MEAL_V2
我们需要一个额外的 Python 依赖项
!pip install timm
import torch
# list of models: 'mealv1_resnest50', 'mealv2_resnest50', 'mealv2_resnest50_cutmix', 'mealv2_resnest50_380x380', 'mealv2_mobilenetv3_small_075', 'mealv2_mobilenetv3_small_100', 'mealv2_mobilenet_v3_large_100', 'mealv2_efficientnet_b0'
# load pretrained models, using "mealv2_resnest50_cutmix" as an example
model = torch.hub.load('szq0214/MEAL-V2','meal_v2', 'mealv2_resnest50_cutmix', pretrained=True)
model.eval()
所有预训练模型都要求输入图像以相同的方式进行归一化,即由形状为 (3 x H x W) 的 3 通道 RGB 图像组成的小批量数据,其中 H 和 W 预计至少为 224。图像必须加载到 [0, 1] 范围内,然后使用 mean = [0.485, 0.456, 0.406] 和 std = [0.229, 0.224, 0.225] 进行归一化。
这是一个示例执行。
# Download an example image from the pytorch website
import urllib
url, filename = ("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
try: urllib.URLopener().retrieve(url, filename)
except: urllib.request.urlretrieve(url, filename)
# sample execution (requires torchvision)
from PIL import Image
from torchvision import transforms
input_image = Image.open(filename)
preprocess = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
input_tensor = preprocess(input_image)
input_batch = input_tensor.unsqueeze(0) # create a mini-batch as expected by the model
# move the input and model to GPU for speed if available
if torch.cuda.is_available():
input_batch = input_batch.to('cuda')
model.to('cuda')
with torch.no_grad():
output = model(input_batch)
# Tensor of shape 1000, with confidence scores over ImageNet's 1000 classes
print(output[0])
# The output has unnormalized scores. To get probabilities, you can run a softmax on it.
probabilities = torch.nn.functional.softmax(output[0], dim=0)
print(probabilities)
# Download ImageNet labels
!wget https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt
# Read the categories
with open("imagenet_classes.txt", "r") as f:
categories = [s.strip() for s in f.readlines()]
# Show top categories per image
top5_prob, top5_catid = torch.topk(probabilities, 5)
for i in range(top5_prob.size(0)):
print(categories[top5_catid[i]], top5_prob[i].item())
模型描述
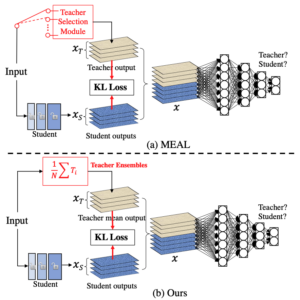
MEAL V2 模型来自MEAL V2: 无需技巧即可将 ImageNet 上的普通 ResNet-50 提升至 80% 以上 Top-1 准确率论文。
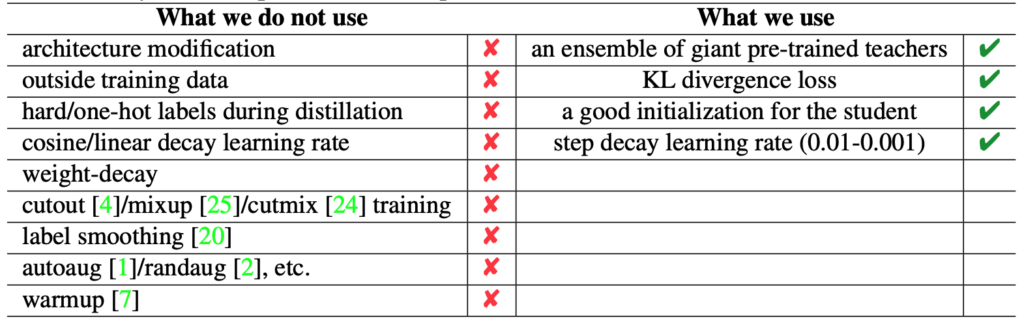
在本文中,我们介绍了一种简单而有效的方法,可以将普通 ResNet-50 在 ImageNet 上的 Top-1 准确率提升到 80% 以上,而无需任何技巧。通常,我们的方法基于最近提出的MEAL,即通过判别器进行集成知识蒸馏。我们通过以下方式进一步简化它:1) 仅在最终输出上采用相似性损失和判别器;2) 使用所有教师集成模型的 softmax 概率平均值作为蒸馏的更强监督。我们方法的一个关键观点是,在蒸馏过程中不应使用 one-hot/硬标签。我们表明,这样一个简单的框架可以实现最先进的结果,而无需涉及任何常用技巧,例如:1) 架构修改;2) ImageNet 以外的外部训练数据;3) autoaug/randaug;4) 余弦学习率;5) mixup/cutmix 训练;6) 标签平滑;等。
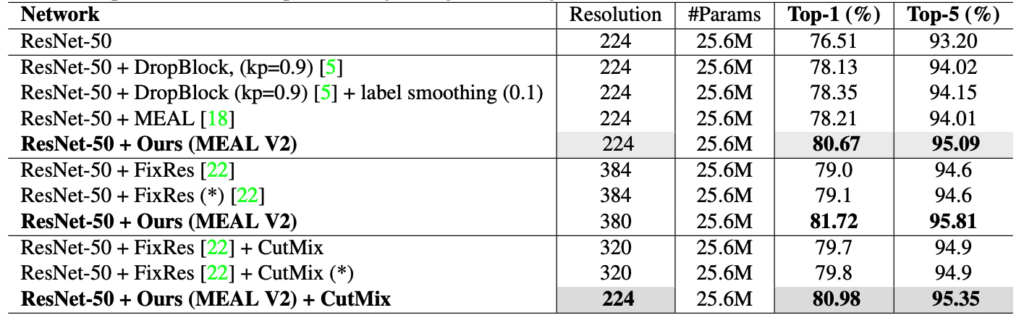
| 模型 | 分辨率 | #参数 | Top-1/Top-5 | |
|---|---|---|---|---|
| MEAL-V1 w/ ResNet50 | 224 | 25.6M | 78.21/94.01 | GitHub |
| MEAL-V2 w/ ResNet50 | 224 | 25.6M | 80.67/95.09 | |
| MEAL-V2 w/ ResNet50 | 380 | 25.6M | 81.72/95.81 | |
| MEAL-V2 + CutMix w/ ResNet50 | 224 | 25.6M | 80.98/95.35 | |
| MEAL-V2 w/ MobileNet V3-Small 0.75 | 224 | 2.04M | 67.60/87.23 | |
| MEAL-V2 w/ MobileNet V3-Small 1.0 | 224 | 2.54M | 69.65/88.71 | |
| MEAL-V2 w/ MobileNet V3-Large 1.0 | 224 | 5.48M | 76.92/93.32 | |
| MEAL-V2 w/ EfficientNet-B0 | 224 | 5.29M | 78.29/93.95 |
参考文献
@article{shen2020mealv2,
title={MEAL V2: Boosting Vanilla ResNet-50 to 80%+ Top-1 Accuracy on ImageNet without Tricks},
author={Shen, Zhiqiang and Savvides, Marios},
journal={arXiv preprint arXiv:2009.08453},
year={2020}
}
@inproceedings{shen2019MEAL,
title = {MEAL: Multi-Model Ensemble via Adversarial Learning},
author = {Shen, Zhiqiang and He, Zhankui and Xue, Xiangyang},
booktitle = {AAAI},
year = {2019}
}