


注意
点击 这里 下载完整示例代码
使用 Wav2Vec2 进行强制对齐¶
作者: Moto Hira
本教程展示了如何使用 torchaudio,利用 CTC 分割算法(详见 CTC-Segmentation of Large Corpora for German End-to-end Speech Recognition)将文本对齐到语音。
注意
本教程最初编写旨在说明 Wav2Vec2 预训练模型的一个用例。
TorchAudio 现在提供一套专为强制对齐设计的 API。CTC 强制对齐 API 教程 说明了核心 API torchaudio.functional.forced_align() 的用法。
如果您希望对齐您的语料库,我们建议使用 torchaudio.pipelines.Wav2Vec2FABundle,它将 forced_align() 及其他支持函数与专门针对强制对齐训练的预训练模型结合在一起。请参阅 多语言数据的强制对齐,其中说明了其用法。
import torch
import torchaudio
print(torch.__version__)
print(torchaudio.__version__)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)
2.7.0
2.7.0
cuda
概述¶
对齐过程如下所示。
从音频波形估计逐帧标签概率
生成格栅矩阵,表示标签在时间步对齐的概率。
从格栅矩阵中找到最可能的路径。
在此示例中,我们使用 torchaudio 的 Wav2Vec2 模型进行声学特征提取。
准备工作¶
首先,我们导入必要的包,并获取我们要处理的数据。
from dataclasses import dataclass
import IPython
import matplotlib.pyplot as plt
torch.random.manual_seed(0)
SPEECH_FILE = torchaudio.utils.download_asset("tutorial-assets/Lab41-SRI-VOiCES-src-sp0307-ch127535-sg0042.wav")
生成逐帧标签概率¶
第一步是生成每个音频帧的标签类别概率。我们可以使用经过 ASR 训练的 Wav2Vec2 模型。这里我们使用 torchaudio.pipelines.WAV2VEC2_ASR_BASE_960H()。
torchaudio 提供对带有相关标签的预训练模型的便捷访问。
注意
在后续章节中,我们将在对数域中计算概率以避免数值不稳定。为此,我们使用 torch.log_softmax() 对发射概率进行归一化。
bundle = torchaudio.pipelines.WAV2VEC2_ASR_BASE_960H
model = bundle.get_model().to(device)
labels = bundle.get_labels()
with torch.inference_mode():
waveform, _ = torchaudio.load(SPEECH_FILE)
emissions, _ = model(waveform.to(device))
emissions = torch.log_softmax(emissions, dim=-1)
emission = emissions[0].cpu().detach()
print(labels)
('-', '|', 'E', 'T', 'A', 'O', 'N', 'I', 'H', 'S', 'R', 'D', 'L', 'U', 'M', 'W', 'C', 'F', 'G', 'Y', 'P', 'B', 'V', 'K', "'", 'X', 'J', 'Q', 'Z')
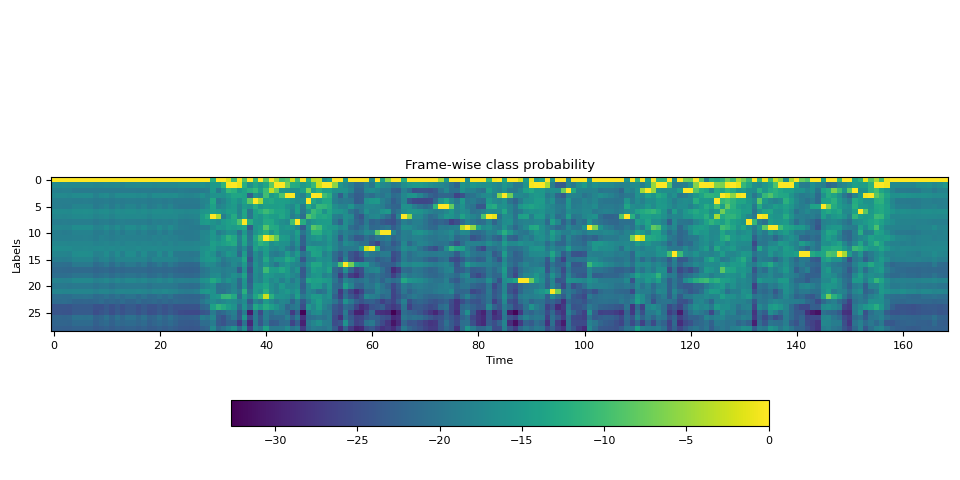
可视化¶
def plot():
fig, ax = plt.subplots()
img = ax.imshow(emission.T)
ax.set_title("Frame-wise class probability")
ax.set_xlabel("Time")
ax.set_ylabel("Labels")
fig.colorbar(img, ax=ax, shrink=0.6, location="bottom")
fig.tight_layout()
plot()
生成对齐概率(格栅)¶
接下来,我们从发射矩阵生成格栅,格栅表示文本标签在每个时间帧出现的概率。
格栅是具有时间轴和标签轴的二维矩阵。标签轴表示我们要对齐的文本。在下文中,我们使用 \(t\) 表示时间轴的索引,使用 \(j\) 表示标签轴的索引。\(c_j\) 表示标签索引 \(j\) 处的标签。
为了生成时间步长 \(t+1\) 的概率,我们查看时间步长 \(t\) 的格栅以及时间步长 \(t+1\) 的发射概率。有两条路径可以达到时间步长 \(t+1\) 并带有标签 \(c_{j+1}\)。第一种情况是标签在 \(t\) 时是 \(c_{j+1}\),并且从 \(t\) 到 \(t+1\) 没有标签变化。另一种情况是标签在 \(t\) 时是 \(c_j\),并且在 \(t+1\) 时转换到下一个标签 \(c_{j+1}\)。
下图说明了这种转换。
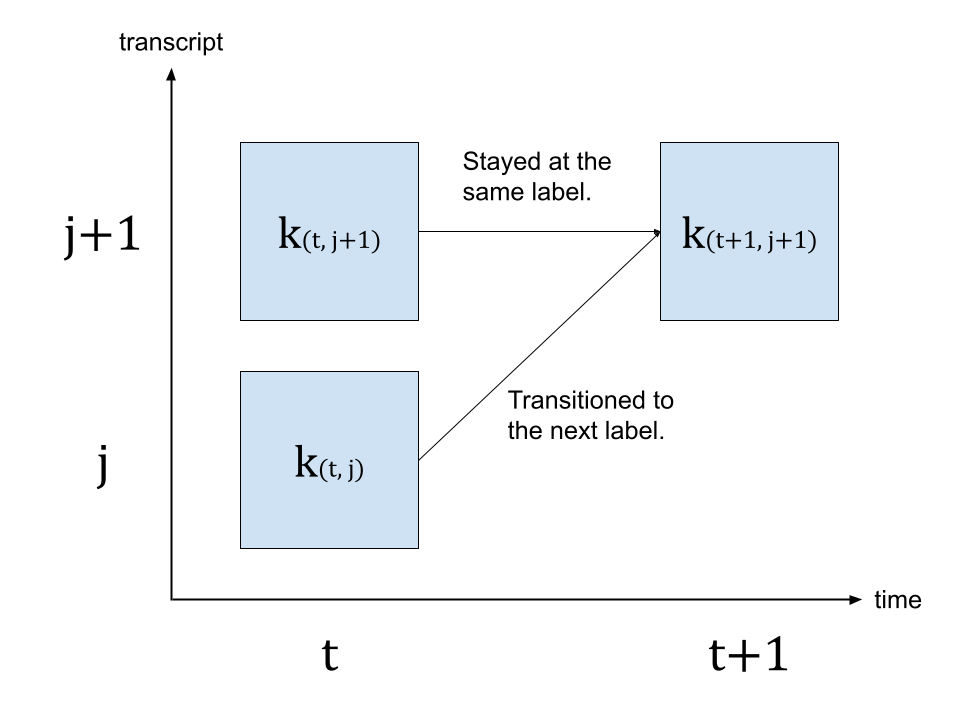
由于我们正在寻找最可能的转换,因此我们取 \(k_{(t+1, j+1)}\) 值的更可能路径,即
\(k_{(t+1, j+1)} = max( k_{(t, j)} p(t+1, c_{j+1}), k_{(t, j+1)} p(t+1, repeat) )\)
其中 \(k\) 表示格栅矩阵,\(p(t, c_j)\) 表示时间步长 \(t\) 处标签 \(c_j\) 的概率。\(repeat\) 表示 CTC 公式中的空白符。(有关 CTC 算法的详细信息,请参阅 Sequence Modeling with CTC [distill.pub])
# We enclose the transcript with space tokens, which represent SOS and EOS.
transcript = "|I|HAD|THAT|CURIOSITY|BESIDE|ME|AT|THIS|MOMENT|"
dictionary = {c: i for i, c in enumerate(labels)}
tokens = [dictionary[c] for c in transcript]
print(list(zip(transcript, tokens)))
def get_trellis(emission, tokens, blank_id=0):
num_frame = emission.size(0)
num_tokens = len(tokens)
trellis = torch.zeros((num_frame, num_tokens))
trellis[1:, 0] = torch.cumsum(emission[1:, blank_id], 0)
trellis[0, 1:] = -float("inf")
trellis[-num_tokens + 1 :, 0] = float("inf")
for t in range(num_frame - 1):
trellis[t + 1, 1:] = torch.maximum(
# Score for staying at the same token
trellis[t, 1:] + emission[t, blank_id],
# Score for changing to the next token
trellis[t, :-1] + emission[t, tokens[1:]],
)
return trellis
trellis = get_trellis(emission, tokens)
[('|', 1), ('I', 7), ('|', 1), ('H', 8), ('A', 4), ('D', 11), ('|', 1), ('T', 3), ('H', 8), ('A', 4), ('T', 3), ('|', 1), ('C', 16), ('U', 13), ('R', 10), ('I', 7), ('O', 5), ('S', 9), ('I', 7), ('T', 3), ('Y', 19), ('|', 1), ('B', 21), ('E', 2), ('S', 9), ('I', 7), ('D', 11), ('E', 2), ('|', 1), ('M', 14), ('E', 2), ('|', 1), ('A', 4), ('T', 3), ('|', 1), ('T', 3), ('H', 8), ('I', 7), ('S', 9), ('|', 1), ('M', 14), ('O', 5), ('M', 14), ('E', 2), ('N', 6), ('T', 3), ('|', 1)]
可视化¶
def plot():
fig, ax = plt.subplots()
img = ax.imshow(trellis.T, origin="lower")
ax.annotate("- Inf", (trellis.size(1) / 5, trellis.size(1) / 1.5))
ax.annotate("+ Inf", (trellis.size(0) - trellis.size(1) / 5, trellis.size(1) / 3))
fig.colorbar(img, ax=ax, shrink=0.6, location="bottom")
fig.tight_layout()
plot()
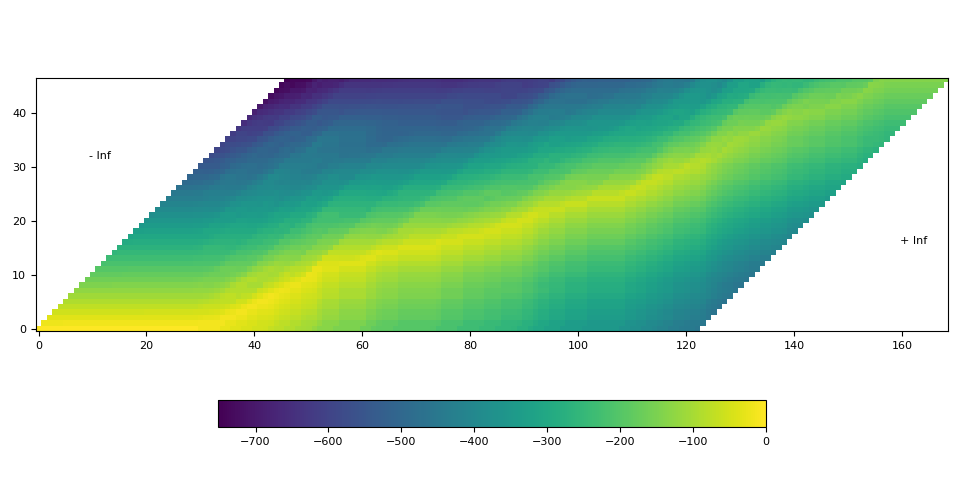
在上面的可视化中,我们可以看到对角线穿过矩阵的高概率轨迹。
找到最可能的路径(回溯)¶
生成格栅后,我们将沿着高概率元素遍历它。
我们将从概率最高的时间步长的最后一个标签索引开始,然后及时回溯,根据转换后概率 \(k_{t, j} p(t+1, c_{j+1})\) 或 \(k_{t, j+1} p(t+1, repeat)\) 选择保持 (\(c_j \rightarrow c_j\)) 或转换 (\(c_j \rightarrow c_{j+1}\))。
一旦标签到达开头,转换就完成。
格栅矩阵用于路径查找,但对于每个段的最终概率,我们取自发射矩阵的逐帧概率。
@dataclass
class Point:
token_index: int
time_index: int
score: float
def backtrack(trellis, emission, tokens, blank_id=0):
t, j = trellis.size(0) - 1, trellis.size(1) - 1
path = [Point(j, t, emission[t, blank_id].exp().item())]
while j > 0:
# Should not happen but just in case
assert t > 0
# 1. Figure out if the current position was stay or change
# Frame-wise score of stay vs change
p_stay = emission[t - 1, blank_id]
p_change = emission[t - 1, tokens[j]]
# Context-aware score for stay vs change
stayed = trellis[t - 1, j] + p_stay
changed = trellis[t - 1, j - 1] + p_change
# Update position
t -= 1
if changed > stayed:
j -= 1
# Store the path with frame-wise probability.
prob = (p_change if changed > stayed else p_stay).exp().item()
path.append(Point(j, t, prob))
# Now j == 0, which means, it reached the SoS.
# Fill up the rest for the sake of visualization
while t > 0:
prob = emission[t - 1, blank_id].exp().item()
path.append(Point(j, t - 1, prob))
t -= 1
return path[::-1]
path = backtrack(trellis, emission, tokens)
for p in path:
print(p)
Point(token_index=0, time_index=0, score=0.9999996423721313)
Point(token_index=0, time_index=1, score=0.9999996423721313)
Point(token_index=0, time_index=2, score=0.9999996423721313)
Point(token_index=0, time_index=3, score=0.9999996423721313)
Point(token_index=0, time_index=4, score=0.9999996423721313)
Point(token_index=0, time_index=5, score=0.9999996423721313)
Point(token_index=0, time_index=6, score=0.9999996423721313)
Point(token_index=0, time_index=7, score=0.9999996423721313)
Point(token_index=0, time_index=8, score=0.9999998807907104)
Point(token_index=0, time_index=9, score=0.9999996423721313)
Point(token_index=0, time_index=10, score=0.9999996423721313)
Point(token_index=0, time_index=11, score=0.9999998807907104)
Point(token_index=0, time_index=12, score=0.9999996423721313)
Point(token_index=0, time_index=13, score=0.9999996423721313)
Point(token_index=0, time_index=14, score=0.9999996423721313)
Point(token_index=0, time_index=15, score=0.9999996423721313)
Point(token_index=0, time_index=16, score=0.9999996423721313)
Point(token_index=0, time_index=17, score=0.9999996423721313)
Point(token_index=0, time_index=18, score=0.9999998807907104)
Point(token_index=0, time_index=19, score=0.9999996423721313)
Point(token_index=0, time_index=20, score=0.9999996423721313)
Point(token_index=0, time_index=21, score=0.9999996423721313)
Point(token_index=0, time_index=22, score=0.9999996423721313)
Point(token_index=0, time_index=23, score=0.9999997615814209)
Point(token_index=0, time_index=24, score=0.9999998807907104)
Point(token_index=0, time_index=25, score=0.9999998807907104)
Point(token_index=0, time_index=26, score=0.9999998807907104)
Point(token_index=0, time_index=27, score=0.9999998807907104)
Point(token_index=0, time_index=28, score=0.9999985694885254)
Point(token_index=0, time_index=29, score=0.9999943971633911)
Point(token_index=0, time_index=30, score=0.9999842643737793)
Point(token_index=1, time_index=31, score=0.9846118092536926)
Point(token_index=1, time_index=32, score=0.9999706745147705)
Point(token_index=1, time_index=33, score=0.15352763235569)
Point(token_index=1, time_index=34, score=0.9999172687530518)
Point(token_index=2, time_index=35, score=0.6091406941413879)
Point(token_index=2, time_index=36, score=0.9997723698616028)
Point(token_index=3, time_index=37, score=0.9997134804725647)
Point(token_index=3, time_index=38, score=0.9999358654022217)
Point(token_index=4, time_index=39, score=0.986176073551178)
Point(token_index=4, time_index=40, score=0.9241712093353271)
Point(token_index=5, time_index=41, score=0.9259618520736694)
Point(token_index=5, time_index=42, score=0.01559634879231453)
Point(token_index=5, time_index=43, score=0.9998377561569214)
Point(token_index=6, time_index=44, score=0.998847484588623)
Point(token_index=7, time_index=45, score=0.10197910666465759)
Point(token_index=7, time_index=46, score=0.9999427795410156)
Point(token_index=8, time_index=47, score=0.9999943971633911)
Point(token_index=8, time_index=48, score=0.9979596138000488)
Point(token_index=9, time_index=49, score=0.035976238548755646)
Point(token_index=9, time_index=50, score=0.06177717074751854)
Point(token_index=9, time_index=51, score=4.336948768468574e-05)
Point(token_index=10, time_index=52, score=0.9999799728393555)
Point(token_index=11, time_index=53, score=0.9967018961906433)
Point(token_index=11, time_index=54, score=0.9999257326126099)
Point(token_index=11, time_index=55, score=0.9999982118606567)
Point(token_index=12, time_index=56, score=0.9990664124488831)
Point(token_index=12, time_index=57, score=0.9999996423721313)
Point(token_index=12, time_index=58, score=0.9999996423721313)
Point(token_index=12, time_index=59, score=0.8452622294425964)
Point(token_index=12, time_index=60, score=0.9999996423721313)
Point(token_index=13, time_index=61, score=0.9996007084846497)
Point(token_index=13, time_index=62, score=0.999998927116394)
Point(token_index=14, time_index=63, score=0.0035339989699423313)
Point(token_index=14, time_index=64, score=1.0)
Point(token_index=14, time_index=65, score=1.0)
Point(token_index=14, time_index=66, score=0.9999915361404419)
Point(token_index=15, time_index=67, score=0.997150719165802)
Point(token_index=15, time_index=68, score=0.9999990463256836)
Point(token_index=15, time_index=69, score=0.9999992847442627)
Point(token_index=15, time_index=70, score=0.9999997615814209)
Point(token_index=15, time_index=71, score=0.9999998807907104)
Point(token_index=15, time_index=72, score=0.9999881982803345)
Point(token_index=15, time_index=73, score=0.011422759853303432)
Point(token_index=15, time_index=74, score=0.9999977350234985)
Point(token_index=16, time_index=75, score=0.9996122717857361)
Point(token_index=16, time_index=76, score=0.999998927116394)
Point(token_index=16, time_index=77, score=0.9728758931159973)
Point(token_index=16, time_index=78, score=0.999998927116394)
Point(token_index=17, time_index=79, score=0.9949368238449097)
Point(token_index=17, time_index=80, score=0.999998927116394)
Point(token_index=17, time_index=81, score=0.9999123811721802)
Point(token_index=17, time_index=82, score=0.9999774694442749)
Point(token_index=18, time_index=83, score=0.6574353575706482)
Point(token_index=18, time_index=84, score=0.9984305500984192)
Point(token_index=18, time_index=85, score=0.9999876022338867)
Point(token_index=19, time_index=86, score=0.9993749260902405)
Point(token_index=19, time_index=87, score=0.9999988079071045)
Point(token_index=19, time_index=88, score=0.10454574227333069)
Point(token_index=19, time_index=89, score=0.9999969005584717)
Point(token_index=20, time_index=90, score=0.3973246216773987)
Point(token_index=20, time_index=91, score=0.9999932050704956)
Point(token_index=21, time_index=92, score=1.6972246612567687e-06)
Point(token_index=21, time_index=93, score=0.9860996603965759)
Point(token_index=21, time_index=94, score=0.9999960660934448)
Point(token_index=22, time_index=95, score=0.9992732405662537)
Point(token_index=22, time_index=96, score=0.9993422627449036)
Point(token_index=22, time_index=97, score=0.9999983310699463)
Point(token_index=23, time_index=98, score=0.9999971389770508)
Point(token_index=23, time_index=99, score=0.9999998807907104)
Point(token_index=23, time_index=100, score=0.9999995231628418)
Point(token_index=23, time_index=101, score=0.9999732971191406)
Point(token_index=24, time_index=102, score=0.9983194470405579)
Point(token_index=24, time_index=103, score=0.9999991655349731)
Point(token_index=24, time_index=104, score=0.9999996423721313)
Point(token_index=24, time_index=105, score=0.9999998807907104)
Point(token_index=24, time_index=106, score=1.0)
Point(token_index=24, time_index=107, score=0.999862790107727)
Point(token_index=24, time_index=108, score=0.9999980926513672)
Point(token_index=25, time_index=109, score=0.9988560676574707)
Point(token_index=25, time_index=110, score=0.9999798536300659)
Point(token_index=26, time_index=111, score=0.8575499653816223)
Point(token_index=26, time_index=112, score=0.9999847412109375)
Point(token_index=27, time_index=113, score=0.987017810344696)
Point(token_index=27, time_index=114, score=1.898651862575207e-05)
Point(token_index=27, time_index=115, score=0.9999796152114868)
Point(token_index=28, time_index=116, score=0.9998251795768738)
Point(token_index=28, time_index=117, score=0.9999990463256836)
Point(token_index=29, time_index=118, score=0.9999732971191406)
Point(token_index=29, time_index=119, score=0.0008991437498480082)
Point(token_index=29, time_index=120, score=0.9993476271629333)
Point(token_index=30, time_index=121, score=0.9975395202636719)
Point(token_index=30, time_index=122, score=0.0003041217278223485)
Point(token_index=30, time_index=123, score=0.9999344348907471)
Point(token_index=31, time_index=124, score=6.082251275074668e-06)
Point(token_index=31, time_index=125, score=0.9833292961120605)
Point(token_index=32, time_index=126, score=0.9974585175514221)
Point(token_index=33, time_index=127, score=0.0008251372491940856)
Point(token_index=33, time_index=128, score=0.9965135455131531)
Point(token_index=34, time_index=129, score=0.017435934394598007)
Point(token_index=34, time_index=130, score=0.9989168643951416)
Point(token_index=35, time_index=131, score=0.9999697208404541)
Point(token_index=36, time_index=132, score=0.9999842643737793)
Point(token_index=36, time_index=133, score=0.9997639060020447)
Point(token_index=37, time_index=134, score=0.5117325186729431)
Point(token_index=37, time_index=135, score=0.9998301267623901)
Point(token_index=38, time_index=136, score=0.08520185202360153)
Point(token_index=38, time_index=137, score=0.004068952519446611)
Point(token_index=38, time_index=138, score=0.9999815225601196)
Point(token_index=39, time_index=139, score=0.012018151581287384)
Point(token_index=39, time_index=140, score=0.9999980926513672)
Point(token_index=39, time_index=141, score=0.000581191445235163)
Point(token_index=39, time_index=142, score=0.9999070167541504)
Point(token_index=40, time_index=143, score=0.9999960660934448)
Point(token_index=40, time_index=144, score=0.9999980926513672)
Point(token_index=40, time_index=145, score=0.9999916553497314)
Point(token_index=41, time_index=146, score=0.9971164464950562)
Point(token_index=41, time_index=147, score=0.9981791973114014)
Point(token_index=41, time_index=148, score=0.9999310970306396)
Point(token_index=42, time_index=149, score=0.9879276156425476)
Point(token_index=42, time_index=150, score=0.999763548374176)
Point(token_index=42, time_index=151, score=0.9999536275863647)
Point(token_index=43, time_index=152, score=0.9999715089797974)
Point(token_index=44, time_index=153, score=0.3192700445652008)
Point(token_index=44, time_index=154, score=0.9997826218605042)
Point(token_index=45, time_index=155, score=0.016051672399044037)
Point(token_index=45, time_index=156, score=0.999901294708252)
Point(token_index=46, time_index=157, score=0.46622487902641296)
Point(token_index=46, time_index=158, score=0.9999994039535522)
Point(token_index=46, time_index=159, score=0.9999996423721313)
Point(token_index=46, time_index=160, score=0.9999995231628418)
Point(token_index=46, time_index=161, score=0.9999996423721313)
Point(token_index=46, time_index=162, score=0.9999996423721313)
Point(token_index=46, time_index=163, score=0.9999996423721313)
Point(token_index=46, time_index=164, score=0.9999995231628418)
Point(token_index=46, time_index=165, score=0.9999995231628418)
Point(token_index=46, time_index=166, score=0.9999996423721313)
Point(token_index=46, time_index=167, score=0.9999996423721313)
Point(token_index=46, time_index=168, score=0.9999995231628418)
可视化¶
def plot_trellis_with_path(trellis, path):
# To plot trellis with path, we take advantage of 'nan' value
trellis_with_path = trellis.clone()
for _, p in enumerate(path):
trellis_with_path[p.time_index, p.token_index] = float("nan")
plt.imshow(trellis_with_path.T, origin="lower")
plt.title("The path found by backtracking")
plt.tight_layout()
plot_trellis_with_path(trellis, path)
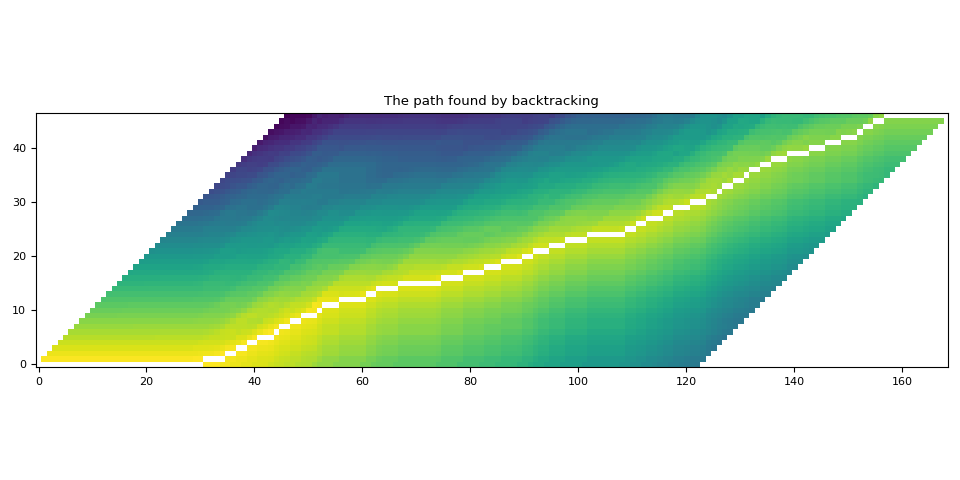
看起来不错。
分割路径¶
现在这条路径包含相同标签的重复,所以让我们将它们合并,使其接近原始文本。
合并多个路径点时,我们简单地取合并段的平均概率。
# Merge the labels
@dataclass
class Segment:
label: str
start: int
end: int
score: float
def __repr__(self):
return f"{self.label}\t({self.score:4.2f}): [{self.start:5d}, {self.end:5d})"
@property
def length(self):
return self.end - self.start
def merge_repeats(path):
i1, i2 = 0, 0
segments = []
while i1 < len(path):
while i2 < len(path) and path[i1].token_index == path[i2].token_index:
i2 += 1
score = sum(path[k].score for k in range(i1, i2)) / (i2 - i1)
segments.append(
Segment(
transcript[path[i1].token_index],
path[i1].time_index,
path[i2 - 1].time_index + 1,
score,
)
)
i1 = i2
return segments
segments = merge_repeats(path)
for seg in segments:
print(seg)
| (1.00): [ 0, 31)
I (0.78): [ 31, 35)
| (0.80): [ 35, 37)
H (1.00): [ 37, 39)
A (0.96): [ 39, 41)
D (0.65): [ 41, 44)
| (1.00): [ 44, 45)
T (0.55): [ 45, 47)
H (1.00): [ 47, 49)
A (0.03): [ 49, 52)
T (1.00): [ 52, 53)
| (1.00): [ 53, 56)
C (0.97): [ 56, 61)
U (1.00): [ 61, 63)
R (0.75): [ 63, 67)
I (0.88): [ 67, 75)
O (0.99): [ 75, 79)
S (1.00): [ 79, 83)
I (0.89): [ 83, 86)
T (0.78): [ 86, 90)
Y (0.70): [ 90, 92)
| (0.66): [ 92, 95)
B (1.00): [ 95, 98)
E (1.00): [ 98, 102)
S (1.00): [ 102, 109)
I (1.00): [ 109, 111)
D (0.93): [ 111, 113)
E (0.66): [ 113, 116)
| (1.00): [ 116, 118)
M (0.67): [ 118, 121)
E (0.67): [ 121, 124)
| (0.49): [ 124, 126)
A (1.00): [ 126, 127)
T (0.50): [ 127, 129)
| (0.51): [ 129, 131)
T (1.00): [ 131, 132)
H (1.00): [ 132, 134)
I (0.76): [ 134, 136)
S (0.36): [ 136, 139)
| (0.50): [ 139, 143)
M (1.00): [ 143, 146)
O (1.00): [ 146, 149)
M (1.00): [ 149, 152)
E (1.00): [ 152, 153)
N (0.66): [ 153, 155)
T (0.51): [ 155, 157)
| (0.96): [ 157, 169)
可视化¶
def plot_trellis_with_segments(trellis, segments, transcript):
# To plot trellis with path, we take advantage of 'nan' value
trellis_with_path = trellis.clone()
for i, seg in enumerate(segments):
if seg.label != "|":
trellis_with_path[seg.start : seg.end, i] = float("nan")
fig, [ax1, ax2] = plt.subplots(2, 1, sharex=True)
ax1.set_title("Path, label and probability for each label")
ax1.imshow(trellis_with_path.T, origin="lower", aspect="auto")
for i, seg in enumerate(segments):
if seg.label != "|":
ax1.annotate(seg.label, (seg.start, i - 0.7), size="small")
ax1.annotate(f"{seg.score:.2f}", (seg.start, i + 3), size="small")
ax2.set_title("Label probability with and without repetation")
xs, hs, ws = [], [], []
for seg in segments:
if seg.label != "|":
xs.append((seg.end + seg.start) / 2 + 0.4)
hs.append(seg.score)
ws.append(seg.end - seg.start)
ax2.annotate(seg.label, (seg.start + 0.8, -0.07))
ax2.bar(xs, hs, width=ws, color="gray", alpha=0.5, edgecolor="black")
xs, hs = [], []
for p in path:
label = transcript[p.token_index]
if label != "|":
xs.append(p.time_index + 1)
hs.append(p.score)
ax2.bar(xs, hs, width=0.5, alpha=0.5)
ax2.axhline(0, color="black")
ax2.grid(True, axis="y")
ax2.set_ylim(-0.1, 1.1)
fig.tight_layout()
plot_trellis_with_segments(trellis, segments, transcript)
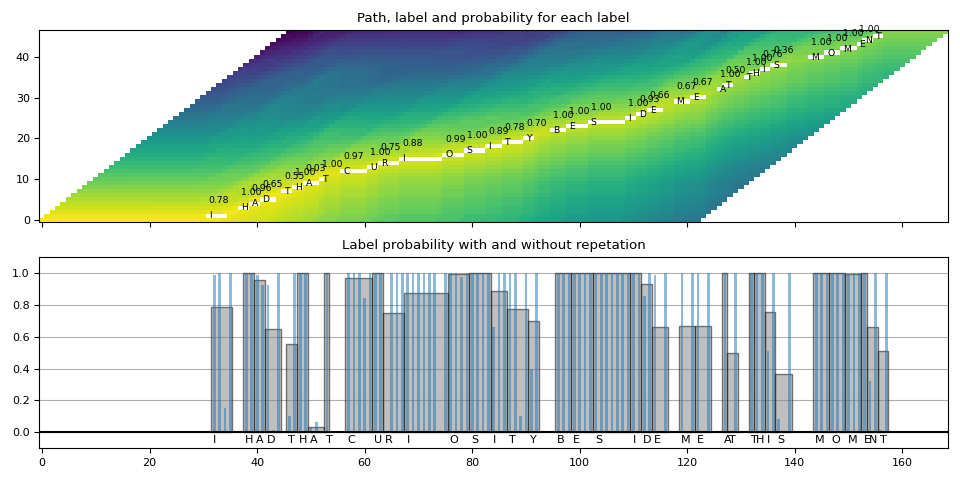
看起来不错。
将段合并成词¶
现在我们来合并词。Wav2Vec2 模型使用 '|' 作为词边界,因此我们将每个 '|' 出现之前的段合并。
最后,我们将原始音频分割成片段音频,并听取它们,以查看分割是否正确。
# Merge words
def merge_words(segments, separator="|"):
words = []
i1, i2 = 0, 0
while i1 < len(segments):
if i2 >= len(segments) or segments[i2].label == separator:
if i1 != i2:
segs = segments[i1:i2]
word = "".join([seg.label for seg in segs])
score = sum(seg.score * seg.length for seg in segs) / sum(seg.length for seg in segs)
words.append(Segment(word, segments[i1].start, segments[i2 - 1].end, score))
i1 = i2 + 1
i2 = i1
else:
i2 += 1
return words
word_segments = merge_words(segments)
for word in word_segments:
print(word)
I (0.78): [ 31, 35)
HAD (0.84): [ 37, 44)
THAT (0.52): [ 45, 53)
CURIOSITY (0.89): [ 56, 92)
BESIDE (0.94): [ 95, 116)
ME (0.67): [ 118, 124)
AT (0.66): [ 126, 129)
THIS (0.70): [ 131, 139)
MOMENT (0.88): [ 143, 157)
可视化¶
def plot_alignments(trellis, segments, word_segments, waveform, sample_rate=bundle.sample_rate):
trellis_with_path = trellis.clone()
for i, seg in enumerate(segments):
if seg.label != "|":
trellis_with_path[seg.start : seg.end, i] = float("nan")
fig, [ax1, ax2] = plt.subplots(2, 1)
ax1.imshow(trellis_with_path.T, origin="lower", aspect="auto")
ax1.set_facecolor("lightgray")
ax1.set_xticks([])
ax1.set_yticks([])
for word in word_segments:
ax1.axvspan(word.start - 0.5, word.end - 0.5, edgecolor="white", facecolor="none")
for i, seg in enumerate(segments):
if seg.label != "|":
ax1.annotate(seg.label, (seg.start, i - 0.7), size="small")
ax1.annotate(f"{seg.score:.2f}", (seg.start, i + 3), size="small")
# The original waveform
ratio = waveform.size(0) / sample_rate / trellis.size(0)
ax2.specgram(waveform, Fs=sample_rate)
for word in word_segments:
x0 = ratio * word.start
x1 = ratio * word.end
ax2.axvspan(x0, x1, facecolor="none", edgecolor="white", hatch="/")
ax2.annotate(f"{word.score:.2f}", (x0, sample_rate * 0.51), annotation_clip=False)
for seg in segments:
if seg.label != "|":
ax2.annotate(seg.label, (seg.start * ratio, sample_rate * 0.55), annotation_clip=False)
ax2.set_xlabel("time [second]")
ax2.set_yticks([])
fig.tight_layout()
plot_alignments(
trellis,
segments,
word_segments,
waveform[0],
)
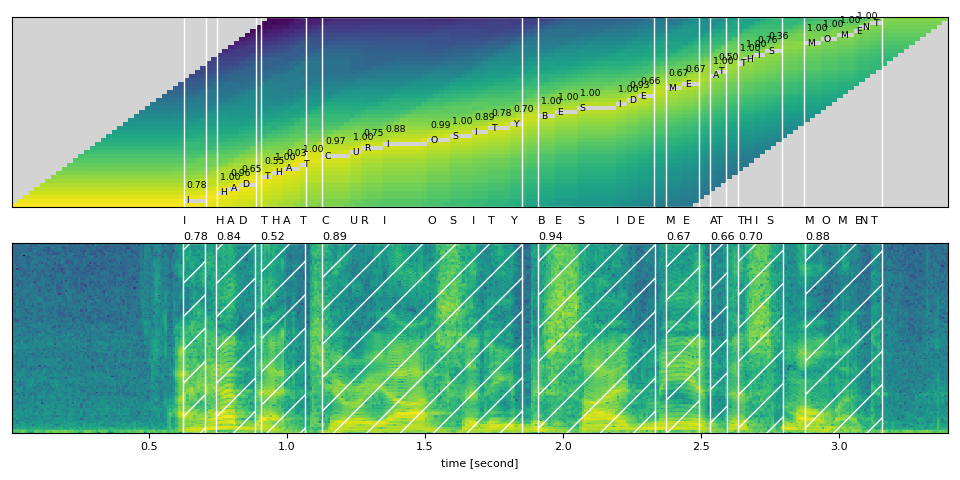
音频样本¶
def display_segment(i):
ratio = waveform.size(1) / trellis.size(0)
word = word_segments[i]
x0 = int(ratio * word.start)
x1 = int(ratio * word.end)
print(f"{word.label} ({word.score:.2f}): {x0 / bundle.sample_rate:.3f} - {x1 / bundle.sample_rate:.3f} sec")
segment = waveform[:, x0:x1]
return IPython.display.Audio(segment.numpy(), rate=bundle.sample_rate)
# Generate the audio for each segment
print(transcript)
IPython.display.Audio(SPEECH_FILE)
|I|HAD|THAT|CURIOSITY|BESIDE|ME|AT|THIS|MOMENT|
display_segment(0)
I (0.78): 0.624 - 0.704 sec
display_segment(1)
HAD (0.84): 0.744 - 0.885 sec
display_segment(2)
THAT (0.52): 0.905 - 1.066 sec
display_segment(3)
CURIOSITY (0.89): 1.127 - 1.851 sec
display_segment(4)
BESIDE (0.94): 1.911 - 2.334 sec
display_segment(5)
ME (0.67): 2.374 - 2.495 sec
display_segment(6)
AT (0.66): 2.535 - 2.595 sec
display_segment(7)
THIS (0.70): 2.635 - 2.796 sec
display_segment(8)
MOMENT (0.88): 2.877 - 3.159 sec
结论¶
在本教程中,我们了解了如何使用 torchaudio 的 Wav2Vec2 模型执行 CTC 分割以进行强制对齐。
脚本总运行时间: ( 0 分 1.731 秒)
