ProxylessNAS
import torch
target_platform = "proxyless_cpu"
# proxyless_gpu, proxyless_mobile, proxyless_mobile14 are also avaliable.
model = torch.hub.load('mit-han-lab/ProxylessNAS', target_platform, pretrained=True)
model.eval()
所有预训练模型都要求输入图像以相同的方式进行归一化,即由形状为 (3 x H x W) 的 3 通道 RGB 图像组成的小批量数据,其中 H 和 W 预计至少为 224。图像必须加载到 [0, 1] 范围内,然后使用 mean = [0.485, 0.456, 0.406] 和 std = [0.229, 0.224, 0.225] 进行归一化。
这是一个示例执行。
# Download an example image from the pytorch website
import urllib
url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
try: urllib.URLopener().retrieve(url, filename)
except: urllib.request.urlretrieve(url, filename)
# sample execution (requires torchvision)
from PIL import Image
from torchvision import transforms
input_image = Image.open(filename)
preprocess = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
input_tensor = preprocess(input_image)
input_batch = input_tensor.unsqueeze(0) # create a mini-batch as expected by the model
# move the input and model to GPU for speed if available
if torch.cuda.is_available():
input_batch = input_batch.to('cuda')
model.to('cuda')
with torch.no_grad():
output = model(input_batch)
# Tensor of shape 1000, with confidence scores over ImageNet's 1000 classes
print(output[0])
# The output has unnormalized scores. To get probabilities, you can run a softmax on it.
probabilities = torch.nn.functional.softmax(output[0], dim=0)
print(probabilities)
# Download ImageNet labels
!wget https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt
# Read the categories
with open("imagenet_classes.txt", "r") as f:
categories = [s.strip() for s in f.readlines()]
# Show top categories per image
top5_prob, top5_catid = torch.topk(probabilities, 5)
for i in range(top5_prob.size(0)):
print(categories[top5_catid[i]], top5_prob[i].item())
模型描述
ProxylessNAS 模型来自ProxylessNAS: Direct Neural Architecture Search on Target Task and Hardware论文。
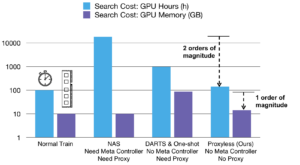
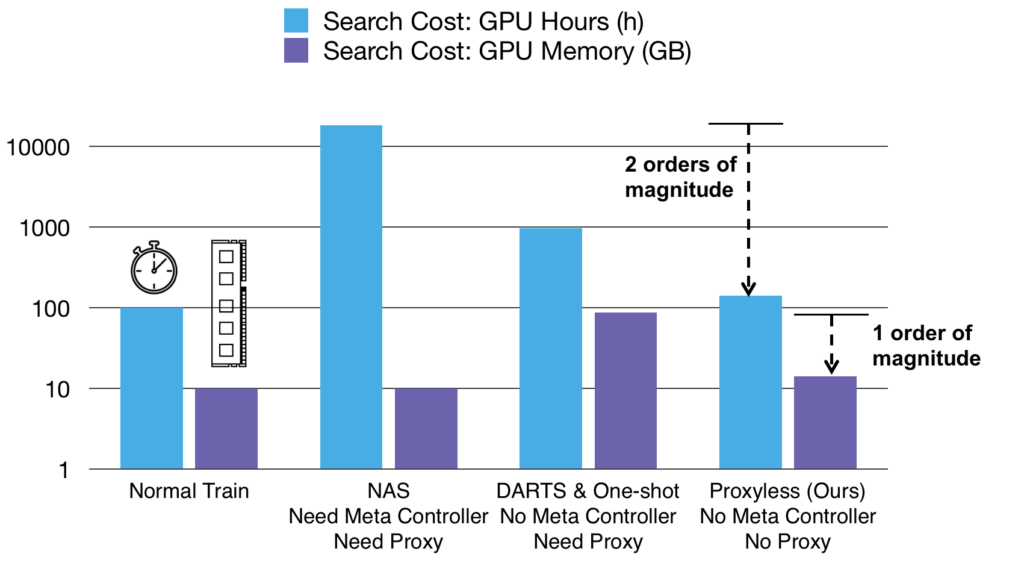
传统上,人们倾向于为所有硬件平台设计一个高效模型。但是,不同的硬件具有不同的属性,例如,CPU 频率更高,而 GPU 更擅长并行化。因此,我们不是进行泛化,而是需要为不同的硬件平台定制 CNN 架构。如下所示,在相似的准确度下,定制化在所有三个平台上都提供了免费但显著的性能提升。
| 模型结构 | GPU 延迟 | CPU 延迟 | 移动设备延迟 |
|---|---|---|---|
| proxylessnas_gpu | 5.1毫秒 | 204.9毫秒 | 124毫秒 |
| proxylessnas_cpu | 7.4毫秒 | 138.7毫秒 | 116毫秒 |
| proxylessnas_mobile | 7.2毫秒 | 164.1毫秒 | 78毫秒 |
预训练模型对应的 Top-1 准确度如下所示。
| 模型结构 | Top-1 错误率 |
|---|---|
| proxylessnas_cpu | 24.7 |
| proxylessnas_gpu | 24.9 |
| proxylessnas_mobile | 25.4 |
| proxylessnas_mobile_14 | 23.3 |
参考文献