基本概念¶
本文介绍了 TorchX 的高级概念和项目结构。有关如何创建和运行应用程序,请查看快速入门指南。
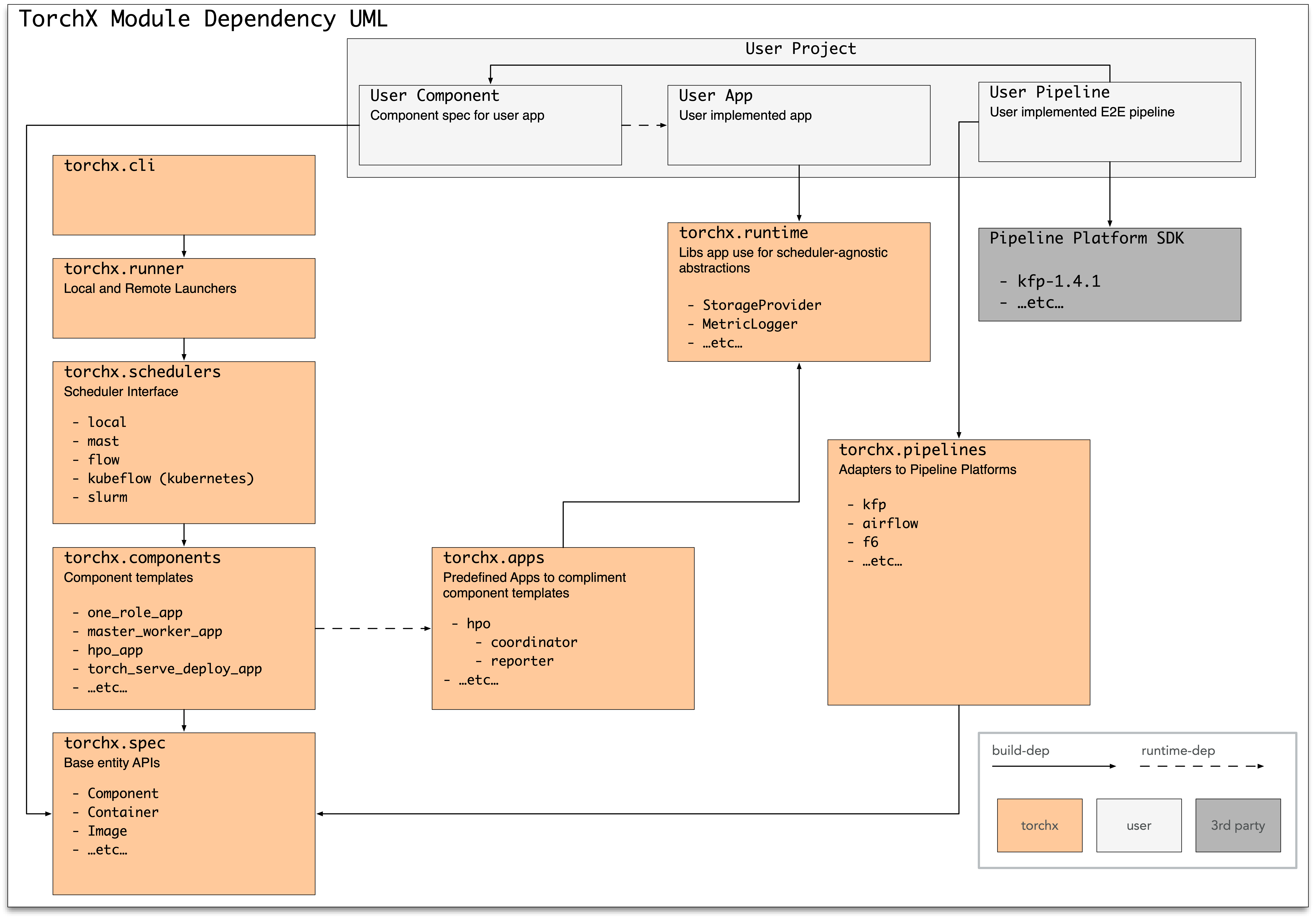
项目结构¶
TorchX 中的顶级模块为
torchx.specs: 应用程序规范(作业定义)APItorchx.components: 预定义(内置)应用程序规范torchx.workspace: 处理为远程执行修补映像torchx.cli: CLI 工具torchx.runner: 给定应用程序规范,将应用程序作为作业提交到调度器torchx.schedulers: 运行程序支持的后端作业调度器torchx.pipelines: 将给定应用程序规范转换为 ML 管道平台中的“阶段”的适配器torchx.runtime: 可以在编写应用程序(而非应用程序规范)时使用的实用程序和抽象库
以下是 UML 图
概念¶
AppDefs¶
在 TorchX 中,AppDef 只是一个包含实际应用程序定义的结构。在调度器术语中,这被称为 JobDefinition,Kubernetes 中类似的概念是 spec.yaml。为了区分应用程序二进制文件(逻辑)和规范,我们通常将 TorchX AppDef 称为“应用程序规范”或 specs.AppDef。它是 torchx.runner 和 torchx.pipelines 共同理解的接口,允许您将应用程序作为独立作业运行或作为 ML 管道中的一个阶段运行。
以下是一个简单的 specs.AppDef 示例,它会回显“hello world”
import torchx.specs as specs
specs.AppDef(
name="echo",
roles=[
specs.Role(
name="echo",
entrypoint="/bin/echo",
image="/tmp",
args=["hello world"],
num_replicas=1
)
]
)
如您所见,specs.AppDef 是一个纯粹的 Python 数据类,它只编码主二进制文件(入口点)的名称、传递给它的参数,以及一些其他运行时参数,如 num_replicas 和有关运行容器的信息(entrypoint=/bin/echo)。
应用程序规范很灵活,可以编码各种应用程序拓扑的规范。例如,num_replicas > 1 表示应用程序是分布式的。指定多个 specs.Roles 可以表示非同构分布式应用程序,例如需要单个“协调器”和多个“工作器”的应用程序。
请参阅 torchx.specs 的API 文档 以了解更多信息。
应用程序规范的灵活特性也导致它具有许多字段。好消息是,在大多数情况下,您不需要从头开始构建应用程序规范。相反,您可以使用名为 components 的模板化应用程序规范。
组件¶
TorchX 中的组件只是一个模板化的 spec.AppDef。您可以将它们视为 spec.AppDef 的便捷“工厂方法”。
注意
与应用程序不同,组件不映射到实际的 Python 数据类。相反,返回 spec.AppDef 的工厂函数称为组件。
应用程序规范模板化的粒度各不相同。某些组件,如上面的 echo 示例,是可直接运行的,这意味着它们具有硬编码的应用程序二进制文件。其他组件,如 ddp(分布式数据并行)规范,只指定应用程序的拓扑结构。以下是一个可能的 DDP 样式训练器应用程序规范模板,它指定了同构节点拓扑结构
import torchx.specs as specs
def ddp(jobname: str, nnodes: int, image: str, entrypoint: str, *script_args: str):
single_gpu = specs.Resources(cpu=4, gpu=1, memMB=1024)
return specs.AppDef(
name=jobname,
roles=[
specs.Role(
name="trainer",
entrypoint=entrypoint,
image=image,
resource=single_gpu,
args=script_args,
num_replicas=nnodes
)
]
)
如您所见,参数化的程度完全由组件作者决定。创建组件的工作量仅仅是编写一个 Python 函数。不要尝试通过参数化所有内容来过度泛化组件。组件易于创建且成本低廉,您可以根据重复使用的情况创建任意数量的组件。
建议 1: 由于组件是 Python 函数,因此可以通过 Python 函数组合来实现组件组合,而不是对象组合。但是,我们不推荐组件组合,因为这样做会影响可维护性。
建议 2: 要定义组件之间的依赖关系,请使用管道 DSL。请参阅下面的管道适配器 部分,了解如何在管道上下文中使用 TorchX 组件。
在编写自己的组件之前,请浏览 TorchX 中包含的组件 库,看看是否有适合您需求的组件。
运行程序和调度器¶
Runner 的作用正如您所预期的那样——给定应用程序规范,它会通过作业调度器将应用程序作为作业启动到集群上。
在 TorchX 中有两种访问运行程序的方式
CLI:
torchx run ~/app_spec.py以编程方式:
torchx.runner.get_runner().run(appspec)
请参阅调度器,了解运行程序可以启动应用程序的调度器列表。
管道适配器¶
虽然运行程序将组件作为独立作业启动,但 torchx.pipelines 使得将组件插入 ML 管道/工作流成为可能。对于特定目标管道平台(例如 Kubeflow 管道),TorchX 定义了一个适配器,该适配器将 TorchX 应用程序规范转换为目标平台中的“阶段”表示。例如,Kubeflow 管道的 torchx.pipelines.kfp 适配器将应用程序规范转换为 kfp.ContainerOp(更准确地说是 Kubeflow“组件规范”yaml)。
在大多数情况下,应用程序规范会映射到管道中的一个“阶段”(或节点)。但是,高级组件,尤其是那些具有自身微型控制流的组件(例如 HPO),可能会映射到“子管道”或“内联管道”。这些高级组件如何映射到管道的精确语义取决于目标管道平台。例如,如果管道 DSL 允许从上游阶段动态地将阶段添加到管道中,则 TorchX 可能会利用此功能将子管道“内联”到主管道中。TorchX 通常会尽最大努力将应用程序规范适配到目标管道平台中最规范的表示形式。
有关支持的管道平台列表,请参见 管道。
运行时¶
重要
torchx.runtime 绝不是使用 TorchX 的必需条件。如果您的基础设施是固定的,并且您不需要您的应用程序可移植到不同类型的调度程序和管道,则可以跳过此部分。
您的应用程序(不是应用程序规范,而是实际的应用程序二进制文件)对 TorchX 具有零依赖性(例如,/bin/echo 不使用 TorchX,但可以为其创建 echo_torchx.py 组件)。
注意
torchx.runtime 是您在编写应用程序二进制文件时唯一应该使用的模块!
但是,由于 TorchX 本质上允许您的应用程序在任何地方运行,因此建议您的应用程序以调度程序/基础设施不可知的方式编写。
这通常意味着在与调度程序/基础设施的接触点添加一个 API 层。例如,以下应用程序不是基础设施不可知的
import boto3
def main(input_path: str):
s3 = boto3.session.Session().client("s3")
path = s3_input_path.split("/")
bucket = path[0]
key = "/".join(path[1:])
s3.download_file(bucket, key, "/tmp/input")
input = torch.load("/tmp/input")
# ...<rest of code omitted for brevity>...
上面的二进制文件隐式地假设 input_path 是一个 AWS S3 路径。使此训练器存储不可知的一种方法是引入一个 FileSystem 抽象层。对于文件系统,像 PyTorch Lightning 这样的框架已经定义了 io 层(Lightning 在幕后使用 fsspec)。上面的二进制文件可以使用 Lightning 重写为存储不可知的。
import pytorch_lightning.utilities.io as io
def main(input_url: str):
fs = io.get_filesystem(input_url)
with fs.open(input_url, "rb") as f:
input = torch.load(f)
# ...<rest of code omitted for brevity>...
现在,可以将 main 称为 main("s3://foo/bar") 或 main("file://foo/bar"),使其与存储在各种存储中的输入兼容。
有了 FileSystem,已经存在定义文件系统抽象的库。在 torchx.runtime 中,您会找到提供各种功能抽象的库或指向其他库的指针,您可能需要这些库来编写基础设施不可知的应用程序。理想情况下,torchx.runtime 中的功能会及时上游到诸如 Lightning 这样的库,这些库旨在用于编写您的应用程序。但找到这些抽象的合适永久位置可能需要时间,甚至可能需要创建一个全新的 OSS 项目。在这种情况发生之前,这些功能可以成熟并通过 torchx.runtime 模块提供给用户。
后续步骤¶
查看 快速入门指南,了解如何创建和运行组件。
