使用 QAT 微调 Llama3¶
量化感知训练 (QAT) 是一种常用技术,用户可以使用它对模型进行量化,而不会在准确性或困惑度方面产生显著下降。在本教程中,我们将详细介绍如何在微调期间应用 QAT、量化生成的模型以及使用 torchtune 评估量化模型。
什么是 QAT 以及它如何帮助减少量化退化
如何在 torchtune 中运行 QAT 进行微调
连接 QAT、量化和评估 Recipes 的端到端示例
熟悉 torchtune
确保您已安装 torchtune
确保您已下载Llama3-8B 模型权重
什么是 QAT?¶
量化感知训练 (QAT) 是指在训练或微调期间模拟量化数值,最终目标是生成比简单训练后量化 (PTQ) 更高质量的量化模型。在 QAT 期间,权重和/或激活会被“伪量化”,这意味着它们会像被量化一样进行转换,但保留在原始数据类型(例如 bfloat16)中,而不会实际转换为更低的位宽。因此,伪量化允许模型在更新权重时调整量化噪声,从而使训练过程“感知”到模型最终会在训练后被量化。
# PTQ: x_q is quantized and cast to int8
# scale and zero point (zp) refer to parameters used to quantize x_float
# qmin and qmax refer to the range of quantized values
x_q = (x_float / scale + zp).round().clamp(qmin, qmax).cast(int8)
# QAT: x_fq is still in float
# Fake quantize simulates the numerics of quantize + dequantize
x_fq = (x_float / scale + zp).round().clamp(qmin, qmax)
x_fq = (x_fq - zp) * scale
QAT 通常涉及在训练前后对模型应用转换。例如,在 torchao QAT 实现中,这些步骤表示为 prepare() 和 convert():(1) prepare() 将伪量化操作插入到线性层中,(2) convert() 在训练后将伪量化操作转换为实际的量化和反量化操作,从而生成量化模型(反量化操作通常在 lowering 后与线性层融合)。在这两个步骤之间,训练可以完全照常进行。
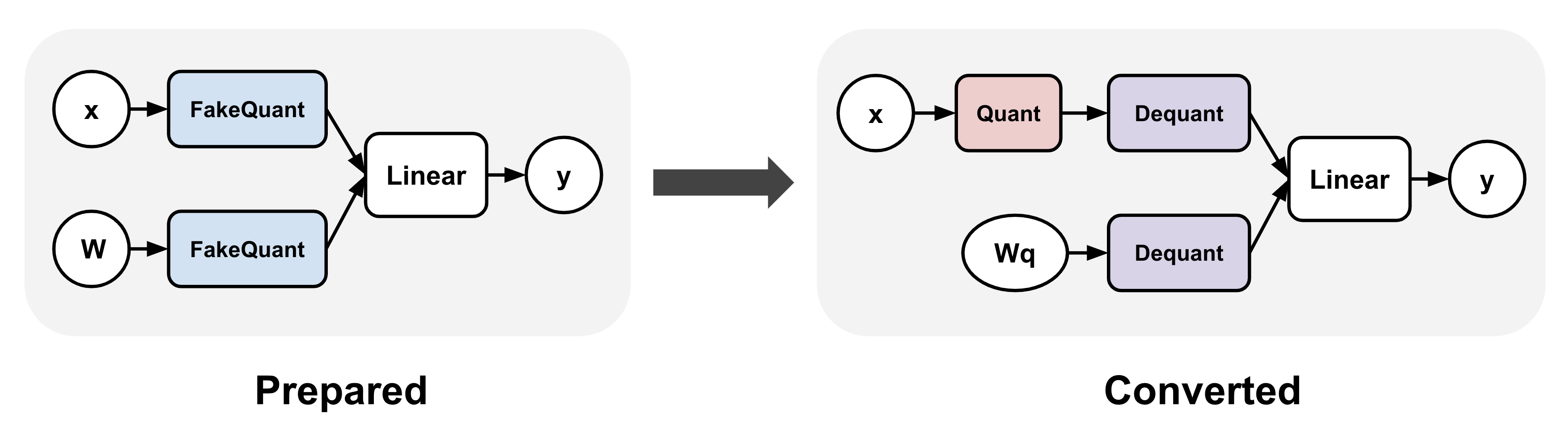
将 QAT 应用于 Llama3 模型¶
我们可以轻松地在 torchtune 中将上述 QAT 转换应用于 Llama3 进行微调
from torchtune.training.quantization import Int8DynActInt4WeightQATQuantizer
from torchtune.models.llama3 import llama3_8b
model = llama3_8b()
# Quantizer for int8 dynamic per token activations +
# int4 grouped per channel weights, only for linear layers
quantizer = Int8DynActInt4WeightQATQuantizer()
# Insert "fake quantize" operations into linear layers.
# These operations simulate quantization numerics during
# fine-tuning without performing any dtype casting
prepared_model = quantizer.prepare(model)
如果我们打印模型,会看到所有线性层都已被 Int8DynActInt4WeightQATLinear 替换,它模拟了 int8 动态每 token 激活 + int4 分组每通道权重的数值。现在模型已准备好进行微调。
>>> print(model.layers[0].attn)
MultiHeadAttention(
(q_proj): Linear(in_features=4096, out_features=4096, bias=False)
(k_proj): Linear(in_features=4096, out_features=1024, bias=False)
(v_proj): Linear(in_features=4096, out_features=1024, bias=False)
(output_proj): Linear(in_features=4096, out_features=4096, bias=False)
(pos_embeddings): RotaryPositionalEmbeddings()
)
>>> print(prepared_model.layers[0].attn)
MultiHeadAttention(
(q_proj): Int8DynActInt4WeightQATLinear(in_features=4096, out_features=4096, bias=False)
(k_proj): Int8DynActInt4WeightQATLinear(in_features=4096, out_features=1024, bias=False)
(v_proj): Int8DynActInt4WeightQATLinear(in_features=4096, out_features=1024, bias=False)
(output_proj): Int8DynActInt4WeightQATLinear(in_features=4096, out_features=4096, bias=False)
(pos_embeddings): RotaryPositionalEmbeddings()
)
微调后,我们可以转换模型以获得实际的量化模型。如果我们打印转换后的模型,会看到 QAT 线性层已替换为 Int8DynActInt4WeightLinear,这是线性层的量化版本。然后可以将这个量化模型保存为检查点并用于推理或生成。
# Fine-tune as before
train_loop(prepared_model)
# Convert fake quantize to actual quantize operations
converted_model = quantizer.convert(prepared_model)
>>> print(converted_model.layers[0].attn)
MultiHeadAttention(
(q_proj): Int8DynActInt4WeightLinear()
(k_proj): Int8DynActInt4WeightLinear()
(v_proj): Int8DynActInt4WeightLinear()
(output_proj): Int8DynActInt4WeightLinear()
(pos_embeddings): RotaryPositionalEmbeddings()
)
torchtune 中的 QAT 微调 Recipe¶
将所有这些结合起来,我们现在可以使用 torchtune 的QAT Recipe 来微调模型。请务必先按照这些说明下载 Llama3 权重和分词器。在本教程中,我们使用以下设置来演示 QAT 在恢复量化退化方面的有效性,与直接量化未进行 QAT 微调的模型相比。您可以复制默认的 QAT config 并相应地进行以下修改
tune cp llama3/8B_qat_full custom_8B_qat_full.yaml
# Dataset
dataset:
_component_: torchtune.datasets.text_completion_dataset
source: allenai/c4
max_seq_len: 8192
column: text
name: en
split: train
seed: null
shuffle: True
...
epochs: 1
max_steps_per_epoch: 2000
fake_quant_after_n_steps: 1000
memory_efficient_fsdp_wrap: False
根据经验,我们观察到在前 N 步禁用伪量化会带来更好的结果,这可能是因为它允许权重在开始向微调过程引入量化噪声之前稳定下来。因此,这里我们在前 1000 步禁用了伪量化。
然后您可以使用以下命令,通过上述 config 运行带有 QAT 的微调。该工作负载需要至少 6 个 GPU,每个 GPU 的显存至少为 80GB。默认情况下,这使用如上所示的 int8 动态每 token 激活 + int4 分组每通道权重量化配置
tune run --nnodes 1 --nproc_per_node 6 qat_distributed --config custom_8B_qat_full.yaml
注意
确保指向您的 Llama3 权重和分词器位置。这可以通过添加 checkpointer.checkpoint_files=[my_model_checkpoint_path] tokenizer_checkpoint=my_tokenizer_checkpoint_path 或直接修改 8B_qat_full.yaml 文件来完成。有关如何轻松克隆和修改 torchtune config 的更多详细信息,请参阅我们的关于配置的一切。
注意
与常规微调相比,QAT 会引入内存和计算开销,因为伪量化本质上涉及额外的操作,并且需要克隆权重以避免在计算伪量化值时修改它们。总的来说,我们预计像 Llama3-8B 这样的模型,微调速度会降低约 30%。通过激活检查点,每个 GPU 的内存占用增加最小(每个 GPU < 5GB)。
量化 QAT 模型¶
请注意,上面的 QAT Recipe 会生成一个未量化的 bfloat16 模型。模型结构与不使用 QAT 进行常规完全微调生成的模型完全相同,只是权重不同。要实际获得量化模型,请复制并对量化 config 进行以下修改
tune cp quantization custom_quantization.yaml
# Model arguments
model:
_component_: torchtune.models.llama3.llama3_8b
checkpointer:
_component_: torchtune.training.FullModelMetaCheckpointer
checkpoint_dir: <your QAT checkpoint dir>
checkpoint_files: [meta_model_0.pt]
recipe_checkpoint: null
output_dir: <your QAT checkpoint dir>
model_type: LLAMA3
...
quantizer:
_component_: torchtune.training.quantization.Int8DynActInt4WeightQATQuantizer
groupsize: 256
以下命令执行 QAT 流程中的 convert 步骤,它实际上将浮点模型量化为具有量化权重的模型
tune run quantize --config custom_quantization.yaml
注意
确保使用与微调模型时相同的 QAT 量化器,否则数值会不准确,量化模型的性能会很差。
评估量化模型¶
现在我们有了一个量化模型,我们可以对其进行一些评估,并将结果与不使用 QAT 的常规微调(即训练后量化)进行比较。为了实现这一点,我们使用了集成在 torchtune 中的 EleutherAI 的评估工具 (evaluation harness)。首先,复制评估 config 并进行以下更改
tune cp eleuther_evaluation custom_eleuther_evaluation.yaml
# Model arguments
model:
_component_: torchtune.models.llama3.llama3_8b
checkpointer:
_component_: torchtune.training.FullModelTorchTuneCheckpointer
checkpoint_dir: <your quantized model checkpoint dir>
checkpoint_files: [meta_model_0-8da4w.pt]
recipe_checkpoint: null
output_dir: <your quantized model checkpoint dir>
model_type: LLAMA3
...
# EleutherAI specific eval args
tasks: ["hellaswag", "wikitext"]
limit: null
max_seq_length: 8192
batch_size: 8
quantizer:
_component_: torchtune.training.quantization.Int8DynActInt4WeightQuantizer
groupsize: 256
注意
由于我们传入的是量化模型,请务必使用相应的训练后量化器而不是 QAT 量化器。例如,如果您在微调期间使用了 Int8DynActInt4WeightQATQuantizer,则在此步骤中应指定 Int8DynActInt4WeightQuantizer。有关支持的量化器完整列表,请参阅量化 Recipe。
现在运行评估 Recipe
tune run eleuther_eval --config my_eleuther_evaluation.yaml
结果应该看起来像这样
# QAT quantized model evaluation results (int8 activations + int4 weights)
| Tasks |Version|Filter|n-shot| Metric |Value | |Stderr|
|---------|------:|------|-----:|---------------|-----:|---|------|
|wikitext | 2|none | 0|word_perplexity|9.9148|± |N/A |
| | |none | 0|byte_perplexity|1.5357|± |N/A |
| | |none | 0|bits_per_byte |0.6189|± |N/A |
|hellaswag| 1|none | 0|acc |0.5687|± |0.0049|
| | |none | 0|acc_norm |0.7536|± |0.0043|
将这些结果与不使用 QAT 进行微调的模型进行比较,我们可以看到,与 PTQ 相比,QAT 能够恢复原始未量化模型中量化退化的大部分。例如,与原始未量化模型相比,hellaswag 任务中的归一化准确率使用 PTQ 下降了 2.20%,而使用 QAT 仅下降了 0.74%。类似地,wikitext 任务中的词语困惑度使用 PTQ 增加了 2.048,而使用 QAT 仅增加了 1.190(越低越好)。
# PTQ quantized model evaluation results (int8 activations + int4 weights)
| Tasks |Version|Filter|n-shot| Metric | Value | |Stderr|
|---------|------:|------|-----:|---------------|------:|---|------|
|wikitext | 2|none | 0|word_perplexity|10.7735|± |N/A |
| | |none | 0|byte_perplexity| 1.5598|± |N/A |
| | |none | 0|bits_per_byte | 0.6413|± |N/A |
|hellaswag| 1|none | 0|acc | 0.5481|± |0.0050|
| | |none | 0|acc_norm | 0.7390|± |0.0044|
# Float model evaluation results (bfloat16)
| Tasks |Version|Filter|n-shot| Metric |Value | |Stderr|
|---------|------:|------|-----:|---------------|-----:|---|------|
|wikitext | 2|none | 0|word_perplexity|8.7251|± |N/A |
| | |none | 0|byte_perplexity|1.4994|± |N/A |
| | |none | 0|bits_per_byte |0.5844|± |N/A |
|hellaswag| 1|none | 0|acc |0.5740|± |0.0049|
| | |none | 0|acc_norm |0.7610|± |0.0043|
因此,QAT 流程生成的量化模型性能优于训练后量化模型。重要的是,在这两种流程中,量化模型结构是相同的,因此模型大小、内存使用情况以及所有其他性能特征也相同。
请注意,尽管权重被量化为 int4,但 QAT 和 PTQ 流程的量化模型大小均为 8.187 GB,而原始浮点模型为 14.958 GB。这是因为该量化器使用 int8 来表示权重,因为 PyTorch 不支持原生 int4 数据类型。一种更有效的表示方法是打包 int4 权重,这将使量化模型大小减半。这是 Int4WeightOnlyQuantizer 的作用,相应的 QAT 量化器将在未来添加。
将 QAT 模型降低到设备上(可选)¶
量化模型的一个重要动机是能够在资源受限的环境中运行它。您可以按照这些说明,使用 executorch 将您的 QAT Llama3 模型进一步降低到边缘设备,例如智能手机。例如,以下命令将模型降低到 XNNPACK 后端
python -m examples.models.llama2.export_llama --checkpoint <your QAT checkpoint> -p <params.json> -kv --use_sdpa_with_kv_cache -X -qmode 8da4w --group_size 256 -d fp32 --metadata '{"get_bos_id":128000, "get_eos_id":128001}' --embedding-quantize 4,32 --output_name="llama3_8da4w.pte"
这会得到一个更小的量化模型,大小为 3.881 GB。在 OnePlus 12 智能手机上进行基准测试时,该模型也达到了与训练后量化模型相同的推理和生成速度。这是因为两种流程中的模型结构是相同的
QAT |
PTQ |
|
|---|---|---|
量化模型大小 |
3.881 GB |
3.881 GB |
推理速度 |
9.709 tok/s |
9.815 tok/s |
生成速度 |
11.316 tok/s |
11.364 tok/s |
