注意
跳转到末尾 下载完整的示例代码
在 Torch-TensorRT 中使用自定义内核与 TensorRT 引擎¶
我们将演示开发者如何在 Torch-TensorRT 中使用自定义内核集成到 TensorRT 引擎中。
如果 Torch-TensorRT 不知道如何在 TensorRT 中编译某些操作,它支持回退到 PyTorch 实现。然而,这会带来图中断的代价,并会降低模型的性能。解决操作符不支持的最简单方法是添加分解(参见:为 Dynamo 前端编写下层 Pass)——它将操作符定义为 Torch-TensorRT 支持的 PyTorch 操作符;或者添加转换器(参见:为 Dynamo 前端编写转换器)——它将操作符定义为 TensorRT 操作符。
在某些情况下,这两种方法都不太适用,可能是因为该操作符是标准 PyTorch 中不存在的自定义内核,或者 TensorRT 无法原生支持它。
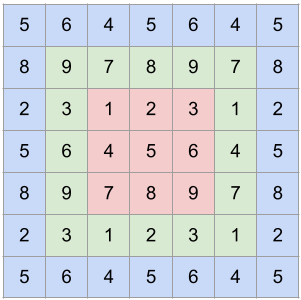
对于这些情况,可以使用 TensorRT 插件来替换 TensorRT 引擎内部的操作符,从而避免图中断带来的性能和资源开销。为了演示,考虑循环填充操作。循环填充对于深度学习中的循环卷积等操作非常有用。下图展示了原始图像(红色)一次循环填充(绿色)和两次循环填充(蓝色)的情况。
在 PyTorch 中编写自定义操作符¶
假设出于某种原因,我们想要使用循环填充的自定义实现。这里我们使用 OpenAI Triton 编写的内核来实现。
在 PyTorch 中使用自定义内核时,建议额外将其注册为 PyTorch 中的正式操作符。这既能简化其在 PyTorch 中的使用,也能更容易在 Torch-TensorRT 中处理该操作。这可以通过 C++ 库或 Python 来完成。(更多详细信息参见:C++ 中的自定义操作符 和 Python 自定义操作符)
from typing import Any, Sequence
import numpy as np
import torch
import triton
import triton.language as tl
from torch.library import custom_op
# Defining the kernel to be run on the GPU
@triton.jit # type: ignore
def circ_pad_kernel(
X: torch.Tensor,
all_pads_0: tl.int32,
all_pads_2: tl.int32,
all_pads_4: tl.int32,
all_pads_6: tl.int32,
orig_dims_0: tl.int32,
orig_dims_1: tl.int32,
orig_dims_2: tl.int32,
orig_dims_3: tl.int32,
Y: torch.Tensor,
Y_shape_1: tl.int32,
Y_shape_2: tl.int32,
Y_shape_3: tl.int32,
X_len: tl.int32,
Y_len: tl.int32,
BLOCK_SIZE: tl.constexpr,
) -> None:
pid = tl.program_id(0)
i = pid * BLOCK_SIZE + tl.arange(0, BLOCK_SIZE)
mask_y = i < Y_len
i3 = i % Y_shape_3
i2 = (i // Y_shape_3) % Y_shape_2
i1 = (i // Y_shape_3 // Y_shape_2) % Y_shape_1
i0 = i // Y_shape_3 // Y_shape_2 // Y_shape_1
j0 = (i0 - all_pads_0 + orig_dims_0) % orig_dims_0
j1 = (i1 - all_pads_2 + orig_dims_1) % orig_dims_1
j2 = (i2 - all_pads_4 + orig_dims_2) % orig_dims_2
j3 = (i3 - all_pads_6 + orig_dims_3) % orig_dims_3
load_idx = (
orig_dims_3 * orig_dims_2 * orig_dims_1 * j0
+ orig_dims_3 * orig_dims_2 * j1
+ orig_dims_3 * j2
+ j3
)
mask_x = load_idx < X_len
x = tl.load(X + load_idx, mask=mask_x)
tl.store(Y + i, x, mask=mask_y)
# The launch code wrapped to expose it as a custom operator in our namespace
@custom_op("torchtrt_ex::triton_circular_pad", mutates_args=()) # type: ignore[misc]
def triton_circular_pad(x: torch.Tensor, padding: Sequence[int]) -> torch.Tensor:
out_dims = np.ones(len(x.shape), dtype=np.int32)
for i in range(np.size(padding) // 2):
out_dims[len(out_dims) - i - 1] = (
x.shape[len(out_dims) - i - 1] + padding[i * 2] + padding[i * 2 + 1]
)
y = torch.empty(tuple(out_dims.tolist()), device=x.device)
N = len(x.shape)
all_pads = np.zeros((N * 2,), dtype=np.int32)
orig_dims = np.array(x.shape, dtype=np.int32)
out_dims = np.array(x.shape, dtype=np.int32)
for i in range(len(padding) // 2):
out_dims[N - i - 1] += padding[i * 2] + padding[i * 2 + 1]
all_pads[N * 2 - 2 * i - 2] = padding[i * 2]
all_pads[N * 2 - 2 * i - 1] = padding[i * 2 + 1]
blockSize = 256
numBlocks = (int((np.prod(out_dims) + blockSize - 1) // blockSize),)
circ_pad_kernel[numBlocks](
x,
all_pads[0],
all_pads[2],
all_pads[4],
all_pads[6],
orig_dims[0],
orig_dims[1],
orig_dims[2],
orig_dims[3],
y,
out_dims[1],
out_dims[2],
out_dims[3],
int(np.prod(orig_dims)),
int(np.prod(out_dims)),
BLOCK_SIZE=256,
)
return y
以上就是创建 PyTorch 自定义操作符所需的全部步骤。我们现在可以直接将其作为 torch.ops.torchtrt_ex.triton_circular_pad 来调用。
测试我们的自定义操作符¶
原生 PyTorch 实现
ex_input = torch.arange(9, dtype=torch.float).reshape(1, 1, 3, 3).to("cuda")
padding = (1, 1, 2, 0)
torch.nn.functional.pad(ex_input, padding, "circular")
tensor([[[[5., 3., 4., 5., 3.],
[8., 6., 7., 8., 6.],
[2., 0., 1., 2., 0.],
[5., 3., 4., 5., 3.],
[8., 6., 7., 8., 6.]]]], device='cuda:0')
我们的自定义实现
torch.ops.torchtrt_ex.triton_circular_pad(ex_input, padding)
tensor([[[[5., 3., 4., 5., 3.],
[8., 6., 7., 8., 6.],
[2., 0., 1., 2., 0.],
[5., 3., 4., 5., 3.],
[8., 6., 7., 8., 6.]]]], device='cuda:0')
我们已经定义了在 PyTorch 中开始使用自定义操作符所需的最少内容,但为了进一步让 Dynamo 能够跟踪此操作符(这是 Torch-TensorRT 支持的前提),我们需要定义该操作符的“伪张量”(Fake Tensor)实现。此函数根据原生 PyTorch 操作符定义了我们的内核对输入张量的影响。它允许 Dynamo 计算张量属性(如大小、步长、设备等),而无需使用真实数据(更多信息参见此处)。在我们的例子中,我们可以直接使用原生的循环填充操作作为我们的 FakeTensor 实现。
@torch.library.register_fake("torchtrt_ex::triton_circular_pad") # type: ignore[misc]
def _(x: torch.Tensor, padding: Sequence[int]) -> torch.Tensor:
return torch.nn.functional.pad(x, padding, "circular")
# Additionally one may want to define an autograd implementation for the backwards pass to round out the custom op implementation but that is beyond the scope of this tutorial (see https://pytorch.ac.cn/docs/main/library.html#torch.library.register_autograd for more)
在模型中使用自定义操作符¶
我们现在可以使用自定义操作符创建模型了。这是一个使用原生支持的操作符(卷积)和我们的自定义操作符的小例子。
from typing import Sequence
from torch import nn
class MyModel(nn.Module): # type: ignore[misc]
def __init__(self, padding: Sequence[int]):
super().__init__()
self.padding = padding
self.conv = nn.Conv2d(1, 5, kernel_size=3)
def forward(self, x: torch.Tensor) -> torch.Tensor:
padded_x = torch.ops.torchtrt_ex.triton_circular_pad(x, self.padding)
y = self.conv(padded_x)
return y
my_model = MyModel((1, 1, 2, 0)).to("cuda")
my_model(ex_input)
tensor([[[[-0.2604, -0.4232, -0.3041],
[-3.0833, -3.2461, -3.1270],
[-0.2450, -0.4079, -0.2887]],
[[ 0.2828, -0.0373, 1.0332],
[-2.3143, -2.6344, -1.5638],
[-1.1867, -1.5068, -0.4363]],
[[ 1.7937, 1.3488, 2.1350],
[ 0.7966, 0.3517, 1.1379],
[ 3.5537, 3.1088, 3.8950]],
[[-1.0550, -0.6163, -1.0109],
[ 0.5245, 0.9632, 0.5686],
[ 0.3775, 0.8162, 0.4216]],
[[-0.4311, -0.1649, -1.2091],
[-4.3668, -4.1006, -5.1447],
[-5.0352, -4.7689, -5.8131]]]], device='cuda:0')
如果我们尝试使用 Torch-TensorRT 编译此模型,我们可以看到(截至 Torch-TensorRT 2.4.0 版本)创建了多个子图,分别在 PyTorch 中运行自定义操作符,在 TensorRT 中运行卷积。
import torch_tensorrt as torchtrt
torchtrt.compile(
my_model,
inputs=[ex_input],
dryrun=True, # Check the support of the model without having to build the engines
min_block_size=1,
)
GraphModule(
(_run_on_gpu_0): GraphModule()
(_run_on_acc_1): GraphModule(
(conv): Module()
)
)
++++++++++++++ Dry-Run Results for Graph +++++++++++++++++
The graph consists of 2 Total Operators, of which 1 operators are supported, 50.0% coverage
The following ops are currently unsupported or excluded from conversion, and are listed with their op-count in the graph:
torch.ops.torchtrt_ex.triton_circular_pad.default: 1
The following nodes are currently set to run in Torch:
Node: torch.ops.torchtrt_ex.triton_circular_pad.default, with layer location: __/triton_circular_pad
Note: Some of the above nodes may be supported, but were not included in a TRT graph by the partitioner
Compiled with: CompilationSettings(enabled_precisions={<dtype.f32: 7>}, debug=False, workspace_size=0, min_block_size=1, torch_executed_ops=set(), pass_through_build_failures=False, max_aux_streams=None, version_compatible=False, optimization_level=None, use_python_runtime=False, truncate_double=False, use_fast_partitioner=True, enable_experimental_decompositions=False, device=Device(type=DeviceType.GPU, gpu_id=0), require_full_compilation=False, disable_tf32=False, sparse_weights=False, refit=False, engine_capability=<EngineCapability.STANDARD: 1>, num_avg_timing_iters=1, dla_sram_size=1048576, dla_local_dram_size=1073741824, dla_global_dram_size=536870912, dryrun=True, hardware_compatible=False)
Graph Structure:
Inputs: List[Tensor: (1, 1, 3, 3)@float32]
...
TRT Engine #1 - Submodule name: _run_on_acc_1
Engine Inputs: List[Tensor: (1, 1, 5, 5)@float32]
Number of Operators in Engine: 1
Engine Outputs: Tensor: (1, 5, 3, 3)@float32
...
Outputs: List[Tensor: (1, 5, 3, 3)@float32]
--------- Aggregate Stats ---------
Average Number of Operators per TRT Engine: 1.0
Most Operators in a TRT Engine: 1
********** Recommendations **********
- For minimal graph segmentation, select min_block_size=1 which would generate 1 TRT engine(s)
- The current level of graph segmentation is equivalent to selecting min_block_size=1 which generates 1 TRT engine(s)
我们看到将有两个子图,一个通过 PyTorch 运行我们的自定义操作符,一个通过 TensorRT 运行卷积。这种图中断将是该模型延迟的重要组成部分。
封装自定义内核以在 TensorRT 中使用¶
为了解决这种图中断,第一步是使我们的内核实现可在 TensorRT 中使用。同样,这可以在 C++ 或 Python 中完成。有关如何实现 TensorRT 插件的具体细节,请参阅此处。从高层次上看,与 PyTorch 类似,您需要定义系统来处理操作符的设置、抽象地计算操作符的影响、序列化操作符以及在引擎中调用操作符实现的实际机制。
import pickle as pkl
from typing import Any, List, Optional, Self
import cupy as cp # Needed to work around API gaps in PyTorch to build torch.Tensors around preallocated CUDA memory
import numpy as np
import tensorrt as trt
class CircularPaddingPlugin(trt.IPluginV2DynamicExt): # type: ignore[misc]
def __init__(
self, field_collection: Optional[List[trt.PluginFieldCollection]] = None
):
super().__init__()
self.pads = []
self.X_shape: List[int] = []
self.num_outputs = 1
self.plugin_namespace = ""
self.plugin_type = "CircularPaddingPlugin"
self.plugin_version = "1"
if field_collection is not None:
assert field_collection[0].name == "pads"
self.pads = field_collection[0].data
def get_output_datatype(
self, index: int, input_types: List[trt.DataType]
) -> trt.DataType:
return input_types[0]
def get_output_dimensions(
self,
output_index: int,
inputs: List[trt.DimsExprs],
exprBuilder: trt.IExprBuilder,
) -> trt.DimsExprs:
output_dims = trt.DimsExprs(inputs[0])
for i in range(np.size(self.pads) // 2):
output_dims[len(output_dims) - i - 1] = exprBuilder.operation(
trt.DimensionOperation.SUM,
inputs[0][len(output_dims) - i - 1],
exprBuilder.constant(self.pads[i * 2] + self.pads[i * 2 + 1]),
)
return output_dims
def configure_plugin(
self,
inp: List[trt.DynamicPluginTensorDesc],
out: List[trt.DynamicPluginTensorDesc],
) -> None:
X_dims = inp[0].desc.dims
self.X_shape = np.zeros((len(X_dims),))
for i in range(len(X_dims)):
self.X_shape[i] = X_dims[i]
def serialize(self) -> bytes:
return pkl.dumps({"pads": self.pads})
def supports_format_combination(
self, pos: int, in_out: List[trt.PluginTensorDesc], num_inputs: int
) -> bool:
assert num_inputs == 1
assert pos < len(in_out)
desc = in_out[pos]
if desc.format != trt.TensorFormat.LINEAR:
return False
# first input should be float16 or float32
if pos == 0:
return bool(
(desc.type == trt.DataType.FLOAT) or desc.type == (trt.DataType.HALF)
)
# output should have the same type as the input
if pos == 1:
return bool((in_out[0].type == desc.type))
return False
def enqueue(
self,
input_desc: List[trt.PluginTensorDesc],
output_desc: List[trt.PluginTensorDesc],
inputs: List[int],
outputs: List[int],
workspace: int,
stream: int,
) -> None:
# Host code is slightly different as this will be run as part of the TRT execution
in_dtype = torchtrt.dtype.try_from(input_desc[0].type).to(np.dtype)
a_mem = cp.cuda.UnownedMemory(
inputs[0], np.prod(input_desc[0].dims) * cp.dtype(in_dtype).itemsize, self
)
c_mem = cp.cuda.UnownedMemory(
outputs[0],
np.prod(output_desc[0].dims) * cp.dtype(in_dtype).itemsize,
self,
)
a_ptr = cp.cuda.MemoryPointer(a_mem, 0)
c_ptr = cp.cuda.MemoryPointer(c_mem, 0)
a_d = cp.ndarray((np.prod(input_desc[0].dims)), dtype=in_dtype, memptr=a_ptr)
c_d = cp.ndarray((np.prod(output_desc[0].dims)), dtype=in_dtype, memptr=c_ptr)
a_t = torch.as_tensor(a_d, device="cuda")
c_t = torch.as_tensor(c_d, device="cuda")
N = len(self.X_shape)
all_pads = np.zeros((N * 2,), dtype=np.int32)
orig_dims = np.array(self.X_shape, dtype=np.int32)
out_dims = np.array(self.X_shape, dtype=np.int32)
for i in range(np.size(self.pads) // 2):
out_dims[N - i - 1] += self.pads[i * 2] + self.pads[i * 2 + 1]
all_pads[N * 2 - 2 * i - 2] = self.pads[i * 2]
all_pads[N * 2 - 2 * i - 1] = self.pads[i * 2 + 1]
all_pads = all_pads.tolist()
orig_dims = orig_dims.tolist()
out_dims = out_dims.tolist()
blockSize = 256
numBlocks = (int((np.prod(out_dims) + blockSize - 1) // blockSize),)
# Call the same kernel implementation we use in PyTorch
circ_pad_kernel[numBlocks](
a_t,
all_pads[0],
all_pads[2],
all_pads[4],
all_pads[6],
orig_dims[0],
orig_dims[1],
orig_dims[2],
orig_dims[3],
c_t,
out_dims[1],
out_dims[2],
out_dims[3],
int(np.prod(orig_dims)),
int(np.prod(out_dims)),
BLOCK_SIZE=256,
)
def clone(self) -> Self:
cloned_plugin = CircularPaddingPlugin()
cloned_plugin.__dict__.update(self.__dict__)
return cloned_plugin
class CircularPaddingPluginCreator(trt.IPluginCreator): # type: ignore[misc]
def __init__(self):
super().__init__()
self.name = "CircularPaddingPlugin"
self.plugin_namespace = ""
self.plugin_version = "1"
self.field_names = trt.PluginFieldCollection(
[trt.PluginField("pads", np.array([]), trt.PluginFieldType.INT32)]
)
def create_plugin(
self, name: str, field_collection: trt.PluginFieldCollection_
) -> CircularPaddingPlugin:
return CircularPaddingPlugin(field_collection)
def deserialize_plugin(self, name: str, data: bytes) -> CircularPaddingPlugin:
pads_dict = pkl.loads(data)
print(pads_dict)
deserialized = CircularPaddingPlugin()
deserialized.__dict__.update(pads_dict)
print(deserialized.pads)
return deserialized
# Register the plugin creator in the TensorRT Plugin Registry
TRT_PLUGIN_REGISTRY = trt.get_plugin_registry()
TRT_PLUGIN_REGISTRY.register_creator(CircularPaddingPluginCreator(), "") # type: ignore[no-untyped-call]
使用 Torch-TensorRT 插入内核¶
现在有了我们的 TensorRT 插件,我们可以创建一个转换器,以便 Torch-TensorRT 知道将我们的插件插入到自定义循环填充操作符的位置。有关编写转换器的更多信息可以在此处找到。
from typing import Dict, Tuple
from torch.fx.node import Argument, Target
from torch_tensorrt.dynamo.conversion import (
ConversionContext,
dynamo_tensorrt_converter,
)
from torch_tensorrt.dynamo.conversion.converter_utils import get_trt_tensor
from torch_tensorrt.fx.converters.converter_utils import set_layer_name
@dynamo_tensorrt_converter(
torch.ops.torchtrt_ex.triton_circular_pad.default
) # type: ignore
# Recall the schema defined above:
# torch.ops.torchtrt_ex.triton_circular_pad.default(Tensor x, IntList padding) -> Tensor
def circular_padding_converter(
ctx: ConversionContext,
target: Target,
args: Tuple[Argument, ...],
kwargs: Dict[str, Argument],
name: str,
):
# How to retrieve a plugin if it is defined elsewhere (e.g. linked library)
plugin_registry = trt.get_plugin_registry()
plugin_creator = plugin_registry.get_plugin_creator(
type="CircularPaddingPlugin", version="1", plugin_namespace=""
)
assert plugin_creator, f"Unable to find CircularPaddingPlugin creator"
# Pass configurations to the plugin implementation
field_configs = trt.PluginFieldCollection(
[
trt.PluginField(
"pads",
np.array(
args[1], dtype=np.int32
), # Arg 1 of `torch.ops.torchtrt_ex.triton_circular_pad` is the int list containing the padding settings. Note: the dtype matters as you are eventually passing this as a c-like buffer
trt.PluginFieldType.INT32,
),
]
)
plugin = plugin_creator.create_plugin(name=name, field_collection=field_configs)
assert plugin, "Unable to create CircularPaddingPlugin"
input_tensor = args[
0
] # Arg 0 `torch.ops.torchtrt_ex.triton_circular_pad` is the input tensor
if not isinstance(input_tensor, trt.ITensor):
# Freeze input tensor if not TensorRT Tensor already
input_tensor = get_trt_tensor(ctx, input_tensor, f"{name}_input")
layer = ctx.net.add_plugin_v2(
[input_tensor], plugin
) # Add the plugin to the network being constructed
layer.name = f"circular_padding_plugin-{name}"
return layer.get_output(0)
最后,我们现在可以完全编译我们的模型了
trt_model = torchtrt.compile(
my_model,
inputs=[ex_input],
min_block_size=1,
)
GraphModule(
(_run_on_acc_0): TorchTensorRTModule()
)
+++++++++++++++ Dry-Run Results for Graph ++++++++++++++++
The graph consists of 2 Total Operators, of which 2 operators are supported, 100.0% coverage
Compiled with: CompilationSettings(enabled_precisions={<dtype.f32: 7>}, debug=True, workspace_size=0, min_block_size=1, torch_executed_ops=set(), pass_through_build_failures=False, max_aux_streams=None, version_compatible=False, optimization_level=None, use_python_runtime=False, truncate_double=False, use_fast_partitioner=True, enable_experimental_decompositions=False, device=Device(type=DeviceType.GPU, gpu_id=0), require_full_compilation=False, disable_tf32=False, sparse_weights=False, refit=False, engine_capability=<EngineCapability.STANDARD: 1>, num_avg_timing_iters=1, dla_sram_size=1048576, dla_local_dram_size=1073741824, dla_global_dram_size=536870912, dryrun=False, hardware_compatible=False)
Graph Structure:
Inputs: List[Tensor: (1, 1, 3, 3)@float32]
...
TRT Engine #1 - Submodule name: _run_on_acc_0
Engine Inputs: List[Tensor: (1, 1, 3, 3)@float32]
Number of Operators in Engine: 2
Engine Outputs: Tensor: (1, 5, 3, 3)@float32
...
Outputs: List[Tensor: (1, 5, 3, 3)@float32]
---------- Aggregate Stats -------------
Average Number of Operators per TRT Engine: 2.0
Most Operators in a TRT Engine: 2
********** Recommendations **********
- For minimal graph segmentation, select min_block_size=2 which would generate 1 TRT engine(s)
- The current level of graph segmentation is equivalent to selecting min_block_size=2 which generates 1 TRT engine(s)
如您所见,现在只为 TensorRT 引擎创建了一个子图,其中包含了我们的自定义内核和原生卷积操作符。
print(trt_model(ex_input))
tensor([[[[-0.2604, -0.4232, -0.3041],
[-3.0833, -3.2461, -3.1270],
[-0.2450, -0.4079, -0.2887]],
[[ 0.2828, -0.0373, 1.0332],
[-2.3143, -2.6344, -1.5638],
[-1.1867, -1.5068, -0.4363]],
[[ 1.7937, 1.3488, 2.1350],
[ 0.7966, 0.3517, 1.1379],
[ 3.5537, 3.1088, 3.8950]],
[[-1.0550, -0.6163, -1.0109],
[ 0.5245, 0.9632, 0.5686],
[ 0.3775, 0.8162, 0.4216]],
[[-0.4311, -0.1649, -1.2091],
[-4.3668, -4.1006, -5.1447],
[-5.0352, -4.7689, -5.8131]]]], device='cuda:0')
我们可以验证我们的实现是否在 TensorRT 和 PyTorch 中都能正确运行
print(my_model(ex_input) - trt_model(ex_input))
tensor([[[[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]],
[[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]],
[[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]],
[[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]],
[[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]]]], device='cuda:0', grad_fn=<SubBackward0>)
脚本总运行时间: ( 0 分钟 0.000 秒)
