内核注册¶
概览¶
在 ExecuTorch 模型导出 的最后阶段,我们将方言中的算子降级为 核心 ATen 算子 的 out 变体。然后我们将这些算子名称序列化到模型 artifact 中。在运行时执行期间,对于每个算子名称,我们需要找到实际的 内核,即执行繁重计算并返回结果的 C++ 函数。
内核库¶
第一方内核库:¶
可移植内核库 是内部默认的内核库,涵盖了大多数核心 ATen 算子。它易于使用/阅读,并用可移植的 C++17 编写。然而,它并未针对性能进行优化,因为它没有为任何特定目标进行专门化。因此,我们提供了内核注册 API,以便 ExecuTorch 用户轻松注册他们自己的优化内核。
优化内核库 针对某些算子专门优化性能,利用了 EigenBLAS 等现有第三方库。这与可移植内核库配合使用效果最佳,在可移植性和性能之间取得了良好的平衡。在这里可以找到一个结合这两个库的示例。
量化内核库 实现了量化和反量化的算子。这些不是核心 ATen 算子,但对于大多数生产用例至关重要。
自定义内核库:¶
实现核心 ATen 算子的自定义内核。尽管我们没有关于实现核心 ATen 算子的自定义内核的内部示例,但优化内核库可以被视为一个很好的例子。我们有优化的 add.out 和可移植的 add.out。当用户组合这两个库时,我们提供了 API 来选择对 add.out 使用哪个内核。为了编写和使用实现核心 ATen 算子的自定义内核,建议使用基于 YAML 的方法,因为它在以下方面提供了全面的支持
组合内核库和定义回退内核;
使用选择性构建来最小化内核大小。
一个 自定义算子 是 ExecuTorch 用户在 PyTorch 的 native_functions.yaml 之外定义的任何算子。
算子与内核契约¶
上述所有内核,无论内部实现还是自定义,都应符合以下要求
匹配源自算子 schema 的调用约定。内核注册 API 将为自定义内核生成头文件作为参考。
满足边缘方言中定义的 dtype 约束。对于以特定 dtype 作为参数的张量,自定义内核的结果需要与预期的 dtype 匹配。这些约束在边缘方言算子中可用。
给出正确结果。我们将提供一个测试框架来自动测试自定义内核。
API¶
这些是将内核/自定义内核/自定义算子注册到 ExecuTorch 中的可用 API
如果不清楚使用哪个 API,请参阅最佳实践。
YAML 入口 API 高级架构¶
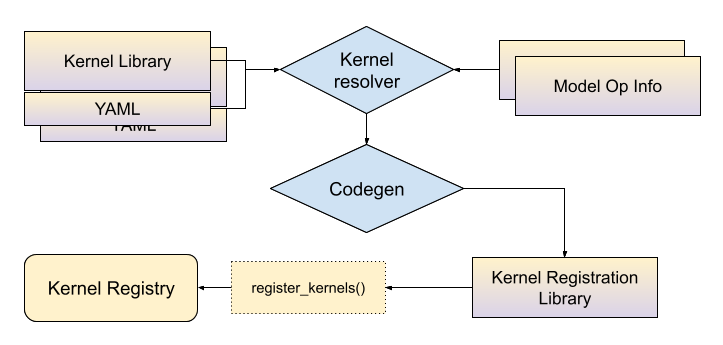
要求 ExecuTorch 用户提供
带有 C++ 实现的自定义内核库
与库关联的 YAML 文件,描述该库实现了哪些算子。对于部分内核,yaml 文件还包含内核支持的 dtypes 和 dim order 信息。更多详情请参阅 API 部分。
YAML 入口 API 工作流程¶
在构建时,与内核库相关的 yaml 文件将连同模型算子信息(参见选择性构建文档)一起传递给 内核解析器,结果是将算子名称和张量元数据的组合映射到内核符号。然后代码生成工具将使用此映射生成连接内核到 ExecuTorch 运行时的 C++ 绑定。ExecuTorch 用户需要将此生成的库链接到其应用程序中才能使用这些内核。
在静态对象初始化时,内核将被注册到 ExecuTorch 内核注册表中。
在运行时初始化阶段,ExecuTorch 将使用算子名称和参数元数据作为键来查找内核。例如,对于“aten::add.out”和输入为 dim order (0, 1, 2, 3) 的 float 张量,ExecuTorch 将进入内核注册表查找与名称和输入元数据匹配的内核。
核心 ATen 算子 out 变体的 YAML 入口 API¶
顶层属性
op(如果算子出现在native_functions.yaml中)或用于自定义算子的func。对于op键,此键的值需要是完整的算子名称(包括重载名称);如果描述自定义算子,则为完整的算子 schema(命名空间、算子名称、算子重载名称和 schema 字符串)。关于 schema 语法,请参考此说明。kernels:定义内核信息。它由arg_meta和kernel_name组成,它们绑定在一起描述“对于具有这些元数据的输入张量,使用此内核”。type_alias(可选):我们为可能的 dtype 选项赋予别名。T0: [Double, Float]意味着T0可以是Double或Float中的一个。dim_order_alias(可选):类似于type_alias,我们为可能的 dim order 选项赋予名称。
kernels 下的属性
arg_meta:“张量参数名称”条目列表。这些键的值是 dtypes 和 dim orders 别名,由相应的kernel_name实现。如果此值为null,则表示内核将用于所有类型的输入。kernel_name:实现此算子的 C++ 函数的预期名称。您可以在此处放置任何名称,但应遵循以下约定:将重载名称中的.替换为下划线,并将所有字符转换为小写。在此示例中,add.out使用名为add_out的 C++ 函数。add.Scalar_out将变为add_scalar_out,其中S为小写。我们支持内核的命名空间,但请注意,我们将在最后一级命名空间中插入native::。因此,kernel_name中的custom::add_out将指向custom::native::add_out。
算子条目的一些示例
- op: add.out
kernels:
- arg_meta: null
kernel_name: torch::executor::add_out
具有默认内核的核心 ATen 算子的 out 变体
具有 dtype/dim order 专用内核的 ATen 算子(适用于 Double dtype,dim order 需为 (0, 1, 2, 3))
- op: add.out
type_alias:
T0: [Double]
dim_order_alias:
D0: [[0, 1, 2, 3]]
kernels:
- arg_meta:
self: [T0, D0]
other: [T0 , D0]
out: [T0, D0]
kernel_name: torch::executor::add_out
自定义算子的 YAML 入口 API¶
如上所述,此选项在选择性构建和合并算子库等功能方面提供了更多支持。
首先我们需要指定算子 schema 以及一个 kernel 部分。因此,我们使用 func 替代 op 并带有算子 schema。例如,这是一个自定义算子的 yaml 条目
- func: allclose.out(Tensor self, Tensor other, float rtol=1e-05, float atol=1e-08, bool equal_nan=False, bool dummy_param=False, *, Tensor(a!) out) -> Tensor(a!)
kernels:
- arg_meta: null
kernel_name: torch::executor::allclose_out
的 kernel 部分与核心 ATen 算子中定义的相同。对于算子 schema,我们重用此 README.md 中定义的 DSL,但有一些差异
仅 Out 变体¶
ExecuTorch 仅支持 out 风格的算子,其中
调用者在最后位置提供名为
out的输出 Tensor 或 Tensor 列表。C++ 函数修改并返回相同的
out参数。如果 YAML 文件中的返回类型是
()(对应于 void),C++ 函数仍应修改out,但无需返回任何内容。
的
out参数必须是仅限关键字的,这意味着它需要跟在名为*的参数后面,就像下面的add.out示例中那样。按照惯例,这些 out 算子使用模式
<name>.out或<name>.<overload>_out命名。
由于所有输出值都通过一个 out 参数返回,ExecuTorch 会忽略实际的 C++ 函数返回值。但是,为了保持一致性,当返回类型非 void 时,函数应始终返回 out。
只能返回 Tensor 或 ()¶
ExecuTorch 仅支持返回单个 Tensor 或单元类型 ()(对应于 void)的算子。它不支持返回任何其他类型,包括列表、optional、元组或布尔值等标量。
支持的参数类型¶
ExecuTorch 不支持核心 PyTorch 支持的所有参数类型。以下是我们当前支持的参数类型列表
Tensor
int
bool
float
str
Scalar
ScalarType
MemoryFormat
Device
Optional
List
List<Optional
> Optional<List
>
CMake 宏¶
我们提供了构建时宏来帮助用户构建他们的内核注册库。该宏接受描述内核库的 yaml 文件以及模型算子元数据,并将生成的 C++ 绑定打包到一个 C++ 库中。该宏在 CMake 中可用。
generate_bindings_for_kernels(FUNCTIONS_YAML functions_yaml CUSTOM_OPS_YAML custom_ops_yaml) 接受一个用于核心 ATen 算子 out 变体的 yaml 文件和一个用于自定义算子的 yaml 文件,生成用于内核注册的 C++ 绑定。它还依赖于 gen_selected_ops() 生成的选择性构建 artifact,更多信息请参阅选择性构建文档。然后 gen_operators_lib 将把这些绑定打包成一个 C++ 库。例如
# SELECT_OPS_LIST: aten::add.out,aten::mm.out
gen_selected_ops("" "${SELECT_OPS_LIST}" "")
# Look for functions.yaml associated with portable libs and generate C++ bindings
generate_bindings_for_kernels(FUNCTIONS_YAML ${EXECUTORCH_ROOT}/kernels/portable/functions.yaml)
# Prepare a C++ library called "generated_lib" with _kernel_lib being the portable library, executorch is a dependency of it.
gen_operators_lib("generated_lib" KERNEL_LIBS ${_kernel_lib} DEPS executorch)
# Link "generated_lib" into the application:
target_link_libraries(executorch_binary generated_lib)
我们还提供了合并两个 yaml 文件(给定优先级)的能力。merge_yaml(FUNCTIONS_YAML functions_yaml FALLBACK_YAML fallback_yaml OUTPUT_DIR out_dir) 将 functions_yaml 和 fallback_yaml 合并为一个 yaml 文件,如果 functions_yaml 和 fallback_yaml 中存在重复条目,此宏将始终采用 functions_yaml 中的条目。
示例
# functions.yaml
- op: add.out
kernels:
- arg_meta: null
kernel_name: torch::executor::opt_add_out
以及 out 回退
# fallback.yaml
- op: add.out
kernels:
- arg_meta: null
kernel_name: torch::executor::add_out
合并后的 yaml 将包含 functions.yaml 中的条目。
自定义算子的 C++ API¶
与 YAML 入口 API 不同,C++ API 仅使用 C++ 宏 EXECUTORCH_LIBRARY 和 WRAP_TO_ATEN 进行内核注册,也不支持选择性构建。这使得此 API 在开发速度方面更快,因为用户不必进行 YAML 编写和构建系统调整。
关于使用哪个 API,请参阅自定义算子最佳实践。
类似于 PyTorch 中的 TORCH_LIBRARY,EXECUTORCH_LIBRARY 接受算子名称和 C++ 函数名称,并将它们注册到 ExecuTorch 运行时。
准备自定义内核实现¶
定义自定义算子的 schema,包括函数式变体(用于 AOT 编译)和 out 变体(用于 ExecuTorch 运行时)。该 schema 需要遵循 PyTorch ATen 约定(参见 native_functions.yaml)。例如
custom_linear(Tensor weight, Tensor input, Tensor(?) bias) -> Tensor
custom_linear.out(Tensor weight, Tensor input, Tensor(?) bias, *, Tensor(a!) out) -> Tensor(a!)
然后使用 ExecuTorch 类型并根据 schema 编写自定义内核,同时使用 API 注册到 ExecuTorch 运行时
// custom_linear.h/custom_linear.cpp
#include <executorch/runtime/kernel/kernel_includes.h>
Tensor& custom_linear_out(const Tensor& weight, const Tensor& input, optional<Tensor> bias, Tensor& out) {
// calculation
return out;
}
使用 C++ 宏将其注册到 ExecuTorch 中¶
在上面的示例中追加以下行
// custom_linear.h/custom_linear.cpp
// opset namespace myop
EXECUTORCH_LIBRARY(myop, "custom_linear.out", custom_linear_out);
现在我们需要为此算子编写一些包装器,以便其在 PyTorch 中出现,但别担心,我们不需要重写内核。为此创建一个单独的 .cpp 文件
// custom_linear_pytorch.cpp
#include "custom_linear.h"
#include <torch/library.h>
at::Tensor custom_linear(const at::Tensor& weight, const at::Tensor& input, std::optional<at::Tensor> bias) {
// initialize out
at::Tensor out = at::empty({weight.size(1), input.size(1)});
// wrap kernel in custom_linear.cpp into ATen kernel
WRAP_TO_ATEN(custom_linear_out, 3)(weight, input, bias, out);
return out;
}
// standard API to register ops into PyTorch
TORCH_LIBRARY(myop, m) {
m.def("custom_linear(Tensor weight, Tensor input, Tensor(?) bias) -> Tensor", custom_linear);
m.def("custom_linear.out(Tensor weight, Tensor input, Tensor(?) bias, *, Tensor(a!) out) -> Tensor(a!)", WRAP_TO_ATEN(custom_linear_out, 3));
}
编译并链接自定义内核¶
将其链接到 ExecuTorch 运行时:在用于构建二进制/应用程序的 CMakeLists.txt 中,我们需要将 custom_linear.h/cpp 添加到二进制目标中。我们也可以构建并链接一个动态加载库(.so 或 .dylib)。
这是一个示例
# For target_link_options_shared_lib
include(${EXECUTORCH_ROOT}/tools/cmake/Utils.cmake)
# Add a custom op library
add_library(custom_op_lib SHARED ${CMAKE_CURRENT_SOURCE_DIR}/custom_op.cpp)
# Include the header
target_include_directory(custom_op_lib PUBLIC ${CMAKE_CURRENT_SOURCE_DIR}/include)
# Link ExecuTorch library
target_link_libraries(custom_op_lib PUBLIC executorch)
# Define a binary target
add_executable(custom_op_runner PUBLIC main.cpp)
# Link this library with --whole-archive !! IMPORTANT !! this is to avoid the operators being stripped by linker
target_link_options_shared_lib(custom_op_lib)
# Link custom op lib
target_link_libraries(custom_op_runner PUBLIC custom_op_lib)
将其链接到 PyTorch 运行时:我们需要将 custom_linear.h、custom_linear.cpp 和 custom_linear_pytorch.cpp 打包成一个动态加载库(.so 或 .dylib),并将其加载到我们的 python 环境中。一种方法是
import torch
torch.ops.load_library("libcustom_linear.so/dylib")
# Now we have access to the custom op, backed by kernel implemented in custom_linear.cpp.
op = torch.ops.myop.custom_linear.default
在模型中使用自定义算子¶
自定义算子可以在 PyTorch 模型中显式使用,或者您可以编写一个转换来用自定义变体替换核心算子的实例。对于此示例,您可以找到所有 torch.nn.Linear 的实例并将其替换为 CustomLinear。
def replace_linear_with_custom_linear(module):
for name, child in module.named_children():
if isinstance(child, nn.Linear):
setattr(
module,
name,
CustomLinear(child.in_features, child.out_features, child.bias),
)
else:
replace_linear_with_custom_linear(child)
剩余步骤与正常流程相同。现在您可以在 eager 模式下运行此模块,也可以导出到 ExecuTorch。
自定义算子 API 最佳实践¶
考虑到我们有两个自定义算子内核注册 API,应该使用哪个 API?以下是每个 API 的一些优点和缺点
C++ API
优点
只需修改 C++ 代码
类似于 PyTorch 自定义算子 C++ API
维护成本低
缺点
不支持选择性构建
没有集中的记录
YAML 入口 API
优点
支持选择性构建
为自定义算子提供集中位置
对于一个应用程序,它显示了哪些算子正在注册以及哪些内核绑定到这些算子
缺点
用户需要创建和维护 yaml 文件
更改算子定义相对不灵活
总的来说,如果我们正在构建一个使用自定义算子的应用程序,在开发阶段建议使用 C++ API,因为它使用成本低且灵活易变。一旦应用程序进入生产阶段,自定义算子定义和构建系统相当稳定,且需要考虑二进制大小时,建议使用 Yaml 入口 API。
