PyTorch 2.0 版本包含 PyTorch Transformer API 的新高性能实现,旨在使最先进的 Transformer 模型的训练和部署更具成本效益。继“fastpath”推理执行(“Better Transformer”)成功发布之后,此版本引入了对使用自定义核架构进行缩放点积注意力 (SPDA) 的训练和推理的高性能支持。
您可以通过直接调用新的 SDPA 算子(如SDPA 教程中所述),或通过与现有 PyTorch Transformer API 集成透明地利用新的融合 SDPA 核。PyTorch Transformer API 的所有功能将继续兼容,许多功能映射到高性能 SDPA 核,而其他功能则无法提供更高的性能支持(例如,如下所述的 need_weights),同时对其他功能扩展的高性能支持可能仍在积极开发中。
类似于“fastpath”架构,自定义核已完全集成到 PyTorch Transformer API 中——因此,使用原生 Transformer 和 MultiHeadAttention API 将使用户透明地看到显著的速度提升。与“fastpath”架构不同,新引入的“自定义核”支持更多的用例,包括使用交叉注意力、Transformer 解码器以及用于训练模型,此外还支持现有 fastpath 推理用于固定和可变序列长度的 Transformer 编码器和自注意力用例。
为了充分利用不同的硬件模型和 Transformer 用例,支持多个 SDPA 自定义核,并具有自定义核选择逻辑,该逻辑将为给定模型和硬件类型选择最高性能的核。特别是,PyTorch 2.0 版本中包含的第一个自定义核是 Flash Attention 核(sdpa_flash,用于具有 SM80+ 架构级别的 Nvidia GPU 上的 16 位浮点训练和推理)和 xFormers 内存高效注意力核(sdpa_mem_eff,用于各种 Nvidia GPU 上的 16 位和 32 位浮点训练和推理)。当自定义核不适用时,通用核 sdpa_math 提供实现。
如前所述,自定义核提供更广泛的执行场景支持。为确保高效执行(例如,使用 GPU 张量核),模型配置需要满足少量要求。这些要求列表将随着时间的推移而演变,有望放宽限制当前支持的自定义核使用的约束,或在未来提供额外的核。
有关自定义核和调度约束的最新列表,您可以参考sdp_utils.h。截至 PyTorch 2.0,现有融合 SDPA 核具有以下约束:
- Flash Attention 仅支持 16 位浮点数据类型(float16 和 bfloat16)。
- 对于 16 位浮点数,头部维度必须是 8 的倍数;对于 32 位浮点数,头部维度必须是 4 的倍数。目前,Flash Attention 自定义核支持的最大 head_dim 为 128。
- 对于 mem_efficient 核,CUDA 架构级别必须为 sm5x 或更高;对于 Flash Attention,必须为 sm80。
- Flash Attention 支持任意 dropout,在 PyTorch 2.0 中,mem_efficient 核不支持 dropout(即,对于此核,dropout 必须设置为零才能在 PyTorch 2.0 中被选择)。
- 为了支持可变序列长度批次,所有 SDPA 核都支持 Nested Tensor 输入,这些输入使用可变序列长度张量结合输入数据和填充信息进行前向传播。(您可以在Nested Tensor 教程中找到有关 Nested Tensor 的更多信息。)
- 您可以指定一个 key_padding_mask 和一个 attn_mask,方法是在将它们传递给 SDPA 算子之前将它们组合起来。特别是,您可以使用 nn.Transformer API 的每个批次元素的 key padding mask 来实现批次中可变序列长度输入的训练。
- 目前,融合核实现唯一支持的注意力掩码是训练中常用的因果掩码。要在自定义核中指定因果掩码,必须使用 is_causal 布尔值指定,并且 attn_mask 必须为 None。
- 对 Nested Tensors 的支持仍在开发中。具体来说,在 PyTorch 2.0 中,只有 sdpa_math 核支持使用 Nested Tensors 进行训练。此外,PyTorch 2.0 不支持将 Nested Tensors 作为使用 torch.compile() 编译代码的一部分。
- SDPA 算子不支持返回平均注意力权重,因为计算它们会破坏使融合核更有效执行的优化。torch.nn.MultiheadAttention 的前向函数的参数 need_weights 默认为 True。为了使用融合核,need_weights 需要设置为 need_weights=False。
我们发现,在实际应用中,除了训练期间的因果掩码外,注意力掩码很少使用。因此,我们通过内置选项将因果掩码用作注意力掩码,并使用与新 SDPA 算子一起引入的 is_causal 参数选择此新功能,从而降低了核复杂性和计算成本。
为常用因果掩码提供 is_causal 布尔标志也避免了昂贵且内存密集型的因果掩码分配,通过允许更多内存用于大批量,提高了训练内存效率,并减少了内存带宽和缓存争用——这两者在 GPU 加速器中都是宝贵的——因为无需加载注意力掩码张量。
如果所有可用的自定义核的约束均未满足,则训练将回退到使用默认的 sdpa_math 核,该核使用一系列 PyTorch 算子实现缩放点积注意力的数学方程以实现 SDPA。这是最通用的“包罗万象”的备用核,可确保所有模型训练成功。
除了现有的 Transformer API 之外,模型开发者还可以通过调用新的 scaled_dot_product_attention() 算子直接使用缩放点积注意力核。此算子可以与内投影和外投影结合使用,以高效实现多头注意力,如SDPA 教程中所述。
除了添加自定义核之外,加速 PyTorch 2 Transformer 还与 PyTorch 2.0 编译集成。要在使用模型的同时受益于 PT2 编译的额外加速(用于推理或训练),请使用以下命令对模型进行预处理:
model = torch.compile(model)
我们通过结合自定义内核和 `torch.compile()`,使用加速 PyTorch 2 Transformers 在训练 Transformer 模型,特别是大型语言模型方面,取得了显著的加速。
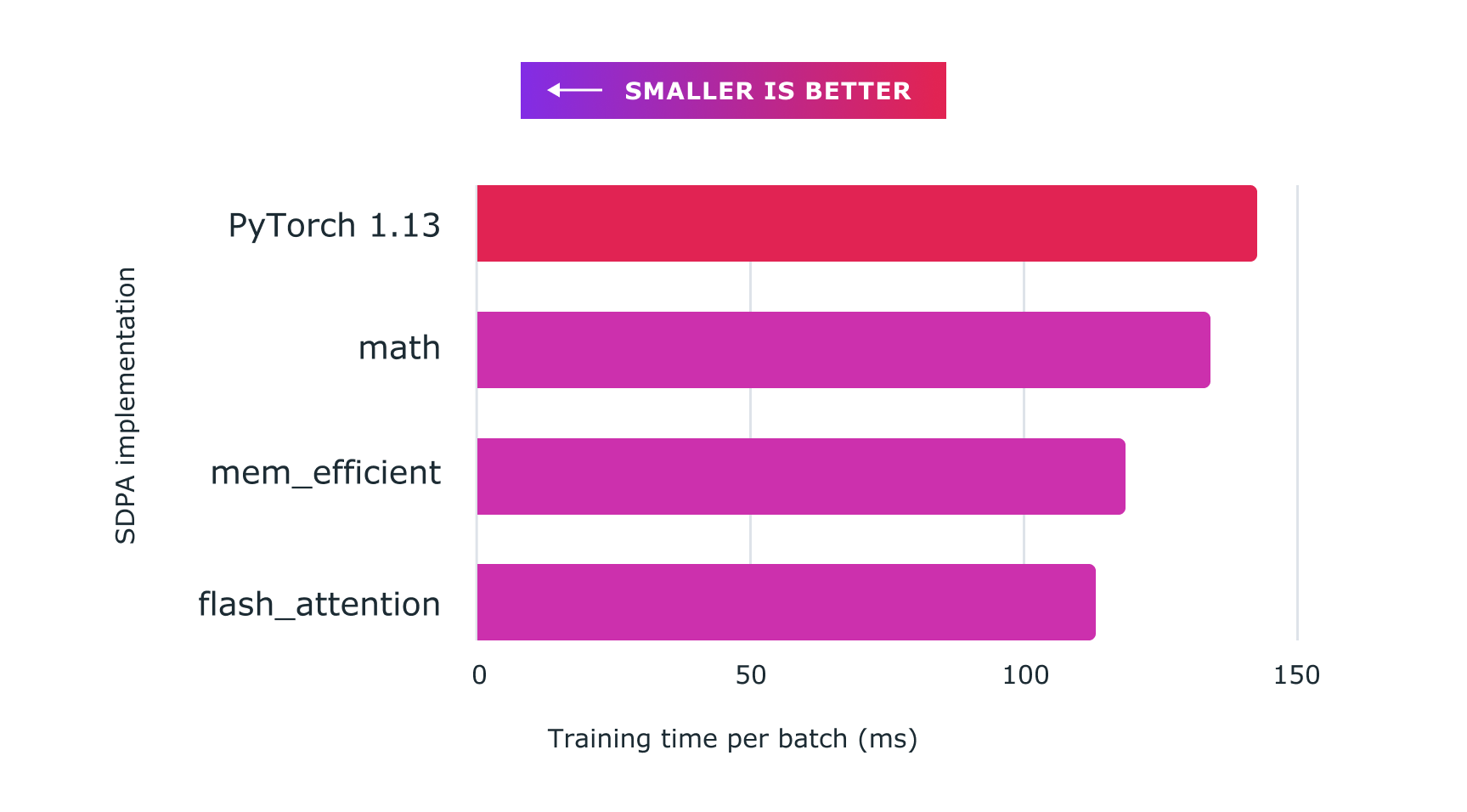 图:使用带有自定义核和 torch.compile 的缩放点积注意力,可以显著加速大型语言模型(例如此处所示的nanoGPT)的训练。
图:使用带有自定义核和 torch.compile 的缩放点积注意力,可以显著加速大型语言模型(例如此处所示的nanoGPT)的训练。
最后,由于自定义核的内存效率更高,请尝试增加训练批次的大小,以通过增加批次大小实现更快的训练。
除了自动核选择之外,上下文管理器还使开发者能够覆盖核选择算法——这在日常操作中不是必需的,但使开发者能够调试其代码,并使性能工程师能够覆盖核选择。SDPA 教程提供了有关使用 SDPA 上下文管理器的其他信息。
除了作为 nn.Transformer API 的一部分提供之外,随着 PyTorch 2.0 的发布,加速 PyTorch 2 Transformer 自定义核还可与 torchtext、torchvision 和 fairseq 领域库结合使用。