleyDB (Creative Commons BY-NC-SA 4.0) 的 NightOwl 的 A Classic Education。这首歌也位于 MUSDB18-HQ 数据集的 train 源中。
为了测试不同的歌曲,可以更改下面的变量名和 URL 以及参数,以便以不同的方式测试歌曲分离器。
# We download the audio file from our storage. Feel free to download another file and use audio from a specific path
SAMPLE_SONG = download_asset("tutorial-assets/hdemucs_mix.wav")
waveform, sample_rate = torchaudio.load(SAMPLE_SONG) # replace SAMPLE_SONG with desired path for different song
waveform = waveform.to(device)
mixture = waveform
# parameters
segment: int = 10
overlap = 0.1
print("Separating track")
ref = waveform.mean(0)
waveform = (waveform - ref.mean()) / ref.std() # normalization
sources = separate_sources(
model,
waveform[None],
device=device,
segment=segment,
overlap=overlap,
)[0]
sources = sources * ref.std() + ref.mean()
sources_list = model.sources
sources = list(sources)
audios = dict(zip(sources_list, sources))
0%| | 0.00/28.8M [00:00<?, ?B/s]
57%|#####7 | 16.5M/28.8M [00:00<00:00, 80.7MB/s]
100%|##########| 28.8M/28.8M [00:00<00:00, 104MB/s]
Separating track
5.1 分离音轨¶
已加载的默认预训练权重集包含 4 个要分离的源:依次是鼓、贝斯、其他和人声。它们已存储在字典“audios”中,因此可以在那里访问。对于这四个源,每个都有一个单独的单元格,用于创建音频、频谱图以及计算 SDR 分数。SDR 是信噪失真比,本质上是音频轨道的“质量”表示。
N_FFT = 4096
N_HOP = 4
stft = torchaudio.transforms.Spectrogram(
n_fft=N_FFT,
hop_length=N_HOP,
power=None,
)
5.2 音频分段和处理¶
下方是处理步骤和将音轨分段 5 秒的操作,以便馈送至频谱图并计算相应的 SDR 分数。
def output_results(original_source: torch.Tensor, predicted_source: torch.Tensor, source: str):
print(
"SDR score is:",
separation.bss_eval_sources(original_source.detach().numpy(), predicted_source.detach().numpy())[0].mean(),
)
plot_spectrogram(stft(predicted_source)[0], f"Spectrogram - {source}")
return Audio(predicted_source, rate=sample_rate)
segment_start = 150
segment_end = 155
frame_start = segment_start * sample_rate
frame_end = segment_end * sample_rate
drums_original = download_asset("tutorial-assets/hdemucs_drums_segment.wav")
bass_original = download_asset("tutorial-assets/hdemucs_bass_segment.wav")
vocals_original = download_asset("tutorial-assets/hdemucs_vocals_segment.wav")
other_original = download_asset("tutorial-assets/hdemucs_other_segment.wav")
drums_spec = audios["drums"][:, frame_start:frame_end].cpu()
drums, sample_rate = torchaudio.load(drums_original)
bass_spec = audios["bass"][:, frame_start:frame_end].cpu()
bass, sample_rate = torchaudio.load(bass_original)
vocals_spec = audios["vocals"][:, frame_start:frame_end].cpu()
vocals, sample_rate = torchaudio.load(vocals_original)
other_spec = audios["other"][:, frame_start:frame_end].cpu()
other, sample_rate = torchaudio.load(other_original)
mix_spec = mixture[:, frame_start:frame_end].cpu()
0%| | 0.00/1.68M [00:00<?, ?B/s]
100%|##########| 1.68M/1.68M [00:00<00:00, 67.9MB/s]
0%| | 0.00/1.68M [00:00<?, ?B/s]
100%|##########| 1.68M/1.68M [00:00<00:00, 102MB/s]
0%| | 0.00/1.68M [00:00<?, ?B/s]
100%|##########| 1.68M/1.68M [00:00<00:00, 171MB/s]
0%| | 0.00/1.68M [00:00<?, ?B/s]
100%|##########| 1.68M/1.68M [00:00<00:00, 120MB/s]
5.3 频谱图和音频¶
在接下来的 5 个单元格中,您可以看到带有相应音频的频谱图。可以使用频谱图清晰地可视化音频。
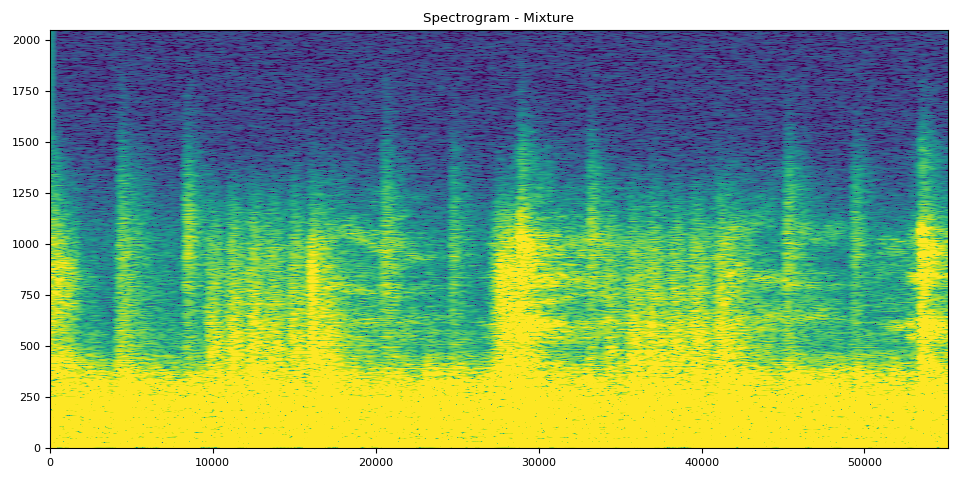
混合片段来自原始音轨,其余音轨是模型的输出
# Mixture Clip
plot_spectrogram(stft(mix_spec)[0], "Spectrogram - Mixture")
Audio(mix_spec, rate=sample_rate)
鼓的 SDR、频谱图和音频
# Drums Clip
output_results(drums, drums_spec, "drums")
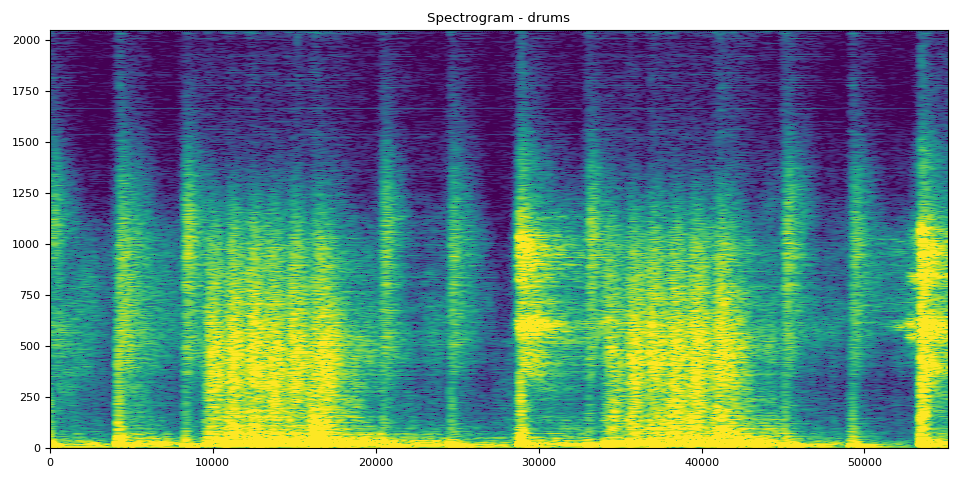
SDR score is: 4.964477475897244
贝斯的 SDR、频谱图和音频
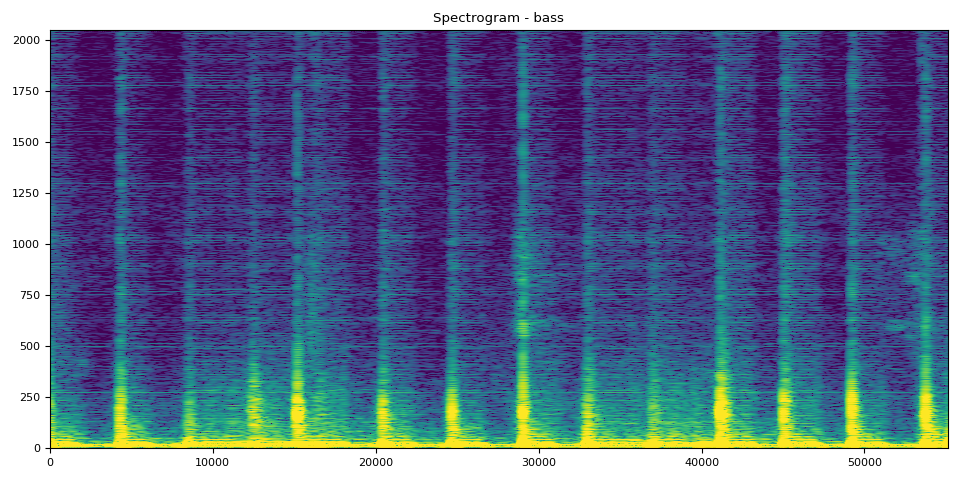
SDR score is: 18.90589959575034
人声的 SDR、频谱图和音频
# Vocals Audio
output_results(vocals, vocals_spec, "vocals")
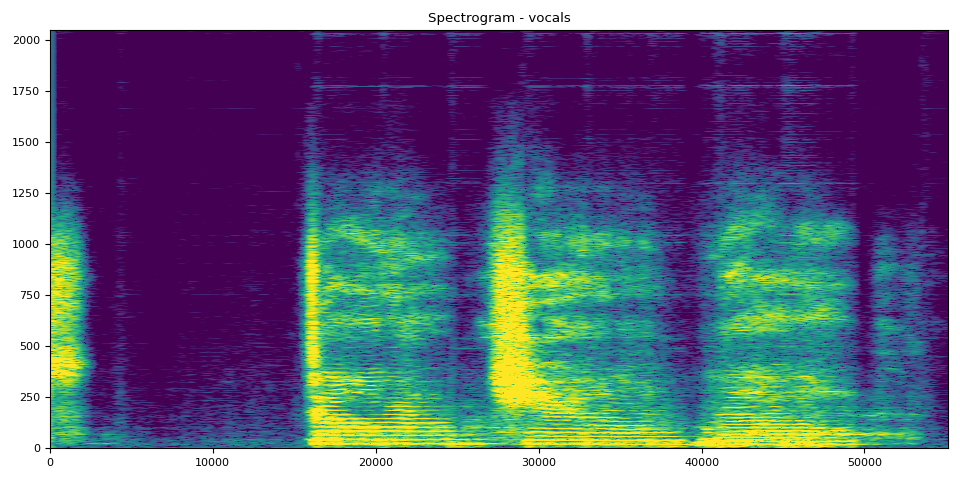
SDR score is: 8.792372276328596
其他的 SDR、频谱图和音频
# Other Clip
output_results(other, other_spec, "other")
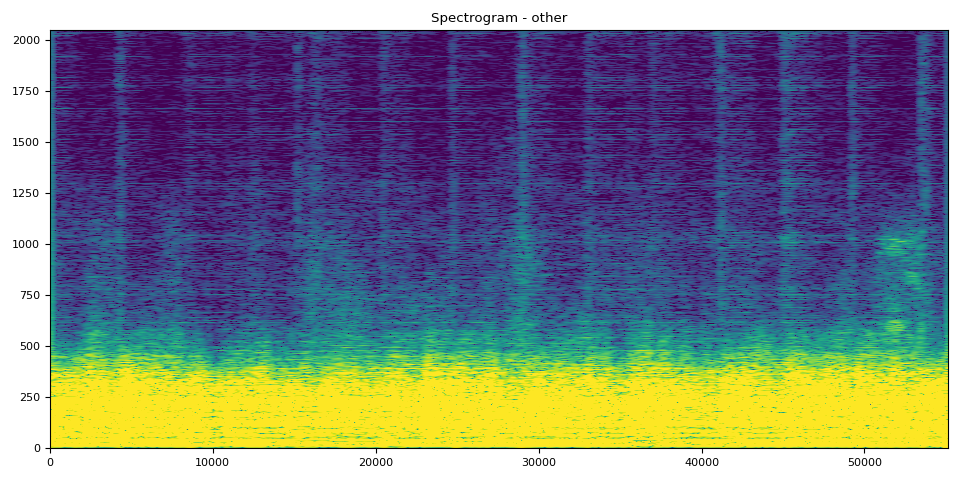
SDR score is: 8.866964245665635
# Optionally, the full audios can be heard in from running the next 5
# cells. They will take a bit longer to load, so to run simply uncomment
# out the ``Audio`` cells for the respective track to produce the audio
# for the full song.
#
# Full Audio
# Audio(mixture, rate=sample_rate)
# Drums Audio
# Audio(audios["drums"], rate=sample_rate)
# Bass Audio
# Audio(audios["bass"], rate=sample_rate)
# Vocals Audio
# Audio(audios["vocals"], rate=sample_rate)
# Other Audio
# Audio(audios["other"], rate=sample_rate)
脚本总运行时间:( 0 分 25.315 秒)
