


注意
点击此处下载完整示例代码
音频特征增强¶
作者: Moto Hira
# When running this tutorial in Google Colab, install the required packages
# with the following.
# !pip install torchaudio librosa
import torch
import torchaudio
import torchaudio.transforms as T
print(torch.__version__)
print(torchaudio.__version__)
2.7.0
2.7.0
准备工作¶
import librosa
import matplotlib.pyplot as plt
from IPython.display import Audio
from torchaudio.utils import download_asset
在本教程中,我们将使用来自 VOiCES 数据集的语音数据,该数据集根据 Creative Commons BY 4.0 获得许可。
SAMPLE_WAV_SPEECH_PATH = download_asset("tutorial-assets/Lab41-SRI-VOiCES-src-sp0307-ch127535-sg0042.wav")
def _get_sample(path, resample=None):
effects = [["remix", "1"]]
if resample:
effects.extend(
[
["lowpass", f"{resample // 2}"],
["rate", f"{resample}"],
]
)
return torchaudio.sox_effects.apply_effects_file(path, effects=effects)
def get_speech_sample(*, resample=None):
return _get_sample(SAMPLE_WAV_SPEECH_PATH, resample=resample)
def get_spectrogram(
n_fft=400,
win_len=None,
hop_len=None,
power=2.0,
):
waveform, _ = get_speech_sample()
spectrogram = T.Spectrogram(
n_fft=n_fft,
win_length=win_len,
hop_length=hop_len,
center=True,
pad_mode="reflect",
power=power,
)
return spectrogram(waveform)
SpecAugment¶
SpecAugment 是一种流行的频谱图增强技术。
torchaudio 实现了 torchaudio.transforms.TimeStretch()、torchaudio.transforms.TimeMasking() 和 torchaudio.transforms.FrequencyMasking()。
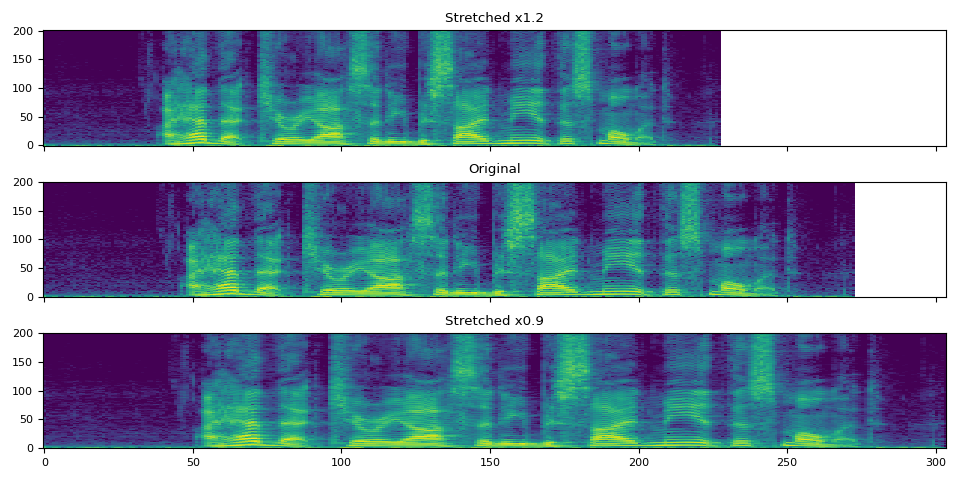
TimeStretch¶
可视化¶
def plot():
def plot_spec(ax, spec, title):
ax.set_title(title)
ax.imshow(librosa.amplitude_to_db(spec), origin="lower", aspect="auto")
fig, axes = plt.subplots(3, 1, sharex=True, sharey=True)
plot_spec(axes[0], torch.abs(spec_12[0]), title="Stretched x1.2")
plot_spec(axes[1], torch.abs(spec[0]), title="Original")
plot_spec(axes[2], torch.abs(spec_09[0]), title="Stretched x0.9")
fig.tight_layout()
plot()
音频样本¶
def preview(spec, rate=16000):
ispec = T.InverseSpectrogram()
waveform = ispec(spec)
return Audio(waveform[0].numpy().T, rate=rate)
preview(spec)
preview(spec_12)
preview(spec_09)
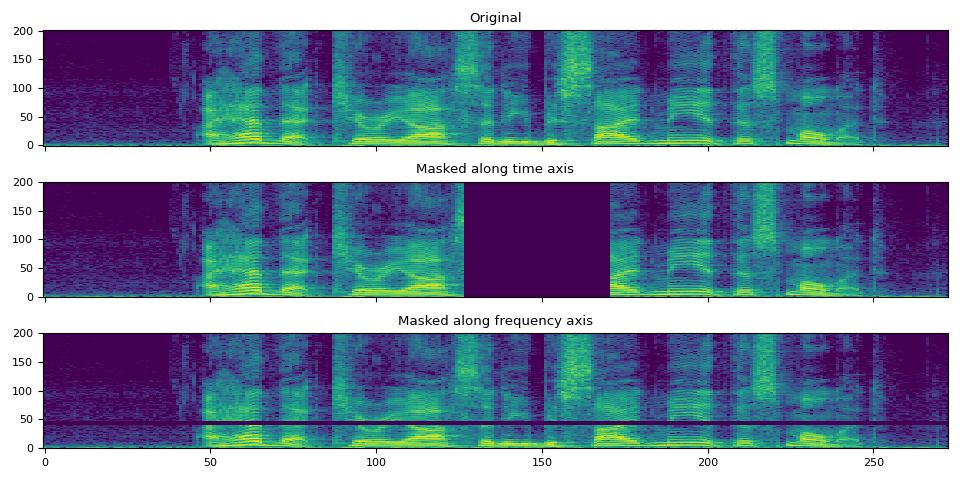
时间和频率遮蔽¶
torch.random.manual_seed(4)
time_masking = T.TimeMasking(time_mask_param=80)
freq_masking = T.FrequencyMasking(freq_mask_param=80)
spec = get_spectrogram()
time_masked = time_masking(spec)
freq_masked = freq_masking(spec)
def plot():
def plot_spec(ax, spec, title):
ax.set_title(title)
ax.imshow(librosa.power_to_db(spec), origin="lower", aspect="auto")
fig, axes = plt.subplots(3, 1, sharex=True, sharey=True)
plot_spec(axes[0], spec[0], title="Original")
plot_spec(axes[1], time_masked[0], title="Masked along time axis")
plot_spec(axes[2], freq_masked[0], title="Masked along frequency axis")
fig.tight_layout()
plot()
脚本总运行时间: ( 0 分 2.298 秒)
