一次性(Once-for-All)
获取超网
您可以按如下方式快速加载超网
import torch
super_net_name = "ofa_supernet_mbv3_w10"
# other options:
# ofa_supernet_resnet50 /
# ofa_supernet_mbv3_w12 /
# ofa_supernet_proxyless
super_net = torch.hub.load('mit-han-lab/once-for-all', super_net_name, pretrained=True).eval()
| OFA 网络 | 设计空间 | 分辨率 | 宽度乘数 | 深度 | 扩展比 | 核大小 |
|---|---|---|---|---|---|---|
| ofa_resnet50 | ResNet50D | 128 – 224 | 0.65, 0.8, 1.0 | 0, 1, 2 | 0.2, 0.25, 0.35 | 3 |
| ofa_mbv3_d234_e346_k357_w1.0 | MobileNetV3 | 128 – 224 | 1.0 | 2, 3, 4 | 3, 4, 6 | 3, 5, 7 |
| ofa_mbv3_d234_e346_k357_w1.2 | MobileNetV3 | 160 – 224 | 1.2 | 2, 3, 4 | 3, 4, 6 | 3, 5, 7 |
| ofa_proxyless_d234_e346_k357_w1.3 | ProxylessNAS | 128 – 224 | 1.3 | 2, 3, 4 | 3, 4, 6 | 3, 5, 7 |
以下是从超网中采样/选择子网的用法
# Randomly sample sub-networks from OFA network
super_net.sample_active_subnet()
random_subnet = super_net.get_active_subnet(preserve_weight=True)
# Manually set the sub-network
super_net.set_active_subnet(ks=7, e=6, d=4)
manual_subnet = super_net.get_active_subnet(preserve_weight=True)
获取专用架构
import torch
# or load a architecture specialized for certain platform
net_config = "resnet50D_MAC_4_1B"
specialized_net, image_size = torch.hub.load('mit-han-lab/once-for-all', net_config, pretrained=True)
specialized_net.eval()
更多模型和配置可在 once-for-all/model-zoo 中找到,并通过以下脚本获取
ofa_specialized_get = torch.hub.load('mit-han-lab/once-for-all', "ofa_specialized_get")
model, image_size = ofa_specialized_get("flops@595M_top1@80.0_finetune@75", pretrained=True)
model.eval()
模型的预测可以通过以下方式评估
# Download an example image from pytorch website
import urllib
url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
try:
urllib.URLopener().retrieve(url, filename)
except:
urllib.request.urlretrieve(url, filename)
# sample execution (requires torchvision)
from PIL import Image
from torchvision import transforms
input_image = Image.open(filename)
preprocess = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
input_tensor = preprocess(input_image)
input_batch = input_tensor.unsqueeze(0) # create a mini-batch as expected by the model
# move the input and model to GPU for speed if available
if torch.cuda.is_available():
input_batch = input_batch.to('cuda')
model.to('cuda')
with torch.no_grad():
output = model(input_batch)
# Tensor of shape 1000, with confidence scores over ImageNet's 1000 classes
print(output[0])
# The output has unnormalized scores. To get probabilities, you can run a softmax on it.
probabilities = torch.nn.functional.softmax(output[0], dim=0)
print(probabilities)
模型描述
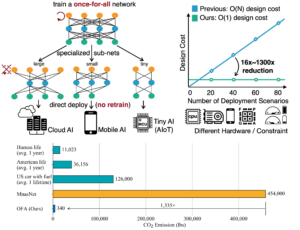
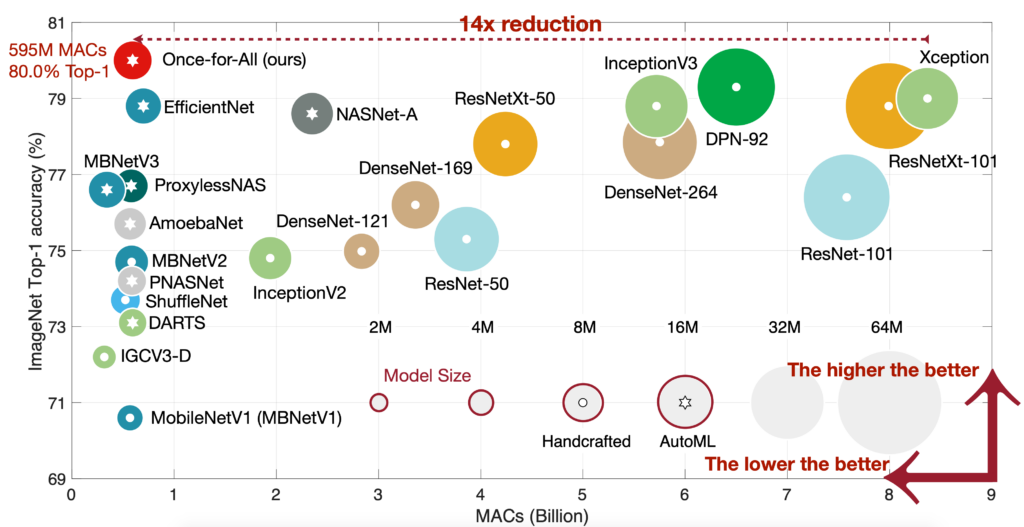
一次训练通用模型 (Once-for-all) 来自 Once for All: Train One Network and Specialize it for Efficient Deployment。传统方法要么手动设计,要么使用神经架构搜索 (NAS) 来寻找专门的神经网络,并针对每种情况从头开始训练,这在计算上是 prohibitive(产生相当于 5 辆汽车寿命的二氧化碳排放),因此无法扩展。在这项工作中,我们提出通过解耦训练和搜索来训练一个支持各种架构设置的“一次训练通用” (OFA) 网络。在各种边缘设备上,OFA 始终优于最先进 (SOTA) 的 NAS 方法(ImageNet top1 准确率比 MobileNetV3 提高高达 4.0%,或相同准确率但比 MobileNetV3 快 1.5 倍,比 EfficientNet 快 2.6 倍,就测量延迟而言),同时将 GPU 小时数和二氧化碳排放量减少了许多个数量级。特别是,OFA 在移动设置(<600M MACs)下实现了新的 SOTA 80.0% ImageNet top-1 准确率。
参考资料
@inproceedings{
cai2020once,
title={Once for All: Train One Network and Specialize it for Efficient Deployment},
author={Han Cai and Chuang Gan and Tianzhe Wang and Zhekai Zhang and Song Han},
booktitle={International Conference on Learning Representations},
year={2020},
url={https://arxiv.org/pdf/1908.09791.pdf}
}