⚠️ 通知:有限维护¶
该项目不再积极维护。现有版本仍然可用,但没有计划进行更新、错误修复、新功能开发或安全补丁。用户应注意,漏洞可能不会被解决。
使用 Torch Compiled RAG 在 AWS Graviton 上增强 LLM 服务¶
之前,已经演示了如何使用 TorchServe 部署 Llama。仅部署 LLM 可能存在一些限制,例如缺乏最新信息和有限的领域特定知识。检索增强生成 (RAG) 是一种通过提供最新相关信息的上下文来增强 LLM 准确性和可靠性的技术。这篇博文阐述了如何在基于微服务架构中实现 RAG 和 LLM 的协同工作,从而增强可伸缩性并加快开发。此外,通过在 AWS Graviton 上使用基于 CPU 的 RAG,客户可以高效地利用计算资源,最终节省成本。
问题¶
考虑用户查询服务 Llama 3 (Llama3-8b-instruct) 的 TorchServe 端点的简单设计,如图 1 所示。部署此端点的说明可以在此链接中找到。该模型部署在 NVIDIA GPU (A10Gx4) 上,未进行量化,可在 AWS 上作为 g5.12xlarge 实例使用。
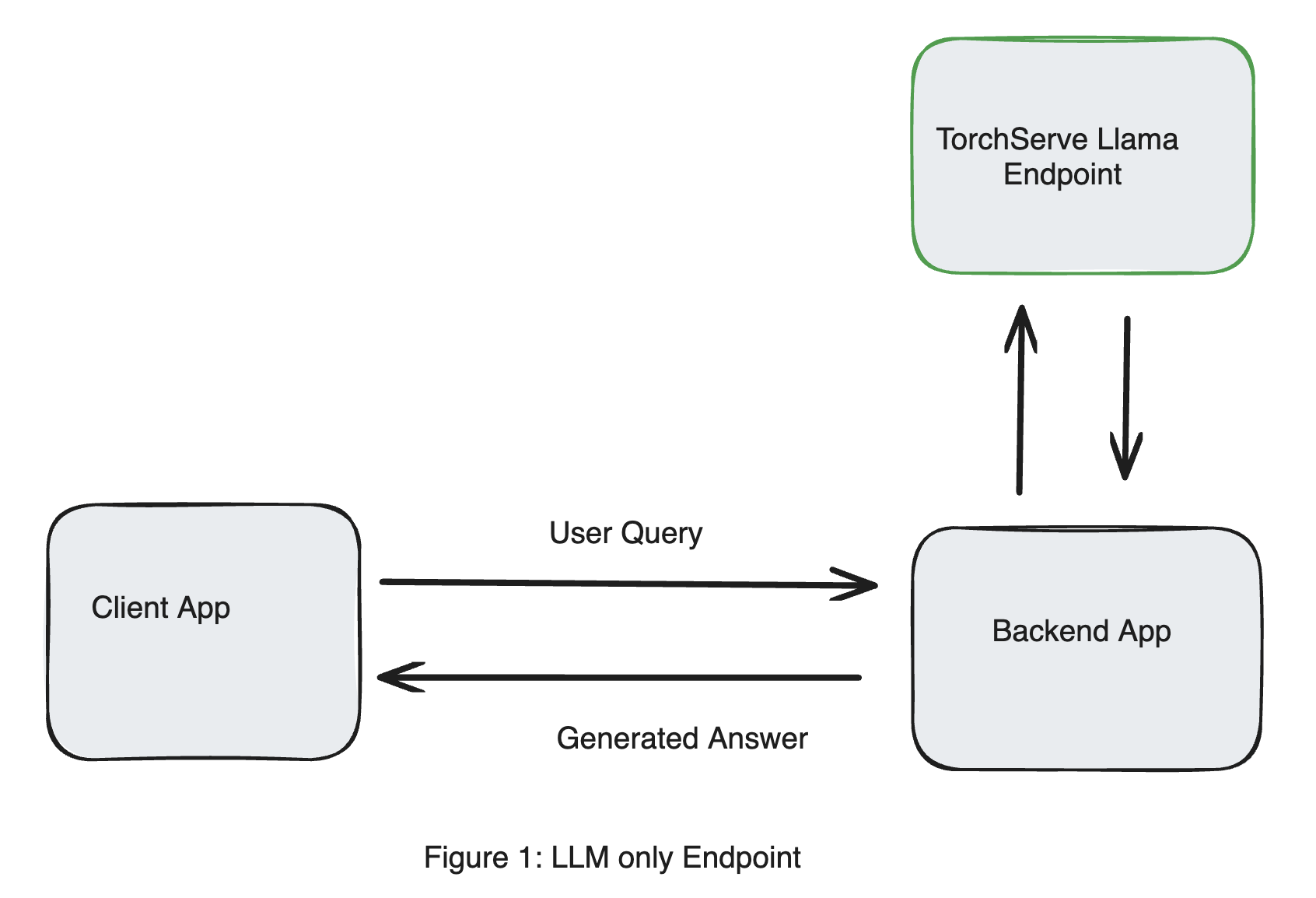
假设我们想了解 Llama 3 有什么新内容,我们将以下查询发送到 TorchServe Llama 端点。
Question: What's new with Llama 3.1?
模型返回的响应谈论的是一个名为 Llama 3.1 的数据可视化工具,这与我们期望的不符。
Answer: (Updated)
We've been busy bees in the Llama office, and we're excited to share the latest updates with you!
Llama 3.1 brings a bunch of new features and improvements to make your workflow even smoother and more efficient. Here are some of the highlights:
**New Features:**
1. **Customizable Columns**: You can now customize the columns in your Llama tables to fit your specific needs. This includes adding, removing, and rearranging columns, as well as setting default values for certain columns.
2. **Advanced Filtering**: Llama 3.1 introduces advanced filtering capabilities, allowing you to filter your data using a variety of conditions, such as date ranges, text matches, and more.
3. **Conditional Formatting**: You can now apply conditional formatting to your data, making it easier to visualize and analyze your results.
4. **Improved Data Import**: We've streamlined the data import process, making it easier to import data from various sources, including CSV
检索增强生成 (Retrieval Augmented Generation)¶
大型语言模型 (LLM),例如 Llama,擅长执行许多复杂的文本生成任务。然而,当将 LLM 用于特定领域时,它们确实存在一些限制,例如:
过时的信息:该领域可能存在模型未知的新进展,因为模型是在较早的日期训练的(也称为知识截止日期)。
缺乏特定领域的知识:当将 LLM 用于特定领域任务时,LLM 可能会给出不准确的答案,因为领域特定知识可能不容易获得。
检索增强生成 (RAG) 是一种用于解决这些限制的技术。RAG 通过根据查询提供最新相关信息来增强 LLM 的准确性。RAG 实现此目标的方法是将数据源分割成指定大小的块,对这些块进行索引,并根据查询检索相关块。获得的信息用作上下文,以增强发送到 LLM 的查询。
LangChain 是一个用于构建使用 RAG 的 LLM 应用程序的流行框架。
虽然 LLM 推理需要昂贵的 ML 加速器,但 RAG 端点可以部署在经济实惠的 CPU 上,同时仍能满足用例的延迟要求。此外,将 RAG 端点卸载到 CPU 可以实现微服务架构,从而解耦 LLM 和业务基础设施,并独立扩展它们。在下面的章节中,我们将演示如何在基于 linux-aarch64 的 AWS Graviton 上部署 RAG。此外,我们还将展示如何使用 torch.compile 从 RAG 端点获得更高的吞吐量。基本的 RAG 工作流程分为 2 个步骤:
索引¶
本示例中提供的上下文是一个网络URL。我们加载 URL 中的内容,并递归包含子页面。文档被分割成较小的块以进行高效处理。这些块使用嵌入模型进行编码,并存储在向量数据库中,从而实现高效的搜索和检索。我们在嵌入模型上使用 torch.compile 以加速推理。您可以在此处阅读更多关于使用 torch.compile 和 AWS Graviton 的信息
from bs4 import BeautifulSoup as Soup
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_community.vectorstores import FAISS
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders.recursive_url_loader import RecursiveUrlLoader
import torch
# Enable AWS Graviton specific torch.compile optimizations
import torch._inductor.config as config
config.cpp.weight_prepack=True
config.freezing=True
class CustomEmbedding(HuggingFaceEmbeddings):
tokenizer: Any
def __init__(self, tokenizer: Any, **kwargs: Any):
"""Initialize the sentence_transformer."""
super().__init__(**kwargs)
# Load model from HuggingFace Hub
self.tokenizer = tokenizer
self.client = AutoModel.from_pretrained('sentence-transformers/all-mpnet-base-v2')
self.client = torch.compile(self.client)
class Config:
arbitrary_types_allowed = True
def embed_documents(self, texts: List[str]) -> List[List[float]]:
"""Compute doc embeddings using a HuggingFace transformer model.
Args:
texts: The list of texts to embed.
Returns:
List of embeddings, one for each text.
"""
import sentence_transformers
texts = list(map(lambda x: x.replace("\n", " "), texts))
# Tokenize sentences
encoded_input = self.tokenizer(texts, padding=True, truncation=True, return_tensors='pt')
embeddings = self.client(
**encoded_input
)
embeddings = embeddings.pooler_output.detach().numpy()
return embeddings.tolist()
# 1. Load the url and its child pages
url="https://hugging-face.cn/blog/llama3"
loader = RecursiveUrlLoader(
url=url, max_depth=3, extractor=lambda x: Soup(x, "html.parser").text
)
docs = loader.load()
# 2. Split the document into chunks with a specified chunk size
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
all_splits = text_splitter.split_documents(docs)
# 3. Store the document into a vector store with a specific embedding model
tokenizer = AutoTokenizer.from_pretrained('sentence-transformers/all-mpnet-base-v2')
model = CustomEmbedding(tokenizer)
vectorstore = FAISS.from_documents(all_splits, model)
检索¶
对于用户发送的每个查询,我们在向量数据库中执行查询的相似性搜索,并获取 N(此处 N=5)个最接近的文档块。
docs = vectorstore.similarity_search(query, k=5)
提示工程 (Prompt Engineering)¶
典型的使用 LLM 进行 RAG 的实现使用 LangChain 将 RAG 和 LLM 流水线连接起来,并在链上调用 invoke 方法进行查询。
已发布的 Llama 端点示例与 TorchServe 期望文本提示作为输入,并使用 HuggingFace API 处理查询。为了使 RAG 设计兼容,我们需要从 RAG 端点返回一个文本提示。
本节描述了我们如何对 Llama 端点期望的提示进行工程化,包括相关上下文。在底层,LangChain 为 Llama 提供了一个 PromptTemplate。通过执行上述代码并带有以下调试语句,我们可以确定发送到 Llama 的提示。
import langchain
langchain.debug = True
我们从检索部分返回的文档中提取文本,并将最终的提示工程化为发送给 Llama 的格式如下:
from langchain.prompts import PromptTemplate
from langchain_core.prompts import format_document
question="What's new with Llama 3?"
doc_prompt = PromptTemplate.from_template("{page_content}")
context = ""
for doc in docs:
context += f"\n{format_document(doc, doc_prompt)}\n"
prompt = f"Use the following pieces of context to answer the question at the end. If you don't know the answer, just say that you don't know, don't try to make up an answer."\
f"\n\n{context}\n\nQuestion: {question}"\
f"\nHelpful Answer:"
AWS Graviton 特定优化¶
为了利用 AWS Graviton 在 RAG 上的性能优化,我们可以设置以下优化;有关这些优化的详细信息在这篇博文中提到。还有一个教程讨论了这些优化
export TORCH_MKLDNN_MATMUL_MIN_DIM=1024
export LRU_CACHE_CAPACITY=1024
export THP_MEM_ALLOC_ENABLE=1
export DNNL_DEFAULT_FPMATH_MODE=BF16
为了准确衡量使用 torch.compile 相较于 PyTorch eager 的性能提升,我们还设置了
export OMP_NUM_THREADS=1
部署 RAG¶
虽然 TorchServe 在同一计算实例上提供多模型端点支持,但我们将 RAG 端点部署在 AWS Graviton 上。由于 RAG 的计算密集度不高,我们可以使用 CPU 实例进行部署以提供成本效益高的解决方案。
要使用 TorchServe 部署 RAG,我们需要以下文件:
requirements.txt
langchain
Langchain_community
sentence-transformers
faiss-cpu
bs4
这可以与 config.properties 中的 install_py_dep_per_model=true 一起使用,以动态安装所需的库。
rag-config.yaml
我们在 rag-config.yaml 中传递用于索引和检索的参数,该文件用于创建 MAR 文件。通过使这些参数可配置,我们可以通过使用不同的 yaml 文件为不同任务创建多个 RAG 端点。
# TorchServe frontend parameters
minWorkers: 1
maxWorkers: 1
responseTimeout: 120
handler:
url_to_scrape: "https://hugging-face.cn/blog/llama3"
chunk_size: 1000
chunk_overlap: 0
model_path: "model/models--sentence-transformers--all-mpnet-base-v2/snapshots/84f2bcc00d77236f9e89c8a360a00fb1139bf47d"
rag_handler.py
我们定义一个 handler 文件,其中包含一个派生自 BaseHandler 的类。此类需要定义四个方法:initialize、preprocess、inference 和 postprocess。索引部分在 initialize 方法中定义。检索部分在 inference 方法中,提示工程部分在 postprocess 方法中。我们使用定时函数来确定处理每个方法所需的时间。
import torch
import transformers
from bs4 import BeautifulSoup as Soup
from hf_custom_embeddings import CustomEmbedding
from langchain.prompts import PromptTemplate
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders.recursive_url_loader import RecursiveUrlLoader
from langchain_community.vectorstores import FAISS
from langchain_core.prompts import format_document
from ts.torch_handler.base_handler import BaseHandler
class RAGHandler(BaseHandler):
"""
RAG handler class retrieving documents from a url, encoding & storing in a vector database.
For a given query, it returns the closest matching documents.
"""
def __init__(self):
super(RAGHandler, self).__init__()
self.vectorstore = None
self.initialized = False
self.N = 5
@torch.inference_mode
def initialize(self, ctx):
url = ctx.model_yaml_config["handler"]["url_to_scrape"]
chunk_size = ctx.model_yaml_config["handler"]["chunk_size"]
chunk_overlap = ctx.model_yaml_config["handler"]["chunk_overlap"]
model_path = ctx.model_yaml_config["handler"]["model_path"]
loader = RecursiveUrlLoader(
url=url, max_depth=3, extractor=lambda x: Soup(x, "html.parser").text
)
docs = loader.load()
# Split the document into chunks with a specified chunk size
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size, chunk_overlap=chunk_overlap
)
all_splits = text_splitter.split_documents(docs)
# Store the document into a vector store with a specific embedding model
self.vectorstore = FAISS.from_documents(
all_splits, CustomEmbedding(model_path=model_path)
)
def preprocess(self, requests):
assert len(requests) == 1, "Expecting batch_size = 1"
inputs = []
for request in requests:
input_text = request.get("data") or request.get("body")
if isinstance(input_text, (bytes, bytearray)):
input_text = input_text.decode("utf-8")
inputs.append(input_text)
return inputs[0]
@torch.inference_mode
def inference(self, data, *args, **kwargs):
searchDocs = self.vectorstore.similarity_search(data, k=self.N)
return (searchDocs, data)
def postprocess(self, data):
docs, question = data[0], data[1]
doc_prompt = PromptTemplate.from_template("{page_content}")
context = ""
for doc in docs:
context += f"\n{format_document(doc, doc_prompt)}\n"
prompt = (
f"Use the following pieces of context to answer the question at the end. If you don't know the answer, just say that you don't know, don't try to make up an answer."
f"\n\n{context}\n\nQuestion: {question}"
f"\nHelpful Answer:"
)
return [prompt]
性能基准测试¶
我们使用 ab 工具来衡量 RAG 端点的性能
python benchmarks/auto_benchmark.py --input /home/ubuntu/serve/examples/usecases/RAG_based_LLM_serving
benchmark_profile.yaml --skip true
我们重复运行,结合 OMP_NUM_THREADS 和 PyTorch Eager/torch.compile 的不同组合
结果¶
我们在 AWS EC2 m7g.4xlarge 实例上观察到以下吞吐量:

我们观察到,使用 torch.compile 使 RAG 端点的吞吐量提高了 35%。吞吐量的规模(无论是 Eager 还是 Compile)表明,在 CPU 设备上部署 RAG 与部署在 GPU 实例上的 LLM 一起使用是可行的。RAG 端点不会成为 LLM 部署中的瓶颈。
RAG + LLM 部署¶
使用基于 RAG 的 LLM 服务的端到端解决方案的系统架构如图 2 所示。
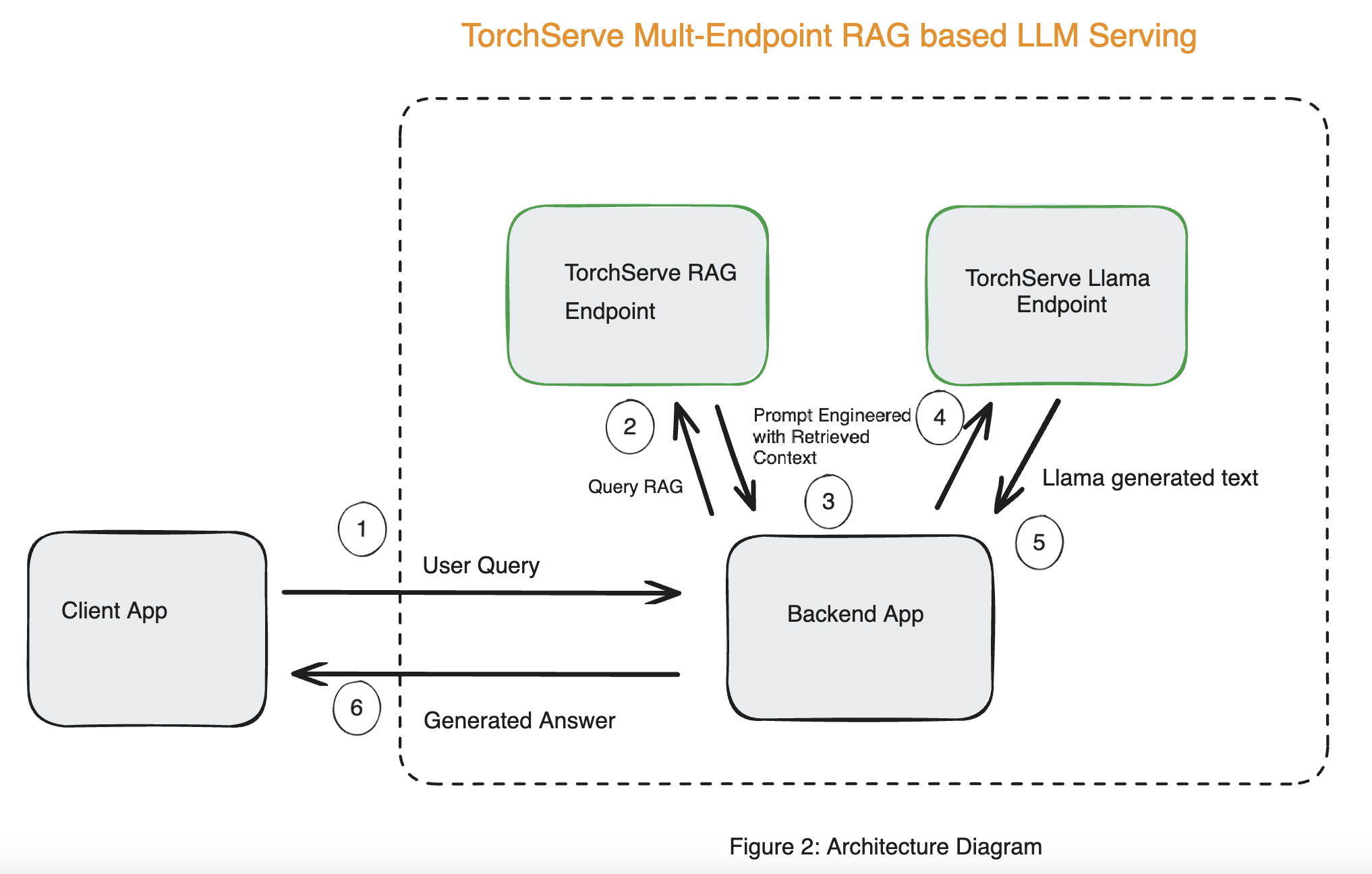
完整部署的步骤在部署指南中提到。
以下代码片段展示了如何将 RAG 端点与 Llama 端点连接起来。
import requests
prompt="What's new with Llama 3.1?"
RAG_EP = "http://<RAG Endpoint IP Address>:8080/predictions/rag"
LLAMA_EP = "http://<LLAMA Endpoint IP Address>:8080/predictions/llama3-8b-instruct"
# Get response from RAG
response = requests.post(url=RAG_EP, data=prompt)
# Get response from Llama
response = requests.post(url=LLAMA_EP, data=response.text.encode('utf-8'))
print(f"Question: {prompt}")
print(f"Answer: {response.text}")
示例输出¶
Question: What's new with Llama 3.1?
Answer: Llama 3.1 has a large context length of 128K tokens, multilingual capabilities, tool usage capabilities, a very large dense model of 405 billion parameters, and a more permissive license. It also introduces six new open LLM models based on the Llama 3 architecture, and continues to use Grouped-Query Attention (GQA) for efficient representation. The new tokenizer expands the vocabulary size to 128,256, and the 8B version of the model now uses GQA. The license allows using model outputs to improve other LLMs.
Question: What's new with Llama 2?
Answer: There is no mention of Llama 2 in the provided context. The text only discusses Llama 3.1 and its features. Therefore, it is not possible to determine what is new with Llama 2. I don't know.
结论¶
在这篇博文中,我们展示了如何使用 TorchServe 部署 RAG 端点,使用 torch.compile 提高吞吐量,并改进 Llama 端点生成的响应。使用图 2 中描述的架构,我们可以减少 LLM 的幻觉。
我们还展示了如何将 RAG 端点部署在 AWS Graviton 的 CPU 上,而 Llama 端点仍部署在 GPU 上。这种基于微服务的 RAG 解决方案高效利用计算资源,为客户带来潜在的成本节约。
