使用 NVIDIA MPS 运行 TorchServe¶
为了部署 ML 模型,TorchServe 在单独的进程中启动每个工作进程,从而将每个工作进程与其他工作进程隔离。每个进程创建自己的 CUDA 上下文来执行其内核并访问分配的内存。
虽然 NVIDIA GPU 在其默认设置下允许多个进程在单个设备上运行 CUDA 内核,但这会带来以下缺点
内核的执行通常是串行的
每个进程创建自己的 CUDA 上下文,这会占用额外的 GPU 内存
对于这些场景,NVIDIA 提供了多进程服务 (MPS),它
允许多个进程在同一 GPU 上共享相同的 CUDA 上下文
以并行方式运行其内核
这可能导致
在同一 GPU 上使用多个工作进程时提高性能
由于共享上下文而降低 GPU 内存使用率
为了利用 NVIDIA MPS 的优势,我们需要在启动 TorchServe 本身之前使用以下命令启动 MPS 守护进程。
sudo nvidia-smi -c 3
nvidia-cuda-mps-control -d
第一个命令启用 GPU 的独占处理模式,只允许一个进程(MPS 守护进程)使用它。第二个命令启动 MPS 守护进程本身。要关闭守护进程,我们可以执行
echo quit | nvidia-cuda-mps-control
有关 MPS 的更多详细信息,请参阅 NVIDIA 的 MPS 文档。需要注意的是,由于硬件资源有限,MPS 仅允许 48 个进程(对于 Volta GPU)连接到守护进程。添加更多客户端/工作进程(到同一 GPU)会导致失败。
基准测试¶
为了展示启用 MPS 的 TorchServe 的性能,并帮助您决定是否为您的部署启用 MPS,我们将使用有代表性的工作负载进行一些基准测试。
首先,我们希望研究在不同操作点启用 MPS 后工作进程的吞吐量如何变化。作为我们基准测试的示例工作负载,我们选择了 HuggingFace Transformers 序列分类示例。我们在 AWS 上的 g4dn.4xlarge 以及 p3.2xlarge 实例上执行基准测试。这两种实例类型每个实例都提供一个 GPU,这将导致多个工作进程被调度到同一 GPU 上。对于基准测试,我们专注于模型吞吐量,如 benchmark-ab.py 工具所衡量的那样。
首先,我们测量单个工作进程在不同批次大小下的吞吐量,因为它将向我们展示 GPU 的计算资源何时被完全占用。其次,我们测量部署两个工作进程时的吞吐量,批次大小是我们预计 GPU 仍有剩余资源可供共享的批次大小。对于每个基准测试,我们执行五次运行,并取运行结果的中位数。
我们使用以下 config.json 进行基准测试,仅根据需要覆盖工作进程数量和批次大小。
{
"url":"/home/ubuntu/serve/examples/Huggingface_Transformers/model_store/BERTSeqClassification",
"requests": 10000,
"concurrency": 600,
"input": "/home/ubuntu/serve/examples/Huggingface_Transformers/Seq_classification_artifacts/sample_text_captum_input.txt",
"workers": "1"
}
请注意,我们将并发级别设置为 600,这将确保 TorchServe 内部批次聚合将批次填充到最大批次大小。但同时,这会使延迟测量结果产生偏差,因为许多请求将等待在队列中等待处理。因此,在以下内容中我们将忽略延迟测量结果。
G4 实例¶
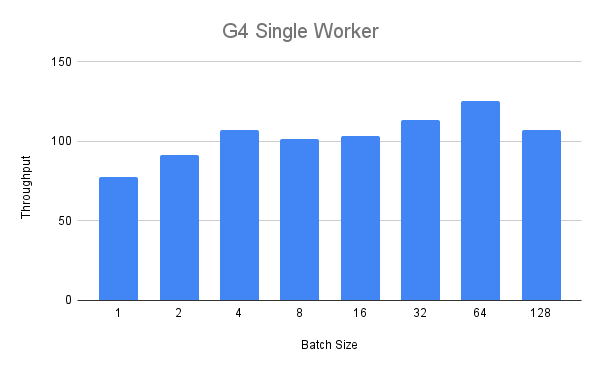
我们首先对 G4 实例执行单工作进程基准测试。在下图中,我们可以看到,在批次大小达到四之前,吞吐量随着批次大小的增加而稳定增长。
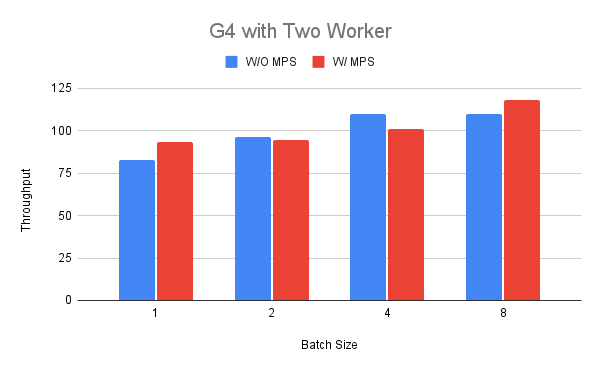
接下来,我们将工作进程数量增加到两个,以便比较启用和禁用 MPS 时的吞吐量。为了启用第二组运行的 MPS,我们首先设置 GPU 的独占处理模式,然后如上所述启动 MPS 守护进程。
根据我们之前的发现,我们选择批次大小在 1 到 8 之间。从图中我们可以看出,在批次大小为 1 和 8 的情况下,吞吐量的性能可能更好(最多 +18%),而在其他情况下则可能更差(-11%)。对该结果的一种解释可能是,当我们在其中一个工作进程中运行 BERT 模型时,G4 实例没有太多资源可以共享。
P3 实例¶
接下来,我们将使用更大的 p3.2xlarge 实例运行相同的实验。使用单个工作进程,我们得到以下吞吐量值
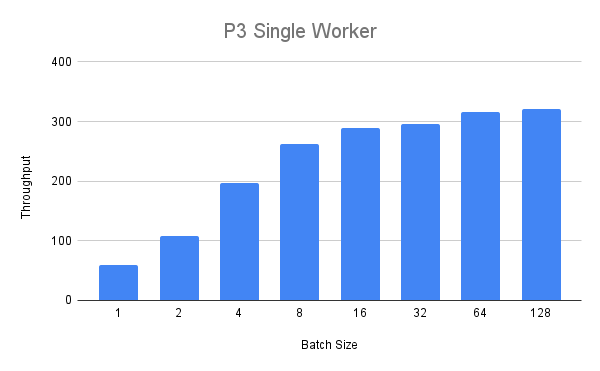
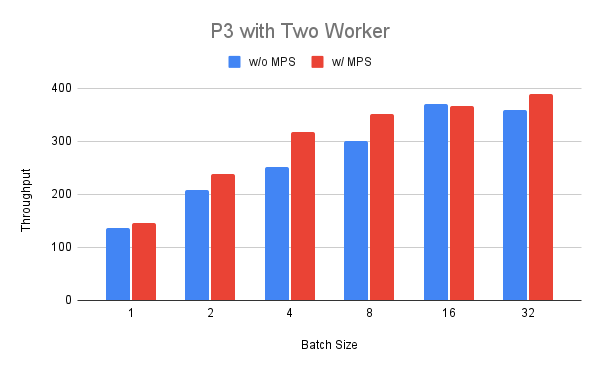
我们可以看到,吞吐量稳定增长,但对于批次大小超过八的情况,我们看到收益递减。最后,我们在 P3 实例上部署两个工作进程,并比较启用和禁用 MPS 时的运行情况。我们可以看到,对于批次大小在 1 到 32 之间的情况,启用 MPS 时吞吐量始终更高(最多 +25%),批次大小为 16 的情况除外。
总结¶
在上一节中,我们看到通过为运行相同模型的两个工作进程启用 MPS,我们得到了混合的结果。对于较小的 G4 实例,我们只在某些操作点看到了好处,而在较大的 P3 实例上,我们看到了更一致的改进。这表明,在启用 MPS 的情况下运行部署所带来的吞吐量方面的益处在很大程度上取决于工作负载和环境,需要使用适当的基准测试和工具在特定情况下确定。需要注意的是,之前的基准测试仅关注吞吐量,而忽略了延迟和内存占用。由于使用 MPS 仅会创建一个单个 CUDA 上下文,因此可以将更多工作进程打包到同一 GPU 上,这在相关场景中也需要考虑。
