Silero 语音转文本模型
# this assumes that you have a proper version of PyTorch already installed
pip install -q torchaudio omegaconf soundfile
import torch
import zipfile
import torchaudio
from glob import glob
device = torch.device('cpu') # gpu also works, but our models are fast enough for CPU
model, decoder, utils = torch.hub.load(repo_or_dir='snakers4/silero-models',
model='silero_stt',
language='en', # also available 'de', 'es'
device=device)
(read_batch, split_into_batches,
read_audio, prepare_model_input) = utils # see function signature for details
# download a single file, any format compatible with TorchAudio (soundfile backend)
torch.hub.download_url_to_file('https://opus-codec.org/static/examples/samples/speech_orig.wav',
dst ='speech_orig.wav', progress=True)
test_files = glob('speech_orig.wav')
batches = split_into_batches(test_files, batch_size=10)
input = prepare_model_input(read_batch(batches[0]),
device=device)
output = model(input)
for example in output:
print(decoder(example.cpu()))
模型描述
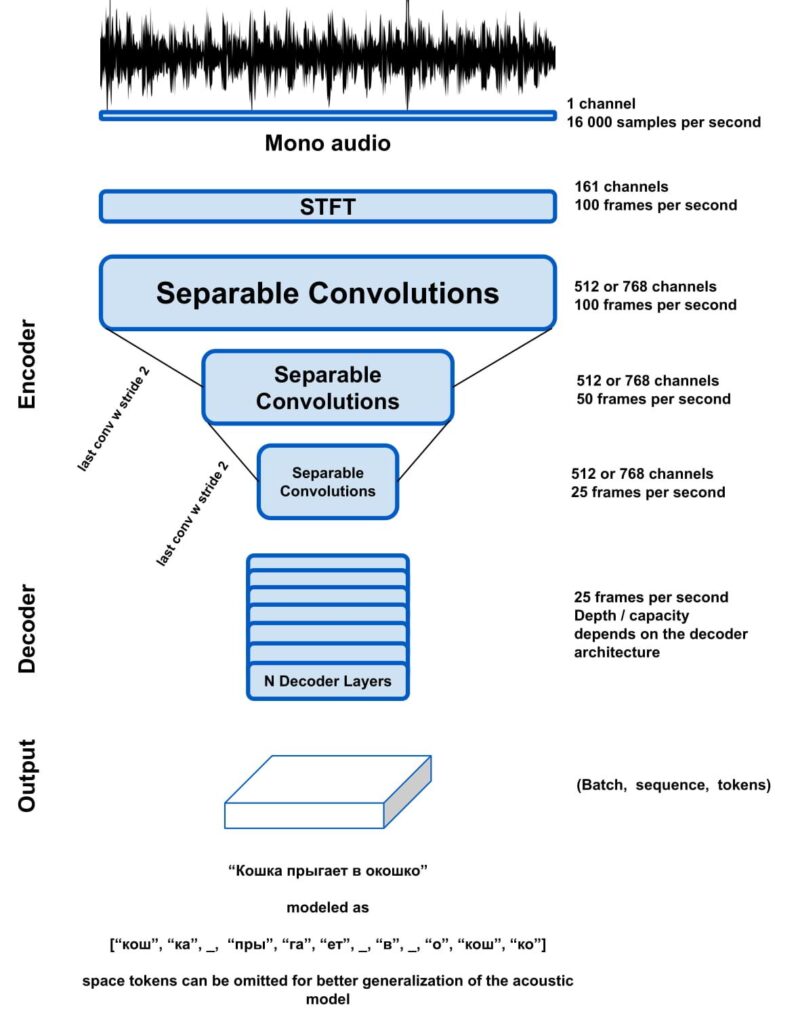
Silero 语音转文本模型以紧凑的形式为几种常用语言提供企业级语音转文本功能。与传统的 ASR 模型不同,我们的模型对各种方言、编解码器、领域、噪声和较低采样率(为简单起见,音频应重新采样到 16 kHz)具有鲁棒性。模型接收归一化后的音频样本(即,除了归一化到 -1…1 之外,不进行任何预处理),并输出带有令牌概率的帧。为了简单起见,我们提供了一个解码器实用程序(我们可以将其包含在模型本身中,但在某些导出场景中,脚本模块在存储模型工件(即标签)时存在问题)。
我们希望我们为 Open-STT 和 Silero 模型所做的努力能让语音领域的 ImageNet 时刻更早到来。
支持的语言和格式
截至本页面更新,支持以下语言:
- 英语
- 德语
- 西班牙语
要查看始终保持最新的语言列表,请访问我们的存储库,并查看yml文件以了解所有可用的检查点。
其他示例和基准
有关其他示例和其他模型格式,请访问此链接。有关质量和性能基准,请参阅维基。这些资源将不时更新。