基于 TorchDynamo 的 ONNX 导出器¶
警告
TorchDynamo 的 ONNX 导出器是一项快速发展的测试版技术。
概述¶
ONNX 导出器利用 TorchDynamo 引擎挂钩到 Python 的帧评估 API,并动态地将字节码重写为 FX 图。生成的 FX 图在最终转换为 ONNX 图之前会进行优化。
这种方法的主要优势在于 FX 图 是使用字节码分析捕获的,它保留了模型的动态特性,而不是使用传统的静态跟踪技术。
导出器旨在模块化和可扩展。它由以下组件组成
ONNX 导出器:
Exporter是协调导出过程的主要类。ONNX 导出选项:
ExportOptions包含一组控制导出过程的选项。ONNX 注册表:
OnnxRegistry是 ONNX 算子和函数的注册表。FX 图提取器:
FXGraphExtractor从 PyTorch 模型中提取 FX 图。模拟模式:
ONNXFakeContext是一个上下文管理器,它为大型模型启用模拟模式。ONNX 程序:
ONNXProgram是导出器的输出,包含导出的 ONNX 图和诊断信息。ONNX 程序序列化器:
ONNXProgramSerializer将导出的模型序列化到文件。ONNX 诊断选项:
DiagnosticOptions包含一组控制导出器发出的诊断信息的选项。
一个简单的例子¶
以下展示了导出器 API 的实际应用,以一个简单的多层感知器 (MLP) 为例
import torch
import torch.nn as nn
class MLPModel(nn.Module):
def __init__(self):
super().__init__()
self.fc0 = nn.Linear(8, 8, bias=True)
self.fc1 = nn.Linear(8, 4, bias=True)
self.fc2 = nn.Linear(4, 2, bias=True)
self.fc3 = nn.Linear(2, 2, bias=True)
def forward(self, tensor_x: torch.Tensor):
tensor_x = self.fc0(tensor_x)
tensor_x = torch.sigmoid(tensor_x)
tensor_x = self.fc1(tensor_x)
tensor_x = torch.sigmoid(tensor_x)
tensor_x = self.fc2(tensor_x)
tensor_x = torch.sigmoid(tensor_x)
output = self.fc3(tensor_x)
return output
model = MLPModel()
tensor_x = torch.rand((97, 8), dtype=torch.float32)
onnx_program = torch.onnx.dynamo_export(model, tensor_x)
如上代码所示,您只需提供 torch.onnx.dynamo_export() 模型实例及其输入。导出器将返回一个 torch.onnx.ONNXProgram 实例,其中包含导出的 ONNX 图以及其他信息。
通过 onnx_program.model_proto 可用的内存模型是符合 ONNX IR 规范 的 onnx.ModelProto 对象。然后可以使用 torch.onnx.ONNXProgram.save() API 将 ONNX 模型序列化为 Protobuf 文件。
onnx_program.save("mlp.onnx")
使用 GUI 检查 ONNX 模型¶
您可以使用 Netron 查看导出的模型。
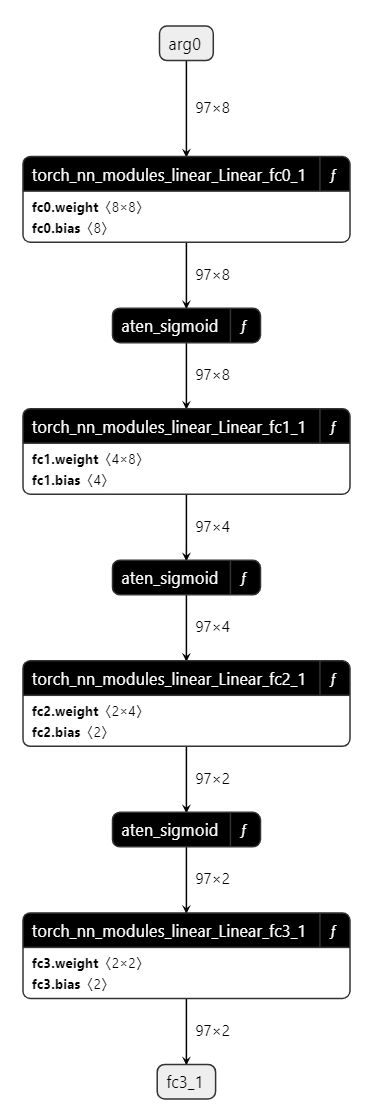
请注意,每个层都用一个矩形框表示,右上角有一个 *f* 图标。
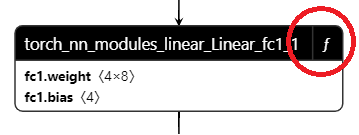
展开它,将显示函数体。
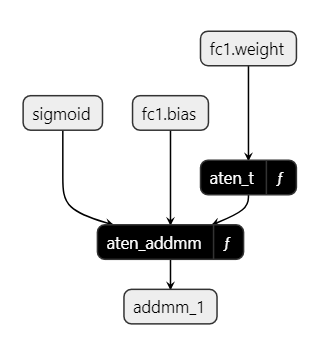
函数体是 ONNX 运算符或其他函数的序列。
使用 SARIF 诊断问题¶
ONNX 诊断通过采用 静态分析结果交换格式(又名 SARIF) 超越了常规日志,以帮助用户使用 GUI(如 Visual Studio Code 的 SARIF 查看器)调试和改进其模型。
主要优点是
诊断以机器可解析的 静态分析结果交换格式 (SARIF) 发出。
一种更清晰、结构化的方式来添加新的诊断规则并跟踪它们。
作为未来更多使用诊断的改进的基础。
ONNX 诊断 SARIF 规则
- FXE0007:fx-graph-to-onnx
- FXE0008:fx-node-to-onnx
- FXE0010:fx-pass
- FXE0011:no-symbolic-function-for-call-function
- FXE0012:unsupported-fx-node-analysis
- FXE0013:op-level-debugging
- FXE0014:find-opschema-matched-symbolic-function
- FXE0015:fx-node-insert-type-promotion
- FXE0016:find-operator-overloads-in-onnx-registry
API 参考¶
- torch.onnx.dynamo_export(model, /, *model_args, export_options=None, **model_kwargs)¶
将 torch.nn.Module 导出到 ONNX 图。
- 参数
model (Union[Module, Callable, ExportedProgram]) – 要导出到 ONNX 的 PyTorch 模型。
model_args –
model的位置输入。model_kwargs –
model的关键字输入。export_options (Optional[ExportOptions]) – 影响导出到 ONNX 的选项。
- 返回值
导出的 ONNX 模型的内存表示。
- 返回类型
示例 1 - 最简单的导出
class MyModel(torch.nn.Module): def __init__(self) -> None: super().__init__() self.linear = torch.nn.Linear(2, 2) def forward(self, x, bias=None): out = self.linear(x) out = out + bias return out model = MyModel() kwargs = {"bias": 3.} args = (torch.randn(2, 2, 2),) onnx_program = torch.onnx.dynamo_export( model, *args, **kwargs).save("my_simple_model.onnx")
示例 2 - 使用动态形状导出
# The previous model can be exported with dynamic shapes export_options = torch.onnx.ExportOptions(dynamic_shapes=True) onnx_program = torch.onnx.dynamo_export( model, *args, **kwargs, export_options=export_options) onnx_program.save("my_dynamic_model.onnx")
通过打印输入动态维度,我们可以看到输入形状不再是 (2,2,2)
>>> print(onnx_program.model_proto.graph.input[0]) name: "arg0" type { tensor_type { elem_type: 1 shape { dim { dim_param: "arg0_dim_0" } dim { dim_param: "arg0_dim_1" } dim { dim_param: "arg0_dim_2" } } } }
- class torch.onnx.ExportOptions(*, dynamic_shapes=None, op_level_debug=None, fake_context=None, onnx_registry=None, diagnostic_options=None)¶
影响 TorchDynamo ONNX 导出器的选项。
- 变量
dynamic_shapes (Optional[bool]) – 输入/输出张量的形状信息提示。当为
None时,导出器会确定最兼容的设置。当为True时,所有输入形状都被视为动态。当为False时,所有输入形状都被视为静态。op_level_debug (Optional[bool]) – 是否以操作级别调试信息导出模型
diagnostic_options (DiagnosticOptions) – 导出器的诊断选项。
fake_context (Optional[ONNXFakeContext]) – 用于符号跟踪的假上下文。
onnx_registry (Optional[OnnxRegistry]) – 用于将 ATen 运算符注册到 ONNX 函数的 ONNX 注册表。
- torch.onnx.enable_fake_mode()¶
在上下文持续时间内启用假模式。
在内部,它实例化一个
torch._subclasses.fake_tensor.FakeTensorMode上下文管理器,该管理器将用户输入和模型参数转换为torch._subclasses.fake_tensor.FakeTensor。一个
torch._subclasses.fake_tensor.FakeTensor是一个torch.Tensor,它能够运行 PyTorch 代码,而无需实际通过在meta设备上分配的张量进行计算。由于设备上没有实际分配数据,因此此 API 允许导出大型模型,而无需执行模型所需的实际内存占用。强烈建议在导出内存不足以容纳的模型时启用假模式。
- 返回值
一个
ONNXFakeContext对象,必须通过ExportOptions.fake_context参数传递给dynamo_export()。
示例
# xdoctest: +REQUIRES(env:TORCH_DOCTEST_ONNX) >>> import torch >>> import torch.onnx >>> class MyModel(torch.nn.Module): # Dummy model ... def __init__(self) -> None: ... super().__init__() ... self.linear = torch.nn.Linear(2, 2) ... def forward(self, x): ... out = self.linear(x) ... return out >>> with torch.onnx.enable_fake_mode() as fake_context: ... my_nn_module = MyModel() ... arg1 = torch.randn(2, 2, 2) # positional input 1 >>> export_options = torch.onnx.ExportOptions(fake_context=fake_context) >>> onnx_program = torch.onnx.dynamo_export( ... my_nn_module, ... arg1, ... export_options=export_options ... ) >>> # Saving model WITHOUT initializers >>> onnx_program.save("my_model_without_initializers.onnx") >>> # Saving model WITH initializers >>> onnx_program.save("my_model_with_initializers.onnx", model_state=MyModel().state_dict())
警告
此 API 处于实验阶段,并且不向后兼容。
- class torch.onnx.ONNXProgram(model_proto, input_adapter, output_adapter, diagnostic_context, *, fake_context=None, export_exception=None, model_signature=None, model_torch=None)¶
已导出到 ONNX 的 PyTorch 模型的内存中表示。
- 参数
model_proto (onnx.ModelProto) – 导出的 ONNX 模型,作为
onnx.ModelProto。input_adapter (io_adapter.InputAdapter) – 用于将 PyTorch 输入转换为 ONNX 输入的输入适配器。
output_adapter (io_adapter.OutputAdapter) – 用于将 PyTorch 输出转换为 ONNX 输出的输出适配器。
diagnostic_context (diagnostics.DiagnosticContext) – 用于 SARIF 诊断系统的上下文对象,负责记录错误和元数据。
fake_context (Optional[ONNXFakeContext]) – 用于符号跟踪的假上下文。
export_exception (Optional[Exception]) – 导出过程中发生的异常(如果有)。
model_signature (Optional[torch.export.ExportGraphSignature]) – 导出 ONNX 图的模型签名。
- adapt_torch_inputs_to_onnx(*model_args, model_with_state_dict=None, **model_kwargs)[source]¶
将 PyTorch 模型输入转换为导出的 ONNX 模型输入格式。
由于设计差异,PyTorch 模型和导出的 ONNX 模型之间的输入/输出格式通常不相同。例如,PyTorch 模型允许 None,但 ONNX 不支持。PyTorch 模型允许嵌套的张量结构,但 ONNX 仅支持扁平化的张量,等等。
实际的适配步骤与每个单独的导出相关联。它取决于 PyTorch 模型、用于导出的特定模型参数和模型关键字参数集以及导出选项。
此方法重放导出期间记录的适配步骤。
- 参数
- 返回值
从 PyTorch 模型输入转换而来的张量序列。
- 返回类型
示例
# xdoctest: +REQUIRES(env:TORCH_DOCTEST_ONNX) >>> import torch >>> import torch.onnx >>> from typing import Dict, Tuple >>> def func_nested_input( ... x_dict: Dict[str, torch.Tensor], ... y_tuple: Tuple[torch.Tensor, Tuple[torch.Tensor, torch.Tensor]] ... ): ... if "a" in x_dict: ... x = x_dict["a"] ... elif "b" in x_dict: ... x = x_dict["b"] ... else: ... x = torch.randn(3) ... ... y1, (y2, y3) = y_tuple ... ... return x + y1 + y2 + y3 >>> x_dict = {"a": torch.tensor(1.)} >>> y_tuple = (torch.tensor(2.), (torch.tensor(3.), torch.tensor(4.))) >>> onnx_program = torch.onnx.dynamo_export(func_nested_input, x_dict, y_tuple) >>> print(x_dict, y_tuple) {'a': tensor(1.)} (tensor(2.), (tensor(3.), tensor(4.))) >>> print(onnx_program.adapt_torch_inputs_to_onnx(x_dict, y_tuple, model_with_state_dict=func_nested_input)) (tensor(1.), tensor(2.), tensor(3.), tensor(4.))
警告
此 API 处于实验阶段,并且不向后兼容。
- adapt_torch_outputs_to_onnx(model_outputs, model_with_state_dict=None)[源代码]¶
将 PyTorch 模型输出转换为导出的 ONNX 模型输出格式。
由于设计差异,PyTorch 模型和导出的 ONNX 模型之间的输入/输出格式通常不相同。例如,PyTorch 模型允许 None,但 ONNX 不支持。PyTorch 模型允许嵌套的张量结构,但 ONNX 仅支持扁平化的张量,等等。
实际的适配步骤与每个单独的导出相关联。它取决于 PyTorch 模型、用于导出的特定模型参数和模型关键字参数集以及导出选项。
此方法重放导出期间记录的适配步骤。
- 参数
- 返回值
导出 ONNX 模型输出格式的 PyTorch 模型输出。
- 返回类型
示例
# xdoctest: +REQUIRES(env:TORCH_DOCTEST_ONNX) >>> import torch >>> import torch.onnx >>> def func_returning_tuples(x, y, z): ... x = x + y ... y = y + z ... z = x + y ... return (x, (y, z)) >>> x = torch.tensor(1.) >>> y = torch.tensor(2.) >>> z = torch.tensor(3.) >>> onnx_program = torch.onnx.dynamo_export(func_returning_tuples, x, y, z) >>> pt_output = func_returning_tuples(x, y, z) >>> print(pt_output) (tensor(3.), (tensor(5.), tensor(8.))) >>> print(onnx_program.adapt_torch_outputs_to_onnx(pt_output, model_with_state_dict=func_returning_tuples)) [tensor(3.), tensor(5.), tensor(8.)]
警告
此 API 处于实验阶段,并且不向后兼容。
- property diagnostic_context: diagnostics.DiagnosticContext¶
与导出相关的诊断上下文。
- property model_proto: onnx.ModelProto¶
导出的 ONNX 模型,以
onnx.ModelProto格式。
- property model_signature: Optional[ExportGraphSignature]¶
导出 ONNX 图的模型签名。
此信息很重要,因为 ONNX 规范通常与 PyTorch 的规范不同,导致 ONNX 图的输入和输出模式与实际 PyTorch 模型实现不同。通过使用模型签名,用户可以了解输入和输出的差异,并正确地在 ONNX Runtime 中执行模型。
注意:模型签名仅在从
torch.export.ExportedProgram对象导出 ONNX 图时可用。注意:对模型进行的任何更改模型签名的转换都必须通过
InputAdaptStep和/或OutputAdaptStep对此模型签名进行更新。示例
以下模型产生不同的输入和输出集。前 4 个输入是模型参数(即 conv1.weight、conv2.weight、fc1.weight、fc2.weight),接下来的 2 个输入是注册的缓冲区(即 my_buffer2、my_buffer1),最后 2 个输入是用户输入(即 x 和 b)。第一个输出是缓冲区变异(即 my_buffer2),最后一个输出是实际的模型输出。
>>> class CustomModule(torch.nn.Module): ... def __init__(self): ... super().__init__() ... self.my_parameter = torch.nn.Parameter(torch.tensor(2.0)) ... self.register_buffer("my_buffer1", torch.tensor(3.0)) ... self.register_buffer("my_buffer2", torch.tensor(4.0)) ... self.conv1 = torch.nn.Conv2d(1, 32, 3, 1, bias=False) ... self.conv2 = torch.nn.Conv2d(32, 64, 3, 1, bias=False) ... self.fc1 = torch.nn.Linear(9216, 128, bias=False) ... self.fc2 = torch.nn.Linear(128, 10, bias=False) ... def forward(self, x, b): ... tensor_x = self.conv1(x) ... tensor_x = torch.nn.functional.sigmoid(tensor_x) ... tensor_x = self.conv2(tensor_x) ... tensor_x = torch.nn.functional.sigmoid(tensor_x) ... tensor_x = torch.nn.functional.max_pool2d(tensor_x, 2) ... tensor_x = torch.flatten(tensor_x, 1) ... tensor_x = self.fc1(tensor_x) ... tensor_x = torch.nn.functional.sigmoid(tensor_x) ... tensor_x = self.fc2(tensor_x) ... output = torch.nn.functional.log_softmax(tensor_x, dim=1) ... ( ... self.my_buffer2.add_(1.0) + self.my_buffer1 ... ) # Mutate buffer through in-place addition ... return output >>> inputs = (torch.rand((64, 1, 28, 28), dtype=torch.float32), torch.randn(3)) >>> exported_program = torch.export.export(CustomModule(), args=inputs) >>> onnx_program = torch.onnx.dynamo_export(exported_program, *inputs) >>> print(onnx_program.model_signature) ExportGraphSignature( input_specs=[ InputSpec(kind=<InputKind.PARAMETER: 2>, arg=TensorArgument(name='arg0_1'), target='conv1.weight', persistent=None), InputSpec(kind=<InputKind.PARAMETER: 2>, arg=TensorArgument(name='arg1_1'), target='conv2.weight', persistent=None), InputSpec(kind=<InputKind.PARAMETER: 2>, arg=TensorArgument(name='arg2_1'), target='fc1.weight', persistent=None), InputSpec(kind=<InputKind.PARAMETER: 2>, arg=TensorArgument(name='arg3_1'), target='fc2.weight', persistent=None), InputSpec(kind=<InputKind.BUFFER: 3>, arg=TensorArgument(name='arg4_1'), target='my_buffer2', persistent=True), InputSpec(kind=<InputKind.BUFFER: 3>, arg=TensorArgument(name='arg5_1'), target='my_buffer1', persistent=True), InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='arg6_1'), target=None, persistent=None), InputSpec(kind=<InputKind.USER_INPUT: 1>, arg=TensorArgument(name='arg7_1'), target=None, persistent=None) ], output_specs=[ OutputSpec(kind=<OutputKind.BUFFER_MUTATION: 3>, arg=TensorArgument(name='add'), target='my_buffer2'), OutputSpec(kind=<OutputKind.USER_OUTPUT: 1>, arg=TensorArgument(name='_log_softmax'), target=None) ] )
- save(destination, *, model_state=None, serializer=None)[source]¶
使用指定的
serializer将内存中的 ONNX 模型保存到destination。- 参数
destination (Union[str, BufferedIOBase]) – 保存 ONNX 模型的目标位置。它可以是字符串或文件类对象。当与
model_state一起使用时,它必须是目标位置的完整路径字符串。如果 destination 是字符串,除了将 ONNX 模型保存到文件中之外,模型权重也会存储在与 ONNX 模型相同目录中的单独文件中。例如,对于 destination=”/path/model.onnx”,初始化器将保存在“/path/”文件夹中,以及“onnx.model”。model_state (Optional[Union[Dict[str, Any], str]]) – 包含所有权重的 PyTorch 模型的 state_dict。它可以是包含检查点路径的字符串,也可以是包含实际模型状态的字典。支持的文件格式与 torch.load 和 safetensors.safe_open 支持的格式相同。当使用
enable_fake_mode()但需要 ONNX 图上的真实初始化器时,这是必需的。serializer (Optional[ONNXProgramSerializer]) – 要使用的序列化器。如果未指定,则模型将被序列化为 Protobuf。
- save_diagnostics(destination)[source]¶
将导出诊断信息保存为 SARIF 日志到指定的目标路径。
- 参数
destination (str) – 保存诊断 SARIF 日志的目标路径。它必须具有 .sarif 扩展名。
- 引发
ValueError – 如果目标路径不以 .sarif 扩展名结尾。
- class torch.onnx.ONNXProgramSerializer(*args, **kwargs)¶
用于将 ONNX 图序列化为特定格式(例如 Protobuf)的协议。请注意,这是一种高级用法场景。
- serialize(onnx_program, destination)[source]¶
必须实现的序列化协议方法。
- 参数
onnx_program (ONNXProgram) – 表示内存中导出的 ONNX 模型
destination (BufferedIOBase) – 二进制 IO 流或预分配的缓冲区,序列化后的模型应写入其中。
示例
一个简单的序列化器,它将导出的
onnx.ModelProto以 Protobuf 格式写入destination# xdoctest: +REQUIRES(env:TORCH_DOCTEST_ONNX) >>> import io >>> import torch >>> import torch.onnx >>> class MyModel(torch.nn.Module): # Dummy model ... def __init__(self) -> None: ... super().__init__() ... self.linear = torch.nn.Linear(2, 2) ... def forward(self, x): ... out = self.linear(x) ... return out >>> class ProtobufONNXProgramSerializer: ... def serialize( ... self, onnx_program: torch.onnx.ONNXProgram, destination: io.BufferedIOBase ... ) -> None: ... destination.write(onnx_program.model_proto.SerializeToString()) >>> model = MyModel() >>> arg1 = torch.randn(2, 2, 2) # positional input 1 >>> torch.onnx.dynamo_export(model, arg1).save( ... destination="exported_model.onnx", ... serializer=ProtobufONNXProgramSerializer(), ... )
- class torch.onnx.ONNXRuntimeOptions(*, session_options=None, execution_providers=None, execution_provider_options=None)¶
通过 ONNX Runtime 影响 ONNX 模型执行的选项。
- 类 torch.onnx.InvalidExportOptionsError¶
当用户为
ExportOptions指定无效值时引发。
- 类 torch.onnx.OnnxExporterError(onnx_program, message)¶
当 ONNX 导出器错误发生时引发。
当 ONNX 导出过程中出现错误时,会抛出此异常。它封装了在失败之前生成的
ONNXProgram对象,允许访问部分导出结果和相关元数据。
- 类 torch.onnx.OnnxRegistry¶
ONNX 函数的注册表。
注册表维护着从限定名称到固定操作集版本下的符号函数的映射。它支持注册自定义 onnx-script 函数,并支持调度程序将调用调度到相应的函数。
- get_op_functions(namespace, op_name, overload=None)[source]¶
返回给定操作的 ONNXFunctions 列表:torch.ops.<namespace>.<op_name>.<overload>。
该列表按注册时间排序。自定义操作符应位于列表的后半部分。
- is_registered_op(namespace, op_name, overload=None)[source]¶
返回给定操作符是否已注册:torch.ops.<namespace>.<op_name>.<overload>。
- property opset_version: int¶
导出器应针对的 ONNX 操作符集版本。默认为最新支持的 ONNX 操作符集版本:18。随着 ONNX 的不断发展,默认版本将随着时间的推移而增加。
