Wav2Vec2FABundle¶
- 类 torchaudio.pipelines.Wav2Vec2FABundle[源代码]¶
用于捆绑关联信息的 数据类,以便使用预训练的
Wav2Vec2Model进行强制对齐。该类提供了用于实例化预训练模型的接口,以及检索预训练权重和与模型一起使用的额外数据所需的信息。
Torchaudio 库会实例化此类的对象,每个对象代表一个不同的预训练模型。客户端代码应通过这些实例访问预训练模型。
请参阅下方了解用法和可用值。
- 示例 - 特征提取
>>> import torchaudio >>> >>> bundle = torchaudio.pipelines.MMS_FA >>> >>> # Build the model and load pretrained weight. >>> model = bundle.get_model() Downloading: 100%|███████████████████████████████| 1.18G/1.18G [00:05<00:00, 216MB/s] >>> >>> # Resample audio to the expected sampling rate >>> waveform = torchaudio.functional.resample(waveform, sample_rate, bundle.sample_rate) >>> >>> # Estimate the probability of token distribution >>> emission, _ = model(waveform) >>> >>> # Generate frame-wise alignment >>> alignment, scores = torchaudio.functional.forced_align( >>> emission, targets, input_lengths, target_lengths, blank=0) >>>
- 使用
Wav2Vec2FABundle的教程
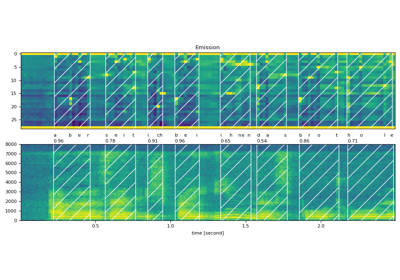
属性¶
sample_rate¶
方法¶
get_aligner¶
get_dict¶
- Wav2Vec2FABundle.get_dict(star: Optional[str] = '*', blank: str ='-') Dict[str, int][源代码]¶
获取从 token 到索引的映射(在 emission feature 维度中)
- 参数:
- 返回:
对于在 ASR 上微调的模型,返回表示输出类别标签的字符串元组。
- 返回类型:
Tuple[str, ...]
- 示例
>>> from torchaudio.pipelines import MMS_FA as bundle >>> bundle.get_dict() {'-': 0, 'a': 1, 'i': 2, 'e': 3, 'n': 4, 'o': 5, 'u': 6, 't': 7, 's': 8, 'r': 9, 'm': 10, 'k': 11, 'l': 12, 'd': 13, 'g': 14, 'h': 15, 'y': 16, 'b': 17, 'p': 18, 'w': 19, 'c': 20, 'v': 21, 'j': 22, 'z': 23, 'f': 24, "'": 25, 'q': 26, 'x': 27, '*': 28} >>> bundle.get_dict(star=None) {'-': 0, 'a': 1, 'i': 2, 'e': 3, 'n': 4, 'o': 5, 'u': 6, 't': 7, 's': 8, 'r': 9, 'm': 10, 'k': 11, 'l': 12, 'd': 13, 'g': 14, 'h': 15, 'y': 16, 'b': 17, 'p': 18, 'w': 19, 'c': 20, 'v': 21, 'j': 22, 'z': 23, 'f': 24, "'": 25, 'q': 26, 'x': 27}
get_labels¶
- Wav2Vec2FABundle.get_labels(star: Optional[str] = '*', blank: str ='-') Tuple[str, ...][源代码]¶
获取与 emission 特征维度相对应的标签。
第一个是 blank token,并且它是可自定义的。
- 参数:
- 返回:
对于在 ASR 上微调的模型,返回表示输出类别标签的字符串元组。
- 返回类型:
Tuple[str, ...]
- 示例
>>> from torchaudio.pipelines import MMS_FA as bundle >>> bundle.get_labels() ('-', 'a', 'i', 'e', 'n', 'o', 'u', 't', 's', 'r', 'm', 'k', 'l', 'd', 'g', 'h', 'y', 'b', 'p', 'w', 'c', 'v', 'j', 'z', 'f', "'", 'q', 'x', '*') >>> bundle.get_labels(star=None) ('-', 'a', 'i', 'e', 'n', 'o', 'u', 't', 's', 'r', 'm', 'k', 'l', 'd', 'g', 'h', 'y', 'b', 'p', 'w', 'c', 'v', 'j', 'z', 'f', "'", 'q', 'x')
get_model¶
- Wav2Vec2FABundle.get_model(with_star: bool = True, *, dl_kwargs=None) Module[源代码]¶
构建模型并加载预训练权重。
权重文件会从互联网下载并使用
torch.hub.load_state_dict_from_url()进行缓存。- 参数:
with_star (bool,可选) – 如果启用,输出层的最后一维会扩展一个,这对应于 star token。
dl_kwargs (keyword arguments 字典) – 传递给
torch.hub.load_state_dict_from_url()。
- 返回:
Wav2Vec2Model的变体。注意
使用此方法创建的模型返回的是对数域的概率(即应用了
torch.nn.functional.log_softmax()),而其他 Wav2Vec2 模型返回的是 logit。
