使用 QLoRA 微调 Llama2¶
在本教程中,我们将学习 QLoRA,它是 LoRA 的一项增强,可以将冻结的模型参数保持在 4 位量化精度,从而减少内存使用。我们将逐步介绍如何在 torchtune 中利用 QLoRA 在 <10 GB 内存中微调 Llama2-7b 模型。强烈建议先了解 torchtune 中的 LoRA 微调。
QLoRA 如何比 LoRA 微调节省内存
torchtune 中 QLoRA 概览
如何在 torchtune 中运行 QLoRA 微调
熟悉 torchtune
确保已下载 Llama2-7B 模型权重
什么是 QLoRA?¶
QLoRA 在 LoRA 的基础上构建,以进一步节省内存。在 LoRA 中,模型参数可以被视为存在于两个部分:适配器(adapter),它们是添加到神经网络不同层的低秩矩阵;以及基础模型参数(base model parameters),它们是原始模型的一部分。在普通的 LoRA 风格训练中,这两个参数都保持相同的精度(通常是 fp32 或 bf16),因此计算的激活和中间梯度都采用 fp32/bf16 格式。
QLoRA 进一步将基础模型参数量化为定制的 4 位 NormalFloat (NF4) 数据类型,从而使参数内存使用量减少 4-8 倍,同时在很大程度上保留了模型精度。因此,绝大多数参数仅占用 4 位(而不是 bf16/fp32 数据类型所需的 16 或 32 位)。这种量化是通过原始 QLoRA 论文中强调的方法完成的。适配器参数仍保持原始精度,激活、梯度和优化器状态仍以更高精度存在,以保持准确性。
QLoRA 作者引入了两个关键抽象来减少内存使用并避免精度下降:定制的 4 位 NormalFloat 类型,以及一种双重量化方法,该方法将量化参数本身进行量化以节省更多内存。torchtune 使用 NF4Tensor 抽象从 torchao 库来构建论文中指定的 QLoRA 组件。torchao 是一个 PyTorch 原生库,允许您量化和剪枝模型。
使用 QLoRA 节省内存¶
在本节中,我们将概述如何在 torchtune 中将 QLoRA 应用于 LoRALinear 层。有关 torchtune 中 QLoRA 和底层抽象的详细信息,请参阅本教程的 QLoRA in torchtune deepdive 部分。
QLoRA 的一个核心思想是计算数据类型 (dtypes) 和存储数据类型的区别。具体来说,QLoRA 将基础模型参数存储在 4 位精度(即存储 dtype)中,并在原始更高精度(计算 dtype,通常是 fp32 或 bf16)中运行计算。第一步,QLoRA 需要将这些基础模型参数量化到 4 位精度并存储它们。
要以 QLoRA 方式量化 LoRALinear 层,只需将 quantize_base 标志设置为 True 传递给 LoRALinear。此标志将导致基础模型权重被量化,并由 NF4Tensor dtype 支持。前向传播也会自动处理以使用 NF4Tensor dtype,具体来说,NF4 基础权重将被反量化到计算精度,计算激活,并且在反向传播中仅存储 4 位参数用于梯度计算,避免了存储更高精度计算 dtype 所带来的额外内存开销。
下面是一个创建量化 LoRALinear 层与未量化 LoRALinear 层进行比较的示例。正如我们所见,量化层比未量化层消耗的内存少约 8 倍。
import torch
from torchtune.modules.peft import LoRALinear
torch.set_default_device("cuda")
qlora_linear = LoRALinear(512, 512, rank=8, alpha=0.1, quantize_base=True)
print(torch.cuda.memory_allocated()) # 177,152 bytes
del qlora_linear
torch.cuda.empty_cache()
lora_linear = LoRALinear(512, 512, rank=8, alpha=0.1, quantize_base=False)
print(torch.cuda.memory_allocated()) # 1,081,344 bytes
在 torchtune 中使用 QLoRA¶
现在我们将介绍如何初始化一个支持 QLoRA 的 Llama2-7b 模型,以及 QLoRA 检查点的一些详细信息。
使用 torchtune,您可以使用一个类似于 LoRA 构建器 (lora_llama_2_7b) 的简单构建器将 QLoRA 应用于 Llama2 模型。下面是一个初始化启用 QLoRA 的 Llama2-7b 模型的简单示例
from torchtune.models.llama2 import qlora_llama2_7b
qlora_model = qlora_llama2_7b(lora_attn_modules=["q_proj", "v_proj"])
在底层,这将对所有注意力层中的 q_proj 和 v_proj 矩阵应用 LoRA,并进一步将这些矩阵中的基础参数量化为 NF4 dtype。请注意,基础模型参数的量化仅应用于配置了 LoRA 适配器的层。例如,在这种情况下,注意力层中的 k_proj 和 output_proj 没有应用 LoRA,因此它们的基础模型参数未被量化。我们可以通过打印特定注意力层的基础模型参数 dtype 来看到这一点
attn = qlora_model.layers[0].attn
print(type(attn.q_proj.weight)) # <class 'torchao.dtypes.nf4tensor.NF4Tensor'>
print(type(attn.k_proj.weight)) # <class 'torch.nn.parameter.Parameter'>
接下来,有一些对于支持 QLoRA 的模型的检查点(即 state_dict)至关重要的细节。为了与 torchtune 的 检查点功能良好集成,我们需要将 NF4Tensors 转换回其原始精度(通常是 fp32/bf16)。这使得 QLoRA 训练的检查点能够在 torchtune 内外(例如训练后量化、评估、推理)与其他生态系统良好互操作。此转换过程还允许将 LoRA 适配器权重合并回基础模型,就像典型的 LoRA 训练流程中那样。
为了实现这一点,在使用 torchtune 的 lora_llama_2_7b 构建器时,我们会自动注册一个钩子 reparametrize_as_dtype_state_dict_post_hook,该钩子在对顶级模型调用 .state_dict() 后运行。此钩子将 NF4Tensors 转换回其原始精度,同时也将这些转换后的张量卸载到 CPU。此卸载是为了避免内存峰值;如果我们不这样做,就必须在 GPU 上保留 state_dict 的完整 bf16/fp32 副本。
综合来看:QLoRA 微调¶
综合来看,现在我们可以使用 torchtune 的 LoRA 单设备微调配方,配合QLoRA 配置来微调模型。
请确保您已首先按照这些说明下载了 Llama2 权重和分词器。然后,您可以运行以下命令,在单个 GPU 上执行 Llama2-7B 的 QLoRA 微调。
tune run lora_finetune_single_device --config llama2/7B_qlora_single_device
注意
请确保正确指向您的 Llama2 权重和分词器位置。这可以通过添加 checkpointer.checkpoint_files=[my_model_checkpoint_path] tokenizer_checkpoint=my_tokenizer_checkpoint_path 或直接修改 7B_qlora_single_device.yaml 文件来完成。有关如何轻松克隆和修改 torchtune 配置的更多详细信息,请参阅我们的“关于配置的一切”配方。
默认情况下,此运行将在模型初始化时以及训练期间每 100 次迭代记录内存峰值统计信息。让我们了解 QLoRA 在 LoRA 训练基础上实现的内存节省。LoRA 训练可以按如下方式运行
tune run lora_finetune_single_device --config llama2/7B_lora_single_device
您应该会看到在模型初始化和训练期间打印出的内存使用情况。LoRA 模型初始化的示例日志如下
Memory Stats after model init::
GPU peak memory allocation: 13.96 GB
GPU peak memory reserved: 13.98 GB
GPU peak memory active: 13.96 GB
下表比较了 QLoRA 在模型初始化和训练期间保留的内存与普通 LoRA 的对比。我们可以看到,QLoRA 在模型初始化期间将内存峰值降低了约 35%,在模型训练期间降低了约 40%
微调方法 |
保留内存峰值,模型初始化 |
保留内存峰值,训练中 |
|---|---|---|
LoRA |
13.98 GB |
15.57 GB |
QLoRA |
9.13 GB |
9.29 GB |
从日志中可以看出,开箱即用的训练性能相当慢,每秒不到 1 次迭代
1|149|Loss: 0.9157477021217346: 1%| | 149/25880 [02:08<6:14:19, 1.15it/s
为了加快速度,我们可以利用 torch.compile 来编译模型并运行编译后的结果。要使用 QLoRA 训练,必须使用 PyTorch 的 nightly build。要将 PyTorch 更新到最新的 nightly build,请参阅安装说明。更新后,您可以通过配置覆盖将 compile 标志指定为 True
tune run lora_finetune_single_device --config llama2/7B_qlora_single_device compile=True
从日志中我们可以看到大约 200% 的速度提升(在训练稳定后的几百次迭代后)
1|228|Loss: 0.8158286809921265: 1%| | 228/25880 [11:59<1:48:16, 3.95it/s
下面可以看到 QLoRA 和 LoRA 之间平滑损失曲线的比较。
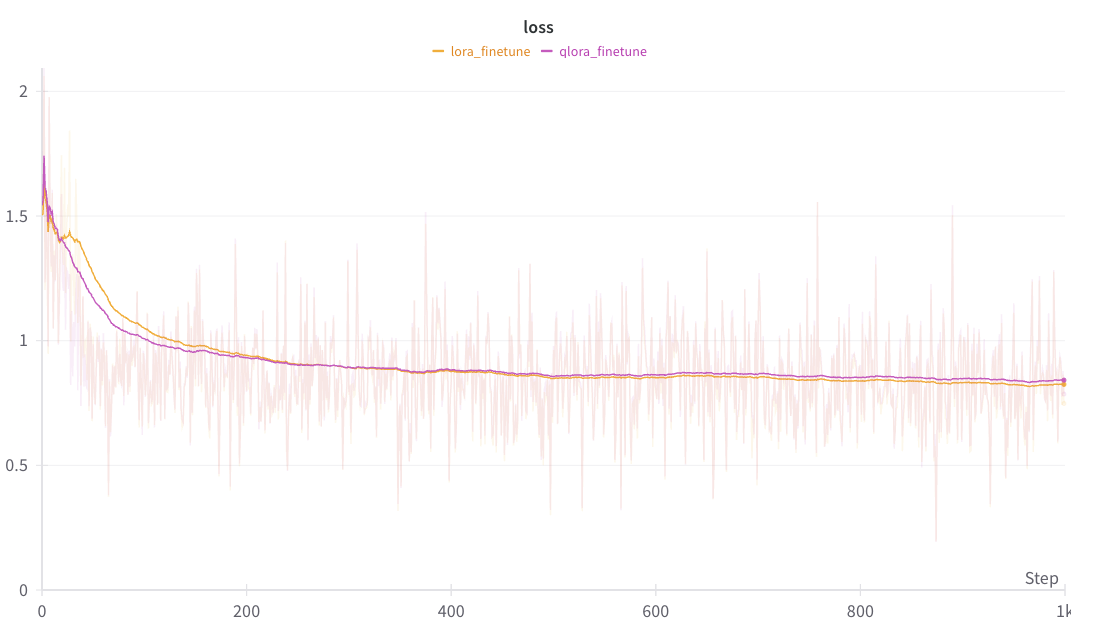
注意
上图是使用 W&B 生成的。您可以使用 torchtune 的 WandBLogger 生成类似的损失曲线,但您需要单独安装 W&B 并设置账户。有关在 torchtune 中使用 W&B 的更多详细信息,请参阅我们的“记录到 Weights & Biases”配方。
作为练习,您还可以尝试运行一些评估任务或手动检查由您保存的检查点(可在 output_dir 中找到)生成的输出。
在最后一部分,我们将深入探讨如何从 LoRA 组件构建 QLoRA 组件。
深度解析:从 LoRA 构建 QLoRA¶
本深度解析部分从本教程的 使用 QLoRA 节省内存 部分继续,深入探讨如何使用 NF4Tensor 进行量化以及在前向传播中如何适当处理。
首先,我们将从一个普通的最小 LoRA 层开始,它取自LoRA 教程并进行了增强以支持量化
import torch
from torch import nn
import torch.nn.functional as F
from torchao.dtypes.nf4tensor import linear_nf4, to_nf4
class LoRALinear(nn.Module):
def __init__(
self,
in_dim: int,
out_dim: int,
rank: int,
alpha: float,
dropout: float,
quantize_base: bool
):
# These are the weights from the original pretrained model
self.linear = nn.Linear(in_dim, out_dim, bias=False)
self.linear_weight = self.linear.weight
# Use torchao's to_nf4 API to quantize the base weight if needed.
if quantize_base:
self.linear_weight = to_nf4(self.linear_weight)
# These are the new LoRA params. In general rank << in_dim, out_dim
self.lora_a = nn.Linear(in_dim, rank, bias=False)
self.lora_b = nn.Linear(rank, out_dim, bias=False)
# Rank and alpha are commonly-tuned hyperparameters
self.rank = rank
self.alpha = alpha
# Most implementations also include some dropout
self.dropout = nn.Dropout(p=dropout)
# The original params are frozen, and only LoRA params are trainable.
self.linear.weight.requires_grad = False
self.lora_a.weight.requires_grad = True
self.lora_b.weight.requires_grad = True
def forward(self, x: torch.Tensor) -> torch.Tensor:
# frozen_out would be the output of the original model
if quantize_base:
# Call into torchao's linear_nf4 to run linear forward pass w/quantized weight.
frozen_out = linear_nf4(x, self.weight)
else:
frozen_out = F.linear(x, self.weight)
# lora_a projects inputs down to the much smaller self.rank,
# then lora_b projects back up to the output dimension
lora_out = self.lora_b(self.lora_a(self.dropout(x)))
# Finally, scale by the alpha parameter (normalized by rank)
# and add to the original model's outputs
return frozen_out + (self.alpha / self.rank) * lora_out
如上所述,torchtune 依赖于 torchao 来获取 QLoRA所需的一些核心组件。这包括 NF4Tensor,以及诸如 to_nf4 和 linear_nf4 的实用工具。
在 LoRA 层之上的关键更改是使用了 to_nf4 和 linear_nf4 API。
to_nf4 接受一个未量化(bf16 或 fp32)的张量,并生成权重的 NF4 表示。有关 to_nf4 的实现细节,请参阅此处。linear_nf4 处理使用量化基础模型权重运行时的前向传播和自动梯度。它使用输入的激活和未量化权重计算前向传播,就像普通的 F.linear 一样。量化权重会保存用于反向传播,而不是权重的未量化版本,以避免由于存储更高精度变量来计算反向传播中的梯度而产生的额外内存使用。有关 linear_nf4 的更多详细信息,请参阅此处。
