量化概述¶
量化是一种降低计算精度并减少模型内存占用的过程。要了解更多信息,请访问ExecuTorch 概念页面。这对于边缘设备(包括可穿戴设备、嵌入式设备和微控制器)特别有用,这些设备通常具有有限的资源,如处理能力、内存和电池续航。通过使用量化,我们可以使模型更高效,并使其能够有效地在这些设备上运行。
从流程上看,量化发生在 ExecuTorch 堆栈的早期阶段。
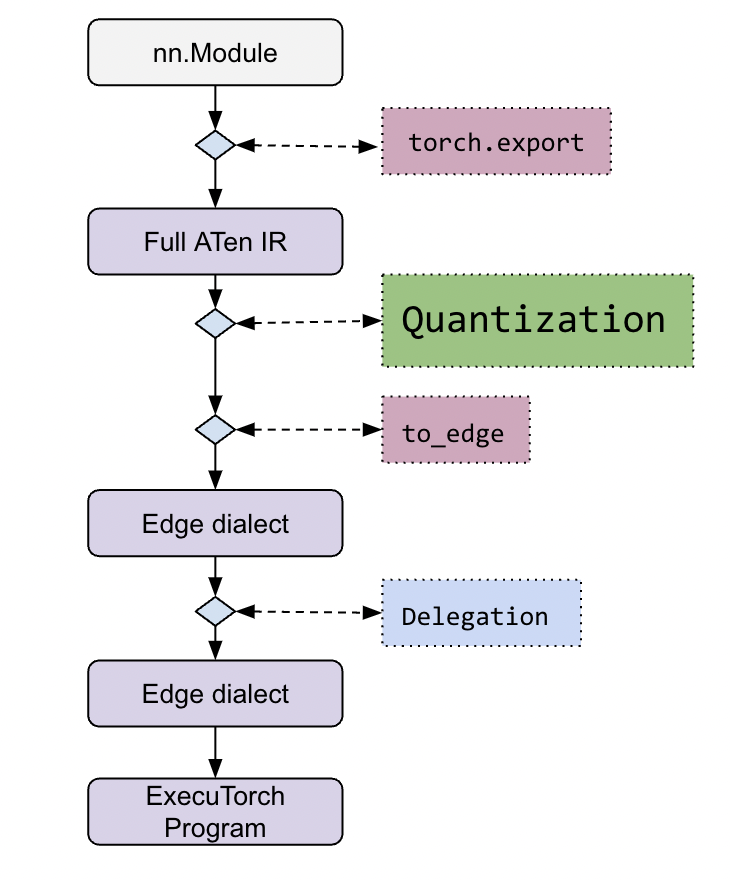
更详细的工作流程可以在ExecuTorch 教程中找到。
量化通常与实现了量化算子的执行后端相关联。因此,每个后端对于模型应如何量化都有自己的观点,这通过后端特定的 Quantizer 类来表达。Quantizer 为建模用户提供了关于他们希望如何对模型进行量化的 API,并将用户意图传递给量化工作流程。
后端开发者需要实现自己的 Quantizer 来表达其后端中不同算子或算子模式如何量化。这通过量化工作流程提供的 Annotation API 来实现。由于 Quantizer 也面向用户,因此它将公开特定的 API,供建模用户配置他们希望如何对模型进行量化。每个后端都应该为自己的 Quantizer 提供 API 文档。
建模用户将使用针对其目标后端的 Quantizer 来量化其模型,例如 XNNPACKQuantizer。
有关使用 XNNPACKQuantizer 的量化流程示例、更多文档和教程,请参阅ExecuTorch 教程中的 Performing Quantization(执行量化)部分。
源数量化:Int8DynActInt4WeightQuantizer¶
除了基于导出的量化(如上所述),ExecuTorch 还希望重点介绍基于源的量化,这通过 torchao 实现。与基于导出的量化不同,基于源的量化在导出之前直接修改模型。一个具体示例如下:Int8DynActInt4WeightQuantizer。
该方案表示在推理过程中,对权重进行 4 位量化,对激活进行 8 位动态量化。
使用 from torchao.quantization.quant_api import Int8DynActInt4WeightQuantizer 导入后,该类使用指定数据类型精度和分组大小构建的量化实例,来修改提供的 nn.Module。
# Source Quant
from torchao.quantization.quant_api import Int8DynActInt4WeightQuantizer
model = Int8DynActInt4WeightQuantizer(precision=torch_dtype, groupsize=group_size).quantize(model)
# Export to ExecuTorch
from executorch.exir import to_edge
from torch.export import export
exported_model = export(model, ...)
et_program = to_edge(exported_model, ...).to_executorch(...)
