概念¶
本页概述了 ExecuTorch 文档中使用的关键概念和术语。旨在帮助读者理解 PyTorch Edge 和 ExecuTorch 中使用的术语和概念。
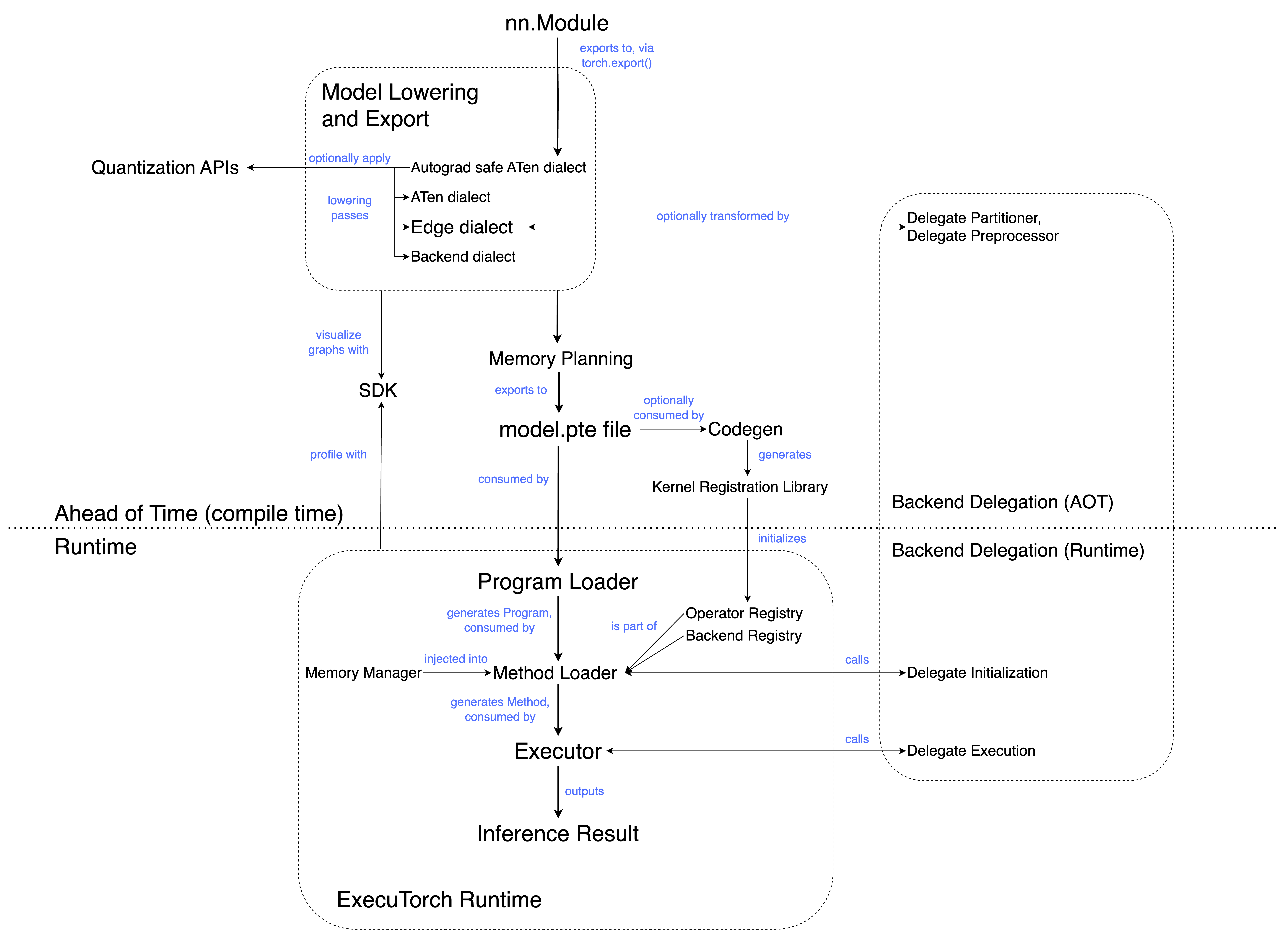
AOT (提前编译)¶
AOT 通常指在执行之前进行的程序准备。概括地说,ExecuTorch 工作流程分为 AOT 编译和运行时。AOT 步骤包括编译为中间表示 (IR),以及可选的转换和优化。
ATen 方言¶
ATen 方言是将 eager 模块导出为图表示的直接结果。它是 ExecuTorch 编译流水线的入口点;导出为 ATen 方言后,后续 Pass 可以将其降低到 Core ATen 方言 和 Edge 方言。
ATen 方言是具有额外属性的有效 EXIR。它包含函数式 ATen 算子、高阶算子(如控制流算子)以及注册的自定义算子。
ATen 方言的目标是尽可能忠实地捕获用户的程序。
ATen 模式¶
ATen 模式使用 PyTorch 核心中的 Tensor (即 at::Tensor) 和相关类型 (如 ScalarType) 的 ATen 实现。这与 ETensor 模式形成对比,ETensor 模式使用 ExecuTorch 中更小的 Tensor 实现 (即 executorch::runtime::etensor::Tensor) 和相关类型 (如 executorch::runtime::etensor::ScalarType)。
依赖完整
at::TensorAPI 的 ATen 内核在此配置下可用。ATen 内核倾向于进行动态内存分配,并且通常具有额外的灵活性(以及由此带来的开销)来处理移动/嵌入式客户端不需要的情况。例如,CUDA 支持、稀疏张量支持和 dtype 提升。
注意:ATen 模式目前正在开发中 (WIP)。
Autograd 安全的 ATen 方言¶
Autograd 安全的 ATen 方言仅包含可微分的 ATen 算子,以及高阶算子(控制流算子)和注册的自定义算子。
后端¶
接收整个图或其中一部分,并带来性能和效率提升的特定硬件(如 GPU、NPU)或软件栈(如 XNNPACK)。
后端方言¶
后端方言是将 Edge 方言导出到特定后端的直接结果。它具备目标感知能力,可能包含仅对目标后端有意义的算子或子模块。这种方言允许引入特定于目标的算子,这些算子不符合 Core ATen 算子集中定义的模式,并且不在 ATen 或 Edge 方言中显示。
后端注册表¶
将后端名称映射到后端接口的表。这允许在运行时通过名称调用后端。
特定后端算子¶
这些算子不属于 ATen 方言或 Edge 方言。特定后端算子仅由 Edge 方言之后的 Pass 引入(参见后端方言)。这些算子特定于目标后端,通常执行速度更快。
代码生成¶
概括地说,代码生成执行两项任务:生成 内核注册 库,以及可选地运行 选择性构建。
内核注册库将算子名称(模型中引用)与相应的内核实现(来自内核库)连接起来。
选择性构建 API 从模型和/或其它来源收集算子信息,并且仅包含它们所需的算子。这可以减小二进制文件的大小。
代码生成的输出是一组 C++ 绑定(各种 .h、.cpp 文件),它们将内核库和 ExecuTorch 运行时粘合在一起。
Core ATen 方言¶
Core ATen 方言包含核心 ATen 算子以及高阶算子(控制流)和注册的自定义算子。
核心 ATen 算子 / 标准 ATen 算子集¶
PyTorch ATen 算子库的一个精选子集。使用核心 ATen 分解表导出时,核心 ATen 算子不会被分解。它们作为后端或编译器应从上游期望的基线 ATen 算子的参考。
Core ATen 分解表¶
分解算子意味着将其表达为其他算子的组合。在 AOT 过程中,会采用默认的分解列表,将 ATen 算子分解为核心 ATen 算子。这称为 Core ATen 分解表。
自定义算子¶
这些算子不属于 ATen 库,但出现在 eager 模式 中。注册的自定义算子通常通过 TORCH_LIBRARY 调用注册到当前的 PyTorch eager 模式运行时中。它们很可能与特定的目标模型或硬件平台相关联。例如,torchvision::roi_align 是 torchvision 广泛使用的自定义算子(不针对特定硬件)。
DataLoader¶
一个接口,使 ExecuTorch 运行时能够从文件或其他数据源读取数据,而无需直接依赖于操作系统概念,如文件或内存分配。
维度顺序¶
ExecuTorch 引入了 维度顺序 来描述张量的内存格式,通过返回维度从最外层到最内层的排列。
例如,对于内存格式为 [N, C, H, W] 或 连续 内存格式的张量,[0, 1, 2, 3] 将是其维度顺序。
此外,对于内存格式为 [N, H, W, C] 或 channels_last 内存格式 的张量,我们返回 [0, 2, 3, 1] 作为其维度顺序。
目前,ExecuTorch 仅支持 连续 和 channels_last 内存格式的维度顺序表示。
DSP (数字信号处理器)¶
一种针对数字信号处理优化了架构的专用微处理器芯片。
dtype¶
数据类型,张量中数据的类型(例如,浮点数、整数等)。
动态形状¶
指模型在推理过程中能够接受不同形状输入的能力。例如,ATen 算子 unique_consecutive 和自定义算子 MaskRCNN 的输出形状依赖于数据。对这类算子进行内存规划很困难,因为即使输入形状相同,每次调用也可能产生不同的输出形状。为了在 ExecuTorch 中支持动态形状,内核可以使用客户端提供的 MemoryAllocator 分配张量数据。
Eager 模式¶
Python 执行环境,其中模型中的算子在遇到时立即执行。例如,Jupyter / Colab notebook 在 eager 模式下运行。这与 graph 模式形成对比,graph 模式中算子首先被合成为图,然后编译并执行。
Edge 方言¶
EXIR 的一种方言,具有以下属性
所有算子均来自预定义的算子集,称为“Edge 算子”或注册的自定义算子。
图以及每个节点的输入和输出必须是 Tensor。所有 Scalar 类型都被转换为 Tensor。
Edge 方言引入了对边缘设备有用的特化,但不一定适用于通用(服务器)导出。然而,Edge 方言不包含针对特定硬件的特化,除了原始 Python 程序中已有的特化。
Edge 算子¶
带有 dtype 特化的 ATen 算子。
ExecuTorch¶
PyTorch Edge 平台内的一个统一 ML 软件栈,旨在实现高效的设备端推理。ExecuTorch 定义了一个工作流程,用于在移动、可穿戴设备和嵌入式设备等边缘设备上准备(导出和转换)和执行 PyTorch 程序。
ExecuTorch 方法¶
nn.Module Python 方法的可执行等价物。例如,forward() Python 方法会编译成一个 ExecuTorch Method。
ExecuTorch 程序¶
一个 ExecuTorch Program 将诸如 forward 之类的字符串名称映射到特定的 ExecuTorch Method 入口。
executor_runner¶
包含所有算子和后端的 ExecuTorch 运行时的一个示例包装器。
ExportedProgram¶
torch.export 的输出,它将 PyTorch 模型(通常是 nn.Module)的计算图与模型消耗的参数或权重捆绑在一起。
flatbuffer¶
一种内存效率高、跨平台的序列化库。在 ExecuTorch 的上下文中,eager 模式的 PyTorch 模型被导出为 flatbuffer 格式,这是 ExecuTorch 运行时消耗的格式。
框架开销¶
各种加载和初始化任务(非推理)的开销。例如:加载程序、初始化执行器、内核和后端委托分派,以及运行时内存利用。
函数式 ATen 算子¶
没有任何副作用的 ATen 算子。
Graph 模式¶
在 graph 模式下,算子首先被合成为一个图,然后作为一个整体进行编译和执行。这与 eager 模式形成对比,eager 模式下算子在遇到时即执行。Graph 模式通常提供更高的性能,因为它允许算子融合等优化。
高阶算子¶
高阶算子 (HOP) 是指以下类型的算子
接受 Python 函数作为输入,或返回 Python 函数作为输出,或两者皆是。
与所有 PyTorch 算子一样,高阶算子也具有针对后端和功能的可选实现。这使我们能够例如注册高阶算子的 autograd 公式,或定义高阶算子在 ProxyTensor 追踪下的行为。
混合量化¶
一种量化技术,根据计算复杂度和对精度损失的敏感性,模型不同部分采用不同的技术进行量化。模型某些部分可能不进行量化以保留精度。
中间表示 (IR)¶
源语言和目标语言之间的程序表示形式。通常,它是编译器或虚拟机内部用于表示源代码的数据结构。
内核¶
算子的实现。一个算子可以有针对不同后端/输入等的多种实现。
内核注册表 / 算子注册表¶
包含内核名称与其实现之间映射的表。这使得 ExecuTorch 运行时能够在执行期间解析对内核的引用。
降低¶
将模型转换为在各种后端上运行的过程。称之为“降低”是因为它将代码移得更接近硬件。在 ExecuTorch 中,降低作为后端委托的一部分执行。
内存规划¶
为模型分配和管理内存的过程。在 ExecuTorch 中,在将图保存到 flatbuffer 之前会运行一个内存规划 Pass。这将为每个张量分配一个内存 ID 和缓冲区中的偏移量,标记张量存储的起始位置。
节点¶
EXIR 图中的一个节点代表特定的计算或操作,在 Python 中使用 torch.fx.Node 类表示。
算子¶
在张量上执行的函数。这是抽象;内核是实现。一个算子可以有针对不同后端/输入等的多种实现。
算子融合¶
算子融合是将多个算子组合成一个复合算子的过程,由于减少了内核启动次数和内存读写次数,从而加快了计算速度。这是 graph 模式相对于 eager 模式的性能优势。
Out 变体¶
算子的 out 变体不会在内核实现中分配返回的张量,而是将其结果存储到通过 out kwarg 传入的预分配张量中。
这使得内存规划器更容易执行张量生命周期分析。在 ExecuTorch 中,在内存规划之前会执行一个 out 变体 Pass。
部分内核¶
支持部分张量 dtype 和/或维度顺序的内核。
分区器¶
模型的部分可能被委托到优化的后端上运行。分区器将图分割成适当的子网络并标记它们以进行委托。
ETensor 模式¶
ETensor 模式使用 ExecuTorch 中更小的张量实现(executorch::runtime::etensor::Tensor)以及相关类型(executorch::runtime::etensor::ScalarType 等)。这与 ATen 模式形成对比,ATen 模式使用 ATen 实现的张量(at::Tensor)和相关类型(ScalarType 等)。
executorch::runtime::etensor::Tensor,也称为 ETensor,是at::Tensor的源代码兼容子集。针对 ETensor 编写的代码可以针对at::Tensor进行构建。ETensor 本身不拥有或分配内存。为了支持动态形状,内核可以使用客户端提供的 MemoryAllocator 分配 Tensor 数据。
可移植内核¶
可移植内核是算子实现,它们被编写成与 ETensor 兼容。由于 ETensor 与 at::Tensor 兼容,可移植内核可以针对 at::Tensor 进行构建,并与 ATen 内核在同一模型中使用。可移植内核具有以下特点:
与 ATen 算子签名兼容
使用可移植 C++ 编写,因此可以针对任何目标进行构建
作为参考实现编写,优先考虑清晰度和简洁性而非优化
通常比 ATen 内核尺寸更小
编写时避免使用 new/malloc 进行动态内存分配。
程序¶
描述 ML 模型的代码和数据的集合。
程序源代码¶
描述程序的 Python 源代码。它可以是 Python 函数,也可以是 PyTorch eager 模式 nn.Module 中的方法。
PTQ (训练后量化)¶
一种量化技术,模型在训练后进行量化(通常为了性能提升)。PTQ 在训练后应用量化流程,这与 QAT 在训练期间应用形成对比。
QAT (量化感知训练)¶
模型在量化后可能会损失精度。与 PTQ 等技术相比,QAT 通过在训练期间模拟量化的影响,从而实现更高的精度。在训练期间,所有权重和激活都被“伪量化”;浮点值被四舍五入以模拟 int8 值,但所有计算仍然使用浮点数完成。因此,训练期间进行的所有权重调整都“感知”到模型最终将被量化。QAT 在训练期间应用量化流程,这与 PTQ 在训练后应用形成对比。
