几周前,TorchVision v0.11 发布,其中包含了大量新原语、模型和训练方法改进,从而实现了最新技术水平(SOTA)的结果。该项目被戏称为“电池已备好的 TorchVision”,旨在现代化我们的库。我们希望通过使用通用构建块,使研究人员更容易复现论文和进行研究。此外,我们渴望为应用机器学习从业者提供必要的工具,让他们使用与研究中相同的 SOTA 技术,在自己的数据上训练模型。最后,我们希望更新我们的预训练权重,并为用户提供更好、开箱即用的模型,希望他们能构建更好的应用程序。
尽管还有许多工作要做,但我们想与大家分享一些上述工作带来的令人兴奋的成果。我们将展示如何使用 TorchVision 中包含的新工具,在 ResNet50 [1] 这样极具竞争力且经过充分研究的架构上取得最先进的结果。我们将分享用于将基线提高 4.7 个准确率百分点以上、最终达到 80.9% 的 Top-1 准确率的确切方法,并分享推导新训练过程的历程。此外,我们将展示这种方法能很好地泛化到其他模型变体和系列。我们希望上述内容能影响未来研究,以开发更强大、可泛化的训练方法,并激励社区采用并贡献我们的努力。
结果
使用基于 ResNet50 的新训练方法,我们更新了以下模型的预训练权重
| 模型 | 准确率@1 | 准确率@5 |
|---|---|---|
| ResNet50 | 80.858 | 95.434 |
| ResNet101 | 81.886 | 95.780 |
| ResNet152 | 82.284 | 96.002 |
| ResNeXt50-32x4d | 81.198 | 95.340 |
请注意,除了 ResNet50(原文RetNet50应为笔误)之外,所有模型的准确率都可以通过微调训练参数进一步提高,但我们的重点是提供一个对所有模型都表现良好的单一稳健方法。
更新:我们已更新了 TorchVision 中大多数流行分类模型的预训练权重,详细信息请参阅这篇博客文章。
目前有两种使用模型的最新权重的方法。
使用多预训练权重 API
我们目前正在开发一种新的原型机制,它将扩展 TorchVision 的模型构建方法以支持多种权重。除了权重之外,我们还存储了有用的元数据(例如标签、准确率、方法链接等)以及使用模型所需的预处理变换。示例
from PIL import Image
from torchvision import prototype as P
img = Image.open("test/assets/encode_jpeg/grace_hopper_517x606.jpg")
# Initialize model
weights = P.models.ResNet50_Weights.IMAGENET1K_V2
model = P.models.resnet50(weights=weights)
model.eval()
# Initialize inference transforms
preprocess = weights.transforms()
# Apply inference preprocessing transforms
batch = preprocess(img).unsqueeze(0)
prediction = model(batch).squeeze(0).softmax(0)
# Make predictions
label = prediction.argmax().item()
score = prediction[label].item()
# Use meta to get the labels
category_name = weights.meta['categories'][label]
print(f"{category_name}: {100 * score}%")
使用传统 API
不想使用原型 API 的用户可以选择使用以下方法通过传统 API 访问新权重
from torchvision.models import resnet
# Overwrite the URL of the previous weights
resnet.model_urls["resnet50"] = "https://download.pytorch.org/models/resnet50-11ad3fa6.pth"
# Initialize the model using the legacy API
model = resnet.resnet50(pretrained=True)
# TODO: Apply preprocessing + call the model
# ...
训练方法
我们的目标是利用 TorchVision 新引入的原语,推导出一个强大的新训练方法,以便在 ImageNet 上从头开始训练、不使用额外外部数据时,使原始 ResNet50 架构实现最先进的结果。尽管通过使用架构特定的技巧 [2] 可以进一步提高准确率,但我们决定不包含这些技巧,以便该方法可用于其他架构。我们的方法 着重于简洁性,并基于 FAIR 的研究工作 [3], [4], [5], [6], [7]。 我们的发现与 Wightman 等人 [7] 的并行研究一致,他们的研究也报告了通过关注训练方法而带来的显著准确率提升。
话不多说,以下是我们方法的主要参数
# Optimizer & LR scheme
ngpus=8,
batch_size=128, # per GPU
epochs=600,
opt='sgd',
momentum=0.9,
lr=0.5,
lr_scheduler='cosineannealinglr',
lr_warmup_epochs=5,
lr_warmup_method='linear',
lr_warmup_decay=0.01,
# Regularization and Augmentation
weight_decay=2e-05,
norm_weight_decay=0.0,
label_smoothing=0.1,
mixup_alpha=0.2,
cutmix_alpha=1.0,
auto_augment='ta_wide',
random_erase=0.1,
ra_sampler=True,
ra_reps=4,
# EMA configuration
model_ema=True,
model_ema_steps=32,
model_ema_decay=0.99998,
# Resizing
interpolation='bilinear',
val_resize_size=232,
val_crop_size=224,
train_crop_size=176,
使用我们的标准训练参考脚本,可以使用以下命令训练 ResNet50
torchrun --nproc_per_node=8 train.py --model resnet50 --batch-size 128 --lr 0.5 \
--lr-scheduler cosineannealinglr --lr-warmup-epochs 5 --lr-warmup-method linear \
--auto-augment ta_wide --epochs 600 --random-erase 0.1 --weight-decay 0.00002 \
--norm-weight-decay 0.0 --label-smoothing 0.1 --mixup-alpha 0.2 --cutmix-alpha 1.0 \
--train-crop-size 176 --model-ema --val-resize-size 232 --ra-sampler --ra-reps 4
方法论
我们在探索过程中记住了几条原则
- 训练是一个随机过程,我们试图优化的验证指标是一个随机变量。这是由于采用了随机权重初始化方案以及训练过程中存在随机效应。这意味着我们无法通过单次运行来评估方法更改的效果。标准做法是进行多次运行(通常为 3 到 5 次),并研究汇总统计数据(例如均值、标准差、中位数、最大值等)。
- 不同参数之间通常存在显著的相互作用,特别是对于侧重于正则化和减少过拟合的技术。因此,改变一个参数的值可能会影响其他参数的最优配置。为了解决这个问题,可以采用贪婪搜索方法(通常导致次优结果,但实验可行)或应用网格搜索(导致更好结果,但计算成本高昂)。在这项工作中,我们使用了两者的结合。
- 非确定性或引入噪声的技术通常需要更长的训练周期来提高模型性能。为了保持实验可行性,我们最初使用较短的训练周期(少量轮次)来决定哪些路径可以早期淘汰,哪些应该使用更长时间的训练进行探索。
- 由于重复实验,存在验证数据集过拟合的风险 [8]。为了减轻部分风险,我们只应用能带来显著准确率提升的训练优化,并使用 K 折交叉验证来验证在验证集上进行的优化。此外,我们确认我们的方法要素能很好地泛化到我们未对其超参数进行优化的其他模型上。
关键准确率提升的分解
正如之前的博客文章中所讨论的,训练模型并非准确率单调递增的过程,其中涉及大量回溯。为了量化每次优化的效果,我们在下面试图展示一个从 TorchVision 原始方法开始,推导出最终方法的理想化线性过程。我们想澄清,这只是对我们实际路径的过度简化,因此不应照字面理解。
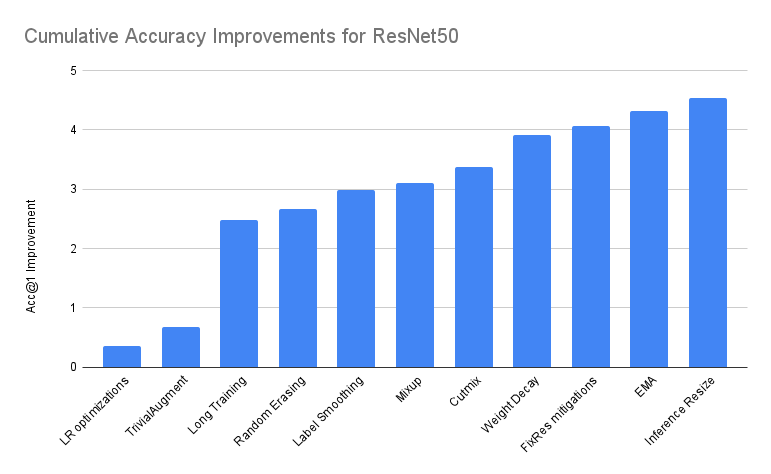
下表总结了在基线基础上叠加增量改进所带来的性能。除非另有说明,我们报告 3 次运行中 Acc@1 最佳的模型。
| 准确率@1 | 准确率@5 | 增量差异 | 绝对差异 | |
|---|---|---|---|---|
| ResNet50 基线 | 76.130 | 92.862 | 0.000 | 0.000 |
| + 学习率优化 | 76.494 | 93.198 | 0.364 | 0.364 |
| + TrivialAugment | 76.806 | 93.272 | 0.312 | 0.676 |
| + 长时间训练 | 78.606 | 94.052 | 1.800 | 2.476 |
| + 随机擦除 | 78.796 | 94.094 | 0.190 | 2.666 |
| + 标签平滑 | 79.114 | 94.374 | 0.318 | 2.984 |
| + Mixup | 79.232 | 94.536 | 0.118 | 3.102 |
| + Cutmix | 79.510 | 94.642 | 0.278 | 3.380 |
| + 权重衰减调优 | 80.036 | 94.746 | 0.526 | 3.906 |
| + FixRes 缓解措施 | 80.196 | 94.672 | 0.160 | 4.066 |
| + EMA | 80.450 | 94.908 | 0.254 | 4.320 |
| + 推理时调整图像大小调优 * | 80.674 | 95.166 | 0.224 | 4.544 |
| + 重复数据增强 ** | 80.858 | 95.434 | 0.184 | 4.728 |
*推理时调整图像大小的调优是在最终模型的基础上进行的。详情见下文。
** 社区贡献,在文章发布后完成。详情见下文。
基线
我们的基线是之前发布的 TorchVision ResNet50 模型。它采用以下方法进行训练
# Optimizer & LR scheme
ngpus=8,
batch_size=32, # per GPU
epochs=90,
opt='sgd',
momentum=0.9,
lr=0.1,
lr_scheduler='steplr',
lr_step_size=30,
lr_gamma=0.1,
# Regularization
weight_decay=1e-4,
# Resizing
interpolation='bilinear',
val_resize_size=256,
val_crop_size=224,
train_crop_size=224,
上述大多数参数是我们的训练脚本中的默认值。我们将在此基线上开始构建,引入优化措施,直到逐步达到最终方法。
学习率优化
我们可以应用一些参数更新来提高训练的准确率和速度。这可以通过增加批大小和调优学习率来实现。另一种常用方法是应用预热(warmup),逐渐增加学习率。这在使用非常高的学习率时特别有利,有助于提高早期轮次的训练稳定性。最后,另一种优化方法是应用余弦调度器(Cosine Schedule)在训练过程中调整学习率。余弦调度器的一大优势在于没有需要优化的超参数,这减少了我们的搜索空间。
以下是在基线方法基础上应用的额外优化措施。请注意,我们进行了多次实验以确定参数的最优配置。
batch_size=128, # per GPU
lr=0.5,
lr_scheduler='cosineannealinglr',
lr_warmup_epochs=5,
lr_warmup_method='linear',
lr_warmup_decay=0.01,
与基线相比,上述优化将我们的 Top-1 准确率提高了 0.364 个百分点。请注意,为了结合不同的学习率策略,我们使用了新引入的 SequentialLR 调度器。
TrivialAugment
原始模型使用随机大小裁剪(Random resized crops)和水平翻转(horizontal flips)等基本数据增强变换进行训练。提高准确率的一个简单方法是应用更复杂的“自动数据增强”(Automatic-Augmentation)技术。对我们来说表现最好的是 TrivialAugment [9],它极其简单,可以被认为是“无参数”的,这意味着它可以帮助我们进一步减少搜索空间。
以下是在上一步基础上应用的更新
auto_augment='ta_wide',
与上一步相比,使用 TrivialAugment 将我们的 Top-1 准确率提高了 0.312 个百分点。
长时间训练
当我们的方法包含具有随机行为的要素时,更长的训练周期是有益的。更具体地说,随着我们开始添加越来越多引入噪声的技术,增加轮次数量变得至关重要。请注意,在我们探索的早期阶段,使用了大约 200 轮次的相对较短周期,随着我们开始缩小大多数参数的范围,后来增加到 400 轮次,最终在方法最终版本中增加到 600 轮次。
下文展示了在之前步骤基础上应用的更新
epochs=600,
这在之前步骤的基础上将我们的 Top-1 准确率进一步提高了 1.8 个百分点。这是我们在这一迭代过程中观察到的最大增幅。值得注意的是,这种单一优化的效果被夸大了,并且在某种程度上具有误导性。仅仅在旧基线上增加轮次数量并不会带来如此显著的改进。然而,学习率优化与强大的数据增强策略相结合,有助于模型从更长周期中获益。还值得一提的是,我们在过程早期引入漫长训练周期的原因在于,接下来的步骤将引入需要显著更多轮次才能获得良好结果的技术。
随机擦除
另一种已知有助于提高分类准确率的数据增强技术是随机擦除(Random Erasing) [10], [11]。它通常与自动数据增强方法结合使用,由于其正则化效果,通常会带来额外的准确率提升。在我们的实验中,我们仅通过网格搜索调优了应用该方法的概率,发现将其概率保持在较低水平(通常在 10% 左右)是有益的。
以下是在之前步骤基础上引入的额外参数
random_erase=0.1,
应用随机擦除将我们的 Acc@1 进一步提高了 0.190 个百分点。
标签平滑
减少过拟合的一个好技术是阻止模型变得过度自信。这可以通过使用标签平滑(Label Smoothing) [12] 来软化真实标签实现。有一个参数控制平滑的程度(值越高,平滑越强),我们需要指定它。尽管通过网格搜索进行优化是可能的,但我们发现 0.05-0.15 左右的值能产生类似结果,因此为了避免对其过度拟合,我们使用了引入该技术论文中的相同值。
下文可以看到在此步骤中添加的额外配置
label_smoothing=0.1,
我们使用了 PyTorch 新引入的 CrossEntropyLoss 的 label_smoothing 参数,这使我们的准确率额外提高了 0.318 个百分点。
Mixup 和 Cutmix
两种常用于产生 SOTA 结果的数据增强技术是 Mixup 和 Cutmix [13], [14]。它们都能通过软化标签和图像来提供强大的正则化效果。在我们的设置中,我们发现随机且等概率地应用其中一种是有益的。每种技术都由超参数 alpha 参数化,该参数控制用于采样平滑概率的 Beta 分布的形状。我们进行了非常有限的网格搜索,主要关注论文中提出的常用值。
下文将展示这两种技术超参数 alpha 的最优值
mixup_alpha=0.2,
cutmix_alpha=1.0,
应用 mixup 使我们的准确率提高了 0.118 个百分点,而将其与 cutmix 结合则额外提高了 0.278 个百分点。
权重衰减调优
我们的标准方法使用 L2 正则化来减少过拟合。权重衰减(Weight Decay)参数控制正则化的程度(值越大,正则化越强),默认普遍应用于模型的所有学习参数。在本方法中,我们对标准方法应用了两项优化。首先,我们进行网格搜索来调优权重衰减参数;其次,我们对归一化层的参数禁用权重衰减。
下文可以看到我们方法中权重衰减的最优配置
weight_decay=2e-05,
norm_weight_decay=0.0,
上述更新使我们的准确率进一步提高了 0.526 个百分点,为调优权重衰减对模型性能有显著影响这一已知事实提供了额外的实验证据。我们将归一化参数与其余参数分离的方法灵感来源于 ClassyVision 的方法。
FixRes 缓解措施
我们在实验早期发现的一个重要特性是,如果验证过程中使用的分辨率从训练时的 224x224 提高,模型的性能会显著更好。这一效应在 FixRes 论文 [5] 中有详细研究,并提出了两种缓解措施:a) 可以尝试降低训练分辨率,以便在验证分辨率下准确率最大化;或 b) 可以通过两阶段训练对模型进行微调,使其适应目标分辨率。由于我们不想引入两阶段训练,我们选择了方案 a)。这意味着我们从 224 减小了训练裁剪尺寸,并使用网格搜索来找到能在 224x224 分辨率下最大化验证准确率的值。
下文可以看到我们方法中使用的最优值
val_crop_size=224,
train_crop_size=176,
上述优化使我们的准确率额外提高了 0.160 个百分点,并将训练速度提高了 10%。
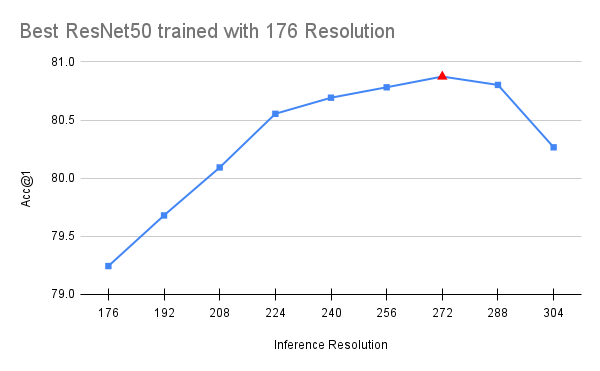
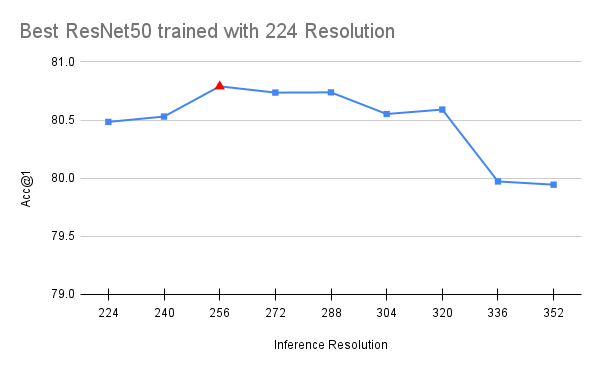
值得注意的是,FixRes 效应仍然存在,这意味着当我们提高分辨率时,模型在验证集上的表现仍然更好。此外,进一步减小训练裁剪尺寸实际上会损害准确率。这在直觉上是合理的,因为在关键细节开始从图像中消失之前,只能将分辨率降低这么多。最后,我们应该注意,上述 FixRes 缓解措施似乎对与 ResNet50 深度相似的模型有益。具有更大感受野的更深变体似乎受到轻微负面影响(通常降低 0.1-0.2 个百分点)。因此,我们将这部分方法视为可选。下文我们可视化了使用完整方法训练的 176 和 224 分辨率模型的最佳可用检查点性能:
指数移动平均(EMA)
EMA 是一种技术,可以在不增加模型复杂性或推理时间的情况下提升模型的准确率。它对模型权重进行指数移动平均,从而提高准确率并使模型更稳定。平均操作每隔几次迭代发生,其衰减参数通过网格搜索进行调优。
下文可以看到我们方法中的最优值
model_ema=True,
model_ema_steps=32,
model_ema_decay=0.99998,
与上一步相比,使用 EMA 使我们的准确率提高了 0.254 个百分点。请注意,TorchVision 的 EMA 实现构建在 PyTorch 的 AveragedModel 类之上,关键区别在于它不仅对模型参数进行平均,还对其 buffers 进行平均。此外,我们采用了 Pycls 中的技巧,这使我们能够以一种不依赖于轮次数的方式参数化衰减。
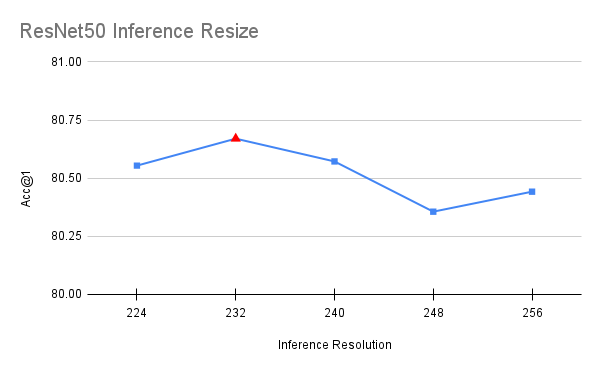
推理时调整图像大小调优
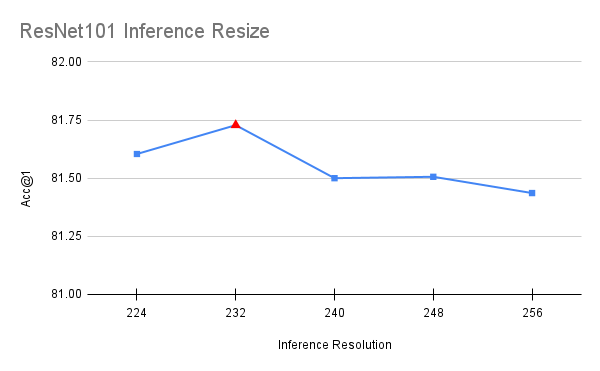
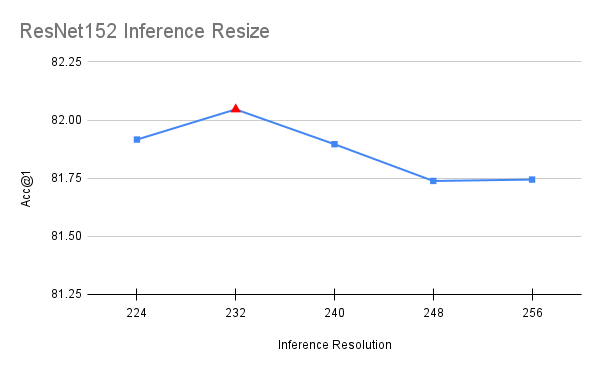
与过程中涉及使用不同参数训练模型的所有其他步骤不同,此优化是在最终模型的基础上进行的。在推理时,图像被调整到特定分辨率,然后从中裁剪一个 224x224 的中心区域。原始方法使用的调整大小为 256,这导致了与 FixRes 论文 [5] 中描述的类似差异。通过将此调整大小值更接近目标推理分辨率,可以提高准确率。为了选择该值,我们在 [224, 256] 区间内以 8 的步长进行了一次简短的网格搜索。为避免过拟合,该值使用一半验证集进行选择,并使用另一半进行确认。
下文可以看到我们方法中使用的最优值
val_resize_size=232,
上述优化使我们的准确率提高了 0.224 个百分点。值得注意的是,ResNet50 的最优值也对 ResNet101、ResNet152 和 ResNeXt50 模型效果最好,这表明它具有跨模型的泛化性。
[更新] 重复数据增强
重复数据增强(Repeated Augmentation) [15], [16] 是另一种可以提高整体准确率的技术,并被其他强大的方法(例如 [6], [7])使用。社区贡献者 Tal Ben-Nun 通过提出使用 4 次重复来训练模型,进一步改进了我们的原始方法。他的贡献是在本文发布后进行的。
下文可以看到我们方法中使用的最优值
ra_sampler=True,
ra_reps=4,
上述是最终的优化措施,使我们的准确率提高了 0.184 个百分点。
已测试但未采用的优化措施
在我们研究的早期阶段,我们实验了额外的技术、配置和优化措施。由于我们的目标是尽可能保持方法的简洁性,我们决定不包含任何未带来显著改进的内容。以下是我们尝试过但未纳入最终方法的几种方法:
- 优化器:使用更复杂的优化器,如 Adam、RMSProp 或带有 Nesterov 动量的 SGD,与带有动量的原始 SGD 相比,并未提供显著更好的结果。
- 学习率调度器: 我们尝试了不同的学习率调度器方案,例如 StepLR 和 Exponential。尽管后者与 EMA 配合效果更好,但通常需要额外的超参数(例如定义最低学习率)才能良好工作。相反,我们只使用余弦退火(cosine annealing)将学习率衰减至零,并选择准确率最高的检查点。
- 自动数据增强: 我们尝试了不同的数据增强策略,例如 AutoAugment 和 RandAugment。这些方法均未胜过更简单的无参数 TrivialAugment。
- 插值方法:使用双三次插值(bicubic)或最近邻插值(nearest)并未比双线性插值(bilinear)提供显著更好的结果。
- 归一化层:使用同步批归一化(Sync Batch Norm)并未比使用常规批归一化(Batch Norm)产生显著更好的结果。
致谢
我们谨感谢 Piotr Dollar、Mannat Singh 和 Hugo Touvron 在方法开发过程中提供的见解和反馈,以及他们之前作为我们方法基础的研究工作。他们的支持对于取得上述成果是无价的。此外,我们还要感谢 Prabhat Roy、Kai Zhang、Yiwen Song、Joel Schlosser、Ilqar Ramazanli、Francisco Massa、Mannat Singh、Xiaoliang Dai、Samuel Gabriel、Allen Goodman 和 Tal Ben-Nun 对“电池已备好”项目的贡献。
参考文献
- Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun. “Deep Residual Learning for Image Recognition”.
- Tong He, Zhi Zhang, Hang Zhang, Zhongyue Zhang, Junyuan Xie, Mu Li. “Bag of Tricks for Image Classification with Convolutional Neural Networks”
- Piotr Dollár, Mannat Singh, Ross Girshick. “Fast and Accurate Model Scaling”
- Tete Xiao, Mannat Singh, Eric Mintun, Trevor Darrell, Piotr Dollár, Ross Girshick. “Early Convolutions Help Transformers See Better”
- Hugo Touvron, Andrea Vedaldi, Matthijs Douze, Hervé Jégou. “Fixing the train-test resolution discrepancy
- Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, Hervé Jégou. “Training data-efficient image transformers & distillation through attention”
- Ross Wightman, Hugo Touvron, Hervé Jégou. “ResNet strikes back: An improved training procedure in timm”
- Benjamin Recht, Rebecca Roelofs, Ludwig Schmidt, Vaishaal Shankar. “Do ImageNet Classifiers Generalize to ImageNet?”
- Samuel G. Müller, Frank Hutter. “TrivialAugment: Tuning-free Yet State-of-the-Art Data Augmentation”
- Zhun Zhong, Liang Zheng, Guoliang Kang, Shaozi Li, Yi Yang. “Random Erasing Data Augmentation”
- Terrance DeVries, Graham W. Taylor. “Improved Regularization of Convolutional Neural Networks with Cutout”
- Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jon Shlens, Zbigniew Wojna. “Rethinking the Inception Architecture for Computer Vision”
- Hongyi Zhang, Moustapha Cisse, Yann N. Dauphin, David Lopez-Paz. “mixup: Beyond Empirical Risk Minimization”
- Sangdoo Yun, Dongyoon Han, Seong Joon Oh, Sanghyuk Chun, Junsuk Choe, Youngjoon Yoo. “CutMix: Regularization Strategy to Train Strong Classifiers with Localizable Features”
- Elad Hoffer, Tal Ben-Nun, Itay Hubara, Niv Giladi, Torsten Hoefler, Daniel Soudry. “Augment your batch: better training with larger batches”
- Maxim Berman, Hervé Jégou, Andrea Vedaldi, Iasonas Kokkinos, Matthijs Douze. “Multigrain: a unified image embedding for classes and instances”
