XNNPACK Delegate 内部¶
这是 ExecuTorch XNNPACK 后端 delegate 的高层次概览。这个高性能 delegate 旨在降低 ExecuTorch 模型的 CPU 推理延迟。我们将简要介绍 XNNPACK 库,并探讨 delegate 的整体架构和预期用例。
什么是 XNNPACK?¶
XNNPACK 是一个高度优化的神经网络操作符库,适用于 Android、iOS、Windows、Linux 和 macOS 环境中的 ARM、x86 和 WebAssembly 架构。这是一个开源项目,您可以在 github 上找到更多相关信息。
什么是 ExecuTorch delegate?¶
Delegate 是后端处理和执行 ExecuTorch 程序部分的入口点。ExecuTorch 模型中被 delegate 的部分会将执行权交给后端。XNNPACK 后端 delegate 是 ExecuTorch 中众多可用的 delegate 之一。它利用 XNNPACK 第三方库在各种 CPU 上高效加速 ExecuTorch 程序。关于 delegate 和开发自己的 delegate 的更多详细信息可在此处找到。此处。建议您在继续阅读架构部分之前熟悉这部分内容。
架构¶
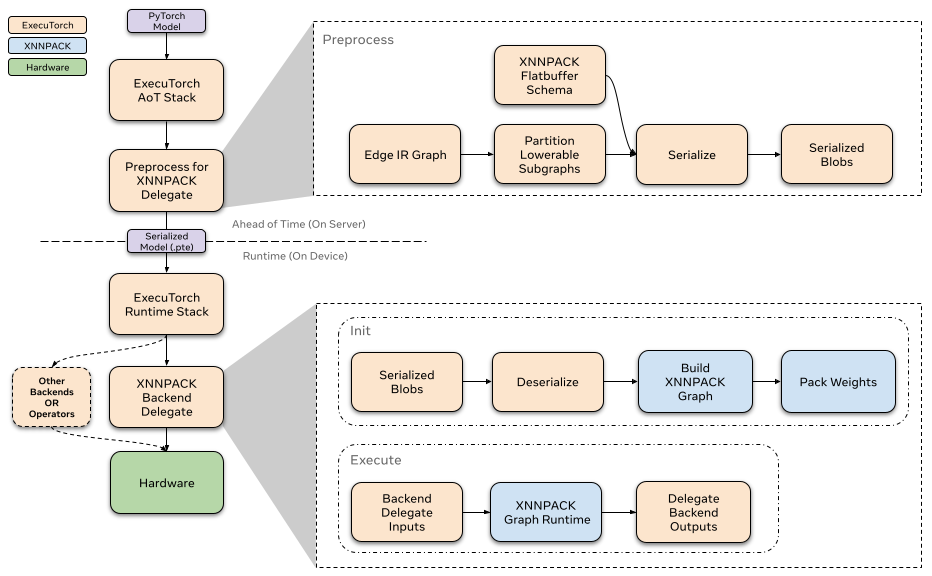
提前 (Ahead-of-time)¶
在 ExecuTorch 导出流程中,向 XNNPACK delegate 的 lowering 发生在 to_backend() 阶段。在此阶段,模型由 XnnpackPartitioner 进行分区。图中被分区的部分被转换为 XNNPACK 特定的图表示,然后通过 flatbuffer 进行序列化。序列化的 flatbuffer 即可由 XNNPACK 后端在运行时反序列化并执行。

分区器 (Partitioner)¶
分区器由后端 delegate 实现,用于标记适合进行 lowering 的节点。XnnpackPartitioner 使用节点目标和模块元数据进行 lowering。可以在此处找到更多关于分区器的参考资料
基于模块的分区¶
source_fn_stack 嵌入在节点的元数据中,提供有关这些节点来源的信息。例如,torch.nn.Linear 等模块在被捕获并导出 to_edge 时,会为其计算生成一组节点。与计算线性模块相关的节点组的 source_fn_stack 即为 torch.nn.Linear. 基于source_fn_stack` 的分区使我们能够识别可通过 XNNPACK 进行 lowering 的节点组。
例如,捕获 torch.nn.Linear 后,您会在与线性模块相关的 addmm 节点的元数据中找到以下键
>>> print(linear_node.meta["source_fn_stack"])
'source_fn_stack': ('fn', <class 'torch.nn.modules.linear.Linear'>)
基于操作符的分区¶
XnnpackPartitioner 也使用操作符目标进行分区。它遍历图并识别可降低到 XNNPACK 的单个节点。基于模块的分区的一个缺点是可能会跳过来自 decompositions 的操作符。例如,像 torch.nn.Hardsigmoid 这样的操作符被分解为 add、muls、divs 和 clamps。虽然 hardsigmoid 本身不可降低,但我们可以降低分解后的操作符。依赖 source_fn_stack 元数据会跳过这些可降低的操作符,因为它们属于一个不可降低的模块,因此为了提高模型性能,我们根据操作符目标以及 source_fn_stack 贪婪地降低操作符。
Passes¶
在任何序列化之前,我们会在子图上应用 passes 来准备图。这些 passes 本质上是图转换,有助于提高 delegate 的性能。下面我们将概述最主要的 passes 及其功能。所有 passes 的描述请参见此处
Channels Last 重塑
ExecuTorch 张量在传入 delegate 之前通常是连续的,而 XNNPACK 只接受 channels-last 内存布局。此 pass 会最大限度地减少插入的 permutation 操作符数量,以便传入 channels-last 内存格式。
Conv1d 转 Conv2d
通过将 Conv1d 节点转换为 Conv2d,使其能够被 delegate 处理
卷积和 BN 融合
将 batch norm 操作与前一个卷积节点融合
运行时¶
XNNPACK 后端的运行时通过自定义的 init 和 execute 函数与 ExecuTorch 运行时交互。每个被 delegate 的子图都包含在一个单独序列化的 XNNPACK blob 中。模型初始化时,ExecuTorch 会对所有 XNNPACK Blobs 调用 init 函数,以从序列化的 flatbuffer 加载子图。之后,执行模型时,每个子图都通过后端通过自定义的 execute 函数执行。要详细了解 delegate 运行时如何与 ExecuTorch 交互,请参阅此资源。
Init¶
调用 XNNPACK delegate 的 init 函数时,我们通过 flatbuffer 反序列化预处理过的 blob。我们使用提前序列化的信息来定义节点(操作符)和边(中间张量),以构建 XNNPACK 执行图。正如我们之前提到的,大部分处理工作已提前完成,因此在运行时我们只需连续调用 XNNPACK API 并传入序列化的参数。当我们将静态数据定义到执行图中时,XNNPACK 会在运行时执行权重打包,为权重和偏置等静态数据的高效执行做准备。创建执行图后,我们创建运行时对象并将其传递给 execute 函数。
由于权重打包会在 XNNPACK 内部创建权重的额外副本,我们会释放预处理过的 XNNPACK Blob 中权重的原始副本,这有助于减少部分内存开销。
Execute¶
执行 XNNPACK 子图时,我们准备好张量输入和输出,并将它们馈送到 XNNPACK 运行时图。执行运行时图后,输出指针将填充计算出的张量。
性能分析¶
我们已为 XNNPACK delegate 启用了基本性能分析功能,可通过编译器标志 -DEXECUTORCH_ENABLE_EVENT_TRACER 启用(添加 -DENABLE_XNNPACK_PROFILING 可获得更多详细信息)。通过 ExecuTorch 的开发者工具集成,您现在也可以使用开发者工具对模型进行性能分析。您可以按照使用 ExecuTorch 开发者工具分析模型中的步骤,了解如何分析 ExecuTorch 模型以及如何使用开发者工具的 Inspector API 查看 XNNPACK 的内部性能分析信息。xnn_executor_runner 中提供了示例实现(请参阅此处教程)。
量化¶
XNNPACK delegate 也可用作执行对称量化模型的后端。对于量化模型 delegate,我们使用 XNNPACKQuantizer 对模型进行量化。Quantizer 是后端特定的,这意味着 XNNPACKQuantizer 被配置为对模型进行量化,以利用 XNNPACK 库提供的量化操作符。我们不会详细介绍如何实现自定义 quantizer,您可以按照此处文档进行操作。但是,我们将简要概述如何量化模型以利用 XNNPACK delegate 的量化执行。
配置 XNNPACKQuantizer¶
from executorch.backends.xnnpack.quantizer.xnnpack_quantizer import (
XNNPACKQuantizer,
get_symmetric_quantization_config,
)
quantizer = XNNPACKQuantizer()
quantizer.set_global(get_symmetric_quantization_config())
这里我们初始化 XNNPACKQuantizer 并将量化配置设置为对称量化。对称量化是指权重以 qmin = -127 和 qmax = 127 进行对称量化,这迫使量化零点为零。get_symmetric_quantization_config() 可以使用以下参数进行配置
is_per_channel权重按通道进行量化
is_qat量化感知训练
is_dynamic动态量化
然后我们可以根据需要配置 XNNPACKQuantizer。下面我们设置以下配置作为示例
quantizer.set_global(quantization_config)
.set_object_type(torch.nn.Conv2d, quantization_config) # can configure by module type
.set_object_type(torch.nn.functional.linear, quantization_config) # or torch functional op typea
.set_module_name("foo.bar", quantization_config) # or by module fully qualified name
使用 XNNPACKQuantizer 对模型进行量化¶
配置好我们的 quantizer 后,现在就可以对模型进行量化了
from torch.export import export_for_training
exported_model = export_for_training(model_to_quantize, example_inputs).module()
prepared_model = prepare_pt2e(exported_model, quantizer)
print(prepared_model.graph)
Prepare 会执行一些 Conv2d-BN 融合,并在适当的位置插入量化观察器。对于训练后量化 (Post-Training Quantization),我们通常在此步骤后校准模型。我们通过 prepared_model 运行示例,以观察张量的统计信息,从而计算量化参数。
最后,我们在此处转换模型
quantized_model = convert_pt2e(prepared_model)
print(quantized_model)
您现在将看到模型的 Q/DQ 表示,这意味着 torch.ops.quantized_decomposed.dequantize_per_tensor 被插入到量化操作符输入处,而 torch.ops.quantized_decomposed.quantize_per_tensor 被插入到操作符输出处。示例
def _qdq_quantized_linear(
x_i8, x_scale, x_zero_point, x_quant_min, x_quant_max,
weight_i8, weight_scale, weight_zero_point, weight_quant_min, weight_quant_max,
bias_fp32,
out_scale, out_zero_point, out_quant_min, out_quant_max
):
x_fp32 = torch.ops.quantized_decomposed.dequantize_per_tensor(
x_i8, x_scale, x_zero_point, x_quant_min, x_quant_max, torch.int8)
weight_fp32 = torch.ops.quantized_decomposed.dequantize_per_tensor(
weight_i8, weight_scale, weight_zero_point, weight_quant_min, weight_quant_max, torch.int8)
out_fp32 = torch.ops.aten.linear.default(x_fp32, weight_fp32, bias_fp32)
out_i8 = torch.ops.quantized_decomposed.quantize_per_tensor(
out_fp32, out_scale, out_zero_point, out_quant_min, out_quant_max, torch.int8)
return out_i8
您可以在此处阅读关于 PyTorch 2 量化的更深入解释。
