TorchRec 高级架构¶
在本节中,您将了解 TorchRec 的高级架构,该架构旨在优化使用 PyTorch 的大规模推荐系统。您将了解 TorchRec 如何使用模型并行在多个 GPU 之间分配复杂模型,从而增强内存管理和 GPU 利用率,并了解 TorchRec 的基本组件和分片策略。
实际上,TorchRec 提供了并行原语,允许混合数据并行/模型并行、嵌入表分片、规划器生成分片计划、流水线训练等。
TorchRec 的并行策略:模型并行¶
随着现代深度学习模型的规模不断扩大,分布式深度学习已成为成功在足够的时间内训练模型所必需的。在这种范式中,已经开发了两种主要方法:数据并行和模型并行。TorchRec 侧重于后者,用于嵌入表的分片。
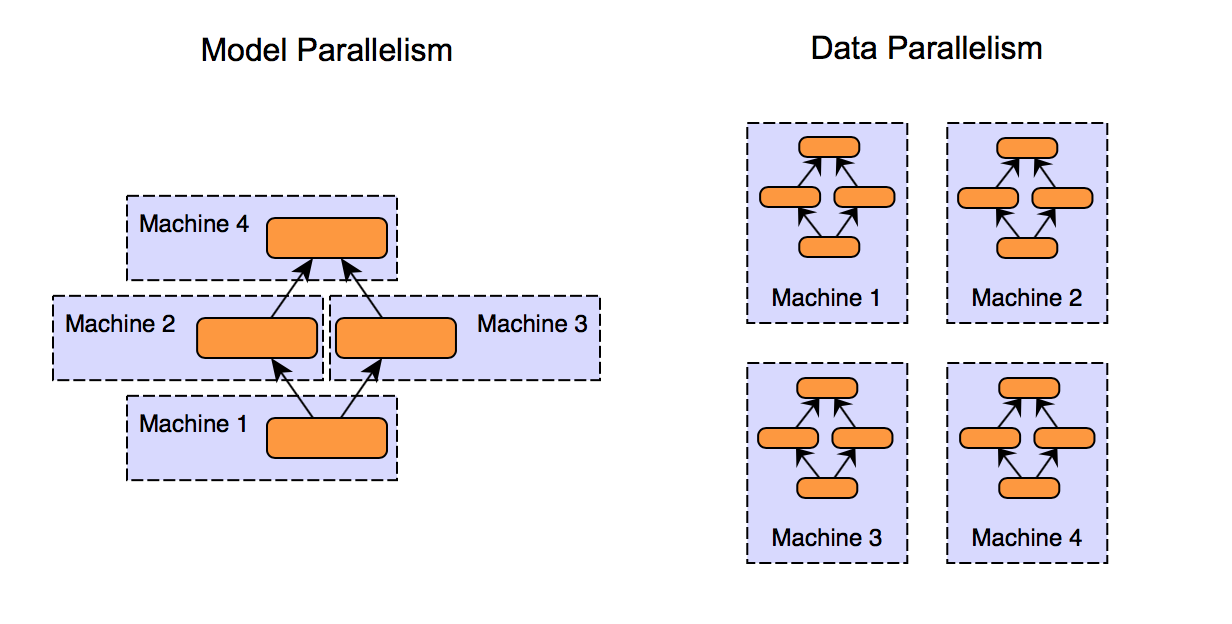
图 1. 模型并行和数据并行方法之间的比较¶
正如您在上面的图表中看到的,模型并行和数据并行是将工作负载分配到多个 GPU 的两种方法,
模型并行
将模型分成多个段并将其分配到 GPU
每个段独立处理数据
适用于不适合单个 GPU 的大型模型
数据并行
在每个 GPU 上分发整个模型的副本
每个 GPU 处理数据子集并为整体计算做出贡献
对于适合单个 GPU 但需要处理大型数据集的模型有效
模型并行的优点
优化大型模型的内存使用和计算效率
特别有利于具有大型嵌入表的推荐系统
在 DLRM 类型架构中实现嵌入的并行计算
嵌入表¶
为了让 TorchRec 知道要推荐什么,我们需要能够表示实体及其关系,这就是嵌入的用途。嵌入是高维空间中实数的向量,用于表示单词、图像或用户等复杂数据中的含义。嵌入表是将多个嵌入聚合到一个矩阵中。最常见的,嵌入表表示为维度为 (B, N) 的 2D 矩阵。
B 是表存储的嵌入数量
N 是每个嵌入的维度数。
B 中的每一个也可以称为 ID(表示电影标题、用户、广告等信息),当访问 ID 时,我们返回相应的嵌入向量,其大小为嵌入维度 N。
还有嵌入池化的选择,通常,我们正在查找给定特征的多个行,这引出了一个问题,即我们如何处理查找多个嵌入向量。池化是一种常用技术,我们组合嵌入向量,通常通过行的总和或平均值,以生成一个嵌入向量。这是 PyTorch nn.Embedding 和 nn.EmbeddingBag 之间的主要区别。
PyTorch 通过 nn.Embedding 和 nn.EmbeddingBag 表示嵌入。在这些模块的基础上,TorchRec 引入了 EmbeddingCollection 和 EmbeddingBagCollection,它们是相应 PyTorch 模块的集合。此扩展使 TorchRec 能够批量处理表并在单个内核调用中执行对多个嵌入的查找,从而提高效率。
这是端到端流程图,描述了如何在推荐模型的训练过程中使用嵌入
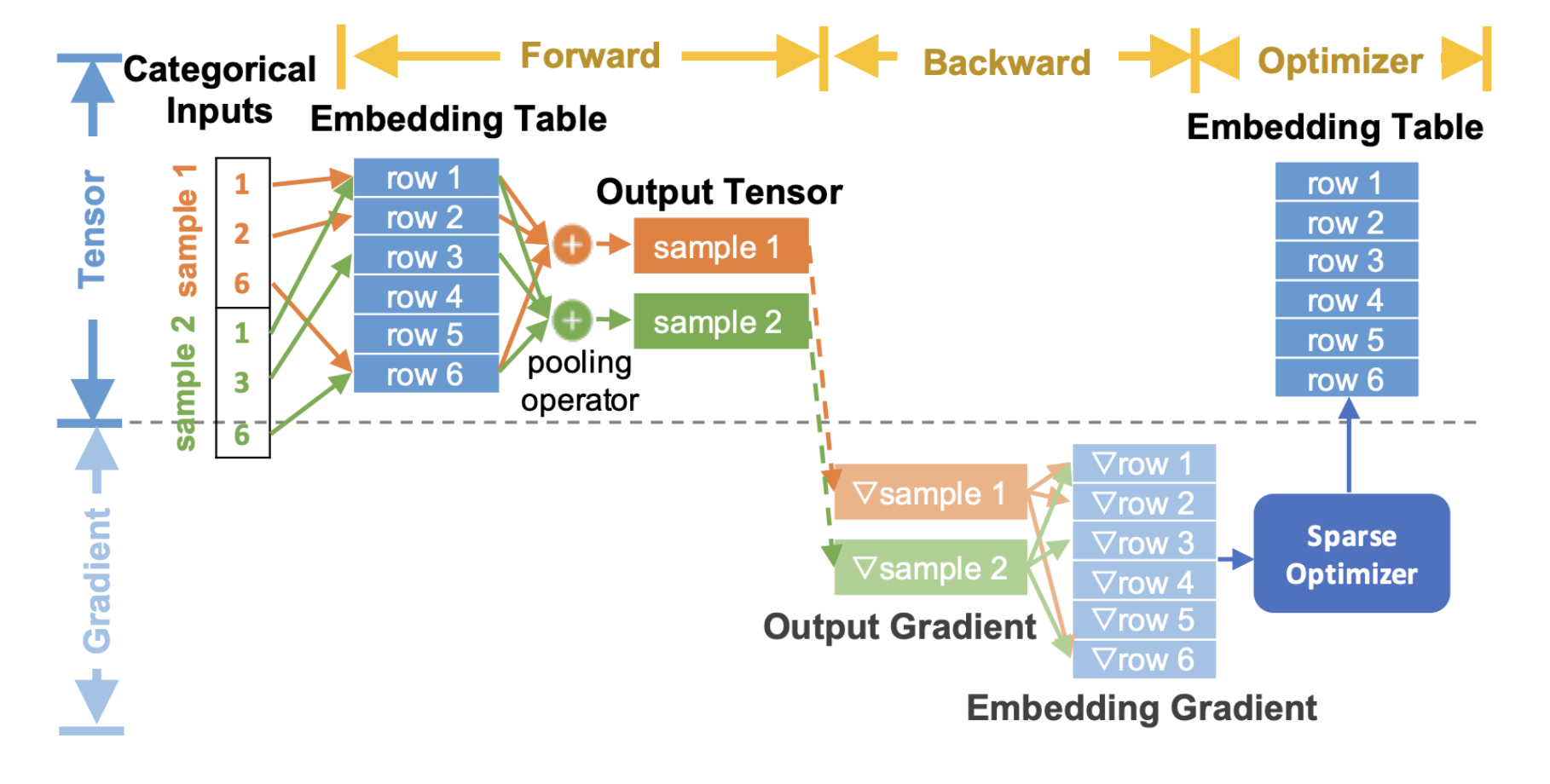
图 2. TorchRec 端到端嵌入流程¶
在上面的图表中,我们展示了通用的 TorchRec 端到端嵌入查找过程,
在前向传播中,我们执行嵌入查找和池化
在反向传播中,我们计算输出查找的梯度,并将它们传递到优化器以更新嵌入表
请注意,此处的嵌入梯度显示为灰色,因为我们没有将它们完全物化到内存中,而是将它们与优化器更新融合在一起。这显著减少了内存使用,我们将在后面的优化器概念部分详细介绍。
我们建议您浏览 TorchRec 概念页面,以了解所有内容如何端到端地联系在一起的基本原理。它包含大量有用的信息,可帮助您充分利用 TorchRec。
