


注意
点击此处下载完整示例代码
使用 Wav2Vec2 进行语音识别¶
作者: Moto Hira
本教程展示了如何使用 wav2vec 2.0 的预训练模型进行语音识别 [论文]。
概述¶
语音识别过程如下所示。
从音频波形中提取声学特征
逐帧估计声学特征的类别
从类别概率序列生成假设
Torchaudio 提供了对预训练权重及相关信息(如期望采样率和类别标签)的便捷访问。它们被捆绑在一起,可在 torchaudio.pipelines 模块下找到。
准备工作¶
import torch
import torchaudio
print(torch.__version__)
print(torchaudio.__version__)
torch.random.manual_seed(0)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)
2.7.0
2.7.0
cuda
import IPython
import matplotlib.pyplot as plt
from torchaudio.utils import download_asset
SPEECH_FILE = download_asset("tutorial-assets/Lab41-SRI-VOiCES-src-sp0307-ch127535-sg0042.wav")
0%| | 0.00/106k [00:00<?, ?B/s]
100%|##########| 106k/106k [00:00<00:00, 62.6MB/s]
创建 pipeline¶
首先,我们将创建一个执行特征提取和分类的 Wav2Vec2 模型。
torchaudio 中提供两种类型的 Wav2Vec2 预训练权重。一种是针对 ASR 任务微调过的,另一种是未微调的。
Wav2Vec2(和 HuBERT)模型以自监督方式进行训练。它们首先仅使用音频进行表示学习,然后使用附加标签针对特定任务进行微调。
未经微调的预训练权重也可以针对其他下游任务进行微调,但本教程不涵盖这部分内容。
我们这里将使用 torchaudio.pipelines.WAV2VEC2_ASR_BASE_960H。
torchaudio.pipelines 中提供了多个预训练模型。请查看文档了解它们是如何训练的详细信息。
bundle 对象提供了实例化模型及其他信息的接口。采样率和类别标签如下所示。
bundle = torchaudio.pipelines.WAV2VEC2_ASR_BASE_960H
print("Sample Rate:", bundle.sample_rate)
print("Labels:", bundle.get_labels())
Sample Rate: 16000
Labels: ('-', '|', 'E', 'T', 'A', 'O', 'N', 'I', 'H', 'S', 'R', 'D', 'L', 'U', 'M', 'W', 'C', 'F', 'G', 'Y', 'P', 'B', 'V', 'K', "'", 'X', 'J', 'Q', 'Z')
模型可以按如下方式构建。此过程将自动获取预训练权重并将其加载到模型中。
model = bundle.get_model().to(device)
print(model.__class__)
Downloading: "https://download.pytorch.org/torchaudio/models/wav2vec2_fairseq_base_ls960_asr_ls960.pth" to /root/.cache/torch/hub/checkpoints/wav2vec2_fairseq_base_ls960_asr_ls960.pth
0%| | 0.00/360M [00:00<?, ?B/s]
16%|#5 | 56.8M/360M [00:00<00:00, 594MB/s]
32%|###1 | 114M/360M [00:00<00:00, 595MB/s]
47%|####7 | 170M/360M [00:00<00:00, 595MB/s]
63%|######3 | 227M/360M [00:00<00:00, 585MB/s]
79%|#######8 | 284M/360M [00:00<00:00, 589MB/s]
95%|#########4| 341M/360M [00:00<00:00, 591MB/s]
100%|##########| 360M/360M [00:00<00:00, 590MB/s]
<class 'torchaudio.models.wav2vec2.model.Wav2Vec2Model'>
加载数据¶
我们将使用来自 VOiCES 数据集的语音数据,该数据集根据 Creative Commons BY 4.0 许可。
IPython.display.Audio(SPEECH_FILE)
要加载数据,我们使用 torchaudio.load()。
如果采样率与 pipeline 期望的不同,我们可以使用 torchaudio.functional.resample() 进行重采样。
注意
torchaudio.functional.resample()也适用于 CUDA tensors。在同一组采样率上多次执行重采样时,使用
torchaudio.transforms.Resample可能会提高性能。
waveform, sample_rate = torchaudio.load(SPEECH_FILE)
waveform = waveform.to(device)
if sample_rate != bundle.sample_rate:
waveform = torchaudio.functional.resample(waveform, sample_rate, bundle.sample_rate)
提取声学特征¶
下一步是从音频中提取声学特征。
注意
针对 ASR 任务微调的 Wav2Vec2 模型可以一步执行特征提取和分类,但为了教程的目的,我们在这里也展示了如何执行特征提取。
with torch.inference_mode():
features, _ = model.extract_features(waveform)
返回的 features 是一个 tensors 列表。每个 tensor 是一个 transformer 层的输出。
fig, ax = plt.subplots(len(features), 1, figsize=(16, 4.3 * len(features)))
for i, feats in enumerate(features):
ax[i].imshow(feats[0].cpu(), interpolation="nearest")
ax[i].set_title(f"Feature from transformer layer {i+1}")
ax[i].set_xlabel("Feature dimension")
ax[i].set_ylabel("Frame (time-axis)")
fig.tight_layout()
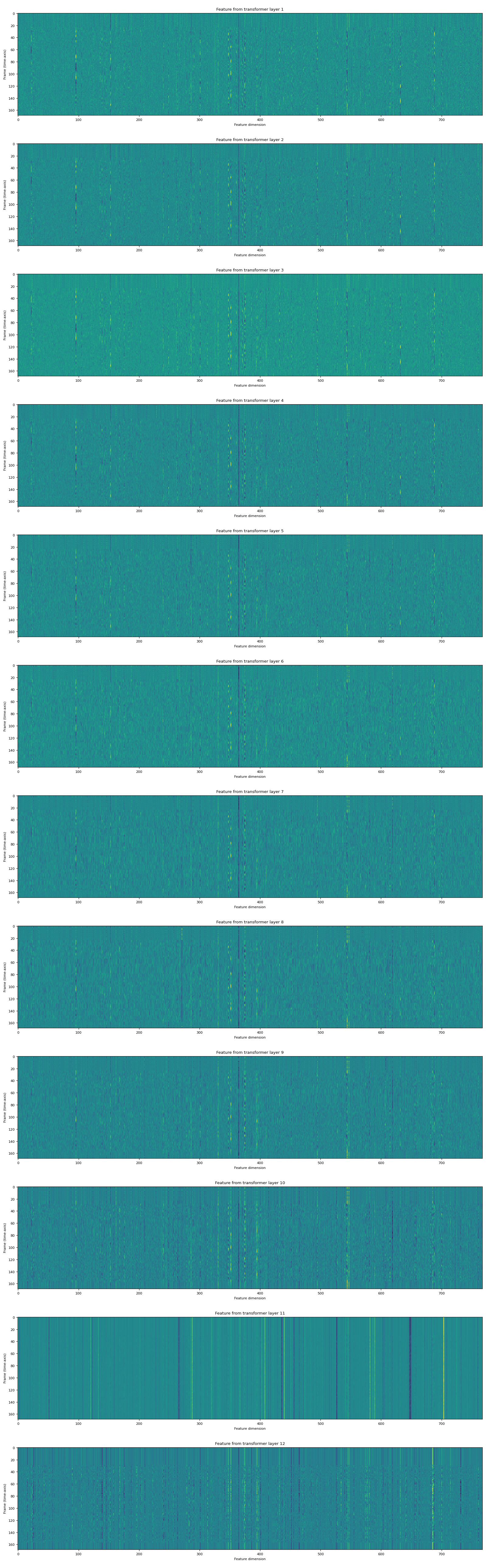
特征分类¶
提取声学特征后,下一步是将它们分类到一组类别中。
Wav2Vec2 模型提供了在一个步骤中执行特征提取和分类的方法。
with torch.inference_mode():
emission, _ = model(waveform)
输出是 logits 的形式。它不是概率的形式。
让我们将其可视化。
plt.imshow(emission[0].cpu().T, interpolation="nearest")
plt.title("Classification result")
plt.xlabel("Frame (time-axis)")
plt.ylabel("Class")
plt.tight_layout()
print("Class labels:", bundle.get_labels())
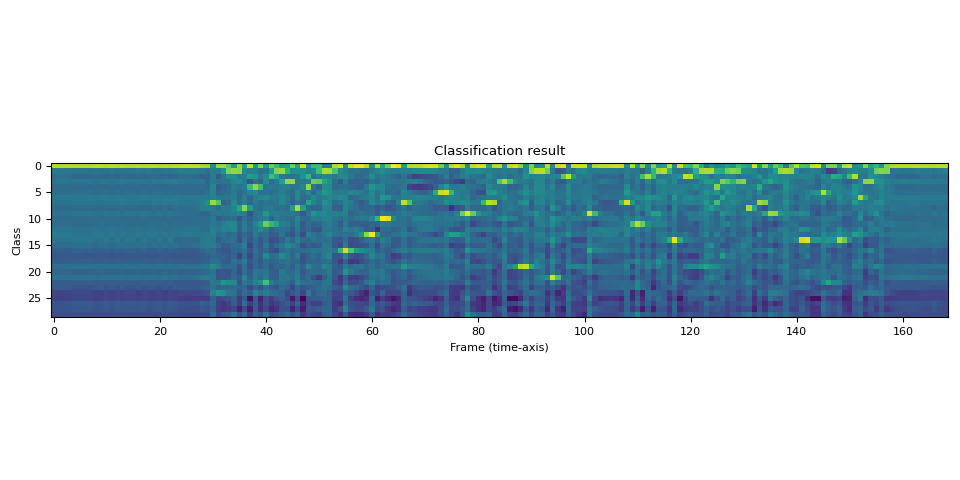
Class labels: ('-', '|', 'E', 'T', 'A', 'O', 'N', 'I', 'H', 'S', 'R', 'D', 'L', 'U', 'M', 'W', 'C', 'F', 'G', 'Y', 'P', 'B', 'V', 'K', "'", 'X', 'J', 'Q', 'Z')
我们可以看到在时间线上某些标签有很强的指示性。
生成转录文本¶
从标签概率序列中,现在我们想生成转录文本。生成假设的过程通常称为“解码”。
解码比简单分类更复杂,因为某个时间步长的解码可能受到周围观测的影响。
例如,以单词 night 和 knight 为例。即使它们的先验概率分布不同(在典型对话中,night 出现的频率远高于 knight),为了准确生成包含 knight 的转录文本,例如 a knight with a sword,解码过程必须推迟最终决定,直到看到足够的上下文。
已经提出了许多解码技术,它们需要外部资源,例如词典和语言模型。
在本教程中,为了简单起见,我们将执行贪婪解码(greedy decoding),它不依赖于此类外部组件,并且只在每个时间步长选择最佳假设。因此,上下文信息不会被使用,并且只能生成一个转录文本。
我们首先定义贪婪解码算法。
class GreedyCTCDecoder(torch.nn.Module):
def __init__(self, labels, blank=0):
super().__init__()
self.labels = labels
self.blank = blank
def forward(self, emission: torch.Tensor) -> str:
"""Given a sequence emission over labels, get the best path string
Args:
emission (Tensor): Logit tensors. Shape `[num_seq, num_label]`.
Returns:
str: The resulting transcript
"""
indices = torch.argmax(emission, dim=-1) # [num_seq,]
indices = torch.unique_consecutive(indices, dim=-1)
indices = [i for i in indices if i != self.blank]
return "".join([self.labels[i] for i in indices])
现在创建解码器对象并解码转录文本。
decoder = GreedyCTCDecoder(labels=bundle.get_labels())
transcript = decoder(emission[0])
让我们检查结果并再次聆听音频。
print(transcript)
IPython.display.Audio(SPEECH_FILE)
I|HAD|THAT|CURIOSITY|BESIDE|ME|AT|THIS|MOMENT|
ASR 模型使用称为连接时序分类 (CTC) 的损失函数进行微调。CTC 损失的详细信息在此处解释。在 CTC 中,空白标记 (ϵ) 是一个特殊标记,表示前一个符号的重复。在解码时,这些空白标记被简单忽略。
结论¶
在本教程中,我们探讨了如何使用 Wav2Vec2ASRBundle 进行声学特征提取和语音识别。构建模型并获取输出只需两行代码。
model = torchaudio.pipelines.WAV2VEC2_ASR_BASE_960H.get_model()
emission = model(waveforms, ...)
脚本总运行时间: ( 0 分钟 4.546 秒)
